
The early-morning AWS outage on October 20–21, 2025, was a wake-up call for enterprise architects who still equate multi-AZ with business resilience. The incident exposed a fundamental truth about cloud dependence in that even the cleanest multi-AZ design can fail if your control plane isn’t autonomous. For roughly two hours, identity, DNS, and API calls tethered to US-EAST-1 were unreachable, breaking service discovery and throttling authentication across otherwise healthy compute resources.
In our view, this was not a failure of AWS infrastructure per se, rather it was a failure of completeness of architecture. Modern enterprises have built their businesses on top of shared control planes that cross regions and clouds. When those control planes fail, every region, zone, and microservice that depends on them inherits the problem.
Architectural Lesson: Multi-AZ does not Equate to Multi-Domain Resilience
Availability Zones were designed to isolate power, network, and hardware faults. They were never intended to protect against logical control-plane dependencies. The AWS incident showed that even when compute, storage, and networking are working, the services that orchestrate them – e.g. identity, routing, DNS – are not necessarily running as intended.
Enterprises must now think in terms of fault-domain isolation that spans not just zones or regions but control planes themselves; and potentially clouds. True resilience demands the ability to continue operating when the provider’s own orchestration layer falters. That means pre-deciding where autonomy is required in services such as DNS, IAM, service discovery, and data control. It is imperative to design for independence across regions or clouds.
This is where supercloud architectures emerge to create an abstraction layer that unifies underlying cloud primitives yet preserves the ability to fail over between them. Supercloud isn’t just a marketing term, it’s a resilience strategy.
Snowgrid: A Supercloud in Action
While many teams scrambled during the outage, more than 300 Snowflake customer workloads were barely impacted. Their secret weapon was Snowgrid, a cross-region, cross-cloud layer that underpins Snowflake’s global service fabric. In our view, Snowgrid embodies the supercloud principle – i.e. abstract away provider dependencies while maintaining consistency, governance, and performance across all regions and clouds. See diagram from Snowflake’s Website below.
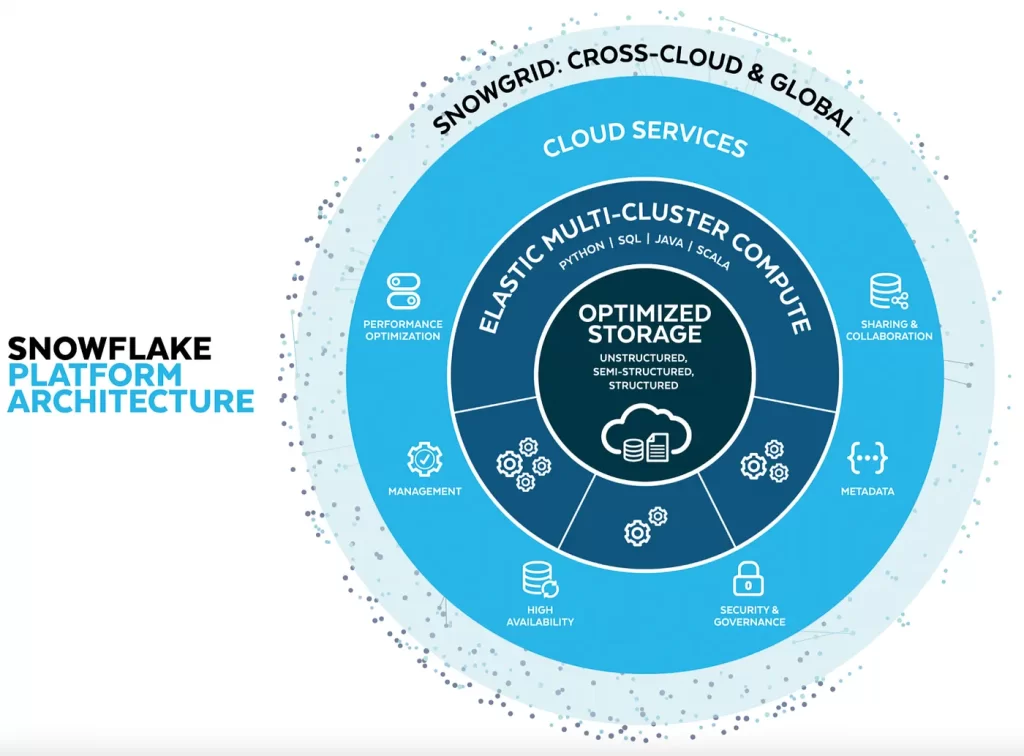
Snowgrid represents one of the more mature implementations of cross-cloud resilience in production today. It operates through three integrated primitives:
- Transactionally consistent replication – Keeps a continuously refreshed, point-in-time-accurate copy of data in another region or cloud, without DIY CDC (e.g. log-based or event-driven change capture). Our (unconfirmed) understanding is that RPOs can be tuned down to minutes, often 1–15+ minutes for business-critical workloads;
- Managed, human-gated failover – Operators initiate two commands: 1) One to failover → ALTER FAILOVER GROUP appname PRIMARY; once severity threshold policies are met; and 2) One other for client redirect (see below);
- Client redirect – ALTER CONNECTION appurl PRIMARY; Once initiated, applications and BI tools automatically follow new endpoints, maintaining user sessions with a brief, (sub-minute) disruption.
Failback is symmetric, meaning the state of the system returns to the primary once stability resumes.
These mechanics turn what would otherwise be an outage event into routine operations. During the AWS failure, affected Snowflake instances failed over to alternate regions – and in some cases, alternate clouds – resuming normal function within a minute.
Resilience by Design
Snowgrid’s architecture is deliberately cross-cloud and cross-region. Every Snowflake region sits on top of AWS, Azure, or GCP infrastructure, and Snowgrid brings them together via a unified metadata layer and secure replication mesh, which represents a single global namespace. Data can be shared, replicated, or failed over across availability zones or cloud providers while preserving access controls, policies, and lineage – what Snowflake calls governance that travels with the data.
Setting up Snowgrid isn’t overly complex. Administrators need to take three steps, specifically: 1) Define failover groups; 2) Specify which accounts or regions participate; and 3) Schedule refresh intervals that align with business RPO/RTO goals. Failover can be triggered manually through the Snowflake console or automated via an API. Failback simply reverses the sequence once the primary region stabilizes.
Our understanding is that replication costs scale linearly with usage and organizations pay in Snowflake credits for compute during replication, plus cross-region or cross-cloud egress. Most enterprises likely use a tiered strategy – i.e. tight RPOs for mission critical, revenue-generating or regulatory data, more relaxed policies elsewhere to balance cost and risk of data loss.
Customer Proof Points
We found two case studies on Snowflake’s Web site for those interested in vendor-provided examples:
- Pfizer uses Snowgrid to replicate over a petabyte of data across AWS U.S., Europe, and Asia, maintaining RPOs tailored to each business unit. When incidents occur, workloads redirect automatically, keeping R&D and manufacturing data available for analytics and AI pipelines. This example emphasizes resilience across AZs;
- HD Supply (Home Depot subsidiary) leveraged Snowgrid to consolidate Azure accounts and migrate 20 TB of data to GCP – completing the project in under 60 days with zero downtime and 30% cost savings. The example emphasized the simplicity of activating Snowgrid once it was set up.
These case studies reinforce what we learned during COVID – i.e. the idea that resilience is not a DR plan; it’s an operating model built into the data platform.
Economic and Competitive Implications
Snowgrid is an insurance policy. From a cost perspective, Snowgrid’s consumption-based model is reasonably efficient. Replication and egress are incremental, not duplicative; the disaster recovery account consumes credits, but only during active use. Compared with building bespoke, DIY multi-cloud data pipelines, the economics often favor Snowgrid, assuming expected loss calculations outweigh the setup and ongoing operational costs.
Snowflake claims it has a meaningful advantage over Databricks in this domain. According to Snowflake, Databricks’ disaster-recovery still depends on manual data copying and environment re-provisioning, lacking automated, transactional failover primitives. As enterprises push AI and analytics into mission-critical workflows, this gap may become increasingly important in considering architectural choices.
Our review of Databricks documentation confirms Snowflake’s claims but we haven’t spoken directly to Databricks about this issue, so please consider this fact in your analysis. Nonetheless, our research indicates that Databricks’ disaster recovery capabilities have historically relied more heavily on manual processes, including data copying, environment re-provisioning, and operator-driven cutovers. Official Databricks documentation and recent industry discussions confirm that while there are tools to automate portions of the Databricks failover process, a “manual decision” by an operator is still often required to initiate disaster recovery. Our understanding is that while a manual decision is also required to initiate a Snowgrid failover, Databricks’ approach lacks true transactional consistency, automated failover groups at the account or workspace level. This gap could be significant for enterprises pushing AI and analytics workloads into areas where high availability and rapid, consistent recovery are table stakes.
Snowgrid Gotchas: What It Does – and Doesn’t – Protect Against
In our view, Snowgrid is one of the most mature cross-cloud fabrics in the market, but it’s not a silver bullet. It’s designed to protect Snowflake accounts and data planes, not entire business systems. Understanding its limits is essential to building a realistic continuity plan and financial justification.
1. Scope of Protection: Snowflake Only
Snowgrid protects Snowflake environments, not the broader application ecosystem. If the outage affects upstream services – e.g. AWS S3 object access, identity federation (Okta, Azure AD), or an ETL/ML pipeline hosted elsewhere – Snowgrid can’t mitigate that. Failing over the Snowflake account won’t restore connectivity to an external data source, event stream, or application API that remains unavailable. In short, Snowgrid keeps your data platform alive, but not necessarily your full data supply chain.
2. Cost Model: Consumption Adds Up
Only a replication refresh job incurs Snowflake credits. The failover operation does not incur any credits. Crossing regions or clouds, incurs data-egress charges from the cloud providers.
- Replication in Snowflake is a serverless feature which incurs compute credits based on the amount of data and metadata replicated;
- Each refresh cycle reads delta data and writes it to the target region. Frequently changing workloads or many replicated objects can drive costs up. Clients may be aware that earlier this year, Snowflake announced its Gen2 warehouse, which addresses this cost challenge. By moving to Gen2, write amplification no longer becomes an issue and confers other benefits like reduced overall cost of storage, egress, faster replication and better overall efficiency;
- Clients should also be aware that hyperscalers charge for cross-cloud egress (e.g. AWS to GCP), which is significantly more expensive than cross-region charges. Our understanding is Snowflake does not mark up egress costs and passes them onto customers.
Customers report that Snowgrid’s incremental spend is modest for tier-1 data, but it scales with both volume and frequency. In forums we scanned, while users were generally positive on Snowgrid’s simplicity and maturity, some complained that costs were unpredictable. As previously discussed, the practical deployment case typically uses a tiered RPO model, with more frequent replication for critical datasets and less frequent schedules for lower value data to keep costs aligned with risk.
3. Project Considerations and Skills Requirements
While the Snowflake console and Snowsight UI appear to make configuration straightforward, Snowgrid’s replication and failover groups require deliberate design:
- A trained account admin must be designated and only that individual can enable and manage replication;
- Objects must be organized into failover groups, and permissions have to be explicitly granted on both source and target accounts;
- Cross-cloud replication also requires administrators to re-establish certain linkages – for example, new IAM roles for S3 buckets or Pub/Sub permissions for GCP;
- Private network paths between VPCs and Snowflake endpoints must be manually established where public IP access is not allowed. This is often the case in highly regulated industries such as financial services and healthcare.
In short, the setup is not “click and forget.” It’s manageable for experienced Snowflake teams but non-trivial for organizations without in-house cloud-security or platform expertise.
4. Operational Boundaries and Human Factors
Failover is human-gated by design. Snowflake intentionally requires a manual promotion of a replica to primary, executed via SQL or a simple console command. This prevents automated start/stops but means failover is not instantaneous or autonomous. To be specific, once the failover command is executed, the failover group replicas immediately become read/write (i.e., the new primary). When connections failover, it typically takes less than a minute for clients to redirect to the newly promoted primary.
We see this as a sensible failsafe but customers should be aware that a human must be in the loop and familiar with organizational policies to determine the severity of an incident. We strongly advise teams to rehearse the cutover, as there’s always a risk of hesitation or mis-sequencing under pressure. Failback, while symmetric, still requires validation and coordinated timing.
5. Business-Case Boundaries
Snowgrid’s ROI depends on data criticality and uptime requirements.
- For non-mission-critical workloads or datasets easily re-hydrated from source systems, the cost of continuous replication may outweigh the value of minute-level RPOs;
- Organizations already operating in a single region with generous RTO tolerance may find scheduled backups or database replication sufficient. The business case will be more compelling in regulated industries like financial services where revenue and compliance are tightly tied to data platforms;
- Snowgrid doesn’t replace higher-level multi-region application architectures; it complements them. Enterprises looking for full stack active/active across clouds still need additional orchestration at the app and identity layers.
On balance, we believe Snowgrid delivers credible, production-proven resilience for Snowflake workloads, but it’s not a comprehensive insurance policy for all workloads. It safeguards the data platform layer, not the total enterprise fabric. Be aware that costs scale with replication frequency and data change rate; configuration requires “superpower” privileges and multi-cloud familiarity; and value diminishes for workloads where downtime is tolerable or where dependencies lie outside Snowflake.
Used correctly, Snowgrid is a strategic tool in a tiered continuity architecture, not a universal shield.
From Snowgrid to Business Continuity Everywhere
The broader takeaway from Monday’s outage is that resilience must be systemic, not siloed. Bringing your Snowflake instance back online doesn’t help if the upstream data sources, applications, or orchestration tools remain down. The architecture should extend Snowgrid-like principles to every tier including DNS, identity, application orchestration, data pipelines and testing. In other words, treat control planes as at-risk dependencies that need to be considered carefully in architecting resilience.
The Bigger Picture: Supercloud as the New Continuity Layer
In our research, the Snowflake event performance is more than a DR success story – it’s a proof that supercloud resilience has become table stakes for regulated industries in particular. Snowgrid abstracts cloud-specific differences in networking, identity, and data management, delivering a single, governed experience across AWS, Azure, and GCP.
This capability defines the next era of enterprise continuity in our view. Multi-AZ was the first step. Multi-region was the second. The third is multi-cloud autonomy, where the platform itself decides, redirects, and recovers faster than human operators can react.
As AI workloads grow more entwined with business operations, downtime becomes increasingly costly. In our opinion, Snowgrid’s architecture will become a reference model for how enterprises engineer continuity at scale, turning global data estates into always-on, borderless superclouds.
Action Item: The AWS outage reminded us that resilience begins where provider guarantees end; and it’s the responsibility of the customer, not the operator, to ensure resilience is architected into their unique organization. Snowflake’s Snowgrid showed what happens when resilience is built into the fabric of the data platform itself. For CxOs, the lesson is architect for autonomy. The next outage is inevitable, but with the right cross-cloud foundation, it doesn’t have to be costly.


