
Machine learning (ML) applications don’t have to be the province of hard-to-find data scientists working on esoteric, custom applications. SaaS-delivered ML applications can hide the data science behind traditional and well-understood GUI’s and API’s. Of six core tasks to manage a machine learning application, enterprises need to focus on three one-time tasks to bootstrap the application.
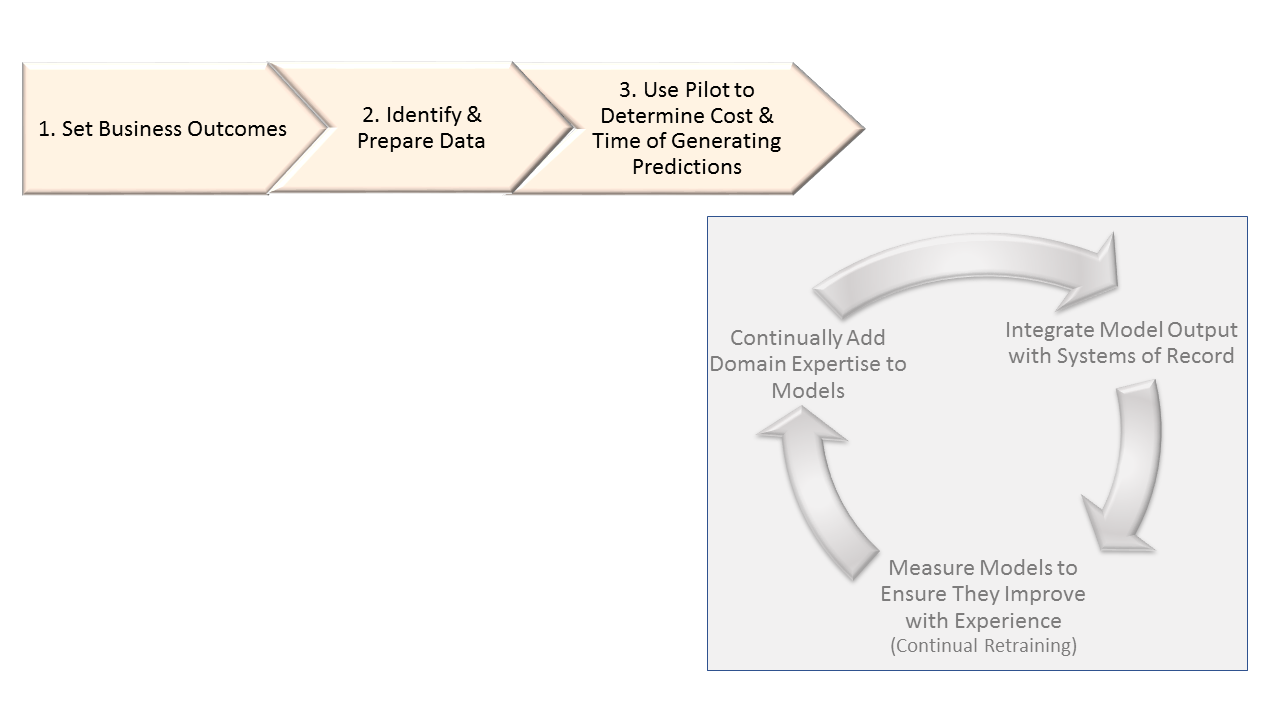
Enterprises looking to start applying machine learning technologies to high-value business problems can avoid the bottlenecks of staffing a data science department and creating custom applications. How? By using packaged ML applications. The output of an ML application is a set of predictions that can serve to guide activity, such as prioritizing special offers to the customers most likely to drop their subscriptions to a service. ML applications typically complement legacy applications’ focus on operational efficiency by driving improvements in revenues and profits. The following steps are the recipe for one-time tasks required to get started with a generic ML app (see Figure 1 for an illustration of how the initial steps work in sequence).
- Start by setting desired business outcomes. ML applications need sponsorship from a C-level executive with P&L responsibility because only they can define strategic objectives and any trade-offs between them, such as profitability relative to growth.
- Based on the desired outcomes, identify and prepare the necessary data. The ML application vendor usually specifies the required inputs, but customers will typically have to inventory, cleanse, and enrich data from multiple Systems of Record to bring it all together.
- Use pilot deployments to determine the time and cost of generating predictions in batch processing. Generating the output in the form of predictions with the appropriate accuracy can consume a lot of time and compute resources. Customers need to find the right balance between cost, precision, and timeliness when determining SLA’s.
Start by setting desired business outcomes.
ML apps’ most basic output is predictions, which good ML apps can perform at a very granular level. Predictions shouldn’t exist in a vacuum. Unlike sprawling, horizontal legacy systems of record, the granular predictions from emerging ML apps typically map directly to business outcomes. For example, a supply chain application can predict how much of a product will sell in each store each day. These predictions enable the application to recommend what to stock in each distribution center and each store and how much to order from suppliers based on predicted demand at a given retail price.
Since the ultimate output of these ML applications maps so clearly to business outcomes, replenishment orders in our example, selection and evaluation of a packaged application should be faster and less risky than with traditional systems of record. Big data pro’s, senior management, and line-of-business (LOB) managers can see exactly how the application will map to their objectives at the start of the evaluation process. All constituents can accelerate through steps that would otherwise be time consuming and uncertain with custom development: 1) engaging in large-scale analytics projects that create shared-service platforms divorced from concrete problems or 2) conducting proofs-of-concept not connected to high-value problems.
Identify and prepare the necessary data based on the desired outcomes.
Packaged ML apps are very specific in identifying exactly what data they need as inputs in order to make their predictions. Taking the replenishment planning application again, the outputs are recommended quantities to order for each product and how much to stock at each location. Every night the user of the application has to upload a file with the same inputs, including pricing, promotions, current inventory, packaging units, and minimum order quantities, among other items.
Going with a packaged ML application enables project teams to avoid much of the uncertainty of creating a data strategy from scratch. Starting a data strategy from scratch requires big data pro’s, senior management, and LOB managers to agree on what business goals they want to achieve. Given the goals, big data pro’s have to prototype an ML app using different predictive models and different sets of inputs (the inputs are called features of the predictive model). The prototyping process determines if the team has the right the model; has access to the necessary data inputs; and whether the predictions can deliver the desired outcomes, such as fewer stock-outs or markdowns in our replenishment example. Using a packaged application short-circuits the substantial time and risk in that process.
Use pilot deployments to determine the time and cost of generating predictions.
Model scoring drives predictions. Scores are usually an intermediate form of output because they form a spectrum of values that indicate probabilities of an outcome. The customer typically decides when a score is high or low enough to become a prediction for a certain business outcome. For example, any prediction between 75 and 100 might indicate a consumer is likely to churn their subscription to a cable TV service.
ML applications can generate their predictions in real-time or batch mode. Real-time predictions have to support the most time-sensitive applications, such as credit card authorization. Real-time predictions’ compute requirements are typically far more intensive than generating them in batch mode. For our example application here, we’ll focus on batch mode. Batch mode predictions might be good enough to generate daily stocking orders for grocery stores. But even though batch mode predictions can happen offline, enterprises must still make sure they fit into a batch window, just as they would with nightly reporting, for example. A grocer with hundreds of stores and tens of thousands of products preparing a 21 day forecast each night has to generate hundreds of millions of predictions (stores x products x days). The volume of predictions and their accuracy determines the compute resources required to create the predictions. This prediction process can be enormously time consuming and expensive. The vendor and the customer have to balance cost, accuracy, and the time window available to complete the process. Typically a model’s accuracy translates into greater sophistication and the need for greater time or compute resources. A critical part of the pilot process is determining the time and cost of this prediction process.
Action item
Customers no longer need to have a staff of data scientists and a team of custom application developers to get started with machine learning. That was a myth propagated by consultants that was true only for a certain point in time. Customers can improve their readiness to absorb an ever-growing class of ML applications by working through the steps in this recipe one application at a time.


