
Enterprises are rapidly moving from an AI that answers questions and generates content to one that performs tasks and takes actions. According to Thomas Kurian, CEO of Google Cloud, this shift requires a fundamentally different approach to infrastructure and software. Google’s view is that only a tightly integrated portfolio – spanning silicon to applications and everything in between – can effectively support this transition.
A linchpin of this transition is the emergent data and AI platform, what we call the System of Intelligence (what Google is initially exposing as its Knowledge Catalog) – this capability ultimately abstracts and harmonizes analytics and operational applications. In addition we see an evolving system of agency – what Google calls a system of action, comprising the Knowledge Catalog and the Agent Platform.
Measurable business value, we think, will ride on top of this infrastructure and that is where the real battle lines will be drawn. Specifically we see frontier model vendors, of which Google is one, rapidly building out capabilities that will become fundamental to the future of software – which we predict will be the biggest transformation in the history of the software industry.
In this Breaking Analysis we contextualize the announcements and news from Google Cloud Next 2026 using the framework we’ve been iterating on for the three years, architected by George Gilbert.
Opening setup: TPU 8, the data foundation, and the move from chat to actions
The kickoff this week was Google’s big TPU 8 announcement – 8t and 8i – with the Acquired guys hosting. It was positioned as the next big step in Google’s silicon roadmap and part of a broader message that Google wants to be seen as the only hyperscaler with a frontier model, a differentiated data stack, and a credible path to delivering agents at scale. There was also a bit of semantic gymnastics around whether TPU is an ASIC – Google said “it’s not an ASIC” rather a more general purpose chip. Call it what you want – it is specialized silicon built to run modern AI efficiently, and it is central to Google’s argument that economics and performance are going to matter more than ever. Surprising to us at the TPU pre-announcement was, while there were plenty of “2X, 3X, 9.8X” claims, there was virtually no mention of metrics around performance per watt, arguably the most important measure for operators that are energy constrained.
TPUs are both impressive and critical to Google’s strategy. Our view, however, is that Nvidia remains a crucial partner of Google’s (and of other hyperscalers), irrespective of their in-house silicon efforts. In other words, we don’t see TPU as directly competitive to Nvidia, rather we see it as a capability that gives Google differentiable advantage via its ability to tightly integrate hardware and software. It also allows google to best manage the gap between accelerator demand and supply. Regardless, access to Nvidia’s CUDA ecosystem is fundamental in providing optionality to developers and being able to provide access to the world’s largest and most important AI ecosystem.
The bigger setup in this Breaking Analysis is that Google has been doing yeoman’s work for years in the data platform layer. It’s not just BigQuery. It’s the metadata layer on top, plus integration with the operational database Spanner. In our view, Google is the only hyperscaler that has been meaningfully competitive with Snowflake and Databricks as a data platform – and that work has been a long build toward what’s now showing up as an agent platform story.
This is where the conversation starts to get really interesting. For decades, the industry built silos – analytic data silos and operational application silos. Agents that transform a business – agents that can perceive, reason, decide, act, and learn – don’t unlock much value if they’re siloed. You end up with automation, but you don’t change how the business works.
This is the context for the premise Thomas Kurian put forward this week. The industry has moved past RAG-based chatbots – request and receive an answer – and into a world where agents, and teams of agents, act on behalf of humans and take action. That shift pulls a new set of infrastructure requirements into the critical path. It has to be integrated.
Google’s positioning is it believes it is the only “full stack” hyperscaler that can bring the pieces together – silicon, infrastructure, data, models, applications and services – into a coherent system for agentic workloads. At the same time, many frontier model vendors don’t have a cloud platform, which creates a structural advantage for Google as it tries to turn model capability into enterprise deployment. Thomas Kurian (and others) presented the stack slide below (and variants), throughout the conference to accentuate this point.
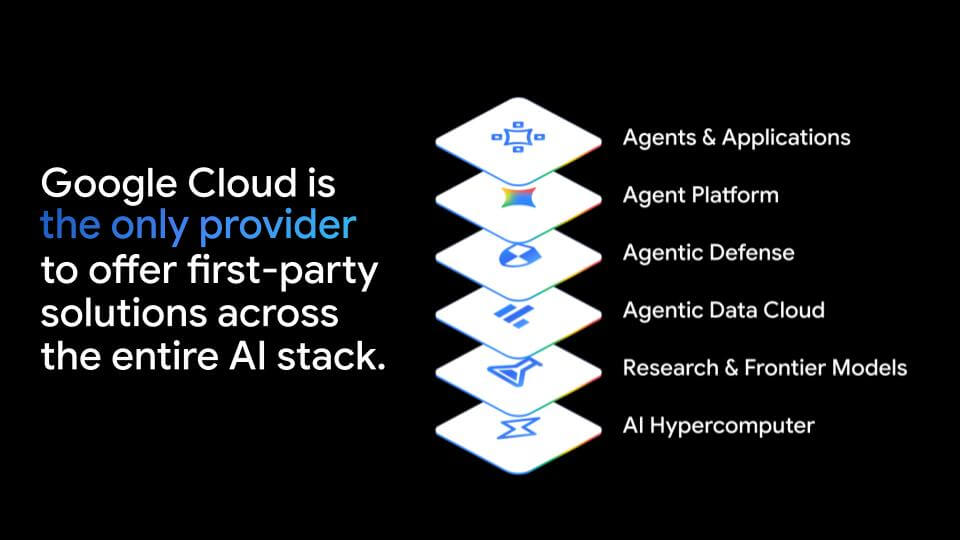
Takeaway – TPU 8 is the headline, but the more important story is Google’s attempt to connect its silicon, data platform, and frontier model posture into an integrated agent platform narrative.
Service as software – why agents force the whole enterprise to re-architect
In this section we revisit our framework for how the software industry is changing. Later in this research note, we map Google’s model and try to reconcile how it fits into our vision of the future.
The core idea in the slide below is, in our research, we believe the entire software industry model is changing, moving from Software-as-a-Service to “Service-as-Software.” When the industry moved from on-prem to SaaS, everything changed – the technology model, the business model, and the operating model. Vendors stopped shipping software and started operating it. Value delivery became continuous – and the organization had to be built around that reality.
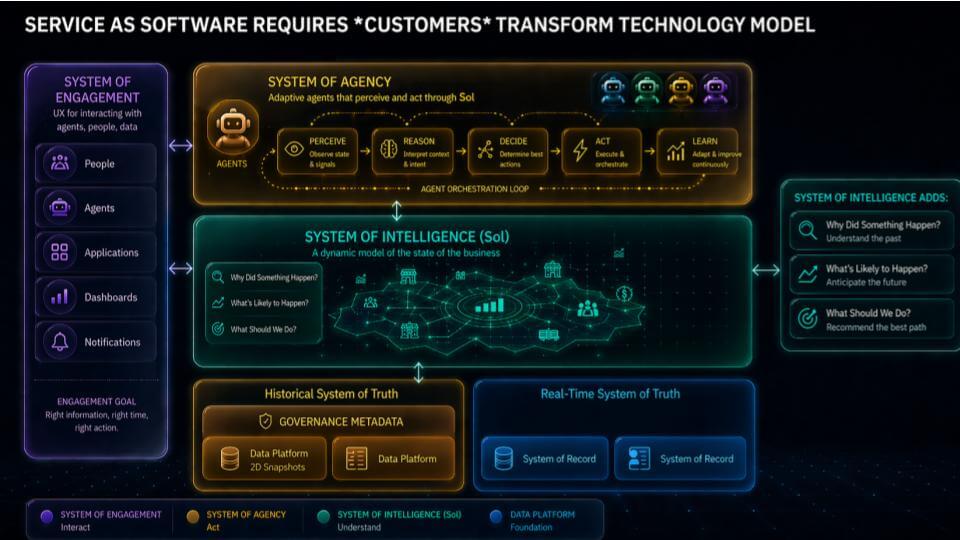
The shift underway now is broader. SaaS re-architecture primarily changed software companies and the IT function that consumed them. Service as software changes the entire enterprise. Any company can scale with less labor by embedding intelligence into workflows and delivering outcomes through software. Over time, that pushes more businesses toward platform economics – and the markets that reward platforms tend toward winner-take-most, with software-like marginal economics conferring competitive advantage to firms that lean in to AI.
Agents are the catalyst. Agents don’t unlock much value if they live inside silos. They add real value when they change business outcomes end-to-end. That’s the point of the middle part of the slide above – i.e. the System of Intelligence (SoI). Google introduced its knowledge catalog, which begins to unlock some of the capabilities of the SoI that we’ve previously described. The point is broader however in that this layer connects agents to the operational and analytic reality of the enterprise so they can perceive, reason, decide, act, and learn across the business, not inside a single department.
The main constraint we’re trying to resolve is shown at the bottom of the slide. For sixty years, enterprises built silos – analytic data silos, operational application silos, and then the organizational silos that formed around them. Each department ends up with its own applications and its own data stores. That structure is not designed for agents that need cross-functional context and permissions to drive outcomes like “compress the hire-to-onboard cycle,” “reduce quote-to-cash friction,” or “cut days out of incident response.” And do so with human language prompts that reimagine the entire workflow, rather than “pave the cowpath” by automating existing processes.
Key takeaways
- SaaS changed software vendors and IT – Service-as-Software changes entire enterprises as they scale with less labor and deliver outcomes through software;
- Agents create value when they operate across silos – not when they automate isolated tasks;
- The SoI becomes the enterprise “intelligence layer” – a knowledge/catalog-like control point that sits above systems of record and departmental data/app stacks.
Five stages of data platform maturity – the on-ramp to a digital twin
The slide below is the maturity path from departmental reporting to something that starts to resemble a digital twin of the enterprise – i.e. the real time digital representation of an organization. When we discuss this concept we often point out that historically in the data business, we think in terms of ‘strings’ that databases understand. Here we think differently – in terms of concepts that humans understand, like people, places, things and activities (e.g. processes).
We believe this represents a profound shift in software. The system of intelligence is an emerging layer and perhaps the most valuable piece of real estate in the emerging AI software stack. It can’t sit on top of a pile of disconnected metrics and dashboards (BI infrastructure). Rather it needs a substrate that models the business in a way agents can use – with enough context, timeliness, and consistency – to drive decisions and actions that are trusted and repeatable at scale.
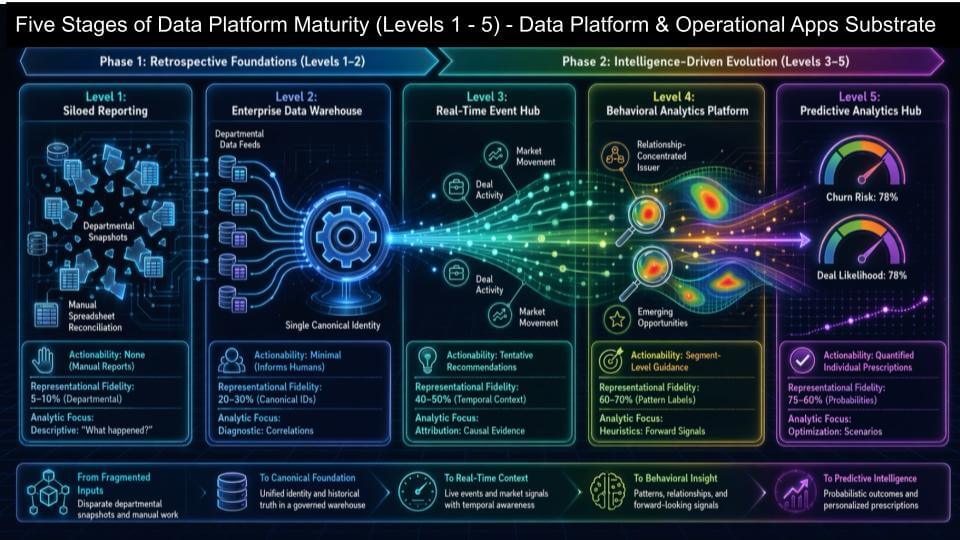
At the left edge of the chart, Level 1 is where most companies started – running reports against siloed operational applications. It’s mostly manual, mostly departmental, and there’s little self-service. Level 2 is where the modern data platform story took off – a BigQuery, Snowflake, or Databricks-style approach where teams standardize key metrics and dimensions to feed “cubes” from different applications. That improves self-service, but in practice the organization still behaves like departments with their own data and views of the truth.
Level 3 is the first real step toward modeling the business instead of just reporting on it. Real-time events start flowing from operational systems into the data platform, and the data platform enriches those events in return. The entities and the events start reinforcing each other, and that’s where “context” becomes something you can actually compute, not just describe.
Level 4 and Level 5 move into behavioral modeling and prediction. This is where products like Salesforce Data Cloud or SAP’s data cloud are headed – models of processes derived from their application footprints, with richer behavioral patterns and predictive signals. The important nuance is these don’t have to become walled gardens. Think of them as value-add layers that sit on top of today’s data platforms and increase fidelity and actionability.
The north star is the digital twin – a real-time digital representation of the enterprise that captures people, places, things, and activities/processes. That is the prerequisite for layering a system of intelligence on top and expecting agents to do more than automate small tasks.
Key takeaways
- Level 1 to Level 2 is reporting to self-service analytics – but still largely departmental;
- Level 3 adds real-time events and richer business modeling – entities and events enrich each other;
- Levels 4 and 5 introduce behavioral insight and prediction – as an overlay/value-add layer, not necessarily a walled garden;
- The end state is a digital twin of the enterprise – the substrate required for a system of intelligence and outcome-level agents.
Bridging Non-Deterministic and Deterministic – The Missing Step for Agents
We now move to the handoff that has to happen if agents are going to take action with confidence. The generative layer gives you creativity – e.g. tokens, language, synthesis, exploration. But enterprise action requires determinism – the rules, the guardrails, and the auditable trail that says what happened, why it happened, and what the system should do (and is allowed to do) next. In our view, this is the core bridge between non-deterministic intelligence on top – deterministic execution underneath – tied together tightly enough that you can trust the outcome.
The simplest way to think about it is goals and guardrails. Agents have goals – what they’re trying to accomplish – and guardrails – what they must do and the rules they must follow. These next stages are the deterministic layers that turn “smart” into “safe and operable” (see below).
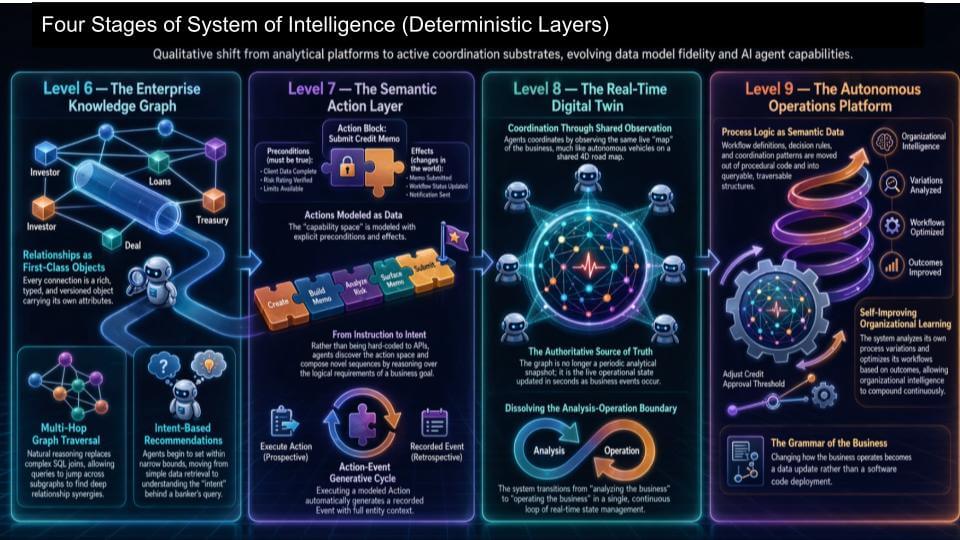
On this slide, the four stages take the maturity model from “analytics helping humans” to “systems coordinating work”:
- Level 6 – Enterprise Knowledge Graph: This is the relationship map– what we sometimes refer to as the 4D map of the enterprise. The example used here is financial services – a bond issuer, the bonds they’ve issued, and the investors who bought them. The point isn’t the bond example. The point is the enterprise needs first-class objects and relationships so agents can traverse reality, not spreadsheets.
- Level 7 – Semantic Action Layer: This is where actions get modeled. Guardrails get richer because you move from “the world as relationships” to “the world as actions with constraints.” This is the step where the enterprise starts expressing what can be done – under what conditions – and what must be true before and after an action.
- Level 8 – Real-Time Digital Twin: Levels 6 and 7 are still overlays – they refer back to underlying analytical state and operational systems. Level 8 is where the model becomes the source of truth. That’s the point where the legacy systems start getting unplugged. The digital twin is no longer a reporting layer – it’s the operational heartbeat.
- Level 9 – Autonomous Operations Platform: This is the far edge of the model. Workflow logic itself gets stored as data, which means the system can learn, optimize, and continuously improve. At that point the organization isn’t just running workflows – it’s refining and optimizing them.
One reason this is so important in our view is it answers the “how do you get there?” question that kept coming up. Specifically, the feedback from Geoffrey Moore when we first laid out service-as-software in a serious way – the idea is compelling, but enterprises need specific steps to get from point A to point B. The last two slides – the five stages of data platform maturity and these four deterministic stages – are the work that fills in that bridge. It’s also why, candidly, this has been iterative. We thought the model was “done” in January – then it got deeper, because the deterministic layers are where the hard problems live.
The bottom line – agents don’t dramatically accelerate value in silos. They compound value when they can navigate enterprise state, take actions under rules, and leave an audit trail. This is the bridge we see between generative output and governed execution.
The Full-Stack Digital Twin – Turning Rules Into Expertise
The slide below is the next step past the deterministic layers. The bottom stack – mapping plus rules – is the part that makes agents safe. It defines what’s allowed, what must be true, and how actions get executed without blowing up the business. But that only covers a slice of how companies actually operate. The bigger chunk is tacit knowledge – the stuff people call “tribal knowledge” – what experts do when the rules conflict, when the data is incomplete, and when the situation is ambiguous.
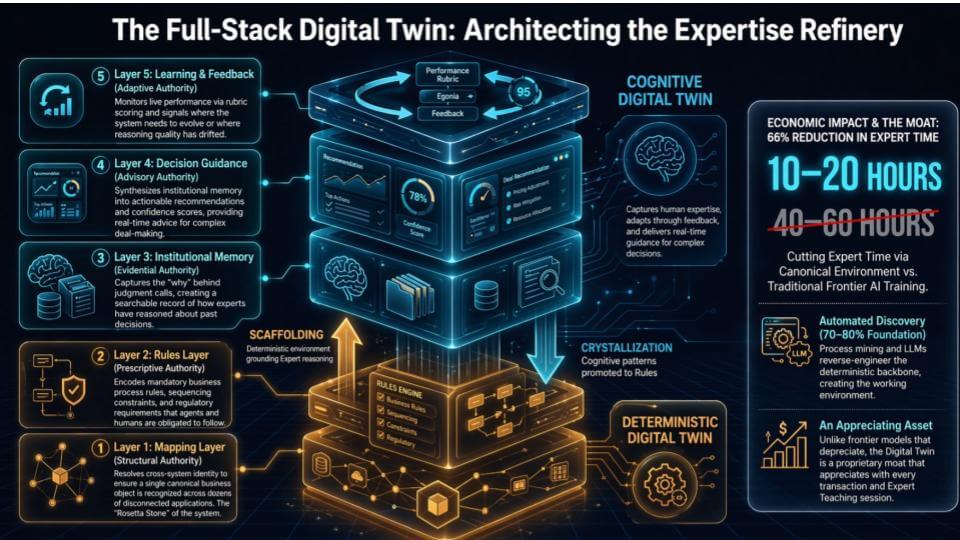
That’s why the slide above separates the deterministic digital twin (the orange/gold “scaffolding”) from the cognitive digital twin (the blue “crystallization”). The deterministic layer is the governed backbone. The cognitive layer is how the organization captures the “why” behind decisions and learns over time.
The viral “context graph” chatter that hit the VC and vendor community late last year was essentially about this problem. Context is what you reach for when deterministic logic breaks down. The logical workflow is:
- Agents run inside rules and mappings until they hit an exception;
- Exceptions go to humans – humans are in the loop;
- The system learns from the human’s reasoning traces – reinforcement learning turns those traces into improved performance over time;
- The system is penalized for wrong actions and rewarded for correct ones and that creates a flywheel effect where scaling laws kick in and outcomes can be operationalized.
The important nuance is you can’t cover the enterprise with deterministic rules alone. In the view laid out above, the rules are necessary, but they’re not the whole game. Most of how a company works lives in judgment calls, conflict resolution, prioritization, and experience. That’s the 90% problem.
The “gold standard” example cited here is a company called Mercor. The concept is that even if the implementation is difficult, an expert teaches their thinking process, teaches how to grade the reasoning process, and even teaches what wrong reasoning looks like. That “teach and grade” loop is the only reliable way to capture the why behind expert judgment. Other approaches try to do it cheaper because it’s less onerous on the expert, but they lose fidelity.
A simple way to explain the mechanics is punishment and reward – if the agent says one plus one equals three, it gets penalized; if it says one plus one equals two, it gets rewarded. Over time you get compounding behavior improvement. That’s the flywheel.
The key connection back to the earlier slide is that deterministic rules make tacit knowledge capture easier. When the rules are explicit, you narrow the surface area of ambiguity. Humans don’t have to explain everything, only the exceptions – and the system can learn faster because it knows exactly where the rules stopped being sufficient.
This is relevant for Google because the agent platform conversation is starting to show more maturity. It’s still early, but the steps are becoming clearer – and the deep dives this week at Google Cloud Next 2026 reinforced that the path forward isn’t just more capable models. That’s important but it’s the combination of deterministic scaffolding plus a systematic way to capture and refine expert judgment that represents state-of-the art today.
Bottom line – the deterministic twin makes agents safe. The cognitive twin makes them useful at scale. The compounding comes from tightly integrating the two together so exceptions become training data and expertise turns into an asset.
Mapping Google’s Data + AI Announcements to the System of Intelligence and System of Agency
We believe the most useful way to decode Google’s data and AI announcements is to strip away the product names – “knowledge catalog” and “agent platform” – and map the underlying capabilities to the layers that we described earlier in this research. Google’s terminology is a little inverted relative to ours. Google tends to talk about “system of intelligence” as the modern data stack and “system of action” as the new agent layer. Our view is different – the system of intelligence is the harmonization layer that makes action safe and repeatable, and it is what ultimately feeds the system of agency.
Understanding the different language and mapping Google’s parlance to ours at the functional level helps to highlight both progress and gaps.
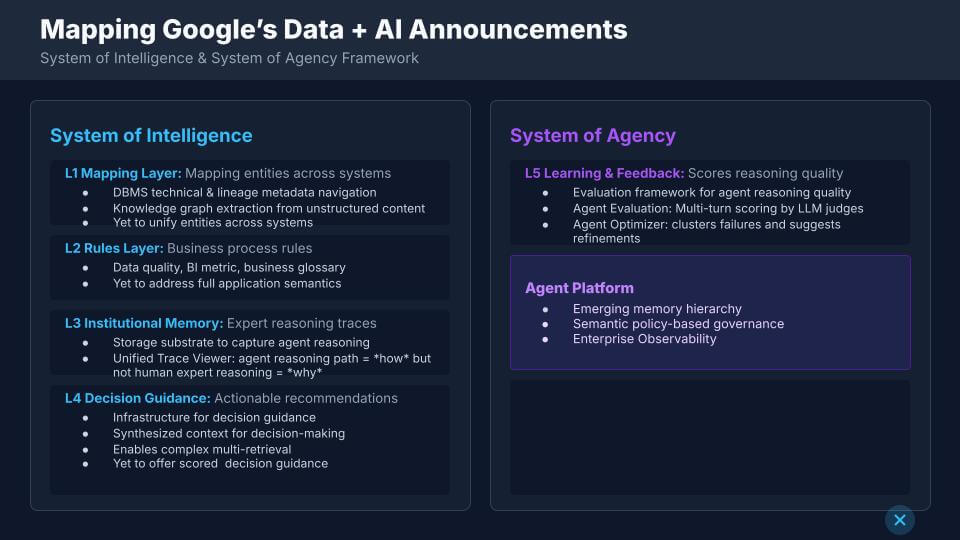
System of Intelligence – what Google has, and what’s still missing
Level 1 – Mapping layer (entities and lineage)
Google is doing real work extracting DBMS technical metadata and lineage. It is also pulling unstructured, document-oriented tacit knowledge into a knowledge graph – and we acknowledge that’s advanced. The shortfall is unification. Google can extract entities, but it does not yet unify those entities across systems into a single, authoritative reference. Customer shows up in many places. Resolving “customer” across all those systems remains the hard part. At least this is our current understanding of where Google is at.
A practical way to say this, as we said earlier, is databases store strings – the knowledge graph wants to speak in things people understand. The move from strings to things – and then from things to activities and processes – is where the big value realization happens, and it’s also where the work gets hard.
Level 2 – Rules layer (from dimensional semantics to application semantics)
Google’s catalog captures data quality rules, BI metrics, and business glossary content – dimensional semantics. That’s useful, but it stops short of full application semantics – the business process rules that are entangled and entombed inside legacy application silos. This is the layer where Palantir often comes up as a reference point for our work – not because it covers everything, but because it shows what “process rules as data” looks like when you go deep. We believe Google wants to cover a lot more ground than Palantir can cover at its pace and within its constrained domain- but that doesn’t make the step any easier. Nor does it mean that Palantir (and it’s CEO Alex Karp) doesn’t have ambitions to broaden its scope.
Level 3 – Institutional memory (how vs. why)
Google has the substrate to capture agent reasoning and store it. The unified trace viewer (Trace Explorer inside of Google Cloud Trace) is a real step because it shows how an agent got to an outcome. That is not the same as capturing human expert reasoning – i.e. the why – which is what drives judgment and confidence. It’s a nuanced gap, but it’s the difference between replaying a path and learning a decision system that can be trusted.
Level 4 – Decision guidance (context synthesis, confidence still thin)
Google can synthesize context and enable complex multi-retrieval. That allows an agent to retrieve more relevant material and make a judgment. The missing piece is confident, scored guidance from the system of intelligence itself – the ability to say “here’s what to do and here’s our confidence score,” grounded in a library of human-grade “why” and in process-aware semantics. Without the “why,” the system can feel closer to static institutional memory than decision guidance.
System of Agency – the learning loop is the tell
On the system of agency side, the key requirement is the learning loop – every layer needs feedback. Agents do work, get scored, get reinforced, and then you accelerate value. This is where Google’s agent evaluation and optimization work is important in our view.
- Agent evaluation is multi-turn scoring – evaluating the full chain, not just a single request/response. That’s closer to how real work happens;
- Agent optimizer looks across clusters of failures and suggests refinements. That stood out because it’s the first time this starts to feel like “agent ops,” not just agent demos. Databricks showed something similar last year, and it left a mark because it turns failures into a roadmap for improvement.
Why this mapping is relevant in the field
We heard a consistent theme from customers in that there is real excitement, but it’s still early for most of them when you push past Thomas Kurian’s keynote narrative – i.e. “in the past year we didn’t just see adoption, we saw transformation.” Skilled employees are being redeployed toward building, deploying and managing agents – that’s where a lot of the near-term “productivity gain” is going. In other words, the productivity story is increasingly coming from the work of creating agentic capability, not just consuming it. So in that sense Kurian’s proclamation holds water. But this is still an elusive reality for the vast majority of enterprises.
This also explains why Palantir keeps coming up in these conversations. Palantir’s forward deployed engineers (FDEs) effectively did this work for customers – building the deterministic foundation (mapping plus rules/ontology) and then layering action on top of it. That deterministic foundation is what makes action safe. The open question is how quickly the broader market can build that foundation without needing an army of specialists – and how quickly Google can industrialize the “why,” not just the “how,” so agents can act with confidence.
Bottom line – Google is putting credible pieces on the chess board – e.g. lineage + metadata extraction, a graph-oriented approach to unstructured knowledge, multi-turn agent evaluation, and failure clustering via optimizer. But gaps exist – e.g. unifying entities across systems, moving from dimensional semantics into real process semantics, and capturing the human “why” so decision guidance becomes confident, scored, and repeatable.
This is work that remains.
Coding Agents as the On-Ramp to Universal Agents and Why Google’s Platform Push
The agent platform discussion has centered around coding. The market is converging on the increasingly obvious fact that to build a universal knowledge-work agent, you start with the coding agent, because the way agents interact with the world is through tools – and tool use increasingly means writing code to call those tools. That’s why Anthropic leaned into coding first and why the coding stack is now the battleground across the frontier model vendors.
We see the competitive pressure showing up in many places. Anthropic’s Claude Code is gaining massive traction, OpenAI is pushing Codex, Grok has to have a credible coding agent capability to be competitive as a frontier model, and Google is taking a different route by building an enterprise agent platform that tries to turn the “harness” into something broader. The news around Elon having an option to buy Cursor underscores the point – if you don’t have a first-class coding agent story, you fall behind quickly.
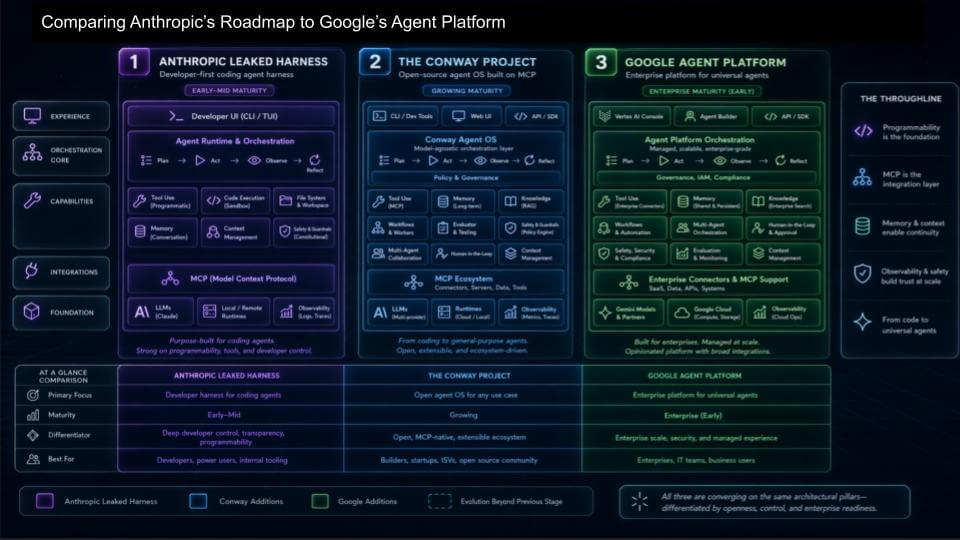
In the simplest terms, the progression on the slide above is:
- Start with a coding harness – get the coding agent right;
- Evolve toward an agent OS/platform built on MCP – with proprietary extensions (memory, observability, developer controls);
- Expand into an enterprise agent platform – where governance, identity, memory, and tool/action policy become first-class.
Anthropic’s early advantage is that “coding first” path is the fastest way into general-purpose agent behavior. The harness gives developers a high-control environment – UI/CLI, orchestration, tool use, context management – and it becomes the training ground for what later turns into broader knowledge-work agents. Their Conway work is the logical next step – an attempt to assemble a fuller platform on top of MCP, with proprietary extensions and enterprise features that go beyond pure coding.
Google’s push is different. It’s trying to build the enterprise control plane for agents – and it has some things the frontier labs can’t easily deliver on their own, at least not yet, even if the frontier labs carve off pieces of the platform experience and live inside enterprise stacks.
Three practical differences stand out to us:
- Governance and agent identity – Identity used to be “the agent acts as the user.” That’s insufficient when agents do work on their own – and when agents act on behalf of other agents. The security model has to evolve from purely resource-based controls (what data you can touch) to intent-based controls (given this context, what action is allowed). The enterprise needs policies that are enforceable at runtime, not just checked at login.
- Memory that doesn’t become a new silo – If enterprises allow memory to get trapped inside a vendor’s proprietary stack, switching costs explode and the organization recreates silos – only now the silos are agent-shaped. The memory model has to be shared, governed, and harmonized. Some personal preference can stay local, but procedural memory – how work gets done – has to be accessible across agents and people or coordination breaks down.
- Unifying the data and action space – Tools and actions on one side, memory and data on the other – when those unify, the result becomes a semantically harmonized knowledge graph. We see this as the path to an enterprise digital twin – a digital representation of the enterprise that agents can act on with confidence.
Net-net, we believe the frontier labs are going to keep pushing hard on coding agents because it is the fastest path to credible tool use. Google’s advantage comes from turning that into an enterprise-ready platform layer – governance, agent identity, intent-based policy, and shared memory – so customers don’t end up with a new generation of silos and lock-in disguised as “agent progress.” Work remains for Google and others but the direction is becoming clearer in our view.
Google Cloud Next 2026 – Pole Position, New Battlegrounds, and the OEM Question
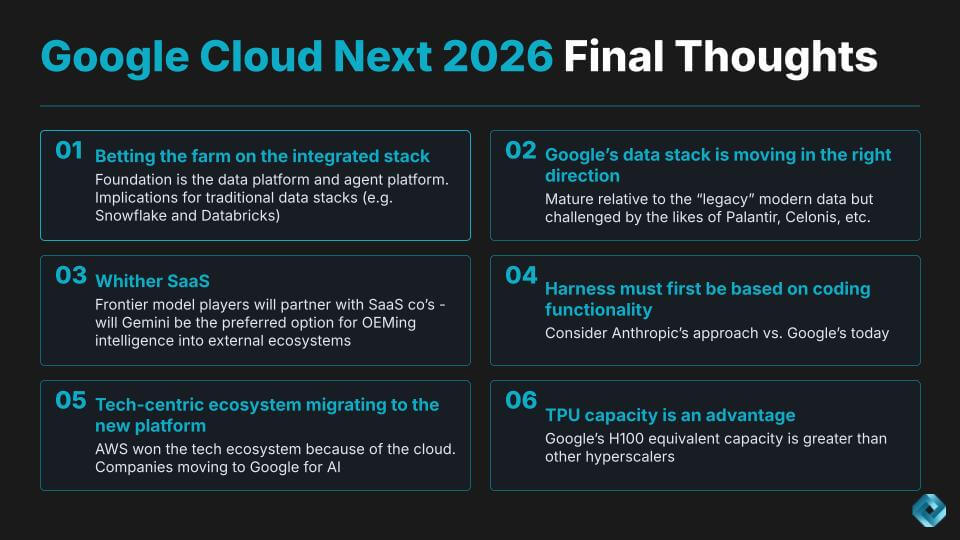
Google is betting the farm on an integrated stack – TPU, frontier model, data platform, agent platform and applications as one cohesive system. That’s Google’s differentiation. In our view it’s directionally right, and it also pulls Google into new territory where the winners will be decided by adoption, operating leverage, and the ability to turn “context” into “action” without breaking security boundaries. We see Google as having a strong technical story here but its vision statement to businesses could be framed in more “wallet” than technical terms.
This brings an interesting question for the likes of Snowflake and Databricks. Those two are climbing “up” from the read path – give me context from the data platform – and then stretching toward richer context. The question is what happens once they’ve read and reasoned, how do they operationalize the decision the agent makes? That’s where action becomes the differentiator, and it’s why coding capability matters so much as the starting point for agent maturity. If the agent can’t reliably execute, then all that context is just analysis theater.
Google is moving in the right direction – but it’s also crossing into the arena occupied by Palantir and Celonis, and even the integration layer that vendors like MuleSoft helped define. We see this as the hard part. Specifically harmonization across operational systems, data systems, and workflows – with enterprise-grade governance. This is where we believe our “system of intelligence” has to emerge as a real product layer – irrespective of what Google calls it.
A few takeaways from this:
- The integrated stack is Google’s edge – and the constraint. Google can bring more capabilities than most players. But once customers demand cross-app harmonization, the competitive options expand fast – Palantir, Celonis, Salesforce, ServiceNow, and others all have designs on that layer. Google will partner with these firms but the next bullet is important.
- “Wither SaaS” hinges on OEM mechanics and trust boundaries. Frontier model players will partner with SaaS companies – the open question is whose model becomes the preferred OEM option. Gemini has a positioning advantage inside Google’s footprint. The issue is what happens when the SaaS OEM is not running on Google Cloud. If the data has to leave the SaaS vendor’s security perimeter to use Gemini because Gemini runs in Google, that becomes a point of friction – and we’ve seen how sensitive enterprises are to that boundary.
- Coding harness first – because action is the new standard. The market is telling us that coding is the onramp to agent credibility – Claude Code and Codex have made that obvious. Google’s approach is to embed coding throughout the platform, not treat it as a separate product. We agree that’s a viable architecture – but the point is it has to be fully integrated into the agent platform to be most effective. If the harness is adjacent rather than native, it becomes a gap competitors can exploit.
- The ecosystem flywheel is shifting – and Google is benefiting. AWS won the early cloud era by attracting startups and tech-centric organizations into an innovation flywheel. We see a similar dynamic developing in AI – teams that want to be best at AI are gravitating toward Google, and that ecosystem migration is critical. Microsoft remains ubiquitous, and AWS will fight hard, but the AI-native cohort is a real tailwind for Google.
- TPU capacity is a strategic advantage – even if NVIDIA remains the reference model. Google is one of the few players with real depth in custom acceleration. That gives it leverage on supply and cost. But we would still expect serious customers to want NVIDIA in the mix – because the ecosystem and the low-cost curve are still being set there. We’ll add a bonus slide to this topic next.
Bottom line – Google looks like it’s taking pole position in the agent platform conversation because it can bring the full stack and because its data platform has been doing the yeoman’s work for years. The work that remains is the hard part – i.e. turning “read context” into “take action,” building the harmonization layer at enterprise scale, and solving the OEM/perimeter problem so Gemini can be consumed where the data lives, not only where Google runs.
TPU 8 and the “GPU Rich” Advantage
We open and close on the same topic – TPU. The last point is the one that changes the tone of the whole week – Google’s TPU capacity gives it a structural advantage in AI compute, and it will show up in product velocity.
The Epoch AI chart on “H100 equivalent” capacity below suggests Google has more AI compute than any other cloud, driven largely by TPUs – a brute-force approach compared to Nvidia, but one that lets Google control its own destiny on supply and deployment.
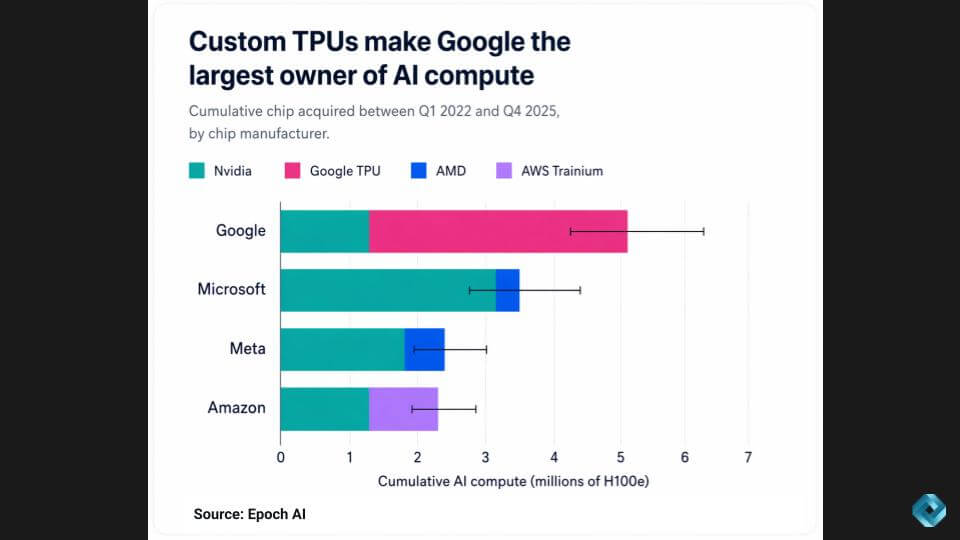
This ties to a concept raised on the Latent Space podcast – “GPU rich” vs. “GPU poor.” Google looks “GPU rich,” which helps explain why Gen AI and agents are showing up broadly across its product line. Microsoft, by contrast, looks “GPU poor” in this slide – which helps explain prioritization decisions (Office first), uneven rollout of Gen AI enablement across Azure services, and the downstream pressure it has created elsewhere in the stack.
There’s a separate point that needs to be said – none of this is “TPUs are eroding NVIDIA’s moat.” The demand for accelerated compute is so large that quality accelerators will sell, in a large part because NVIDIA can’t satisfy all demand. Google will use TPUs primarily to power its own services – not as a merchant silicon vendor.
A few takeaways to anchor this analysis:
- TPU capacity should translate into feature velocity – Google can “put agents everywhere” because it has the compute headroom to do it;
- Microsoft’s AI posture benefits materially from the OpenAI relationship and NVIDIA allocation, but the tradeoffs show up in product prioritization and cloud services cadence;
- Amazon’s position looks different – Trainium (and the consolidation of Inferentia into that roadmap) is real, but Google appears to be separating with its annual cadence and platform consistency.
- NVIDIA remains the volume leader and CUDA remains the dominant development environment – the “bundle” strategy (CPU + GPU + networking + system-level architecture) raises the bar for everyone.
Net-net, we believe Google’s TPU advantage is less about claiming an “NVIDIA alternative” and more about enabling Google’s own stack to move faster – especially at the software layer, where capacity becomes the difference between selective enablement and pervasive agent rollout.
Action Items for CIOs, CTOs, and AI Architects
In the next 30–60 days, run a structured “agent platform bake-off” with Google, AWS and Azure in the mix. Force it into a synthetic production workflow that crosses multiple systems (not a demo). Pick one high-value, end-to-end process, tie it to your actual data and policies, put Apache Iceberg in the mix and score it on the things like security/auditability, semantic consistency across systems, time-to-value, and the operational requirements to keep it running.
Your goal should be to answer the following question with proof: can Google’s integrated stack (data platform + agent platform + control plane) become the governed layer your agents run through, or does it remain a strong set of parts that still requires too much custom glue? If it clears that hurdle, we would advise going deeper with Google; if it doesn’t, treat it as tactical capability. Regardless, for now, keep your control-plane strategy vendor-neutral until the business value clarity dramatically outweighs lock-in risk.


