
Premise
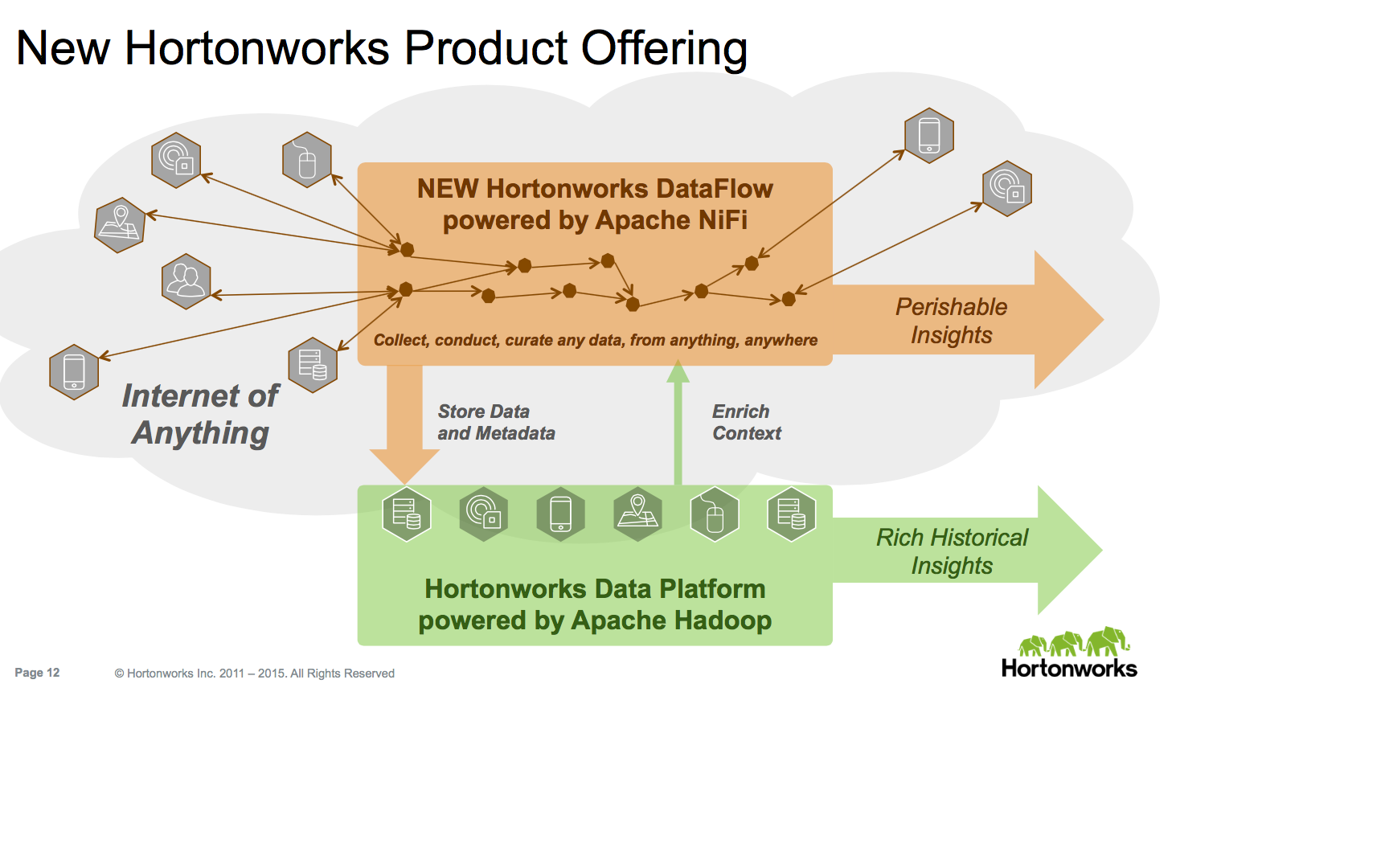
Hortonworks’ recent purchase of Onyara and its newly-renamed Dataflow stream processor doesn’t easily fit into conventional classification schemes. At the most trivial level, it simplifies the fragmented Hadoop data ingest capabilities, which includes Kafka, Sqoop, and Flume. It is also meant to work with or instead of analytic stream processing engines such as Spark Streaming, Storm, Samza, Flink – sort of. Most important, it is meant to support both the Internet of Things as well as the application-to-application analytics that traditional stream processors underpin.
Besides reviewing why Dataflow doesn’t easily fit in conventional categories, this two-part research note explains 3 key issues.
Part 1: IoT stream processing requirements, splintering of Hadoop ecosystem
- The Internet of Things requires additional features beyond what’s in traditional stream processors,
- And Hadoop vendors’ traditional practice of differentiating on management tools on the periphery but supporting common compute engines in the core is now breaking down.
Part 2: how stream processing is emerging as a peer to batch processing
- Streaming analytics has a large and growing number of use cases that complement traditional batch analytics in databases for near real-time applications.
The Internet of Things requires additional features beyond what’s in traditional stream processors
Most stream processors have been about analyzing data going from one or more source applications out to one or more target applications. Hortonworks Dataflow is designed to go much further in a number of dimensions.
- It’s bi-directional. The “assembly line” doesn’t just ingest data from other applications or devices. It can send data back to them.
- It’s not just about queueing data for transmission and/or analysis. It also has a separate “channel” to send and receive data that controls devices or applications.
- It’s designed to extend beyond a data center and its applications and devices and extend all the way to the edge of complex networks.
- It needs the resilience, lineage, security capabilities that traditional databases have always had.
Bi-directional
Applying stream processing to the Internet of Things, as opposed to application to application communication, introduces new requirements. At the most basic level, data has to flow in two directions. Conventional applications collect data from operational applications and send it through an analytic pipeline in order to perform historical reporting and business intelligence.
When running a smart grid, that’s not good enough. The application may have very sophisticated analytics at its core that predicts demand and adjusts electricity supply from a number of sources, including highly distributed generators. When the application is collecting data from one house, for example, it may know that it’s not occupied and the air conditioning is keeping it colder than necessary. A smart grid application needs to be able to turn the air conditioning off.
In fact, some of the analytics itself must run closer to the edge of the network to minimize network bandwidth and travel time. Analyzing energy consumption at the neighborhood level might just have to happen nearby. Otherwise the time and bandwidth demands of bringing everything to a central data center may overtax the network and slow the response.
Separate data and control channels
Managing individual appliances in this smart grid is an example of needing one channel to deliver data about what’s going on with devices and another channel to control them. Turning the air conditioner off is a control function. It’s possible to combine data and control channels in a stream processor. But then the applications that analyze the data and the devices that collect the data are all responsible for unpacking both the data and the controlling instructions. It’s just more burdensome and complex that way.
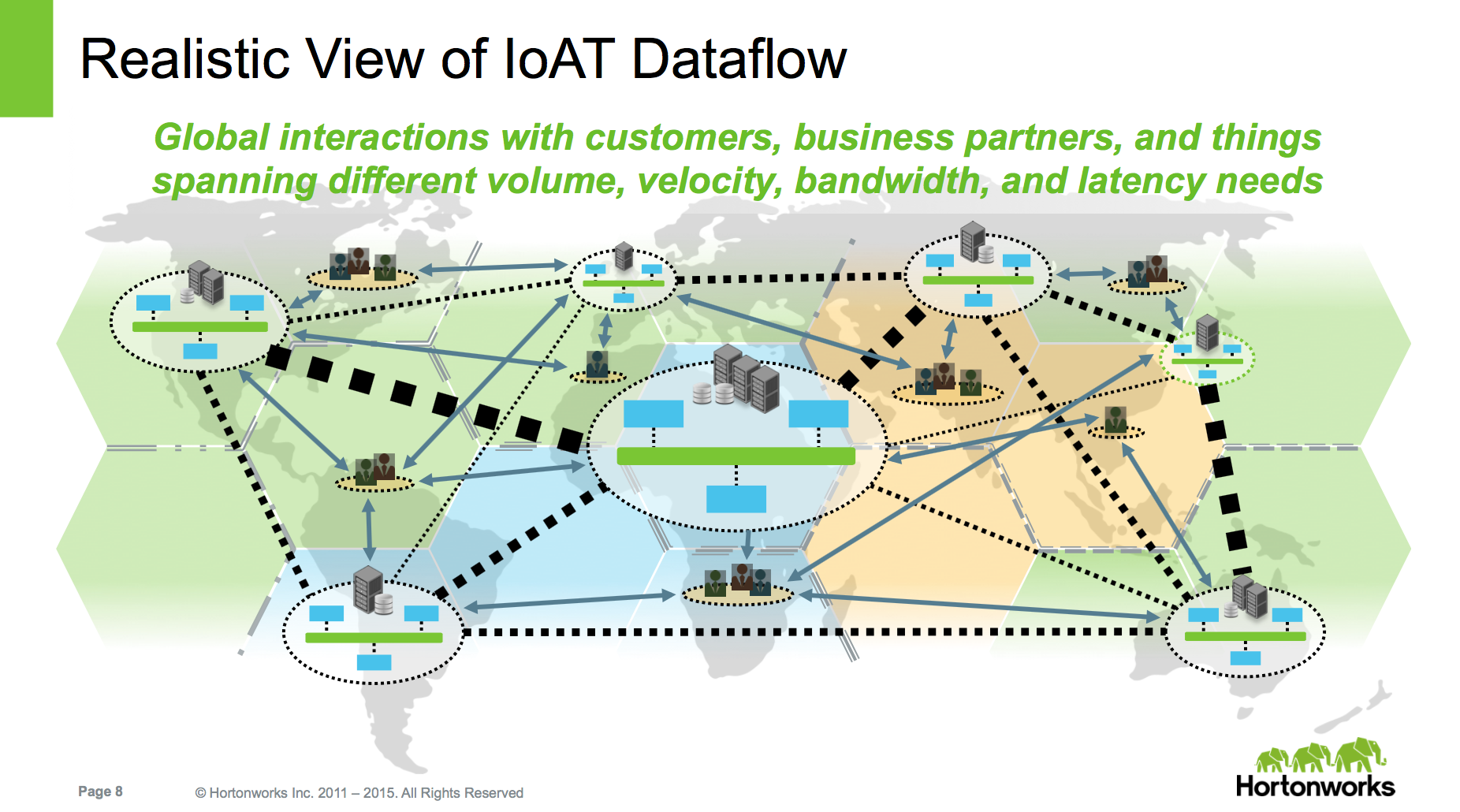
Extending to the edge of the network
In this case, a picture really does say a thousand words. The data can flow along a complex topology that involves not just applications in a data center but across data centers, partners’ systems, and devices located anywhere.
Resilience, lineage, security
Databases have had many decades to become hardened, trustworthy data platforms. Stream processors for the most part are far earlier in this process. Hortonworks Dataflow is actually further along here and it probably reflects its government NSA heritage. It can keep track of data lineage from end-to-end with a complementary audit trail. And in addition to end-to-end encryption options, it supports access control policies that can change frequently. Its resilience is also noteworthy. Most stream processors leave that function to the message queue that delivers the data but don’t support the capability to recover from failures once it’s working on the data. Dataflow claims it can do this.
Implications:
Hadoop vendors’ traditional practice of differentiating on “manage-ability” while supporting common compute engines is now breaking down
In case it wasn’t clear before, the Hadoop ecosystem is growing so fast that centrifugal forces are pulling it apart. Choosing a platform vendor is now a more strategic, long-term partnership than ever before. New functionality is splintering the Hadoop ecosystem and customers don’t really have second source options with different Hadoop distributions. We are now reentering the territory of the proprietary flavors of Unix in the ’90s. Hortonworks Dataflow may be open source, but Cloudera and MapR have given no indication they plan to include it with their distributions.
Traditionally, vendors have largely differentiated their Hadoop distributions with their management tools. Cloudera’s Manager and Navigator didn’t change core the compute engines such as MapReduce, Hive, Pig, and others. They did ship their own analytic MPP SQL database, Impala, but its data format is the Parquet standard and it also uses the standard Hive HCatalog so data isn’t really locked in. MapR has always had its own implementations of HDFS and HBase that made them easier to manage. But their API’s are the standard ones so any compliant tools can work with them and the data isn’t locked away either. Now that’s no longer the case.
Hortonworks was always the vendor most committed to using Apache projects not only for the core compute engines but the management tools as well, starting with Ambari. With the new Dataflow product, stream processing, which is becoming as much a core compute engine as its batch counterparts, looks like it’s going to be different across different vendors.
Action Item
IT leaders can no longer treat stream processors as esoteric functionality employed solely by leading-edge consumer Internet services. They are becoming core functionality that works side-by-side with the more familiar batch processing engines such as Hive, HBase, or Impala. Application developers that need near real-time functionality can start to evaluate stream processors as part of design patterns. However, their analytics functionality is still a bit primitive and most of them need a lot of hardening in order to be resilient enough for mainstream customers.


