
Premise
A New class of applications: Systems of Intelligence will define emergent application activity that enterprises will be building or buying for at least the next decade. Historically, organizations have built and run on so-called Systems of Record. Increasingly, organizations will focus on analyzing data to anticipate and influence customer interactions. Notably, this is not a one-time event as organizations must continually improve by learning from, enriching and improving data, resulting insights and ultimately actions.
A greater focus on data and analytics will place pressure on the historical practice of primarily using a SQL DBMS for all data management. New applications will have a much greater need for specialized data management and analysis functionality. As such, while there are several different approaches to addressing this transformation, new skills must evolve to effectively implement and operate these systems.
This research note first looks at how the underpinnings of Systems of Intelligence are different from Systems of Record. We will then explain the trade-offs where each will likely find its sweet spot in terms of customer types and use cases.
Executive Summary
Systems of Record standardized the processing of business transactions. The new Systems of Intelligence are about anticipating and influencing customers in real-time. That means an entirely new data platform has to support them. The venerable SQL DBMS needs complementary functionality.
First, Systems of Intelligence are organized around data about customer interactions and related observations. So data preparation tools are much more important. Practitioners face a trade-off between specialized, best-of-breed tools such as Tamr for collecting, cleaning, and integrating many data sources at one end of the spectrum. The other end is products such as Pentaho that can track data lineage because they manage the entire lifecycle from the collection and integration through discovery and visualization, business intelligence, and predictive analytics.
Second, the analytic data pipeline needs to undergo radical transformation. The old practice of batch migration to a data warehouse for historical reporting now needs real-time predictive analytics served up during the transaction in real-time.
Real-time actually belongs on a spectrum for practitioners to choose and it happens on three levels. The first level is looking up a prediction of a customer’s propensity to buy a related product, for example. The second level is how recently that prediction gets updated. Incorporating the customer’s real-time clickstream activity ensures greater accuracy, for example. The third level actually updates the model that calculates those predictions in the first two cases, typically using their outcomes as feedback plus new data, potentially.
Third, practitioners have to choose the data platform upon which to build these apps. Here, too, there is a spectrum with trade-offs. They range from the greatest specialization and innovation across the entire big data ecosystem at one end of the spectrum. The other end of the spectrum goes through the Hadoop ecosystem to the integrated data platforms managed by Azure, Amazon AWS, IBM Bluemix, and Google Cloud Platform. They put the burden of developing, integrating, testing, and operating the platform on the vendors.
Wikibon’s recommendation to clients is that on data preparation and the data platform trade-offs, choices should be made on skillsets. The greater the integration, the lower the demand for highly specialized skills and the lower the administrative and developer complexity. The choice of where on the real-time spectrum is an application-specific one that is independent of skills.
The key defining attributes of Systems of Intelligence vs. Systems of Record
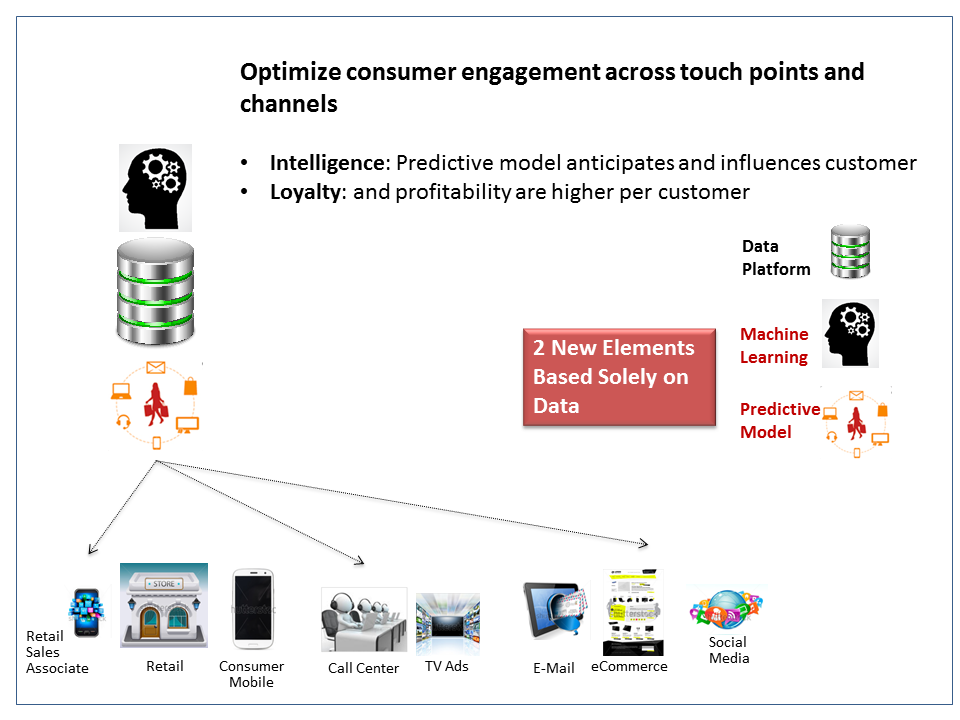
Figure 1: Systems of Intelligence use data about customers and their interactions to get smarter about anticipating and influencing them
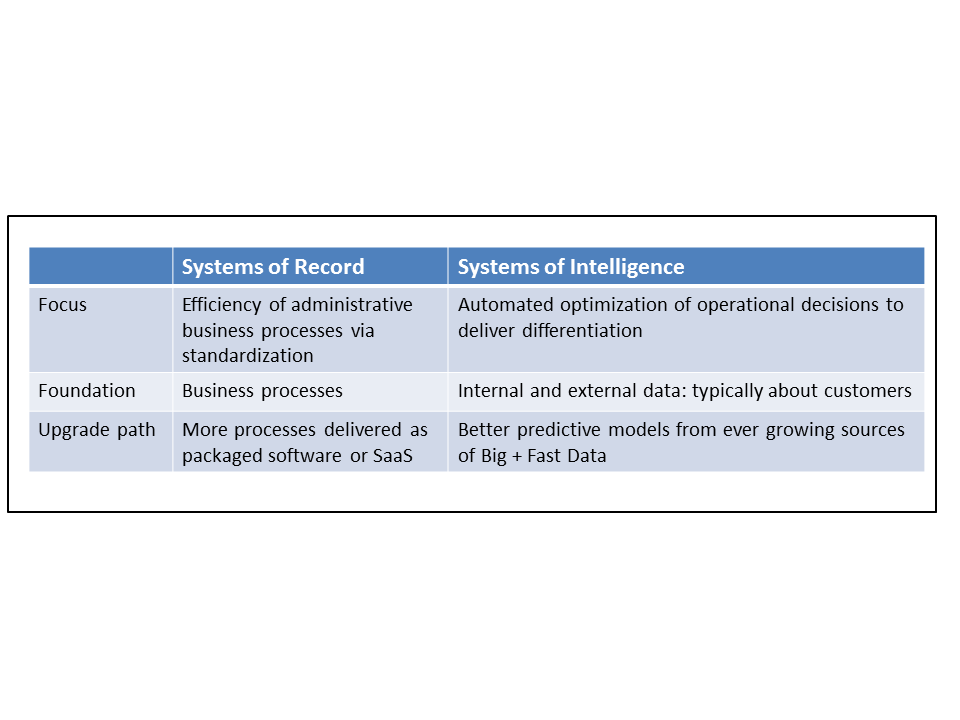
Figure 2: Starting at the highest level, Systems of Record and Systems of Intelligence are focused on different objectives
Data has always been more important than the technology platform of an application. But with Systems of Intelligence, that relative importance grows exponentially. With Systems of Record, standardized business transactions and the business processes they powered gave enterprises visibility into operations.
With Systems of Intelligence, applications can never have enough data, whether from internal, external or syndicated sources. It is the lifeblood of the machine learning process. This process continually improves the predictive model that anticipates and influences customer interactions.
Comparing the data and DBMS foundations of Systems of Record and Systems of Intelligence
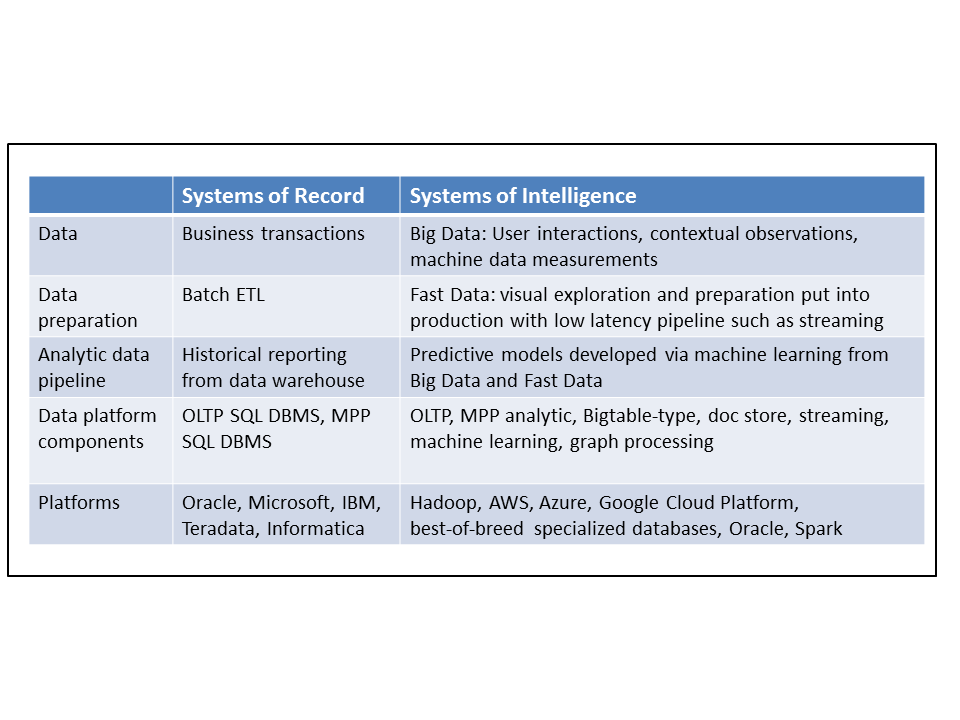
Figure 3: High level comparison of the data and technology layers of Systems of Record and Systems of Intelligence
Data and data preparation
The divergence in technical foundations between the two types of systems is clear when you just start looking at the data they manage. The data about interactions and observations is far greater in volume and variety than transaction data. Practitioners need to understand up front that the process of preparing that data to go through the analytic data pipeline is currently far more sophisticated with Systems of Intelligence. It involves more sources, more cleaning, and far more math in understanding the features in the data.
Analytic data pipeline
Once the we get down to the more software-intensive layers, the gap between the innovative technology in Systems of Intelligence relative to the mature technology in Systems of Record grows even wider. Predictive modeling based on machine learning from an ever-growing array of data sources is the focus on an expanding body of basic research and derivative commercial development. That array of development means practitioners will face many choices and need to understand trade-offs in different approaches. By contrast, business intelligence and reporting are going through sustaining innovation. They are mostly dealing with more data and greater performance demands once the data gets into the warehouse.
Data platform components
When we get to the layer of the data platform components, the differences between old and new systems require practitioners to evaluate products in a host of new product categories. Systems of Record ran on SQL DBMS’s in two configurations, one for OLTP and one for data warehousing. Now, there needs to be a large range of specialized, new functionality:
- Operational database, such as HBase or Cassandra, or a traditional OLTP SQL database;
- MPP analytic database such as Greenplum or Vertica that can support both data scientists as well as business analysts;
- Document store that is actually better understood as a database that serves JSON-based UI’s to mobile and Web clients;
- Stream processor that can analyze data arriving in real-time;
- Graph processor that can make sense of data that has lots of relationships, such as recommending a product based on a combination of other products with similar attributes and a likes from a set of people with similar attributes as the user;
- Machine learning and the processes it drives play an important role, so we’ll review its evolution in greater detail below.
Data platforms
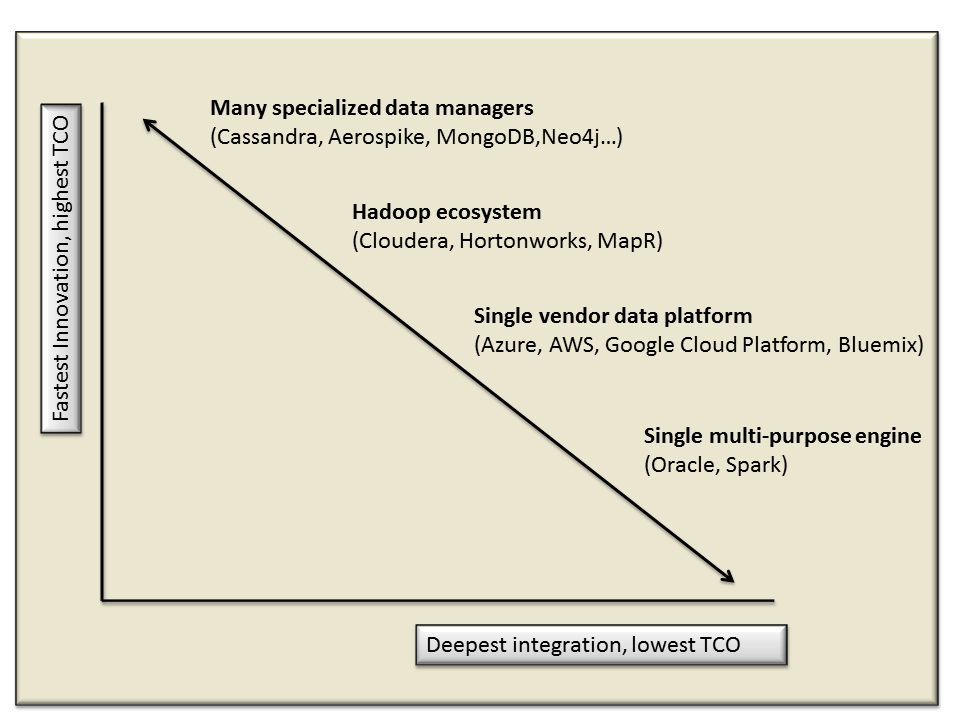
Figure 4: Data platforms organize the specialized data management functionality. They exist on a spectrum that goes from greatest innovation and its associated complexity on one end to deepest integration and greatest simplicity on the other end.
Finally, there are several ways to fulfill the need for the specialized data management functionality in the new systems. They exist on a spectrum starting from greatest specialization and speed of evolution and progress to ever greater integration and simplicity:
- Best-of-breed specialized products from an ecosystem that includes hundreds
- Hadoop ecosystem
- Cloud platform vendors including Azure, Google, and Amazon AWS, and IBM Bluemix
- Multi-purpose integrated engines, including Spark as analytic operating system and Oracle’s DBMS
Section 1
Data and data preparation: Systems of Record vs. Systems of Intelligence
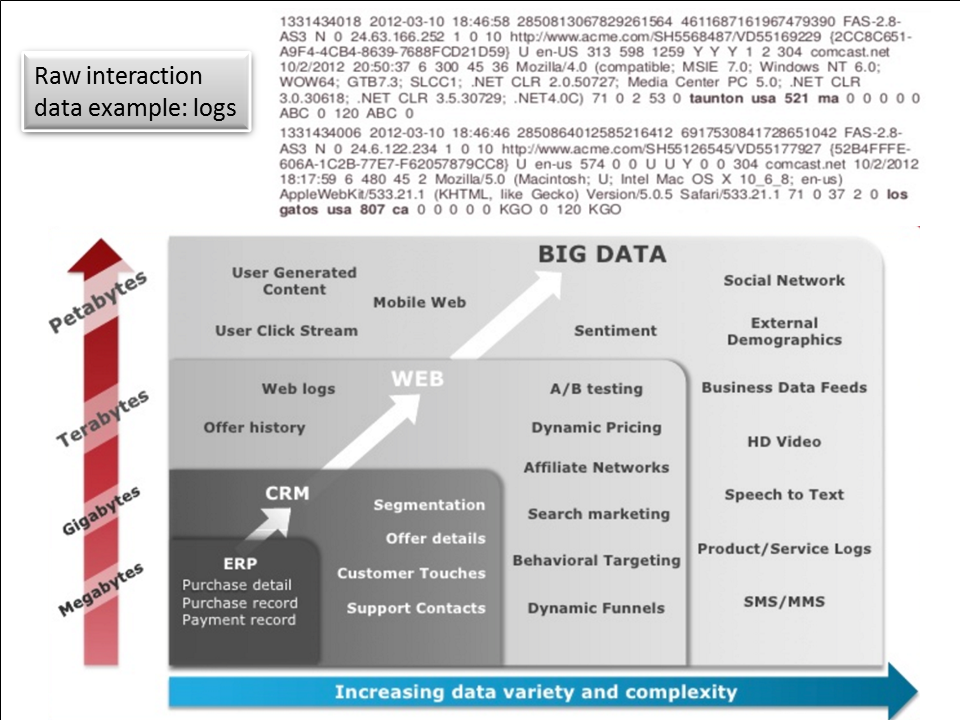
Figure 5: a look at example data about interactions and observations. The first part shows raw log entries. These need new DBMS technology for several reasons including growing volume and less structure.
Source: Teradata Aster
Everyone already knows about the differences in volume, variety, and velocity of data. Figure X above does a good job of putting a framework around example data sources. But peeling back another layer shows how different the data is and why it needs a completely different data management platform.
The example of the raw log data at the top of Figure X reveals several characteristics in the data that are different from business transactions. First, deriving its structure typically requires a human to read it in order to make the preparation repeatable. Second, this type of data doesn’t need sophisticated ACID transactions that are one of the core features of a SQL DBMS. Log data just gets collected. It typically doesn’t participate in updates with potential conflicts. Third, the structure of the data keeps evolving. Applications evolve to capture more information in each interaction, they can capture new interactions, and they can collect more data about observations of what’s going on around the consumer. Newer databases make it easier to work with data whose structure is evolving. Traditional SQL DBMS’s do have some capability to handle data with evolving structure, but it’s not their sweet spot.
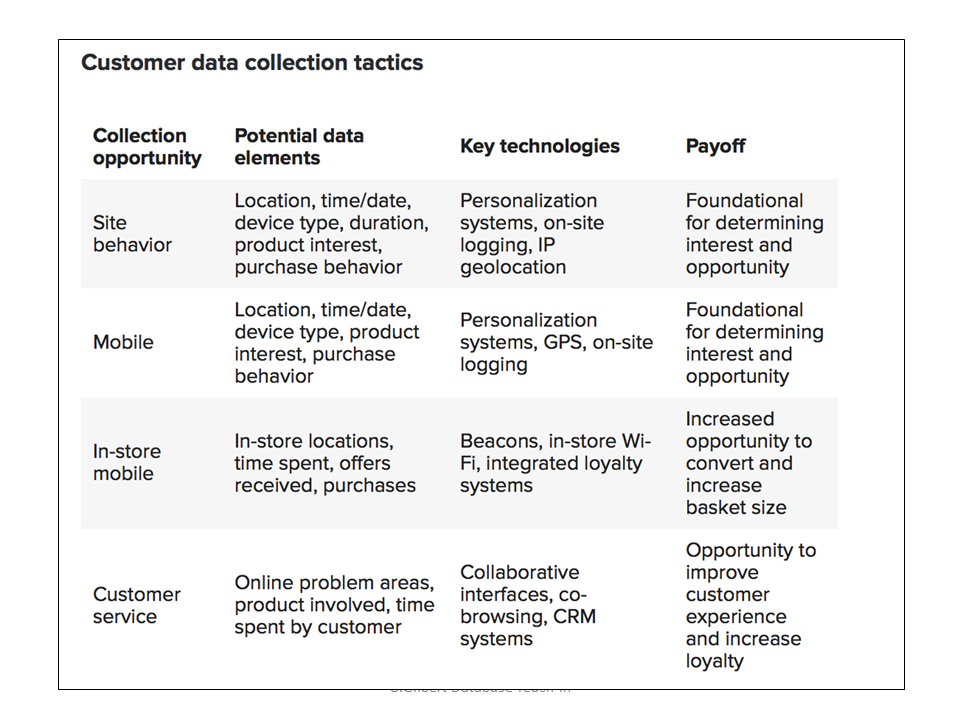
Figure 6: Example of interaction and observation data
Source: Gigaom Research
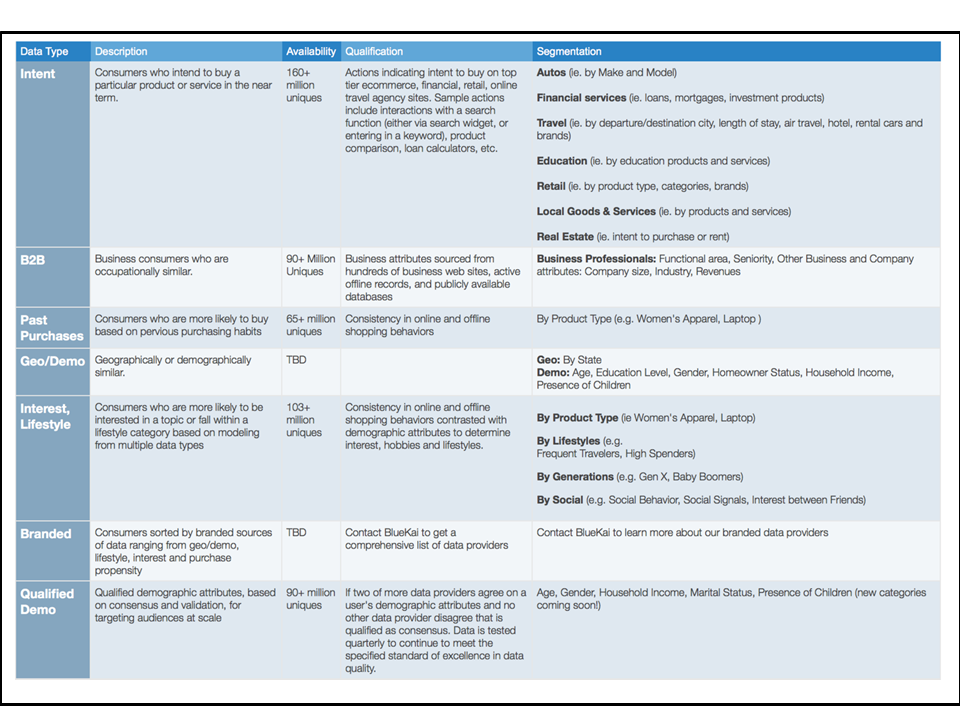
Figure 7: An example of very rich customer profile data that can be syndicated to enrich profiles developed on internal data
Source: Oracle BlueKai
Figure X above shows just how many more collection points and strategies are emerging for developers to consider when building applications. Figure X below that shows how enrichment options via syndicated data can add even more value.
The key take-away is that the customer profile in Systems of Intelligence are so much richer than the last generation that they are unrecognizable. Enterprises can never finish gathering and refining the new customer profile.
Data preparation and the analytic data pipeline: Batch ETL and historical reporting in DW vs. Fast Data feeding a predictive model
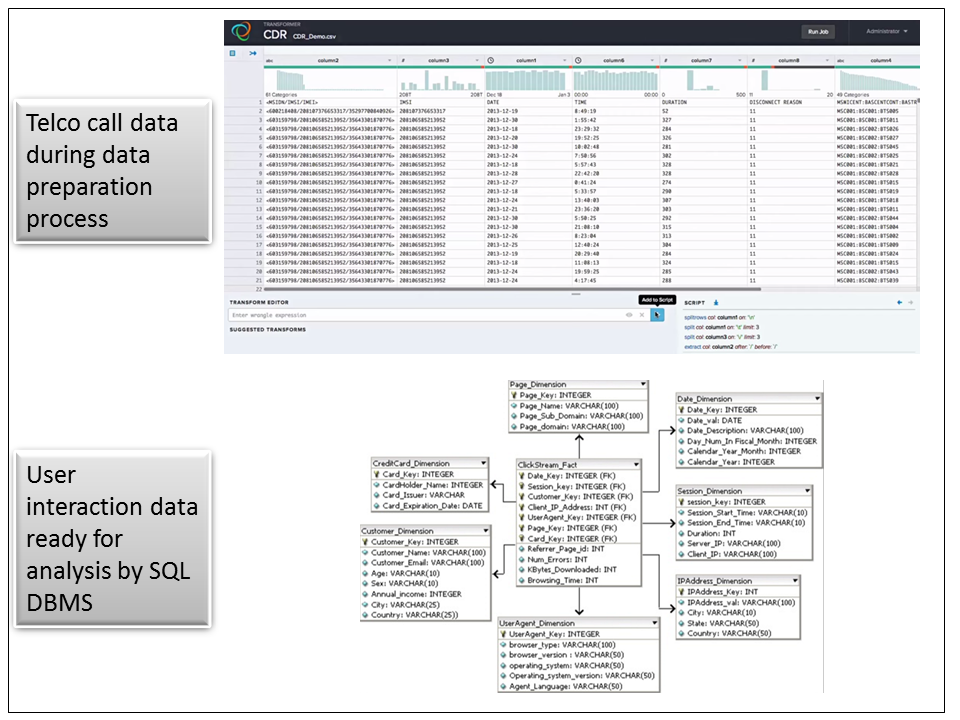
Figure 8: An example in the top half of data preparation that starts with extracting the fields in telco call detail records, their version of log files. In the bottom half is a diagram of what the data looks like when it’s ready for reporting and business intelligence in a SQL data warehouse.
Top figure is from Trifacta
Data preparation is one of the areas where the big data revolution began. The tremendous new variety and evolving structure of data meant that traditional ETL had to evolve. The telco example above shows a more traditional example of machine log data that gets parsed and cleansed in order to fit the structure a SQL data warehouse needs.
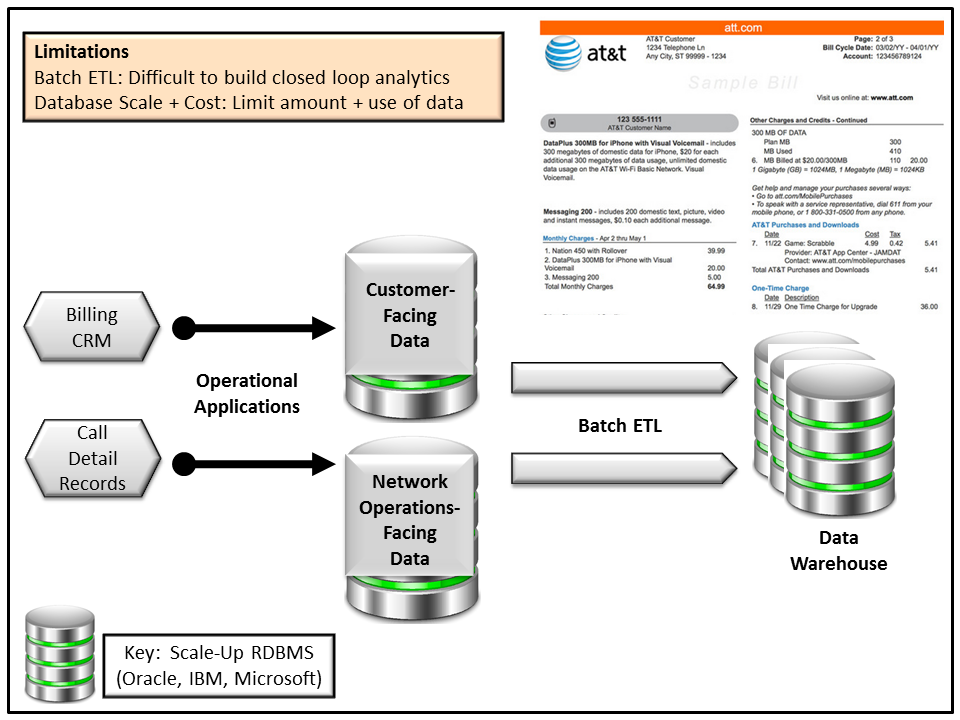
Figure 9: An example of a traditional data preparation and analytic data pipeline. A Telco collects data on calls and matches it up with customer profiles to produce monthly bills. The ability to produce reports in a shorter interval such as daily could enable online bill reviews.
A traditional analytic data pipeline in a System of Record starts with ETL tools and ends with production reporting would look like Figure X above. In this example, records about calls, coming from the call detail record logs, are matched up with customer profiles, including rates, monthly limits, etc. This creates a monthly bill, which is one type of report.
To be clear, SQL data warehouses still have a role to play in an era of big data. When data preparation reveals answers to questions that the business will need repeatedly, SQL data warehouses are still a very efficient way to put them into production.
But when the structure of data such as those log files is changing and a large number of new data sources have to get “wrangled”, new tools are needed. The data lifecycle these new tools must manage is more extended. They need to help in a range of workflows from extracting structure to visualization to helping data scientists explore features for their predictive models.
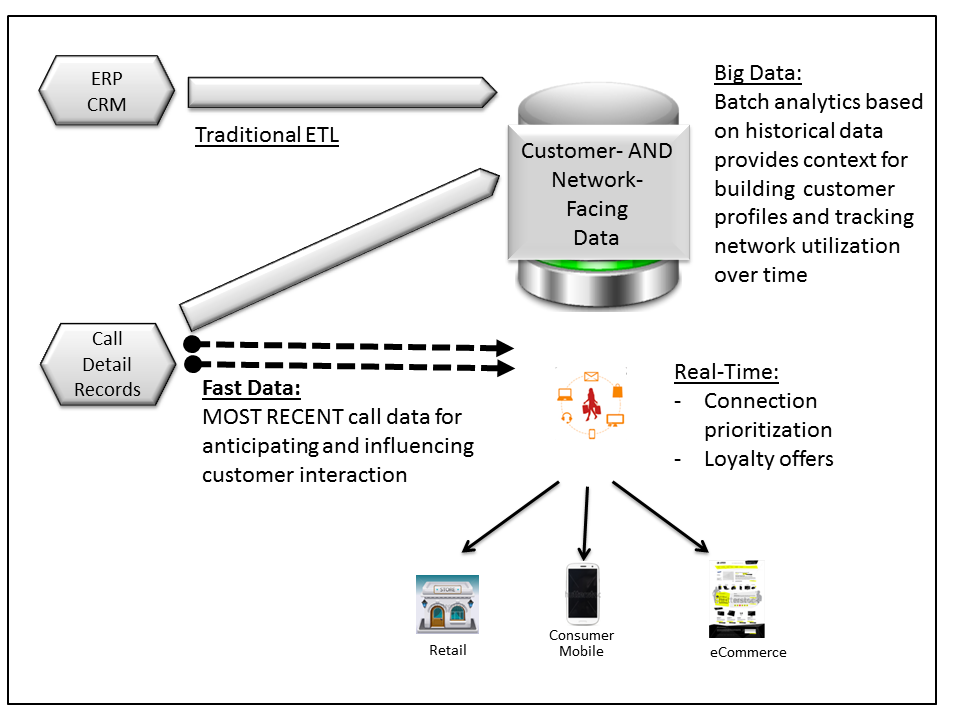
Figure 10: With Systems of Intelligence, a critical requirement is reducing the amount of time between when the operational applications collect data and when key elements are available at the point of interaction.
Section 2
Analytic data pipeline
Since anticipating and influencing the customer at the point of interaction is the key differentiating characteristic feature of Systems of Intelligence, getting critical data through the analytic data pipeline is critical. The rapidly growing interest in stream processing systems such as Spark Streaming, Storm, Samza, and Data Torrent is directly related to this problem. In the telco example, getting and processing information about calls and network congestion in real-time could allow the predictive model to make sure the most important customers don’t experience dropped calls.
These predictive models are the heart of Systems of Intelligence but they are a “black box” to many. The next section tries to explain them in layman’s terms.
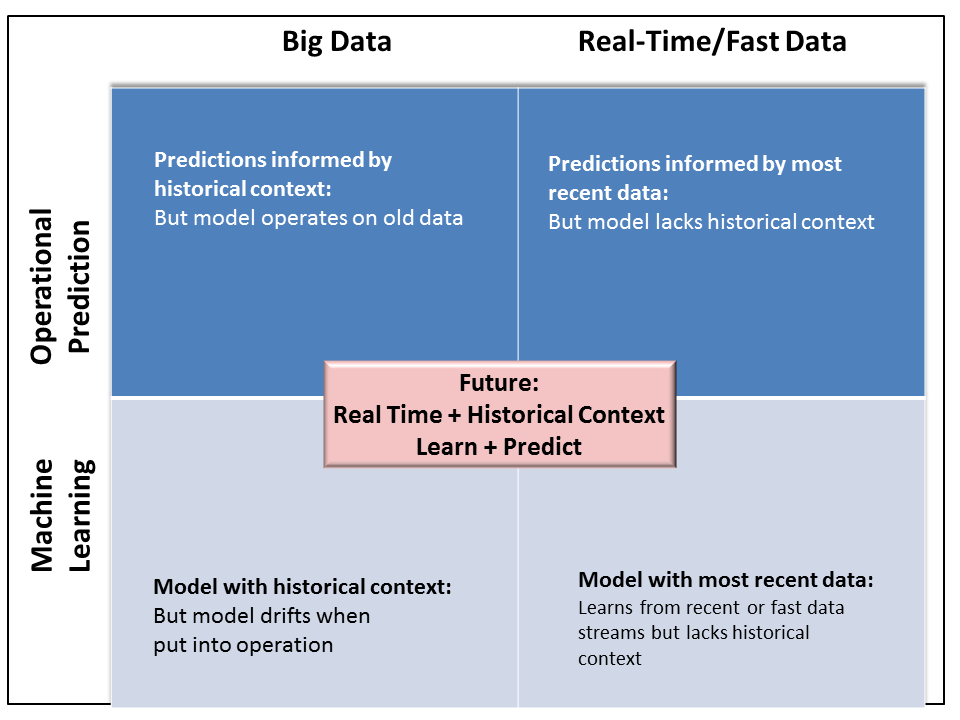
Figure 11: The evolution of the most important data platform component: machine learning and its generation of predictive models
One way to make sense out of machine learning and predictive models is to understand first that predictive models are the output of the machine learning process. (To be completely accurate, there are other models, such as classification that can be used for segmenting customers, but this is meant to be simple).
The second concept is that with Systems of Intelligence, machine learning can operate on both historical or real-time data. Historical data generally falls into the category of big data, since it accumulates many sources over time. Real-time data is the most recent data, whether about a current customer interaction or the latest sensor readings of machine data.
So understanding machine learning and its evolution breaks down into a 2×2 matrix: big vs. real-time or fast data and the process of machine learning vs. the predictive models, which are its output. (See figure X above).
When machine learning operates on big data it gets the benefit of the most data points so the predictive model it creates starts out with the greatest accuracy. But this is a batch process so that the model will always be operating on old data and will drift when put into operation.
By contrast, when machine learning operates on real-time data, the predictive model gets the benefit of the most up-to-date fresh facts. But since it is operating on only the most recent data, it doesn’t get the benefit of historical context. As a result, it won’t be as accurate as the model produced by batch processing big data sets.
Getting the best of the freshness of real-time data and the context of historical data is the ultimate goal. That will enable the most accurate predictive models based on the richest historical context to stay always up-to-date with the most recent data. In other words, this is the heart of how Systems of Intelligence will continually improve.
Even further out, new historical sources and new real-time streams will be incorporated so that the machine learning process will be able to produce ever more intelligent models. And the process of building models will get easier, making them accessible to more than just data scientists. There was a widely-cited McKinsey study that said enterprises will need hundreds of thousands more data scientists than we will be able to train. It ignores the industry’s historical ability to create tools that make all kinds of technology easier for more in the user community.
Section 3
Data platform components
The data management functionality required for Systems of Intelligence is stretching traditional SQL DBMS’s to the breaking point. Out of this market opening we are seeing two phenomena emerge:
- Specialization: the creation of a variety of specialized data managers; for the most part, there’s just too much for one product to do.
- Platforms: the emergence of what some are calling a data platform or a data management fabric; the various platforms are on different points on a spectrum of integrated simplicity for developers and administrators and the fastest, most specialized innovation at the cost of complexity for developers and administrators.
The first section below shows a table summarizing examples of the most specialized data managers and then an elaboration of each category.
The following section shows the major data platform approaches. It explains where they fit relative to each other, their core value add, the trade-offs implicit in their design, the customers that are their sweet spot, and the direction of their likely evolution.
Specialization
Without specialization, it will be difficult, though not impossible, to manage the end-to-end integrated data layer that can respond in near real-time in Systems of Intelligence.
The table below lists some of the key functionality required to manage the data layer.
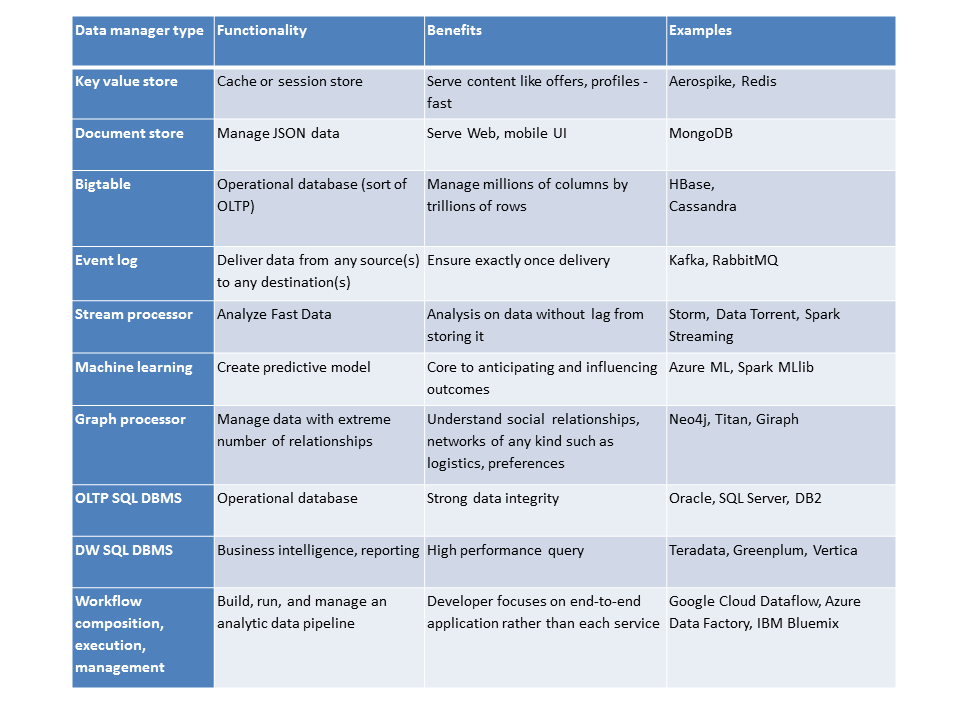
Figure 12: Example data platform components showing the need for specialized functionality
Key value stores such as Aerospike or Redis that scale out can act as caches for high-performance lookups of customer profiles or storing session information such as user activity. These databases are designed to scale out and offer a persistence option in a way that the prior generation’s memcached could not.
Document stores such as MongoDB store JSON documents for serving up the continually evolving Web or mobile UI. UI developers are drawn to these databases because they can start quickly and iterate as they go, in line with the new agile ethos. The flexibility of JSON is critical because browsers and many views within mobile apps render the UI via Javascript. Many traditional databases such as Oracle and even Teradata can manage JSON very effectively. But central IT organizations have much more formalized processes around changing the structure of the data in those databases. Document stores are analogous to last generation’s MySQL in their simplicity of getting developers up and running.
Bigtable-type databases such as Cassandra or HBase handle massive data like the rich, new customer profiles or time series log or machine data. These databases can scale to clusters with tens of thousands of nodes distributed across geographically dispersed data centers. As operational databases, they increasingly augment traditional SQL DBMS’s for Internet-scale applications.
Event logs such as Kafka or RabbitMQ connect the components of a distributed application, such as specialized data managers. By serving as an intermediary, they allow data managers to operate without necessarily having to wait for each other. They also ensure the messages get to the right destination in the right order without dropping or repeating them.
Streaming data processors such as Storm, Data Torrent, Samza, and Spark Streaming for doing, at the simplest level, this generation’s version of ETL on Fast Data. In their most advanced incarnations they can filter the data with SQL and perform machine learning with continually updated predictive models as the output. There are a new generation of in-memory SQL DBMS’s such as VoltDB and MemSQL that are tackling “fast data” from a database perspective. They offer more data protection with more transaction support and richer query capabilities. Stream processors can consume the messages coming from an event log and then send their output through another event log.
Machine learning is the most important category in Systems of Intelligence, which warranted its own description in the previous section.
Graph processors such as Titan and Neo4j can help inform machine learning by taking into account other things that have complex relationships with the customer, like related data from friends, family, or colleagues and data that indicates similarities between products.
OLTP SQL DBMS’s such as Oracle, SQL Server, and DB2 have decades of maturity hardening them for managing the most important business transactions. At their core they are peerless in managing the integrity of this data. More than 75% of the overhead in processing transactions is consumed in managing this integrity via locking shared data and latching shared memory to avoid conflicts, and logging transactions to handle database failures.
SQL data warehouse DBMS’s, like their OLTP cousins, have been heavily optimized for their workloads. Their design center is to be able to scan large volumes of data for analysis. They do this by storing data in highly compressed columns which get fed into a cache in memory that keeps them in columns and which then feeds each column to a processor core via its memory cache. By moving data in a single, compressed format all the way through the processor core, some databases such as Oracle 12c with its in-memory option can process billions of column items per second.
Pipeline workflow, composition, management such as the Azure Data Factory or Google Cloud Platform Data Flow pull all the above data management services into a single analytic pipeline. At their core, they contain the data they operate on, the data management services that perform the operations, and the pipelines that execute those operations. The also monitor and manage execution.
Section 4
Data platforms
There are four main approaches to data platforms. This section looks at several alternative evolutionary paths. No one path is “right” or the “winner”. Rather, they each have different sweet spots in terms of functionality and customer segments.
Data platforms exist on a spectrum starting from greatest innovation combined with complexity for developers and administrators. The other end of the spectrum delivers the deepest integration combined with simplicity for developers and administrators but at the cost of a slower pace of innovation.
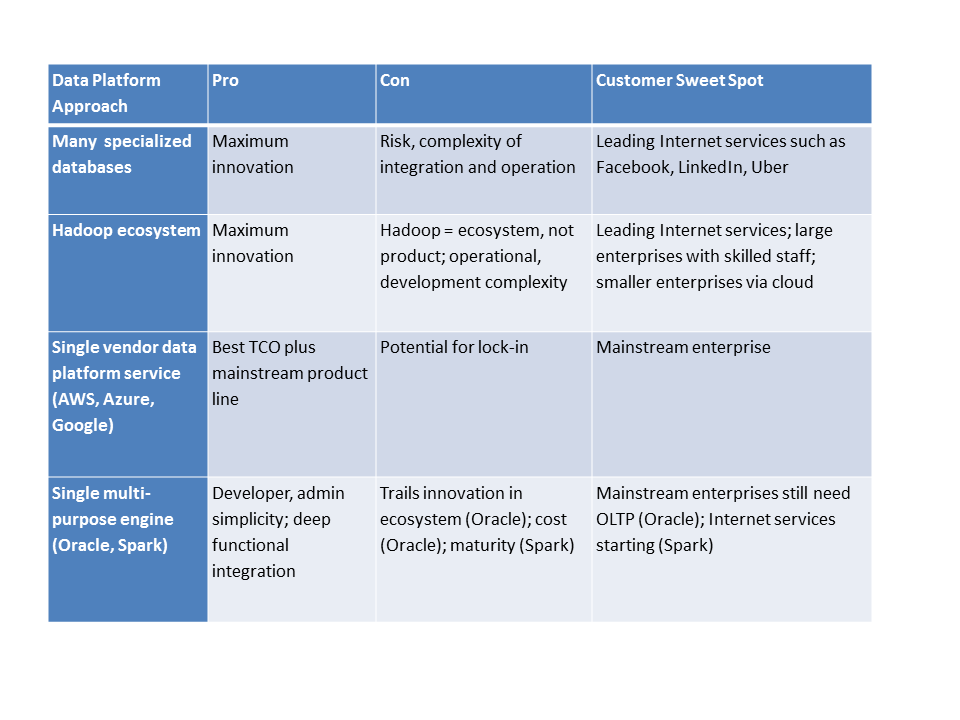
Figure 13: table showing the 4 approaches to building a data platform
1. Many specialized data managers
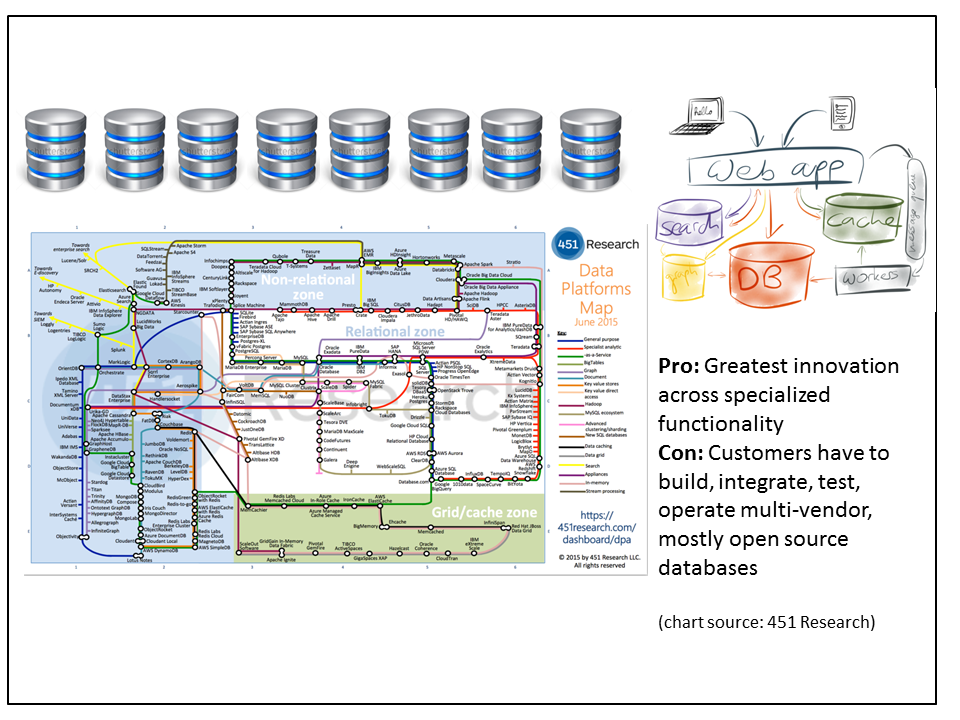
Figure 14: An example in the top half of data preparation that starts with extracting the fields in telco call detail records, their version of log files. In the bottom half is a diagram of what the data looks like when it’s ready for reporting and business intelligence in a SQL data warehouse.
Top figure is from Trifacta
DEFINITION AND EXAMPLES
In this approach we continue to see a “Cambrian Explosion” of innovative, specialized databases from dozens and dozens of vendors. Very often these databases, like the early versions of Hadoop itself, are the byproduct of platform development done by major Web application vendors.
There are literally hundreds of specialized data management products in all parts of the ecosystem. One prominent category is MPP SQL data warehouses. They used to take decades to mature, with Teradata being the most prominent example. Now Cloudera has an entry, Impala, that is rapidly maturing. And within a few years of building Hive, Facebook partners with Teradata to commercialize its nearly-Exabyte-scale Presto internal data warehouse.
WHERE IT FITS RELATIVE TO OTHER APPROACHES
None of the scenarios is entirely exclusive of the other approaches. In this case, some of the specialized data managers such as Storm, HBase, Hive, and Drill also show up as part of the Hadoop ecosystem.
CORE VALUE ADD
Customers can harness the raw innovation from any part of the software ecosystem. They get the long tail of choice. In addition, customers can also stay on the fastest innovation curve. Since the products aren’t constrained by having to fit into any frameworks or other products, new features will likely appear here first.
TRADE-OFFS
There is a downside to choice. Since the new class of applications requires many specialized databases, customers are left to their own devices to build, integrate, test, and operate their data management platforms. But mainstream enterprises don’t have the technical chops or desire to do database R&D on open source products on their own dime.
Also, getting data out of many different databases adds a lot of complexity for developers. With SQL databases, they just say what data they want and the database figures out how to find it and combine it. With multiple different types of databases, the developer would have to extract the relevant data from each database and join it with the others manually. This is cumbersome for a couple of reasons. Without a query language like SQL, they have to specify how to get at the data, not just what they want. This is like the difference between providing an address to a destination versus providing detailed directions about how to get there.
In addition, getting data out of a single database is potentially orders of magnitude faster than doing it manually from multiple databases. A single distributed database optimizes for speed by minimizing how much it moves the data for processing. That’s many times harder, if not impossible, when working directly with multiple databases.
CUSTOMER SWEET SPOT
Many of these products are the byproduct of platform development by the leading Web application vendors such as Facebook, LinkedIn, Twitter, and Uber. It’s a byproduct because they see themselves as online services companies, not software companies, so they contribute the code to the community as open source. Other online service providers are typically the first customers for the most leading edge products.
LIKELY EVOLUTION
As long as Internet-centric companies continue to build out their platforms, we will continue to see them build and consume new standalone, specialized products. But as the market shifts to mainstream customers, we are likely to see a greater emphasis on removing the complexity of developing for and administering products that weren’t designed to work together.
The following scenarios illustrate ever-tighter integration.
2. Hadoop ecosystem
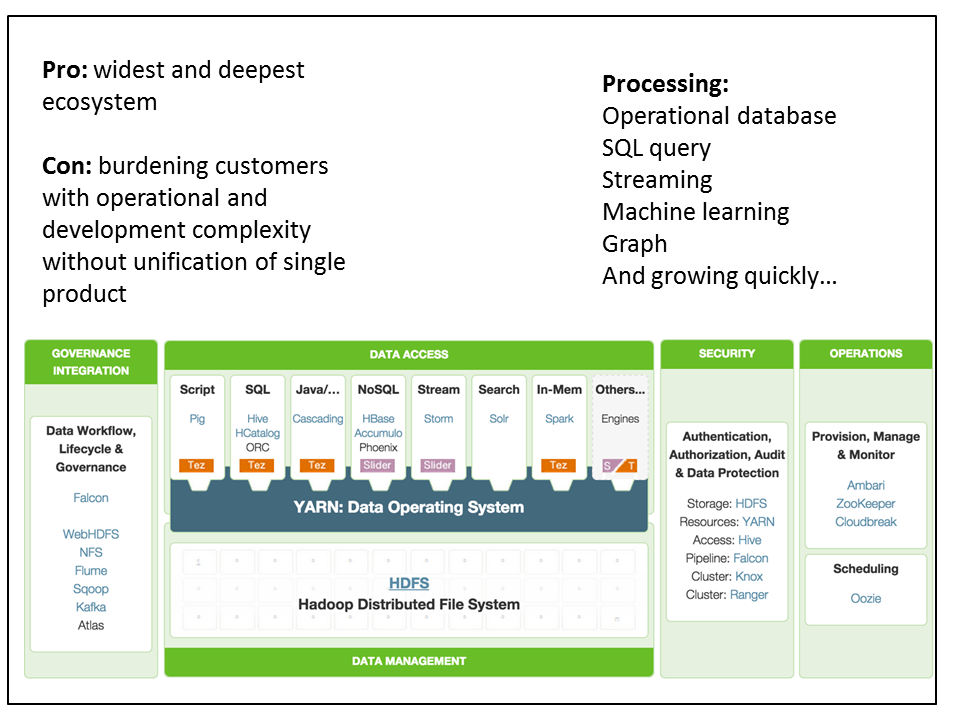
Figure 15: the framework of tools and data management products within the Hadoop: curated innovation at the ecosystem level
DEFINITION
The most important part of defining Hadoop is understanding that it’s not a product. It’s a continually expanding ecosystem where each vendor curates its own distribution. A distribution might have close to two dozen components, each on its own release cycle. But the core platform components upon which everyone in the community agrees are HDFS and YARN. Just about all products that are part of Hadoop build on these products.
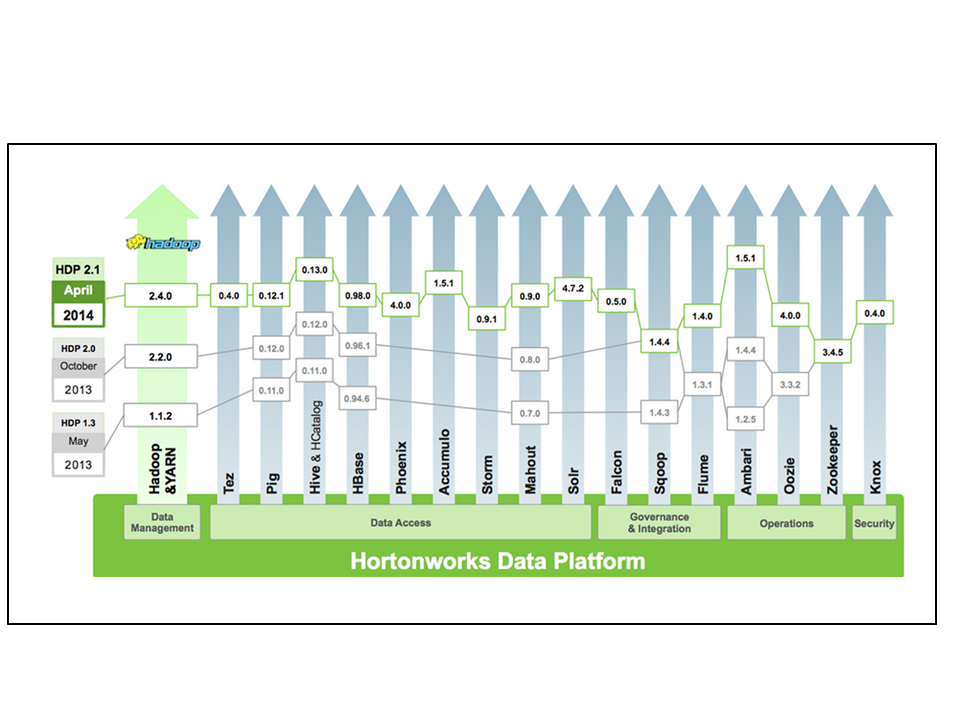
Figure 16: Hadoop is not a product but a carefully curated collection of products, each on their own release cycle
There is a separate attempt to start defining a set of core components with a single release level across multiple vendors’ distributions. The Open Data Platform plans to align its members around a set of common releases of HDFS, YARN, MapReduce, and the Ambari management tool. Hortonworks, Pivotal, and IBM are all part of this alliance. Over time they hope to expand the number of common releases of components that comprise a core distribution.
WHERE IT FITS RELATIVE TO OTHER APPROACHES
Unlike the raw innovation of the previous scenario, the broader community and to some extent each Hadoop distro vendor, agrees on a more carefully curated set of products. In addition, each vendor wraps the distribution with additional value, most often either tools that better integrate administration or improve the data management products. In the admin category are products such as Cloudera’s Manager or the product Hortonworks sponsors, Ambari. In the data management category are Cloudera’s Impala and MapR’s Drill.
CORE VALUE ADD
In a way, if you squint, the Hadoop distribution vendors are like Red Hat 15 years ago. Linux had emerged as the first platform that harnessed the innovation coming from an ecosystem of contributors.
Linux needed a vendor to manage the release cycle of all the components, support it, and provide a way to keep the software up-to-date. In Red Hat’s case, that was the Red Hat Network. The big difference between the Hadoop vendors and Red Hat is that Linux really was a single product and Hadoop is not – yet. And that is at the heart of the trade-off in this approach.
TRADE-OFFS
Hadoop’s application model has always been based on a discrete collection of engines performing tasks where the output of one gets handed off to the next. It’s popular to say that this means Hadoop applications are necessarily batch. But the analysis of machine learning and predictive models in the prior section should make it clear that there are two different types of real-time. The first uses machine learning to update a predictive model in real-time so that it is always up-to-date. And the second uses an existing predictive model to anticipate and influence a customer interaction in real-time, though the model may drift over time.
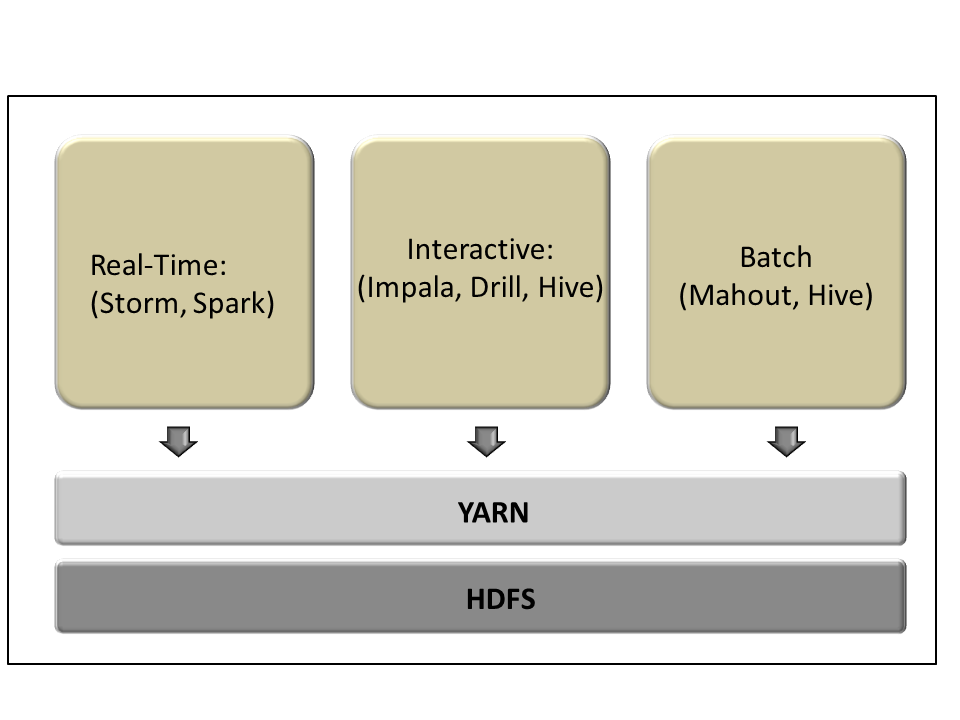
Figure 17: Hadoop’s applications exist on a spectrum between real-time and batch, depending on the type of analytics involved.
Management, security, and data governance products such as Cloudera’s Manager or Apache Ambari; Apache Ranger; and Cloudera Navigator and Apache Atlas; are all attempts at smoothing over the “seams” between the individual products in Hadoop.
More broadly, these tools are part of a continuing effort to hide the administrative and developer complexity that comes from of a collection of fairly independent products, no matter how carefully curated.
CUSTOMER SWEET SPOT
Hadoop’s ability to migrate from its origins at the leading Internet companies and start moving past early enterprise adopters has really been about skillsets and quantifiable value from initial use cases. Companies in the ad-tech, gaming, and e-commerce sectors were the obvious next customers. And telco’s, banks, and traditional retailers have always been leading-edge users of analytic technology.
But for Hadoop to move into the mainstream it needs to start looking more like a single product to administrators and developers. Proactive administration technology such as what Cloudera and Hortonworks are building is a step in this direction. Ironically, the integrated notebooks environments emerging from the Spark community seem most illustrative in how to serve data scientists and application developers. And that represents one potential path of evolution.
LIKELY EVOLUTION
The core YARN and HDFS components are likely to continue their progress in becoming ever more central to the rest of the ecosystem.
Currently YARN mediates access to hardware resources. Over time, with or without the help of the competing Mesos cluster manager, it should start mediating workloads between applications themselves. Basically, that means it would be like the functionality in Windows that enables multiple applications to ask in real-time for cycles to complete their tasks.
HDFS is still a fairly primitive file system. It’s likely to get a lot better at handling more critical capabilities such as updates. It will also embrace multiple types of storage that reflect different price and performance points, such as flash SSD, non-volatile memory, and DRAM.
In addition, the Hadoop vendors are likely to get ahead of the innovation in the individual products in their distros and make them look and feel more like an integrated suite. For administrators, this would require making Hadoop run more like a service even when on-premise.
The biggest draw pulling the evolution of the developer-facing part of the Hadoop ecosystem is Spark. Spark was created as a distributed data processing engine to replace MapReduce. As the Hadoop distro vendors rightly point out, they are embracing Spark as closely as all the other Apache components, starting with YARN and improvements to HDFS.
However, it’s possible that Spark creates its own ecosystem with a gravitational pull external to Hadoop. It could draw much of the data science and developer community into its own orbit, a scenario we’ll examine more closely after the next one.
An additional set of vendors may end up serving developers most effectively. Vendors with the DNA to build developer platforms are likely to include Microsoft, Google, Amazon, and maybe Oracle.
3. Single vendor data platform
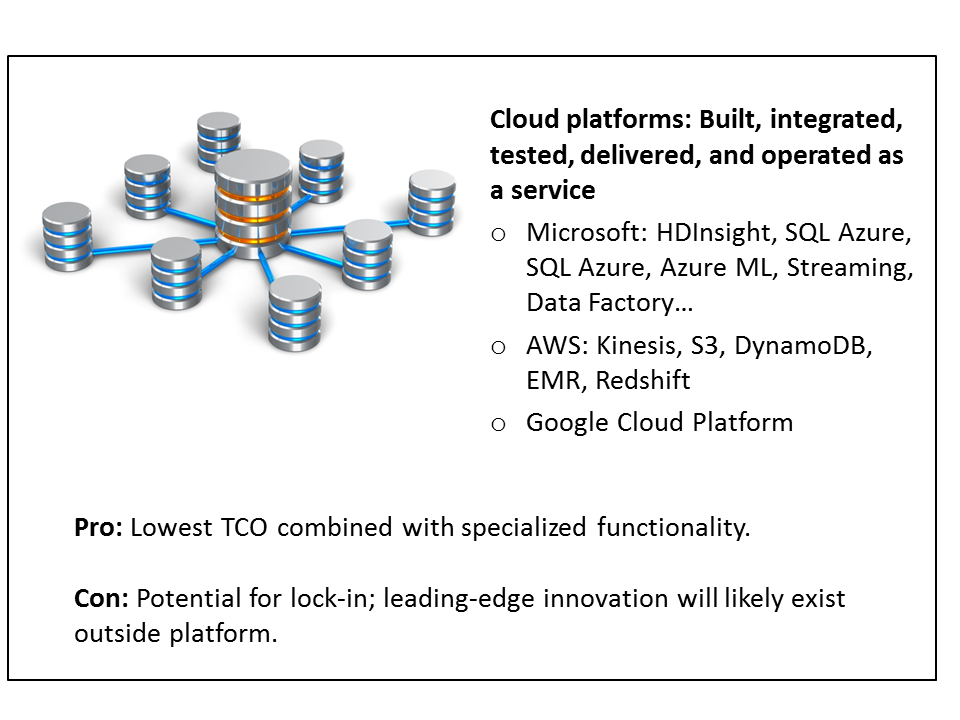
Figure 18: Single vendor data platform combines elements of best-of-breed specialization and low TCO of single vendor solution
DEFINITION
Prominent examples in this category include Microsoft Azure, Google Cloud Platform, Amazon AWS, Oracle Cloud, IBM Bluemix, and Pivotal’s Data Platform running on Cloud Foundry. Beyond running a Platform-as-a-Service, each is at various stages in building tools that help developers work with multiple services seamlessly. They can go all the way toward composing, orchestrating, monitoring, troubleshooting, and tracking the lineage of analytic data pipelines.
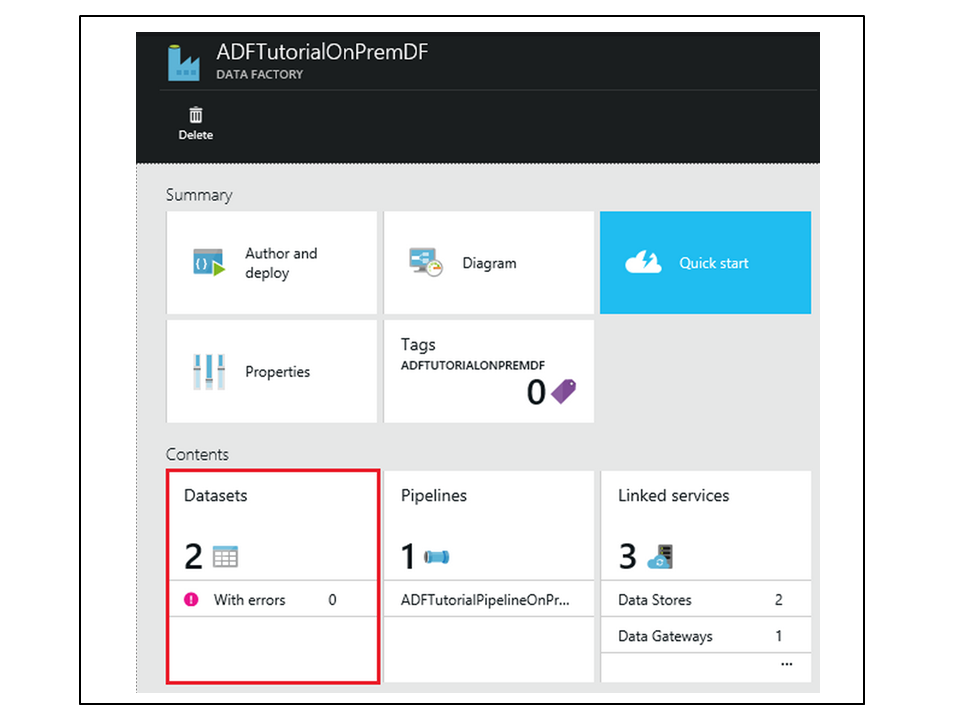
Figure 19: Azure’s Data Factory console showing datasets, services for manipulating or storing data, and the pipelines the use them.
Technically, these services aren’t all single-vendor. For example, Azure contains a Hadoop service based on the Hortonworks distro embedded within its platform. But the key point is that the hosting vendor takes responsibility for administering its set of services.
WHERE IT FITS RELATIVE TO OTHER APPROACHES
These platforms are not necessarily exclusive of Hadoop. Rather, at the highest level they can call on individual Hadoop components. Microsoft’s Azure Data Factory does just that, but it also consumes other, Azure-specific services such as SQL Azure database. The same is true of IBM’s Bluemix and AWS.
CORE VALUE ADD
This approach is further along than the previous two in providing an integrated experience to administrators and developers. Since they run as a service, they go a great deal further in reducing the admin TCO that is critical to mainstream adoption.
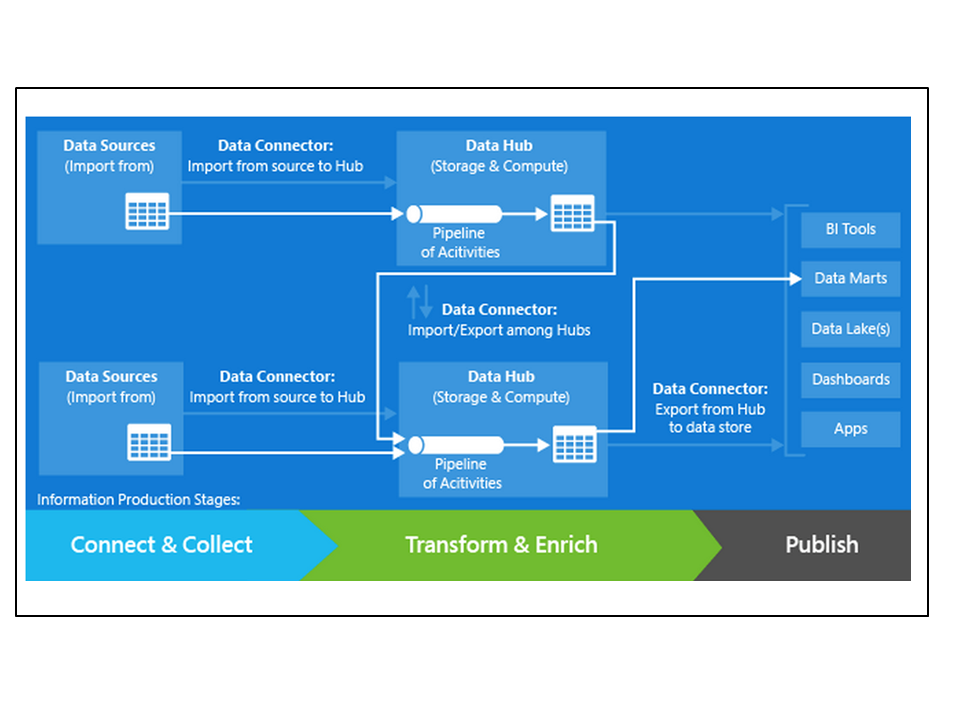
Figure 20: An example of how Azure Data Factory works under the surface
By way of example, Microsoft is hosting close to 1.5M individual SQL Azure databases. If they administered these the same way as traditional on-premise databases, the service would collapse. On-premise databases used to require somewhere between 1 admin for each 30-50 databases. At that rate, Microsoft would require 30,000-50,000 admins just for SQL Azure.
TRADE-OFFS
The extra engineering that goes into ensuring the component products fit together necessarily means the latest and greatest technology will always be beyond the edge of these platforms. That is where the first scenario lives.
In this scenario, customers will necessarily face lock-in, so they have to trust their vendors will be competitive on functionality and price into the future. Part of what supports an integrated developer and administrator experience is the use of proprietary services. For example, the database at the core of IBM’s Bluemix is dashDB, which is emerging as the leading edge of the ongoing effort to integrate the best of DB2 BLU, Netezza, and their other data management tools. Similarly, AWS’s popular Redshift runs only on their cloud.
CUSTOMER SWEET SPOT
This approach seems destined to be the focus of mainstream enterprise adoption over the next 3+ years. More than the previous two approaches, this puts responsibility for building, integrating, testing, delivering, and operating the platform as close to an integrated service as possible. And that breaks much of the link between adoption and the need for scarce skills.
Those skills were in greatest abundance in the largest Internet services and in progressively less amounts at Internet-centric companies such as ad-tech, gaming, e-commerce, and the Fortune 500.
LIKELY EVOLUTION
There is still plenty of room to make the onboarding process for data scientists and application developers still easier. Machine learning can go a long way towards helping data scientists clean new sources of data and even figure out which new sources can help refine their models.
And developers for the most part are still building applications using low-level tools. Even if SQL has replaced MapReduce for many ETL, data exploration, and business intelligence tasks, the rest of the data processing tasks are a good deal less accessible. Whatever its warts, SQL allows developers to say what they want, not how to get it. That means vendors could create visual tools to do a lot of the hard work of generating code. And that under the covers the data access engine could do ever more sophisticated tricks to get things done faster and cheaper.
Extending that capability of building high level visual development with under-the-covers optimization is at the heart of the next approach.
4. Single multi-purpose engine
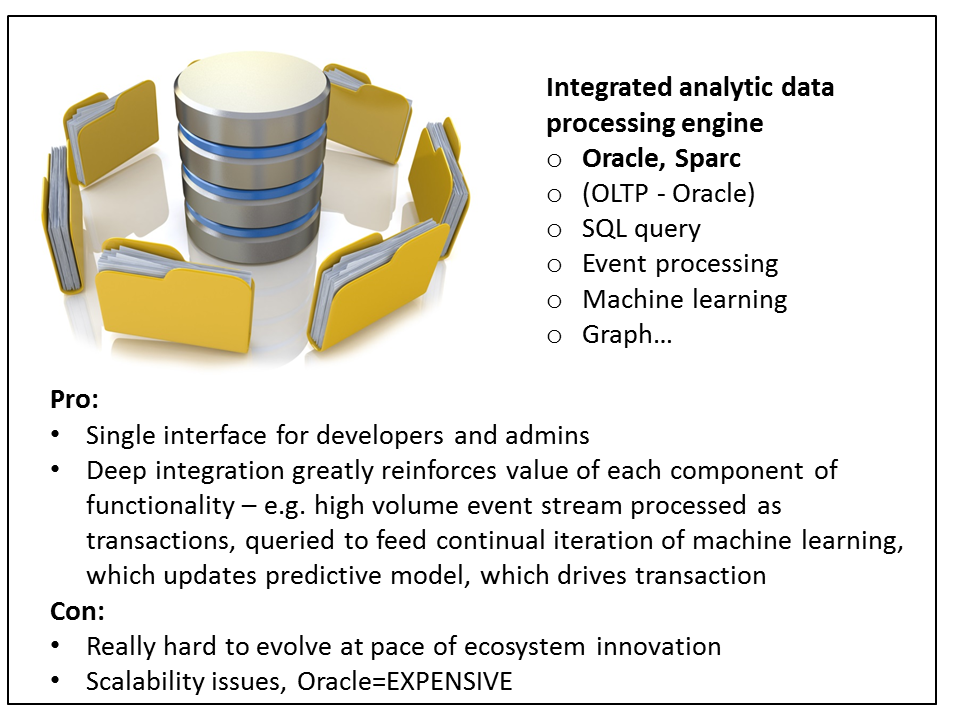
Figure 21: Integrated analytic data processing engine makes it easiest for each functional component to reinforce all the others; current trade-off is ability to serve Web-scale applications and ability to keep up with leading edge specialized products
DEFINITION
Just as SQL databases managed all the workloads and data processing for Systems of Record, this approach does the same for Systems of Intelligence. One engine manages all the different types of workloads, such as real-time, interactive, and batch; and data manipulations such as SQL, streaming, statistics machine learning, graph processing, and others.
There are two products taking this approach that have or are in the process of building up powerful ecosystems: Oracle’s flagship database and Apache Spark.
WHERE IT FITS RELATIVE TO OTHER APPROACHES
This level of integration is the apogee of the progression of the previous approaches in terms of integration for data scientists, developers, and administrators.
CORE VALUE ADD
Spark’s unification and deep integration make it possible to build applications where each step can involve capabilities from other parts of the product.
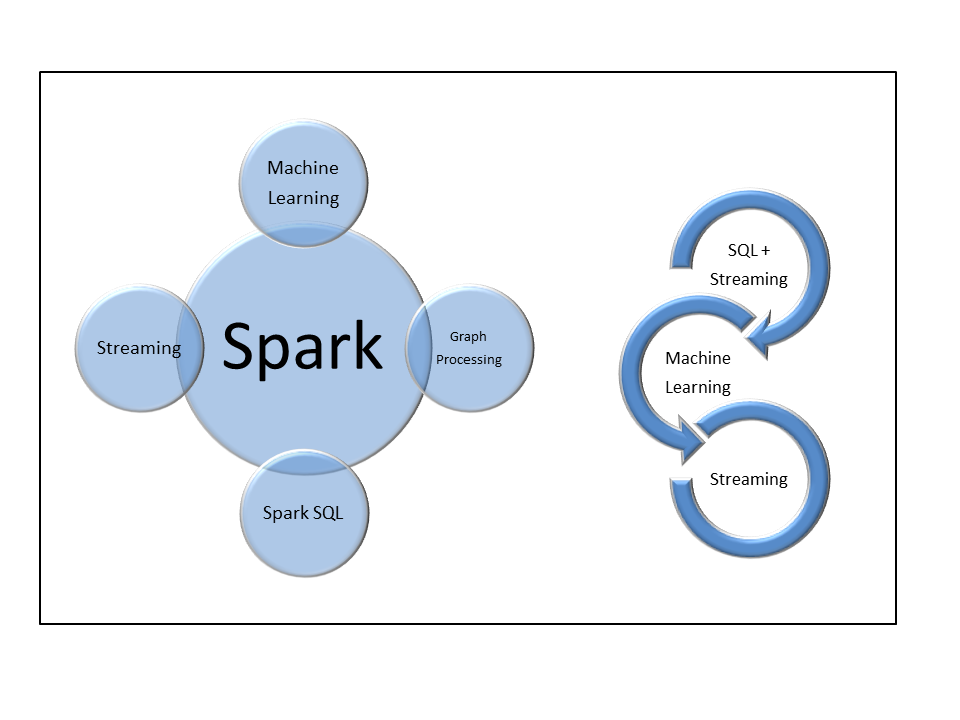
Figure 22: Spark is a single processing engine that has multiple “personalities”. While it leaves the persistence layer to other products, Spark is the equivalent of an analytic operating system kernel.
Eventually developers will be able to join and filter real-time streams of time series machine data with SQL with the result set flowing through machine learning algorithms that continuously update a predictive model.
Oracle has taken a similar approach in integrating comparable functionality into its database for years. However, the database also manages the persistence layer so can handle the entire cycle from one business transaction through the analytic pipeline all the way to influencing the outcome of the very next transaction.
TRADE-OFFS
Spark is immature. Like all enterprise-grade software, it will take time to get hardened. Then it will take on progressively more workloads with lower latency and less tolerance for failure. SQL databases started out as reporting technology for transaction processing done in hierarchical and network databases. It took 10-15 years from Oracle’s appearance on the scene before mission critical apps such as financials, MRP, and ERP applications started moving over.
Spark is attempting to make its general purpose kernel so fast that traditional workloads such as stream processing, SQL, machine learning, and graph processing run just as fast as on specialized products such as Storm and Impala. Normally, specialized applications can achieve better performance and functionality through focus. Spark has a project called Tungsten underway to enable it to run as if it were compiled platform such as an operating system.
The first downside for Oracle, for now, is scalability. You can only stretch a cluster out to so many nodes before the system starts to “rattle”, meaning administrator attention needs to escalate exponentially. Right now Oracle requires shared storage, which means that beyond a certain cluster size, that becomes a bottleneck.
Finally, it’s much harder to make new functionality integrate with existing functionality. Each addition requires careful architecting so that all the pieces fit together. Separate products have no such constraints. As a result, integrated products will always be behind the curve relative to innovative, standalone products.
The biggest trade-off for Oracle customers by far is cost. With all the options, the product costs close to $150,000 per processor *core* at list. That means a single Exadata rack runs well above $30M. Even with a 2/3 discount, a single 24 core server would cost $1.2M vs. $4-7K per year for a full Hadoop distribution.
CUSTOMER SWEET SPOT
For the last 2-3 decades, Oracle has been the unchallenged mainstream data management platform. And for managing critical business transactions it remains that platform. However, several reasons beyond just functional specialization have been moving the center of gravity away from Oracle.
One reason is cost. Open source software and metered pricing are causing a not-so-slow motion collapse in pricing for all traditional infrastructure software.
Another reason has to do with organizational dynamics. Part of the reason Oracle was so successful winning enterprise-wide standardizations was that IT organizations had control over virtually all data. They treated that data as a corporate asset and wanted a common way to administer it. With the dramatic growth in applications, a shrinking share of enterprise data falls under the purview of central IT. Whether new applications live in the cloud or belong to departments and business units, their control of the applications is creating major openings in the market for data management software.
The sweet spot for Spark is very different. Partly because of its relative immaturity and partly because of its initial appeal to data scientists it is seeing early deployment in two different types of customers. The first group are the Internet-centric companies that may or may not use it in conjunction with Hadoop where they might have otherwise used Storm for streaming, Mahout for machine learning, and Hive for SQL-based ETL.
The second group consists of a rapidly growing number of data preparation tool vendors that can leverage its unified engine to build tightly integrated functionality into their own tools. Zoomdata is one such example.
LIKELY EVOLUTION
Oracle is beginning to get big data religion. For starters it’s embracing lower price points for data that can live in Hadoop. Its Big Data SQL appliance bundles its NoSQL key value database, Cloudera’s distro, and some of Oracle’s own code on the Hadoop nodes. This code functions the same way as it does on Exadata, where code on the storage nodes filters out any data from that node unnecessary for answering the query coming from the main Oracle database. This hints at their future direction.
Oracle will keep their mainstream database as the focus for mission-critical transaction processing and probably for production data warehouse functions. But it will likely embrace a spectrum of storage tiers for data on their Big Data SQL appliance. Their data preparation push will likely heavily embrace machine learning to incorporate and make sense of data from the ever growing number of sources.
They are unlikely to be completely price-competitive with the mainstream Hadoop distros because they are requiring the Big Data SQL software to come with its own appliance and that appliance has to be front-ended by Oracle’s database running on Exadata
However, Oracle’s cloud will probably be the best, and possibly the only, cloud for running their database, and by extension, their Big Data SQL software. Amazon and Azure still can’t run Oracle’s database with its cluster option. They would need both shared storage accessible from compute nodes as an option as well as a way to avoid the performance overhead of a VM on every database node. Oracle Cloud gets around this problem by running on their appliances and using their own containers instead of VMs to mediate access to hardware.
The most relevant part of Spark’s future seems likely to stay mostly with Databricks, the company that sponsors its commercial release. Perhaps more than any other big data software vendor, they are committed to hiding the administrative complexity of running their service. They are putting a lot of their secret sauce into making their service appear as if it were running on a single machine.
They are doing the same for data scientists, developers, and potentially business analysts. They are already demonstrating notebooks that used to be for single machine use as a way for data scientists and developers to collaborate on preparing data and building analytic applications.
They are likely to build additional data preparation and analysis functionality that is increasingly visual, rather than code-based. With more visual tools – at least for low-end use-cases, data that the scientists find can be shared with business analysts more easily. The scientists might identify some data as dimensions, like years, quarters, and months; or product line, product family, product, and SKU; or customer segment and consumer. Once the structure of the data is in place, the facts like sales for each SKU can roll-up into different slices or be used in different predictive models. Because the whole thing runs in one set of tools, they can deliver usability that greatly broadens their appeal.
Action Item
Mainstream IT, LoB execs and application development professionals each provide different yet critical perspectives on Systems of Intelligence. IT exes must be in a position to deliver the right infrastructure (e.g. cloud, on-prem, etc.) with the proper performance and SLA profile to support LoB requirements. Line-of-Business execs must have enough knowledge to specify the real-time needs of applications while application development pros must ensure the right skills are in place to deliver and maintain services to Systems of Intelligence over a full life cycle.
Importantly, when choosing a strategy, platform and architecture, organizations must become comfortable taking responsibility for building, integrating, testing, and operating a multitude of vendor data management tools to build a custom platform that leverages an open source software ecosystem while at the same time delivering competitive advantage.


