
Investors have poured north of $30B into independent foundation model players including OpenAI, Anthropic, Cohere, Mistral and others. OpenAI itself has raised more than $20B. To keep pace with the big three FM players (OpenAI, Google and Anthropic), both Meta and xAI will have to spend comparable amounts. In our view, the stampeding herd of LLM investors is blindly focused on the false grail of so-called artificial general intelligence (AGI). We believe the greatest value capture exists in what we’re calling “Enterprise AGI,” metaphorically represented by the proprietary data estates and managerial know-how locked inside of firms like JP Morgan Chase, and virtually every enterprise. Generalized LLMs won’t have open access to the specialized data, tools and processes necessary to harness proprietary intelligence. As such, we believe private enterprises will capture the majority of value in the race for AI leadership.
In this Breaking Analysis we dig deep into the economics of foundation models and we analyze an opportunity that few have fully assessed. Specifically, what we’re calling Enterprise AGI and the untapped opportunities that exist within enterprises. While many firms discuss proprietary data as the linchpin of this opportunity, very few in our view have thought through the real missing pieces and gaps that we hope to describe for you today.
The False Grail of AGI
Let’s start with the catalyst for the AI wave we’re currently riding. Below we show Sam Altman, the CEO of OpenAI. He’s often associated with the drive to create AGI. We’re using a definition of AGI where the AI can perform any economically useful function, better than humans can. We’re not referring to superintelligence or Ray Kurzweil’s idea that our consciousness will be stored and perpetually survivable, rather we’re talking about machines doing business work better than humans.
In the middle we show a scene from Indiana Jones and the Last Crusade, where the character drinks from a golden chalice, believing it to be the Holy Grail. In the context of AGI, the Holy Grail represents the ultimate achievement in AI—the true AGI that so many are chasing.

The rightmost image is from the same movie, showing the man after he drinks from the wrong grail. The meme suggests that while the pursuit of AGI (the “Holy Grail”) is appealing, its outcomes are perhaps illusory.
Indy was More Humble in his Quest

Indy didn’t go for the chalice that he believed belonged to a king. He, as an archaeologist, looked for something much more prosaic. As he said, “The cup of a carpenter. ” Similarly, AGI in the enterprise may really be the pursuit of something much more commonplace than this intergalactic AGI that we were talking about in the last slide. It’s the ability to gradually learn more and more of the white collar work processes of the firm. And instead of one all-intelligent AGI, it’s really a swarm of modestly intelligent agents that can collectively augment human white collar work. So rather than one AI to rule them all, which many people agree may not be likely scenario, we’re thinking of something different.
Imagine a World with Many Thousands of Reliable White Collar Worker Agents
Rather than one AI to rule them all, which many people agree may not be the likely scenario, we envision “worker bee” AIs that can perform mundane tasks more efficiently than humans; and, over time become increasingly adept at more advanced tasks.

Jensen Huang recently said something that resonated with us. He said the following:
NVIDIA today has 32,000 employees. And I’m hoping that NVIDIA someday will be a 50,000 employee company with 100 million AI assistants in every single group. We’ll have a whole directory of AI’s that are just generally good at doing things….and we’ll also have AI’s that are really specialized and skilled. We’ll be one large employee base…some will be digital, some biological.
Jensen Huang on the BG2 Podcast
The big distinction we’re trying to get to in this research is to understand more fully the difference between creating an all-knowing AGI and deploying swarms of worker agents
There are frontier model companies that are trying to create what we’re referring to as the “Messiah AGI,” i.e. a God-like intelligence that is itself smarter than collective biological intelligence. And then there is the concept of 100,000 worker bees, each trained and specialized to do one or even a few tasks quite well. The messiah AGI is trying to make a system with the intelligence to perform all the tasks that run a modern enterprise. By contrast, the more humble goal of the worker bee AGI’s is to learn from and augment their human supervisors; and make them much more productive.
There’s a big distinction between creating a messiah AGI and making 100,000 worker bees productive. And our premise today is the data, processes, know-how and tooling to build the latter isn’t generally accessible to foundation models trained on the Internet. Even with synthetic data generation, there are critical missing pieces which we’ll discuss below.
Comparing a Few Leading LLM Players
Let’s take a look at the current ETR data with respect to LLMs and Gen AI players.
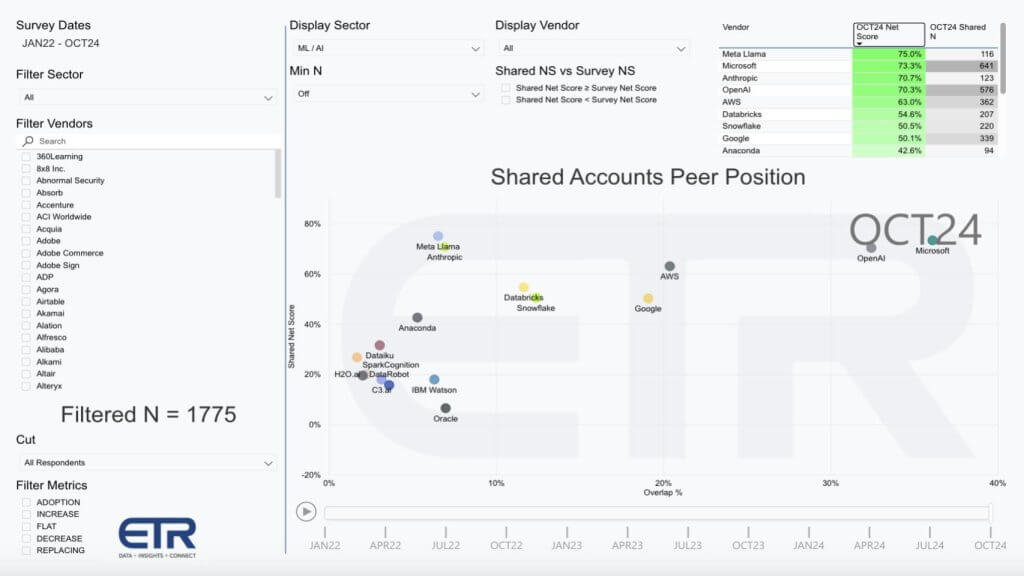
This XY graph shows spending momentum or Net Score on the vertical axis and Overlap or penetration in the data set on the horizontal plane. OpenAI and Microsoft lead in momentum and penetration while the gap in AI between Google and AWS continues to close. Databricks and Snowflake are coming at this from a foundation of enterprise AI while Meta and Anthropic’s position is directly each other, albeit with different strategies. IBM and Oracle are clearly focused on the enterprise and then we show a mix of legacy AI companies clustered in a pack.
In this picture, Microsoft, AWS, Databricks, Snowflake, IBM and Oracle are firmly in the enterprise AI camp, as is the pack; while Google, Meta, Anthropic and OpenAI are battling it out in the foundation model race.
A final point that we want to stress is that building standalone agents on we’re calling Messiah AGI foundation models will be effective for simple groups of concepts and applications. But to really make agents in the enterprise work, we’re going to need a base and tooling to build swarms of agents. That’s vastly more sophisticated and different from the tools to build single agents.
And we’re going to dig into this point at the end of this note.
Why Jamie Dimon is Sam Altman’s Biggest Competitor
Let’s get to the heart of the matter here – i.e. Enterprise AGI and the unique data and process advantage firms possess. Below is a graphic from Alex Wang of Scale AI which shows that GPT-4 was trained on ½ PB of data. Meanwhile, JPMC is sitting on a mountain of data that roughly is 150PB in size. Now more is not necessarily bette so this could be misleading. But the point is JP Morgan’s data estate inherently contains knowhow that is not in the public domain. In other words, this proprietary knowledge is specific to JPMC’s business and is the key ingredient to its competitive advantage
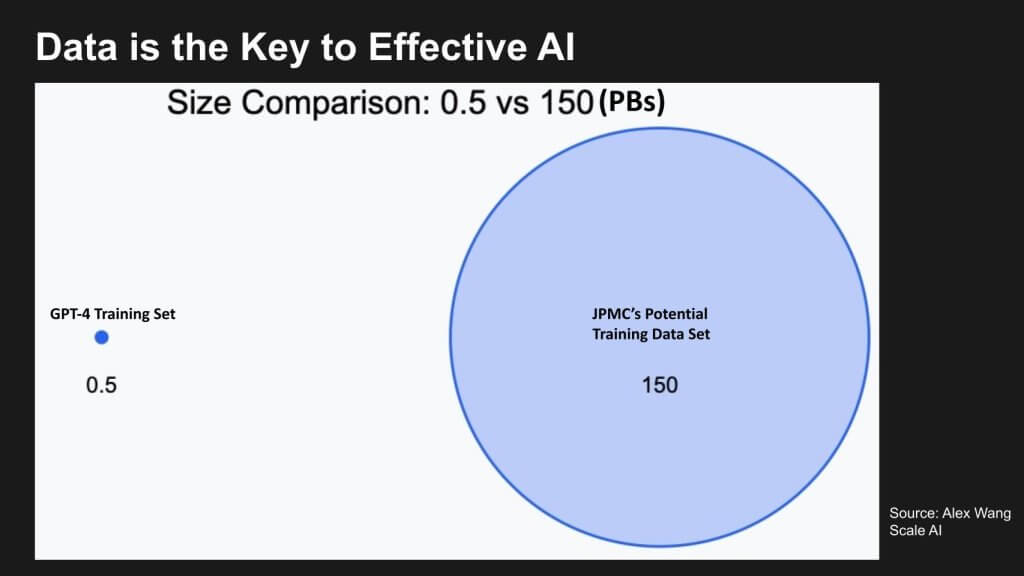
The foundation models that we’ve been talking about are not hugely differentiated. They are all built on the same algorithmic architecture deriving from the transformer. They all progress in size, which we’ll explain. And they all use the same compute infrastructure for training. What differentiates them is the data.
Now it’s not a straightforward conclusion to say that because JP Morgan has 150 petabytes and GPT-4 was trained on less than one petabyte that all that data JPMorgan has can go into training agents. But it’s a proxy for the fact that there is so much proprietary data locked away inside JP Morgan and in every enterprise that the foundation model companies will never get their hands on.
In our view, this data is hugely important because this is what you use to train the AI agents. It’s data that agents will learn from including by observing human employees and capturing their thought processes. And much of that data is not even in that training data set. That’s tacit knowledge currently. The AI companies call this “reasoning traces” because it captures a thought process. It helps you train a model more effectively than input-output matchings. The LLM model companies will never be able to train the public foundation models on these reasoning traces that are core to the know-how and operation of these firms.
That’s why the swarm of workflow agents, which are really specialized action models, collectively have the ability to learn and embody all that management know-how and outperform Sam’s foundation model. Again, we say collectively. So the 100,000 agents as a swarm or the million agents as Jensen referred to them, it’s the collective intelligence of those that outperforms the singular intelligence in a frontier foundation model.
The Internecine Economics of Foundation Model Building
The foundation model vendors are battling it out, chasing what we’re calling a false grail; and as we said in our open the stakes are insanely high.
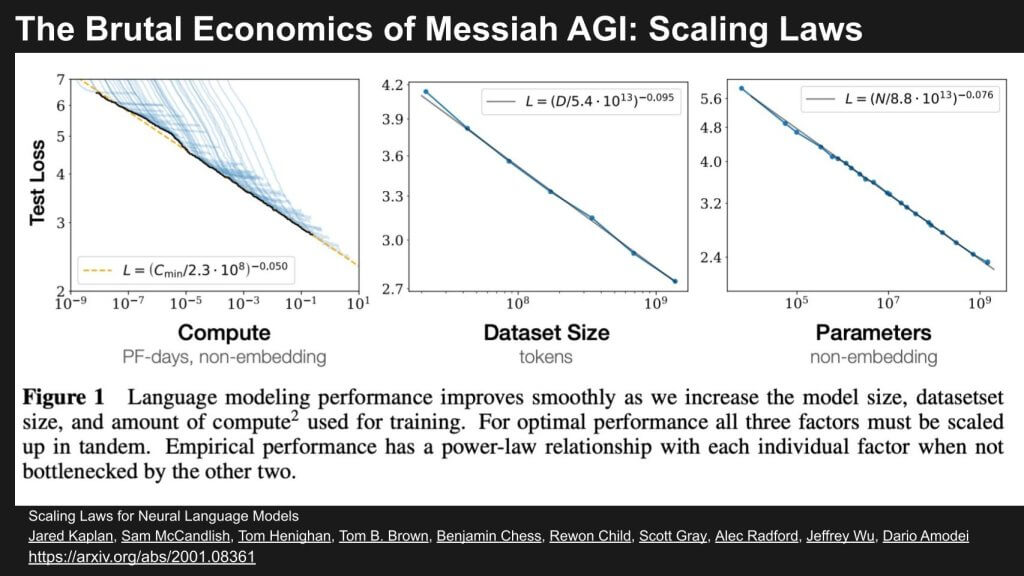
The graphic above illustrates the relationship between test loss and three key factors—compute, dataset size, and parameters. All three are critical to scaling language models effectively. Each panel represents how test loss changes with an increase in one of these factors, while the other factors are held constant.
- Compute (left panel): The graph plots test loss against compute measured in PF-days (petaflop-days), showing a declining trend in test loss as compute increases. The relationship follows a power-law, indicating that as compute grows, test loss decreases, but at a progressively slower rate. The dashed line represents an empirical formula for loss, with a scaling exponent of approximately -0.050. This means returns diminish when reducing test loss solely by increasing compute without scaling the other factors proportionately.
- Dataset Size (middle panel): This graph shows the impact of dataset size on test loss, with the x-axis representing tokens. As the number of tokens grows, the test loss again declines according to a power-law with a scaling exponent of around -0.095. This implies that expanding dataset size contributes to improved model performance, but, similar to compute, there are diminishing returns when dataset size alone is scaled without corresponding increases in compute and the number of parameters.
- Parameters (right panel): The third panel shows test loss relative to the number of parameters in the model. Increasing the number of parameters results in a reduction in test loss, following a power-law relationship with a scaling exponent of about -0.076. This means that adding parameters enhances performance, yet the benefit plateaus if dataset size and compute aren’t scaled in tandem.
Bottom LIne: The data tells us that language model performance improves smoothly as we scale up compute, dataset size, and parameters, but only if these factors are scaled in harmony. But staying on the frontier is brutally competitive and expensive. Continuing with our metaphor, Jamie Dimon doesn’t have to participate in the competitive race…rather he benefits from it and applies innovations in AI to his proprietary data. [Note: JPMC has invested in and provided lending support to OpenAI].
More Salt in the Cost Wound
The previous data shows the brutal economics of cost of scale. Each generation of model has to increase in size and compute data set size and parameter count. And these must increase together to stay competitive. But when you increase them all together, if you look in the right-hand table above, Gemini Ultra, for example, already cost close to costing $200 million for its training.
And the chart below that company named Epoch AI put together shows that the cost of training has been going up by 2.4X per year. And there are factors that may actually accelerate that.
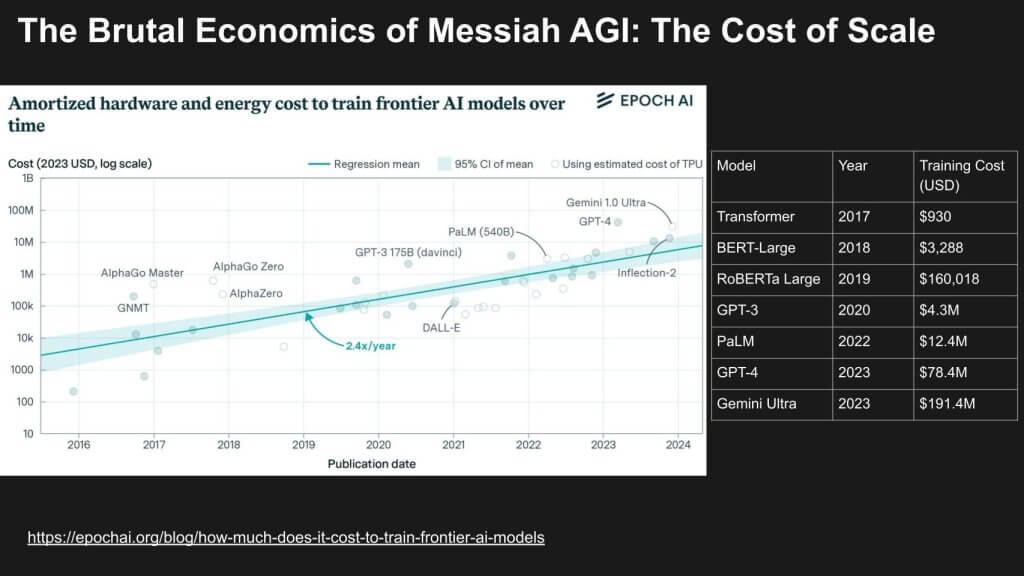
For instance, long context windows, we believe that’s the feature of Gemini Ultra that made it perhaps so much more expensive (multiple times more expensive) than GPT-4. And then there are other techniques like over-training the model so that it’s more efficient at inference time or run time. The point is, there’s this enormous amount of capital going into improving the base capability, but it’s not clear how differentiated one frontier model is from the next.
Costs Increase but Prices are Dropping Quickly
The other concerning factor here is that not only are models are getting increasingly expensive to develop and improve, but pricing is dropping like a rock!
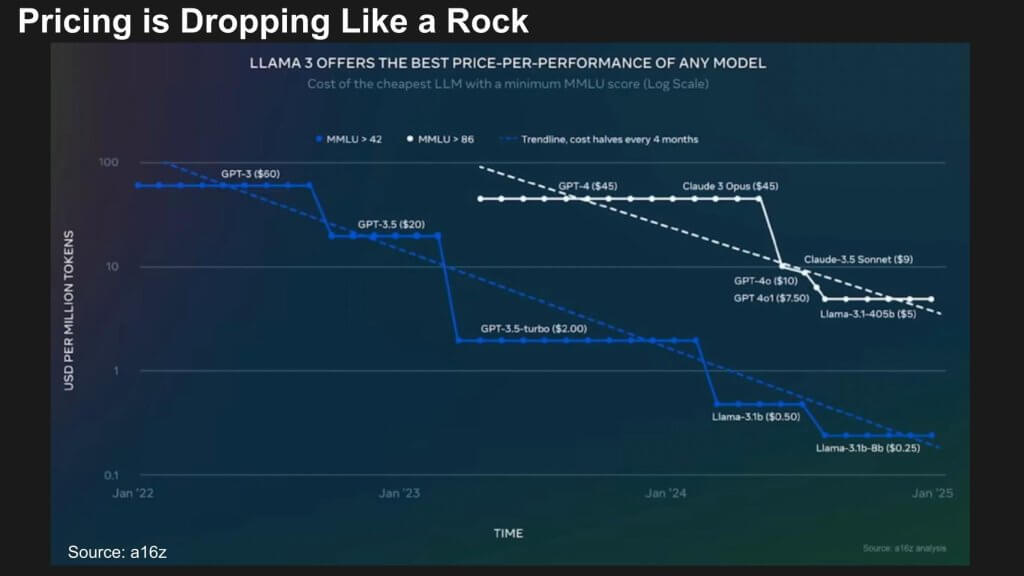
The chart above shows prices dropping by four orders of magnitude in the span of three years for GPT-3 class models. GPT-4 class models are on pace to drop two orders of magnitude within twenty-four months after introduction.
The point is, competition drives down prices and organizations can leverage advanced language models more economically, facilitating wider AI integration across sectors. And, as many have predicted, this could lead to a commoditization of foundational models.
Enter Zuck and Elon with Open Source Models
On the previous slide we showed OpenAI and Anthropic and didn’t even include Gemini. In the latter years we have Meta with is Llama 3, which as shown in the ETR data is really becoming adopted by companies, including enterprises and ISVs in their products. Musk stood up an H-100 training cluster faster and larger (apparently) than anyone. It’s not completely done. But the point is there are more frontier class competitors pouring into the market. And we already see prices dropping precipitously, so the economics of that business are not that attractive.

Other open source players such as IBM with Granite 3.0, while not trying to compete with the largest foundation models, provide support for the thesis around Enterprise AGI, with models that perhaps are smaller but are also sovereign, secure and more targeted at enterprise use cases.
The frontier risks turning into a commodity business. The models, while likely to have some differentiation, require so much resource to building that it seems likely to severely depress the prospect of compelling economic returns.
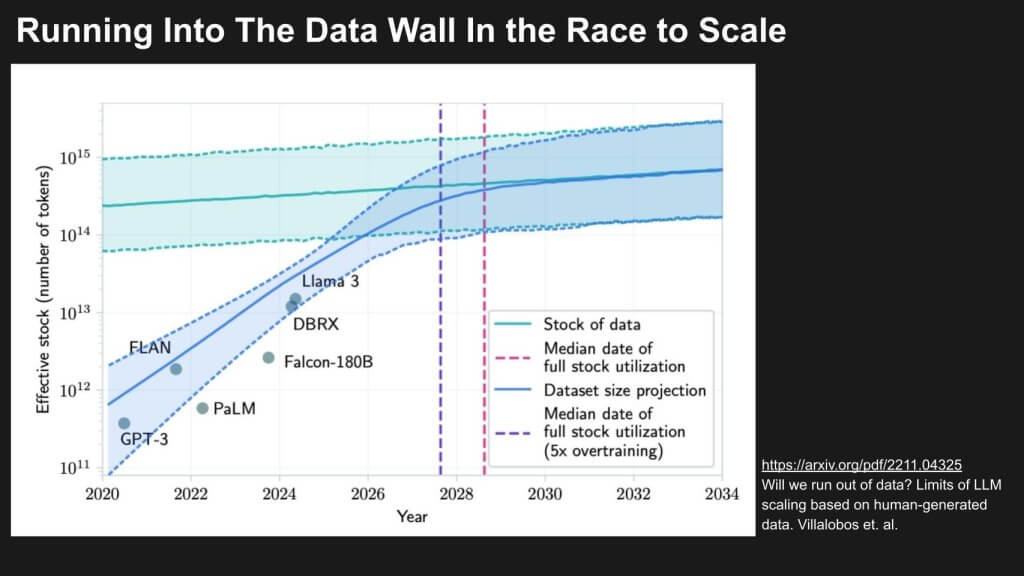
More Bad News: LLMs Hitting a Data Wall
Below we show that without new approaches to data generation or efficiency, scaling LLMs may soon face diminishing returns, constrained not by compute or parameters but by the availability of high-quality data. Because of the scaling laws, we need to keep scaling the training data sets But we’re running out of high quality tokens on the public internet.
What About Synthetic Data Generation?
A key solution to the problem is synthetically generated data, but it can’t be just any data that a model generates. The data actually has to represent new knowledge, not a regurgitation of what’s already in the models. And one way it can do that is with data that can be verified in the real world like computer code or math because it’s the verification process like running the code that makes it high quality data– because you can say this is new. Generating it was a hypothesis, testing it and validating it makes it new knowledge that’s high quality. But the issue is even though you can do this with code and math, it doesn’t actually make the models knowledgeable in all other domains.
That’s why the models need to lead to learn from human expertise.
What’s the Future of Synthetic Data?
This question is addressed in comments made from Alex Wang in a No-Priors conversation. Take a listen and then we’ll come back and comment.
Here’s what Alex Wang had to say on this topic of synthetic data production:
Data production…will be the lifeblood of all the future of these AI systems. Crazy stuff. But JPMorgan’s proprietary data set is 150 petabytes of data. GPT-4 is trained on less than one petabyte of data. So there’s clearly so much data that exists within enterprises and governments that is proprietary data that can be used for training incredibly powerful AI systems. I think there’s this key question of what’s the future of synthetic data and how synthetic data needs to emerge? And our perspective is that the critical thing is what we call hybrid human AI data. So how can you build hybrid human AI systems such that AI are doing a lot of the heavy lifting, but human experts and people, the basically best and brightest, the smartest people, the sort of best at reasoning, can contribute all of their insight and capability to ensure that you produce data that’s of extremely high quality of high fidelity to ultimately fuel the future of these models.
Will Synthetic Data Allow FM Vendors to Break Through the Data Wall?
When Alex mentioned that the best and brightest need to contribute their reasoning and insight, highlighting his platform’s capability to gather data from possibly hundreds of thousands of contributors, it struck a chord of idealism. His vision, as he described, sounded reminiscent of Karl Marx’s famous line, “From each according to his ability, to each according to his needs.” This comparison might seem exaggerated, but it underscores a utopian vision, akin to the idealism of communism itself.

However, the reality is that such valuable knowledge and expertise, often the lifeblood of for-profit enterprises, isn’t likely to be freely extracted just by offering modest compensation. The insights and know-how embedded within these companies are too critical to their competitive edge to be willingly shared for a nominal fee. Jamie Dimon would be foolish to allow that to happen, despite his investment in OpenAI.
This is the real data wall…
The Enterprise Automation Opportunity is Enormous But Requires Specialized Knowledge
A premise we are working today is that enterprise AGI is a large opportunity for companies and most of the value created will accrue to these firms
Let’s examine this with a look at the Power Law concept that we’ve put forth previously from theCUBE Research and use the graphic below from Erik Brynjolffson.
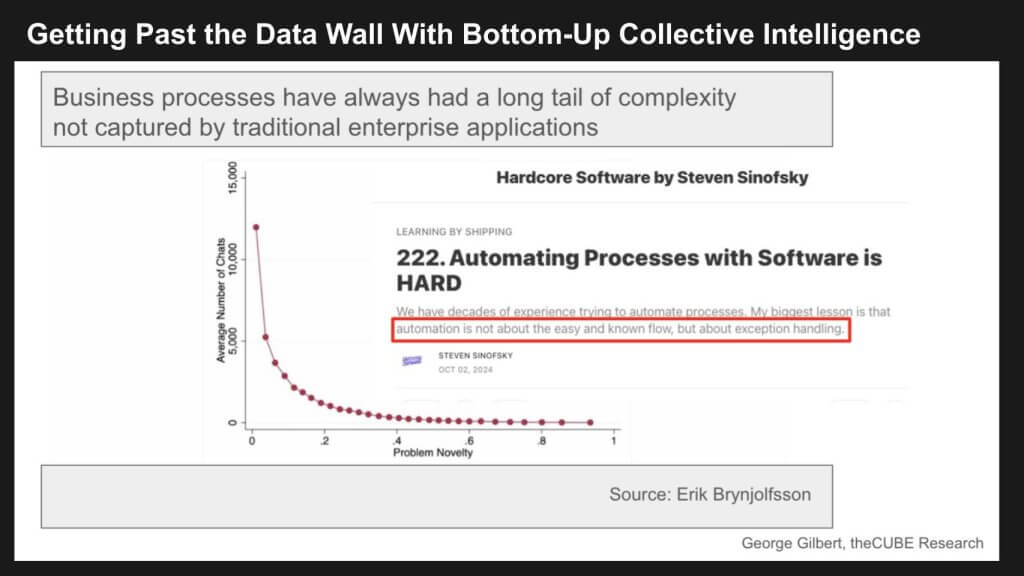
Automation of complex business processes has been historically so difficult because each process is unique and contains specific tribal knowledge. Enterprise apps have been limited in terms of what they can address (e.g. HR, Finance, CRM, etc.). Custom apps have been able to move down the curve slightly but most of the long tail remains un-automated.
As highlighted above in red, Brynjolfsson implies that horizontal enterprise apps are relatively straightforward to create and apply to automate known workflows, but unknown processes require an understanding of exception handline.
Agentic AI has the Potential to Automate Complicated Workflows
Below we’ve taken Brynjolfsson’s chart and superimposed agentic onto it. What we show is that for decades, we’ve solved high volume processes with packaged apps like finance. Everyone does finance the same way. HR is another example. Mid-volume processes were tackled with custom applications. But the economics of building custom applications was difficult because you had to hand code the rules associated with each business process. And each business process itself contained essentially a snowflake of variants that were very difficult to capture.
The reason we couldn’t get to the long tail of processes and the snowflakes within each process, is that it wasn’t feasible to program the complex workflow rules. So we see a future where agents can change the economics of achieving that by observing and learning from human actions.
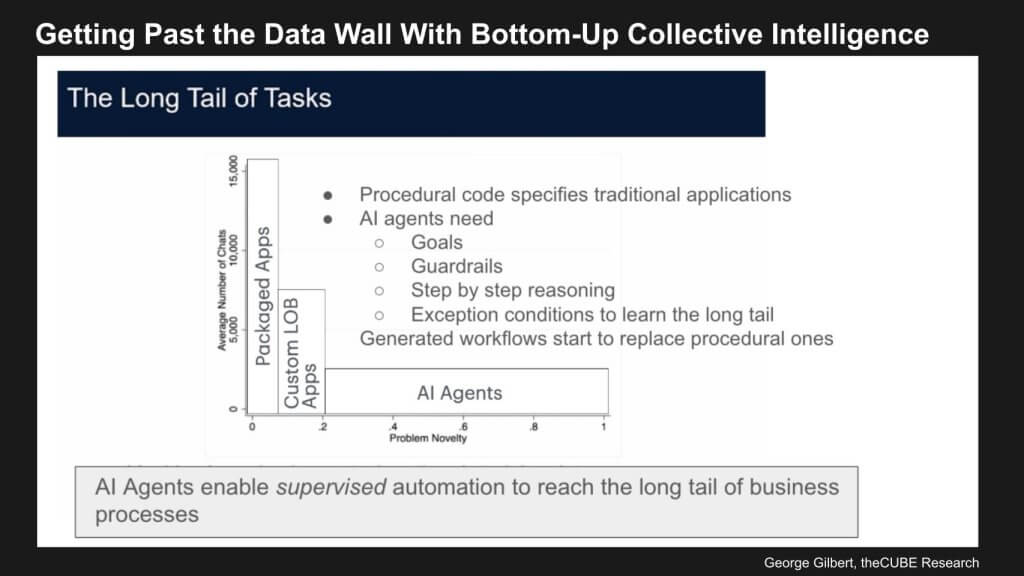
First, citizen developers give agents goals and guardrails. But just as important, agents can generate plans with step-by-step reasoning that humans can then edit and iterate. Then the exception conditions become learnable moments to help get the agent further down the long tail the next time.
Ok now we’re going to walk you through a little demo that explains: 1) The technology to learn from human actions is being worked on today; 2) agents can learn from human reasoning traces and exception handling and 3) There are still gaps to be filled that are fundamental to enterprise AGI becoming a reality.
Agents Learning from Humans
We’re going to illustrate this and walk you through a demo that underscores an example of how agents can learn from human reasoning traces. Specifically we’ll walk through a demo that explains: 1) The technology to learn from human actions is actually in market today; 2) That agents can learn from human reasoning traces on exceptions; and 3) There are still big gaps to be filled and that are fundamental to enterprise AGI becoming a reality.
The first slide of the demo below shows a screenshot from Microsoft’s Copilot Studio.
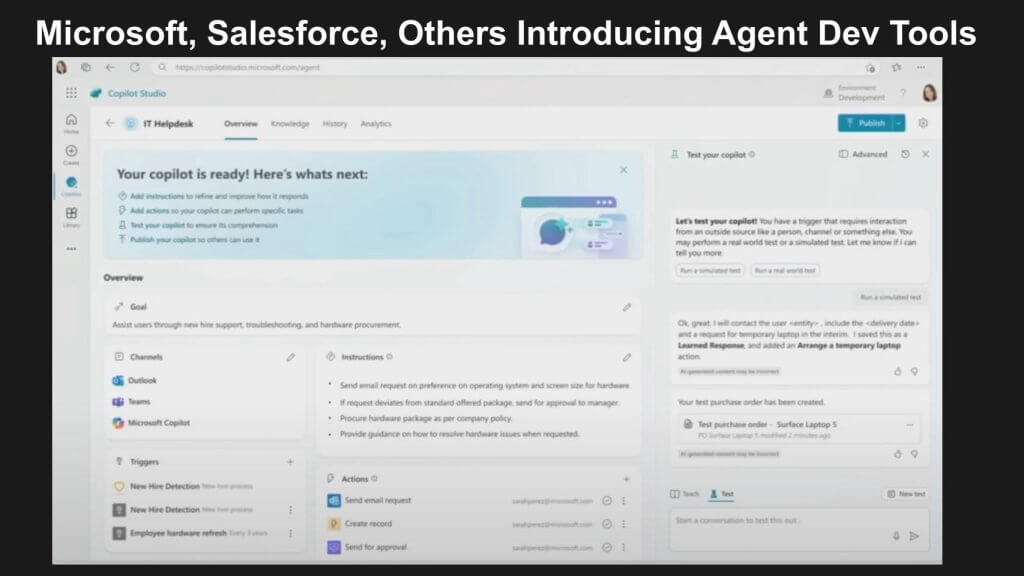
This capability is shipping today from companies like Microsoft, Salesforce, others. The key point is that agents can learn from their human supervisors. We’re looking at a screen above that is defining an agent which onboards an employee. It doesn’t take AGI, it doesn’t even have to be fully Gen AI business logic. It starts by leveraging existing workflows and figuring out how to orchestrate the long tail of activities by combining and recombining those existing building blocks.
An Agent’s Thought Process in Action
An agent’s real power is that they learn from exceptions while in production. This is the opposite of traditional software where you want to catch and suppress bugs before you go into production. Here, essentially you could think about a bug as a learnable moment.
Below this particular agent is onboarding a new employee and providing laptop options. The agent is showing you its thought process in the center pane (highlighted in red).
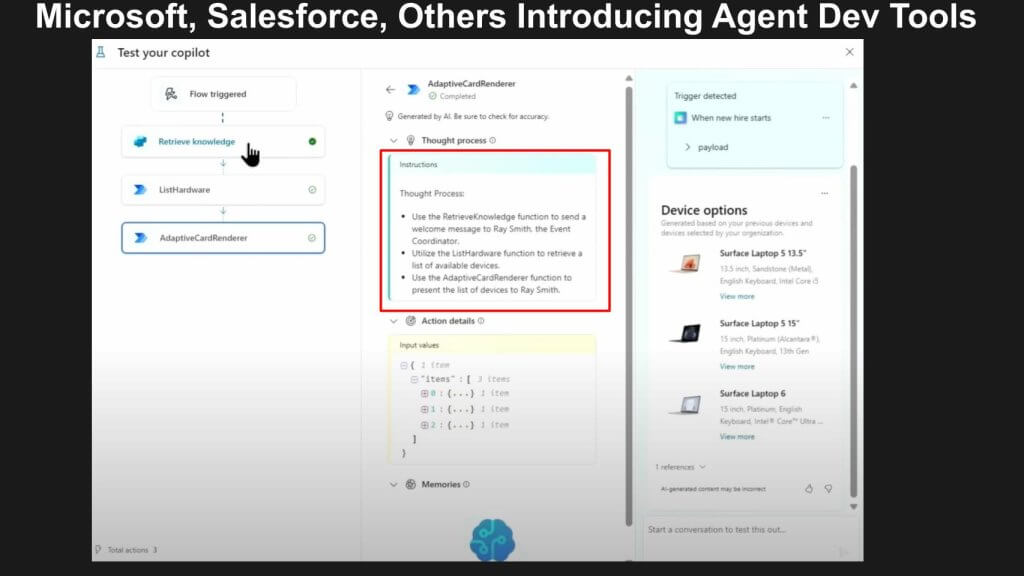
This is not actually what you would see at runtime, but in this example the agent is offering the laptop. The employee works in events and this particular employee needs a tablet, not a laptop. So the agent logs or captures a teachable moment that extends what the agent can do without going back to a human supervisor once it learns. And each teachable moment then extends the agent’s ability to move down that power law curve and handle more edge cases.
An Agent Learns from an Exception
Below we show an exception where the user wants something different (a tablet) than what’s offered on the standard menu. The machine can’t figure it out and the human has to be brought into the loop. The agent then learns from the human reasoning and the actions that the human took to satisfy the next step in the process. That action becomes knowledge embedded into this organic system.
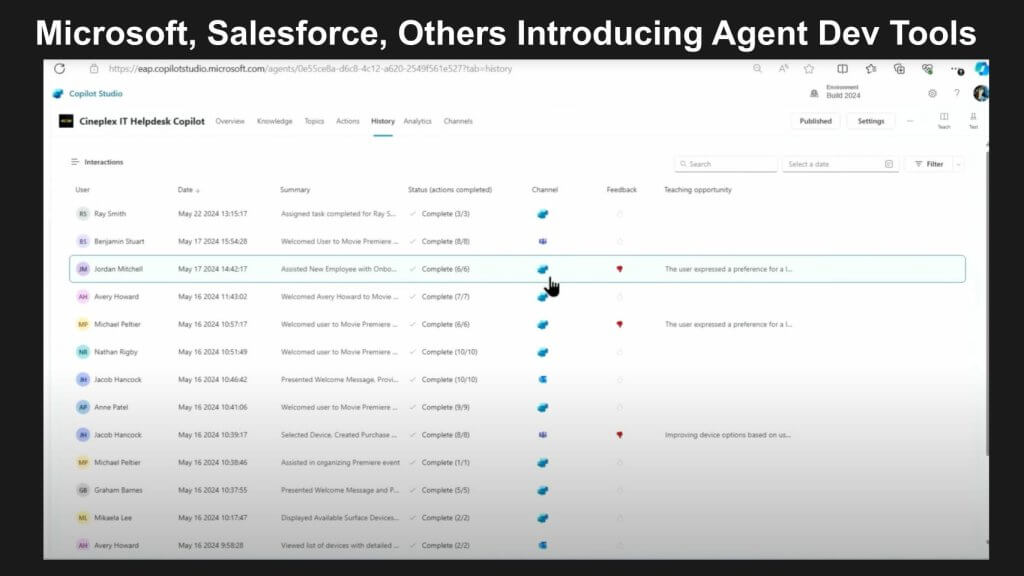
It’s worth pointing out that every row you see above is an instance of the agent having run its onboarding process. The little red mark on the row where the hand cursor points indicates an exception condition. And that was where the human who was being onboarded said, “the choices you’re giving me aren’t good enough.”
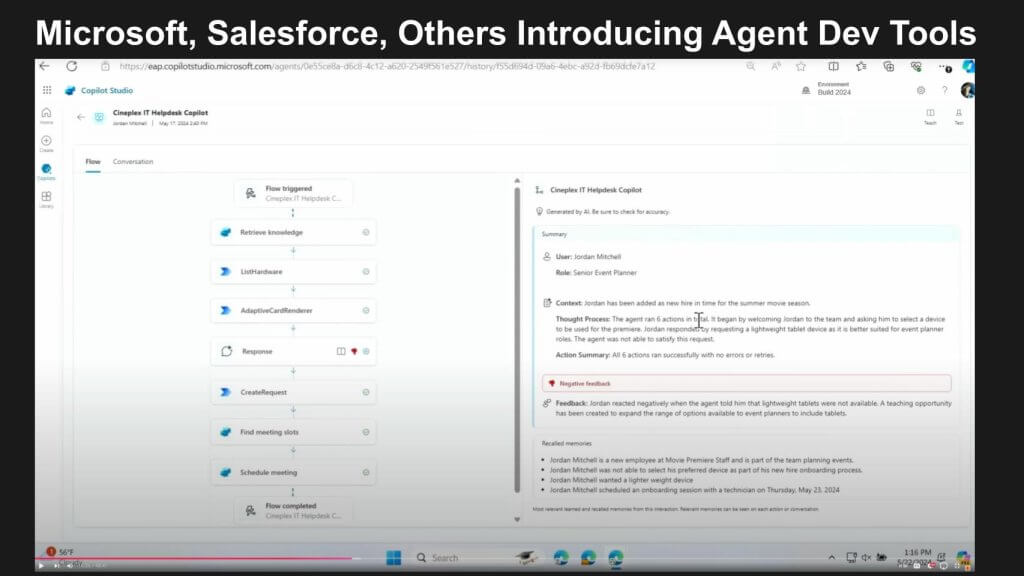
How the Agentic System Learns and Evolves
Below we show the feedback loop and how the agent learns and the system becomes more intelligent. On the right side is the thought process. There’s a little comment that says negative feedback, the system responds accordingly, then the agent knows that the user had that negative feedback. So it creates a potentially learnable step and it expands the range of tablet options without going through all the screens. And now, when an event planner is onboarded, the system adds tablets to the menu.
Advancing Seven Decades of Automation
Let’s take a step back and put this into the context over the history of the information technology industry and automation specifically. Computing initially automated back office functions, and then it evolved into personal computer productivity. In the tech industry we like to talk about a series of waves where each subsequent wave abstracts the previous generation’s complexity away.
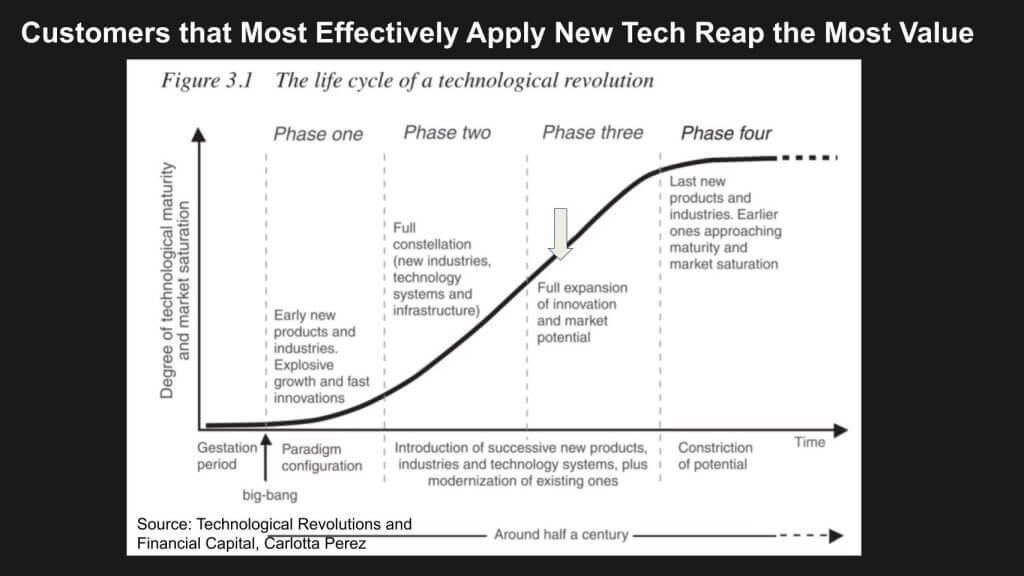
It’s worth pointing out the above chart is from Carlota Perez’s very famous book Technological, Revolutions and Financial Capital. When you go through a wave towards the mature end of the wave, it is the people building on the technology who reap the benefits. And that’s the ultimate message we’re really saying here that the foundation models are enormously capital intensive and talent intensive, but all the data and knowhow that turns data into business value lies locked up inside the enterprises that are not going to be feeding the frontier model companies. In other words, it’s the enterprises who are going to get the big benefits.
Foundation models are enormously capital intensive and talent intensive, but all the data and knowhow that turns data into business value lies locked up inside the enterprises that are not going to be feeding the frontier model companies. In other words, it’s the enterprises who are going to get the big benefits.
Emerging Technology Layers are a Missing Ingredient
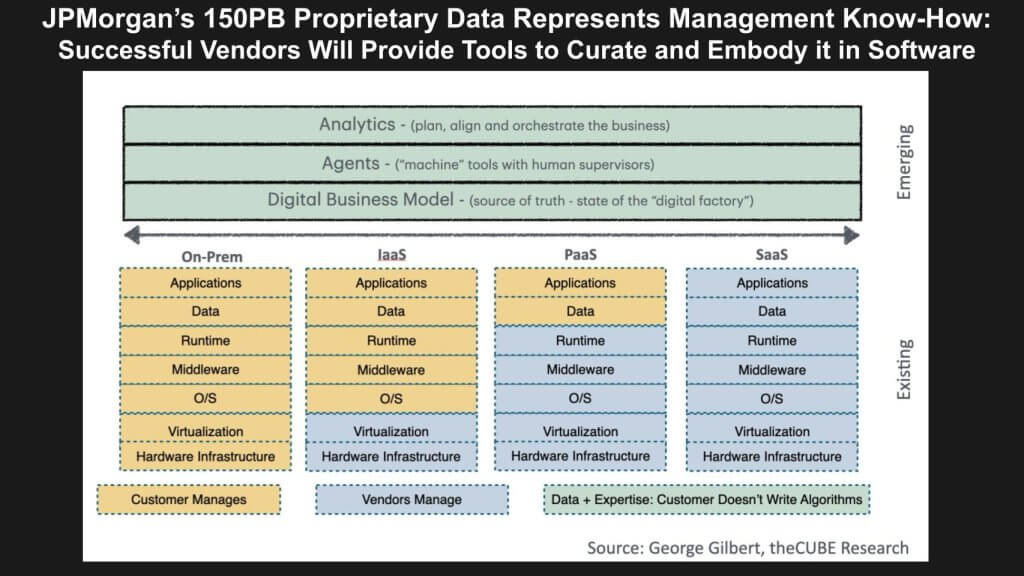
Below we show the evolving technology stack and the impact AI will have on the vision of enterprise AGI. The ongoing evolution of technology infrastructure represents a shift towards a dynamic, interconnected framework that enables a real-time digital representation of an organization. As enterprises increasingly rely on an ecosystem of cloud-based services—Infrastructure-as-a-Service (IaaS), Platform-as-a-Service (PaaS), and Software-as-a-Service (SaaS)—technology becomes the core enabler of modern business models. This integration supports an environment where data resides everywhere and is accessible, governed and trusted. Emerging capabilities, like digital twins, present the vision of a unified, organic system that mirrors the people, processes, and resources within an enterprise, forming a shared and actionable source of truth.
For the collective intelligence of 100,000 agents to work, they need a shared source of truth. The green blocks below represent the data harmonization layer that we speak about so often. And the agent control framework we’ve discussed in previous Breaking Analysis episodes. It also shows a new analytics layer that can interpret top down goals and deliver outcomes based on desired organizational metrics.
Integrating and harmonizing islands of automation and analytic data that have accumulated over decades requires coordinating the data harmonization layer with the armies of agents.
The last decades in on-premises and cloud data lakehouses and warehouses has mostly been an attempt to organize data from operational applications in order to answer questions about what happened. But traditional SQL databases are really only good at answering this type of question about people, places, and things – and it takes quite a bit of effort to harmonize raw data “strings” into all those real world “things.”
Aligning the work of agents to work across harmonized business processes requires a different type of database to serve as the collective source of truth. These databases have to be better at tracking and analyzing activities. They have to be able to answer questions such as why did something happen within or across processes, what is likely to happen, and what should we do next? Answering those questions requires organizing people, places, things, and activities into a knowledge graph.
And just like users of an enterprise application work off a shared source of truth, we will need a larger-scale source of truth for all human and agent workers to share. The irony is that for all the hundreds of agent-based startups, there are far fewer entrants building what could emerge as their source of truth. Early entrants in that category are Celonis, Palantir, RelationalAI, and EnterpriseWeb.
Salesforce is the mainstream vendor farthest along in integrating its suite of operational applications, low/no code agent tools, and its Data Cloud as a harmonized source of truth. The Data Cloud, however, hasn’t yet made the transition to analyzing processes as well as the new vendors.
Microsoft offers a rich set of low/no code tools to build agent-based applications. Its unique value proposition is that its tools work across the entire Microsoft product line, from the desktop applications, the business applications, to all the Azure services.
UiPath is another vendor showing how to upskill its existing customer personas from building RPA bots to agents. We expect to see other vendors follow this lead in upskilling existing personas.
Vendors and customers face a great opportunity in extracting more value from decades of existing investments. By harmonizing the data and application estate, humans and AI agents will be able to work together much more effectively and productively toward common goals than is possible in today’s silo’d world.
Tell us what do you think.
Do you believe that the massive investments going to foundation models are misguided in a quest for fools gold? Or do you believe one model will rule them all, including enterprise AGI? What do you think about this concept of Enterprise AGI? Will FM vendors like OpenAI ultimately develop a business model that dominates and captures most of the value? Or do you believe enterprises will leverage the hundreds of billions of dollars pouring into AI and Gen AI for their own proprietary benefit?
Let us know…


