
The shift to service as software will bring learning curve advantages, software- like marginal economics, and winner- take- most dynamics to all companies across every industry, not just tech vendors. We believe those firms that can more quickly jump on the AI experience curve will see substantially increased benefits relative to their competitors. However, our research suggests that data management complexity and lack of adequate data protection are key risk factors for Chief AI Officers, CTOs, and those line of business heads that are architecting their companies’ AI futures.
In particular, our survey data indicates nearly 70 % of firms protect less than half of their AI- generated data, the very data that will deliver the competitive advantage promised by AI. Moreover, there seems to be quite a dissonance between the perceived and actual maturity of AI capabilities, with serious gaps in areas like cyber, regulatory compliance, governance, and data integration capabilities that we believe will challenge AI outcomes.
In this Breaking Analysis we bring you the zero- loss enterprise, data resilience as an AI service layer. In this episode, Christophe Bertrand presents fresh survey data on this topic, supported by members of TheCUBE research team, including Bob Laliberte, Paul Nashawaty, Jackie McGuire, and Scott Hebner, who will each present their analysis. We’ll share specific results of a recent study designed to gain insight on how data protection is evolving in the AI era, and the degree to which critical AI data are being protected today. We’ll also share some AI ROI data from ETR and cast an eye towards what has to happen in the future to ensure that firms’ most critical assets, i. e their data, are protected and AI-ready. Finally, we’ll examine the practical difficulties of achieving a zero- loss enterprise in the future.
Objectives of the Research
This research follows on from the insightful conversations during the data protection and AI summit earlier this summer. So we went out and did more research on the topic in North America, 300 respondents, very well qualified, and we really wanted to know what data protection IT professionals, infrastructure specialists were thinking in terms of protecting the nascent AI infrastructure, as well as leveraging AI itself as part of their processes.

App/Dev and Cyber Resilience
Before we dive into the survey data, let’s look at the relationship between App/Dev and how it’s changing in the service as software era, specifically in the context of business resiliecnce. To do so we asked Paul Nashawaty, who heads our App/Dev business to weigh in.
[Watch Paul Nashawaty’s analysis]
We believe the impact on cyber resiliency and data protection under services-as-software reflects a fundamental shift in how enterprise software works. The old SaaS model—people operating tools—gives way to a world where software is the operator. AI-driven systems do not just observe; they decide, act, and learn. This creates a $4.6T opportunity (Forbes), but it also transforms security, resilience, trust, and accountability.
What this means for developers. Coding must encode intent – meaning every action should be authorized, auditable, and reversible. DevOps pipelines evolve from merely shipping software to validating automated behavior. Observability moves beyond uptime and basic tracing to understanding what actions occurred, by whom/what, and why.
Platform engineering becomes the stewards of governance. Their mission is to secure the model control plane, enforce policy runtimes, and ensure every agent decision is provable, authentic, and reversible. Our CUBE Research readout indicates 92% of developers say they need modern platforms to innovate; 87% of IT leaders view observability as essential. Even so, data quality remains a major barrier.
The bottom line is cyber resiliency, data protection, and app dev now live everywhere from code to cloud. Organizations are baking resiliency into every layer of the systems that will own digital business, and in this new era resiliency is the business model.
Broader implications we see emerging:
- Security & resilience as imperatives. The shift beyond SaaS demands authorization, auditability, and reversibility across the developer experience and the entire application lifecycle.
- Developer transformation. Developers define actions (not just APIs) with clear context and rollback rules. Model prompts and data pipelines become versioned and governed dependencies. Unit testing evolves to validate intent safety.
- DevOps re-imagined. Pipelines validate behavioral compliance, not just deployment success—no more “push the big green button” and call it done.
- New resiliency metrics. We see the rise of AMTT / MTD (mean time to detect unauthorized access or actions) and AMTTR (mean time to reverse), plus chaos agents for testing agentic behavior under stress.
- Platform engineering & governance. Data-driven oversight expands: 92% need modern tools; 87% call observability essential; 75% report a push toward observability tools for all; 81% of CIOs view sustainability as a software decision maker; and cloud-native modernization can cut carbon footprint ~30%.
In the services-as-software era, software is the business. Winners will build resilience by automating trust and transparency so that automation itself becomes part of their coverage and control surface. A lot is happening and in our view, it’s just the start.
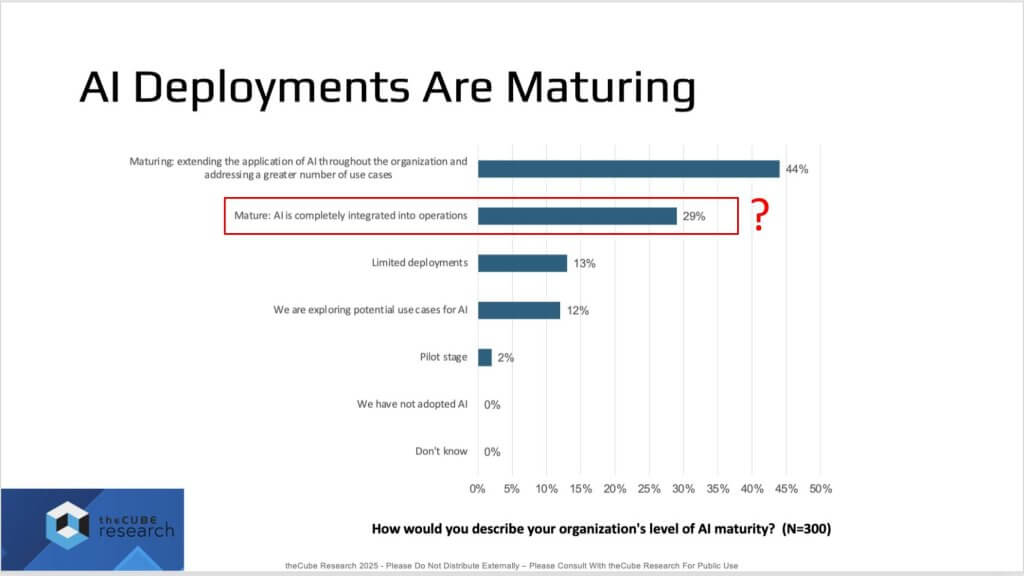
IT Practitioners Believe AI is Maturing…But There’s a Catch
We believe the latest readout (n=300) captures the paradox of this moment. When asked “How would you describe your organization’s level of AI maturity?” a meaningful cohort reports they are maturing/in process, but the standout is the second bar — “Mature: AI is completely integrated into operations.” That headline result is striking. Our interpretation is these responses come primarily from IT infrastructure professionals, and some enthusiasm bias is likely. Integration may be real but scoped – maturity in specific processes, not across the entire enterprise. The takeaway is AI is unavoidable and in flight; the open questions are how it will be implemented and whether it will be implemented correctly. The whole enterprise is not “run by agents.”
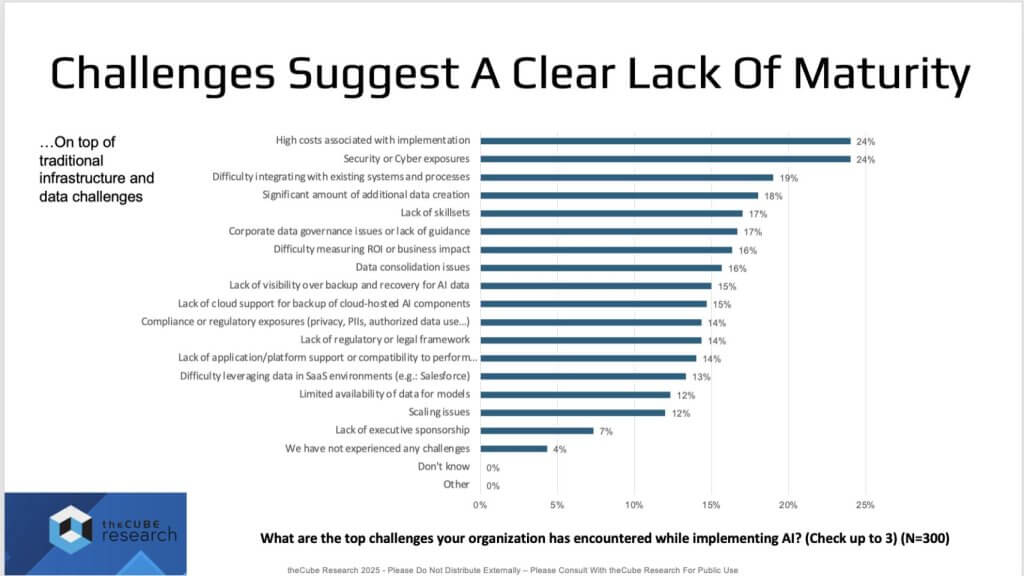
Top Challenges Indicate AI Maturity is Lacking
The next cut – Top challenges – underscores the lack of broad maturity. Respondents selected three items (a “pick-your-poison” popularity ranking). The top two are decisive – i.e. cost and cybersecurity/cyber-resilience. Below that sits a common mix of maturity issues (integration, ROI, readiness) we’ve seen in prior waves including cloud, virtualization, containers, etc. where the narrative was “not quite ready for prime time.” The difference now is an acceleration of investment and an arms race – despite the lack of clear ROI in many cases.
ETR Data Generally Aligns with the MIT Lack of ROI Study
A recent MIT study suggesting 95% of AI projects have failed to deliver tangible ROI, has been a frequent topic of discussion in the tech community. Fresh ETR drill-down data supports the direction of these findings as shown below.
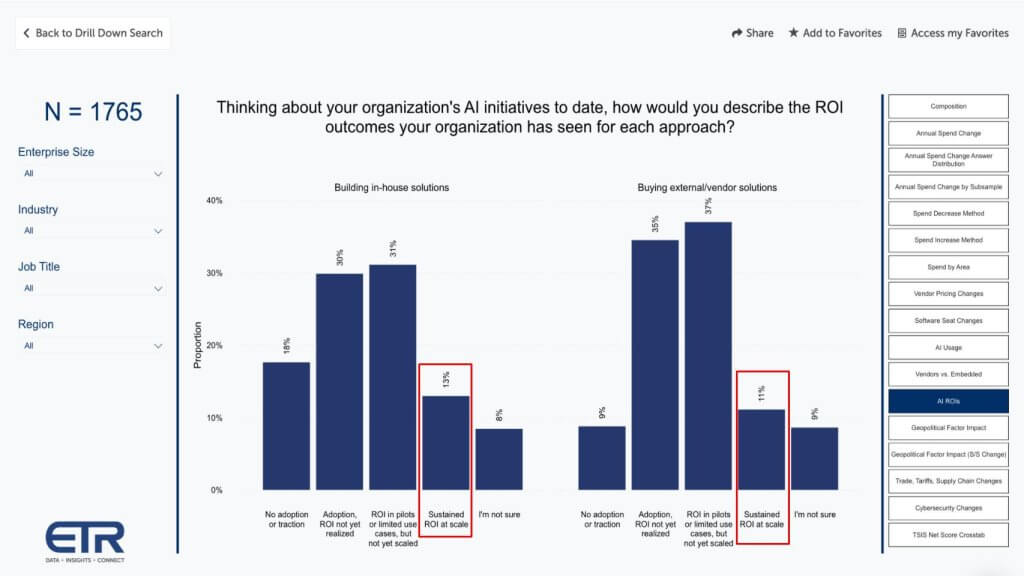
When comparing build in-house vs buy external, the share achieving sustained ROI at scale is small, much closer to the MIT finding that ~5% of production deployments are seeing clear ROI. In our view, three forces drive this dissonance:
Scope — Early implementations are narrow. They may be “mature” within limited domains, not enterprise-wide.
Scale — Everything works “until you add at scale” to the sentence. Many deployments are hitting that wall.
Data — Teams often don’t know where the right data is, or it’s non-compliant and ungoverned. Guidance is thin, exposures are real, and prudent capital allocators can’t simply deploy systems.
The metaphor we’ve been using is it’s like you’ve built a powerful plant and we’re learning to harness nuclear-grade energy…but the control systems aren’t fully installed. That is a dangerous game. Our research indicates the market will move forward regardless; the winners will be those who scale beyond deployment wins, get costs and cyber-resilience under control, and put the governance “controls” in place before turning up the AI dial to the max.
The Network Becomes the AI Supply Chain – and the Security Perimeter
[Watch Bob Laliberte’s analysis of the importance of networking in data management and AI].
We believe the network assumes a strategic, not merely transport, role in the AI era. It becomes the foundational fabric that determines how quickly organizations learn, adapt, and scale AI. In this model, data movement is the product pipeline and every AI service depends on efficient flow between training environments, inference nodes, and edge users. That, in our view, requires programmable, API-driven, AI-orchestrated networks built on telemetry-rich fabrics with closed-loop automation. This leads to software-like economics and faster progress up the AI experience curve.
Our research highlights a critical risk in that 70% of firms protect less than half of their AI-generated data. The gap spans more than storage; it extends across the entire data transport layer. As AI workloads distribute, data protection must be embedded in the network, ensuring every packet is secure, governed, and compliant in motion. The bottom line is the network is now both the AI supply chain and the security perimeter. Enterprises that align data protection, network architecture, and AI operations will not only mitigate risk, they will create durable competitive advantage in an AI-driven economy.
Inference Is Rising as Data Becomes a Prime Target
We believe the industry’s fixation on “training vs. inference” somewhat misses the bigger picture in that inference is accelerating, and with it comes more data creation and a greater need for compute. In the survey cut below, titled “AI Data is a Key Target for Cyber Attackers,” 72 of 300 respondents (~24–25%) reported at least one AI infrastructure exposure. The leading hotspot is data at inference – the very focus of large swaths of AI activity.

Our analysis of the responses (with some category overlap possible) shows the top three exposures are data-related – a critical point that many AI leaders, hyperscalers, and data-platform vendors underemphasize (or gloss over) in our view. We double-clicked prior cyber-resilience research to isolate what this means in the AI context – even at early stages, even with ROI uncertainty, real exposures are emerging right now.
Compounding the issue, attackers themselves are AI-equipped. The result is an arms race where AI-driven adversaries increasingly target vulnerable AI investments. The implication is that enterprises must AI-enable their defenses or be outmatched. The blast radius is exceedingly wide and successful attacks can undermine models, corrupt data, or erode trust in outputs, putting the entire investment at risk. If data can’t be trusted or the model becomes untrustworthy, outcomes fail to deliver adequate returns – perhaps a root cause of limited ROI.
Looking forward, this risk becomes more acute as agents connect to other agents and begin making decisions autonomously. Organizations will need to prove causality – i.e. how a decision was reached – not just what decision was produced. The stakes are rising quickly but the controls are not. In our view, the market wants to run, but on security and governance we are still crawling.
Data Compliance Reality Check
[Watch Jackie McGuire’s analysis on data governance truths]
We believe a stark truth is being overlooked in that agentic and generative AI will explode data volumes in ways that organizations are not prepared for. Each training model – and the artifacts it produces – will likely require retention for significant periods of time. In highly regulated industries, that obligation is clear – e.g. healthcare records must typically be retained 6–10 years (e.g., Medicare – 10 years from date of service); Sarbanes–Oxley drives 7-year retention for many financial documents. Numerous sectors impose comparable mandates.
Complicating matters, we still don’t know how AI-generated interactions will be classified – as human-to-customer activity or machine-to-machine events. Absent new regulation, enterprises should assume they must store a lot of data for a long time. While many forecast labor productivity gains – or even labor substitution – we believe organizations will also incur significant costs for data retention and storage, plus the ongoing burden to secure that data.
Security requirements are rising. Encryption standards – and post-quantum cryptography efforts – are advancing quickly. If enterprises aren’t planning a 10-year horizon for sensitive datasets (e.g., Medicaid/Medicare), they risk future insecurity unless those records are kept with very strong physical and logical protections.
The operational reality is even more concerning as compliance means hiring and funding teams to ensure policies are followed and to monitor exponentially growing data volumes. In our view, the coming environment is a data jungle with dense, regulated, and costly compliance edicts where retention, governance, and security-by-design are as central to AI strategy as models and GPUs. Navigating it won’t be easy; ignoring it won’t be an option in our view.
Backup of AI Data Exposes Troubling Gaps at Scale
We believe the following data set is both clear and deeply concerning. When asked, “What percent of your organization’s AI-generated data is included in regular backups?” respondents delivered 0% “don’t know.” That’s rare – and it boosts confidence in the readout. Yet ~70% report backing up less than half of AI-generated data. Against retention norms – financial services ~7 years; healthcare ~7–10 years – this signals that critical AI data is not being backed up or protected. If regulators or courts require recreation and the data isn’t there, negative consequences may follow.
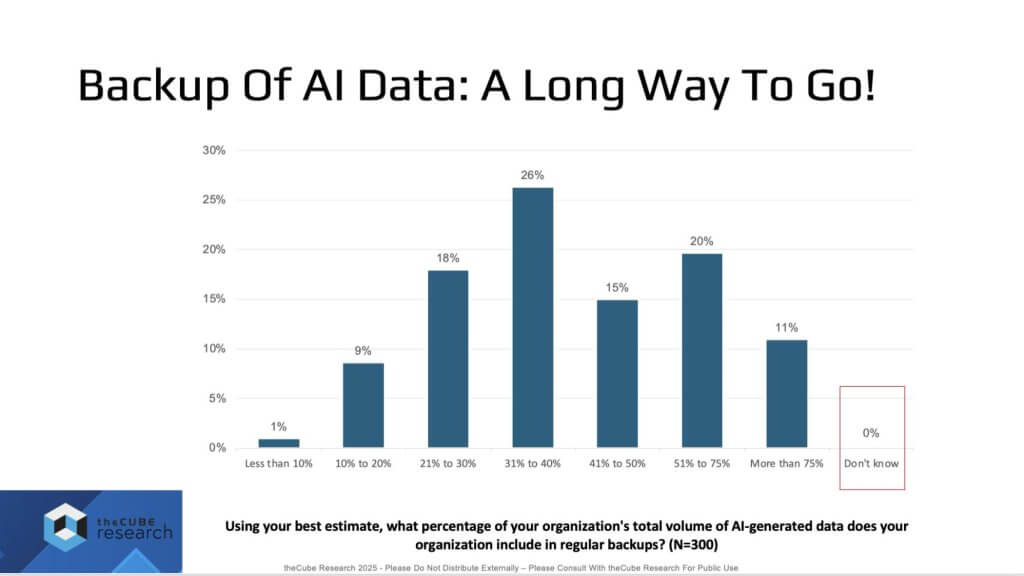
Our view, consistent with the survey design, is that IT infrastructure professionals answering – i.e. the people “stuck” with supporting AI infrastructure, storage, security, and networking. Their responses indicate that we’ve already invested, AI is generating lots of data (with far more to come), and we’re not protecting it. Backup is an afterthought.
We’ve seen this pattern with every new workload – i.e. best practices lag and must catch up – but AI is more than a workload. It’s a new operating model. The mandate is to return to basics and execute on the following:
- Locate & manage data — Where is it? Is it governed and ready for AI?
- Protect inputs — As data is injected into models, applications, and agentic frameworks, ensure appropriate backup and policy controls.
- Protect outputs & relationships — Retain and secure model outputs and the process linkages required for compliance and business resumption.
The bottom line is AI infrastructure is creating another data monster — not only to power better decisions, but also to protect itself while cyber attackers target the data directly. The operational and cost impacts are inevitable if this isn’t addressed at scale.
AI Data Loss is Expensive
We believe the costs of cyber attacks and data loss are well understood in terms of lost productivity, regulatory exposure, reputational damage, especially if data leaks to competitors. In our “AI Data Loss Hurts the Wallet” output, respondents delivered 0% “don’t know” by design – these are practitioners who understand the consequences of losing AI data that isn’t backed up. The most immediate impacts include personnel consequences (yes, people can lose their jobs) and compliance failures that damage the organization, on top of hard and soft productivity costs.
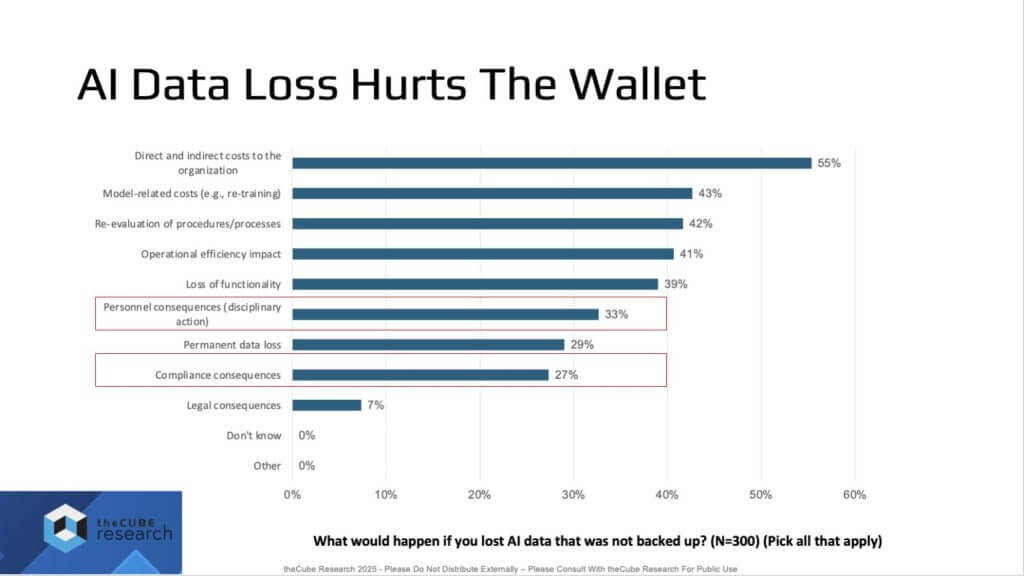
Our view is that compliance will increase in priority as AI deployment broadens and ROI materializes – because with scale comes greater risk and exposure and a mandate to comply. The burden often falls on teams that haven’t had clear guidance and must deliver backup and recovery for an environment that is constantly evolving — amid massive investments in compute and storage, and thus massive data volumes to protect.
What used to be a “boring” discipline – i.e. backup and recovery — is now more critical than ever. If data is the lifeblood of the business, and of the AI processes that power it, then backup and the ability to recover, regardless of cause (notably cyber events), must be top priority. This is an inversion of the current fixation on outcomes and a return to the source, back to basics, back to best practices. Watch the compliance line – it is likely to rise significantly as programs scale.
AI for Data Protection: Automate Recovery Now
We believe there are two sides to this story – data protection for AI and AI for data protection. Flipping that coin, the question becomes how do we improve recovery posture?
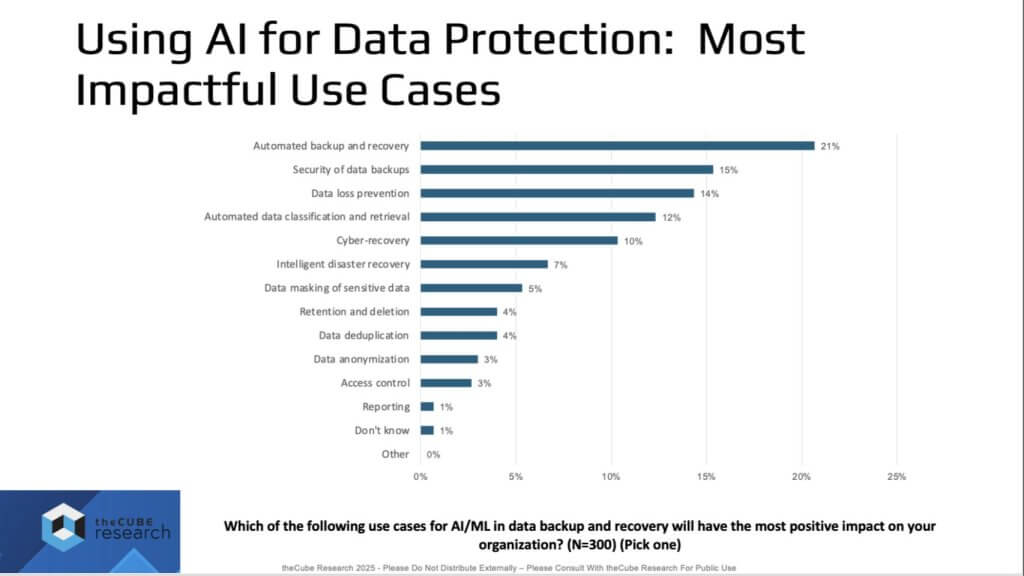
Our read of the above data (single-choice question, 100% response) is that the most impactful use case is automated backup and recovery. The “why” is there’s too much data, systems are too complex, and many IT operations teams are generalists – not PhDs in backup or AI infrastructure (at least not yet). The implication for the market is vendors in data protection, cyber recovery, and the broader data management stack must build automation-first capabilities.
There’s also a pragmatic reminder from the IT trenches – i.e. we’ve automated backup for years, but automation must now permeate the entire protection lifecycle, hardening both security and recoverability end-to-end.
One more point is on tape. We’re not deep-diving today, but our research includes substantial tape findings, and we believe tape has a strong future. AI will generate massive primary data and even more metadata (for compliance, causality, and explainability). That has to live somewhere economically viable. At scale, tape retains an economic advantage, and our data shows many informed decision-makers already view tape as critical for AI-era retention. We’ll cover the details in a separate analysis.
The bottom line is AI as a feature set has a crucial role to play in data governance and data protection – not only shielding the nascent AI infrastructure itself, but also automating recovery, tightening policy enforcement, and giving organizations a sustainable path to retain, prove, and restore at AI scale.
More AI in Backup & Recovery > More Investment > Vendor Shake-Up
We believe the industry is at another inflection point – akin to virtualization, cloud, and still-unfolding SaaS – this time centered on AI for data protection. When asked about forward-looking strategy for leveraging AI features, 51% of respondents say they will invest in data protection and favor vendors that embed AI in their solutions. That’s a big number for a capability that, two to three years ago, was often an afterthought.
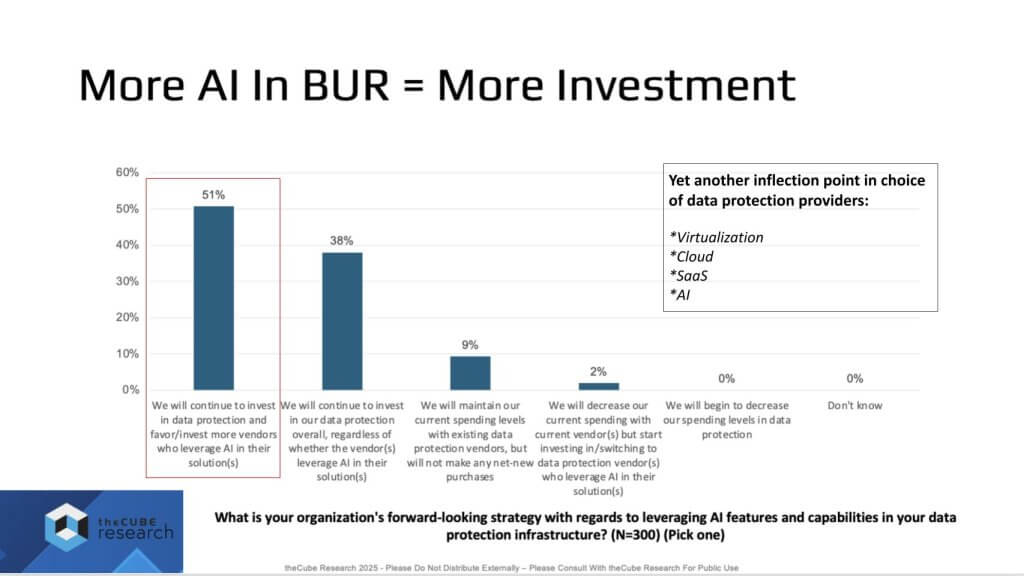
Market structure is shifting too. Cyber recovery and data management are converging, and we expect AI-driven protection to become a core requirement. Our research-led outlook indicates that 51% intent could climb to 75–80% in 18–24 months, at which point the question becomes moot because adoption is assured.
The bottom line is the leaders in what used to be “backup and recovery” (now effectively cyber recovery) will be the vendors that integrate AI deeply and wisely, expand functionality across data and cyber, and prove measurable gains. We’re already seeing the early moves in equity/M&A and roadmaps. We expect an escalating arms race.
Why the urgency? Teams must do a lot more with less as AI drives far more data and greater operational complexity. Buyers want vendors that make protection easier and smarter – using AI for automation, better support, informed recovery strategies, and automated DR planning. In our view, “AI-washing” won’t cut it. Vendors must deliver securely and intelligently, so customers can protect environments better and faster.
Trust & Governance: Immature Today, Big Investments Coming—Starting With Data
[Watch Scott Hebner’s Analysis on Trust and Governance]
We believe the data shown below underscores both the trust gap and the investment path. A new, comprehensive survey – the Agentic AI Futures Index (September; n=625 AI professionals across 13 industries, 9 professions, 3 countries) puts numbers to what many suspected.

Trust today: Average trust index 2.4/5. Only 49% of AI professionals and end users trust outcomes from AI agents—clear evidence of work to do.
Governance frameworks today: Only 29% report enterprise-wide standardized trust/governance frameworks in place. Current maturity index 2.8/5—slightly higher than trust because organizations are trying to address the gap.
Investment trajectory (next 18 months): Index jumps to 3.8/5 with 73% planning significant or strategic investments in trust and governance. The movement to fix the problem is real and near-term.
Where investment starts: The top control priority is data—provenance, assurance, and protection—cited by 72%. Data remains the lifeblood of AI: no trusted data, no trusted AI.

Picking up from this, the above graphic on Responsible Use of AI: Governance & Challenges shows very low “don’t know” and zero “other.” In our view, that indicates respondents clearly understand their obstacles and are converging on a known set of issues. Combined with the investment patterns above, the takeaway is that there’s a trust problem and immature frameworks today, but organizations are preparing to fund and operationalize solutions – beginning with data controls – to bring agentic AI into responsible, enterprise-scale use.
Responsible AI Governance: Invest, Reduce Complexity, Free the Data – or Don’t Expect AI at Scale
We believe the mandate is you must keep investing to reduce cyber exposure, improve cyber recovery, and lower cyber risk – there is effectively no choice. End users must fund it; vendors must expand capabilities across data governance, data management, and backup/recovery (which now extends into cyber recovery).
The core blockers are regulatory complexity, compliance, and data governance. Trust begins with the ability to secure, govern, and manage data for compliance – that is the baseline on which other AI trust components depend. The survey output below was a “pick-your-poison” popularity test; the lineup shows many overlapping, difficult challenges.

One challenge sits conspicuously in the middle at ~25% – leveraging data in SaaS environments. Many SaaS vendors keep data inside their walled gardens and promise their own agents to operate on it. The open question we see is should enterprises extract that data and operate on it themselves? The market will determine the “right” answer, but the control implications are significant.
Regardless, our conclusion is no compliant data and no cyber-resilient data = no AI data (at scale).
We believe the enterprise is crossing the threshold into service-as-software where systems of intelligence feed systems of agency, the network becomes both supply chain and security perimeter, and outcomes (not interfaces) define value. Yet the data shows trust is 2.4/5, only 49% trust agent outcomes, just 29% have enterprise-wide governance, ~70% back up less than half of AI-generated data, and inference data is already a top attack target. The arms race is here -a $4.6T opportunity on one side, AI-equipped adversaries on the other – while ROI at scale still looks like the MIT finding of ~5%.
Our research indicates winners won’t wait for perfect clarity. They will operationalize control as they scale – with governance catalogs as the point of control; governance of actions (not just APIs); agent observability with reasoning traces and data lineage; programmable, telemetry-rich, closed-loop networks; backup and recoverability as first-class (including economic tiers like tape); and Day0/1/2 practices with DevSecOps everywhere. Procurement will follow – 51% already favor data-protection vendors with embedded AI, and we expect that to rise toward 75–80% as cyber recovery and data management converge.
In our view, 2025–2026 won’t be the year of the agent—it will be the decade. The enterprises that align tech, ops, and business models now – treating data and resilience as the business model – will climb the learning curve fastest, convert marginal software economics into durable advantage, and define the control plane for the next era of enterprise computing.

