
AWS CEO Matt Garman used the re:Invent 2025 keynote to fuse the line between the cloud of the past and the AI-native cloud taking shape today. His message was AI is not “bolt on,” superglued to AWS services, rather it’s an evolution of the cloud itself. The keynote emphasized the company’s infrastructure, silicon roadmap, model platform, and emerging agentic ecosystem as the best place to build AI applications. The scale at which AWS is executing on this vision is impressive, but the real question on everyone’s mind was how will AWS balance the needs of its legacy cloud customers and at the same time lead in AI innovation.
A Platform Growing at Massive Scale
AWS entered re:Invent as a $132 billion (run rate) business, growing at 20% year over year (in Q3). Garman shared that over the past twelve months, the company added $22 billion in absolute revenue – more than the annual sales of half the companies in the Fortune 500 and more than our projected annual revenue for Alibaba’s Cloud and GCP. The graphic below depicts theCUBE Research tracking data from the past five years for the top 5 providers. Remarkably, the revenues from the top 5 cloud providers has grown 3.5X since the first year of COVID.
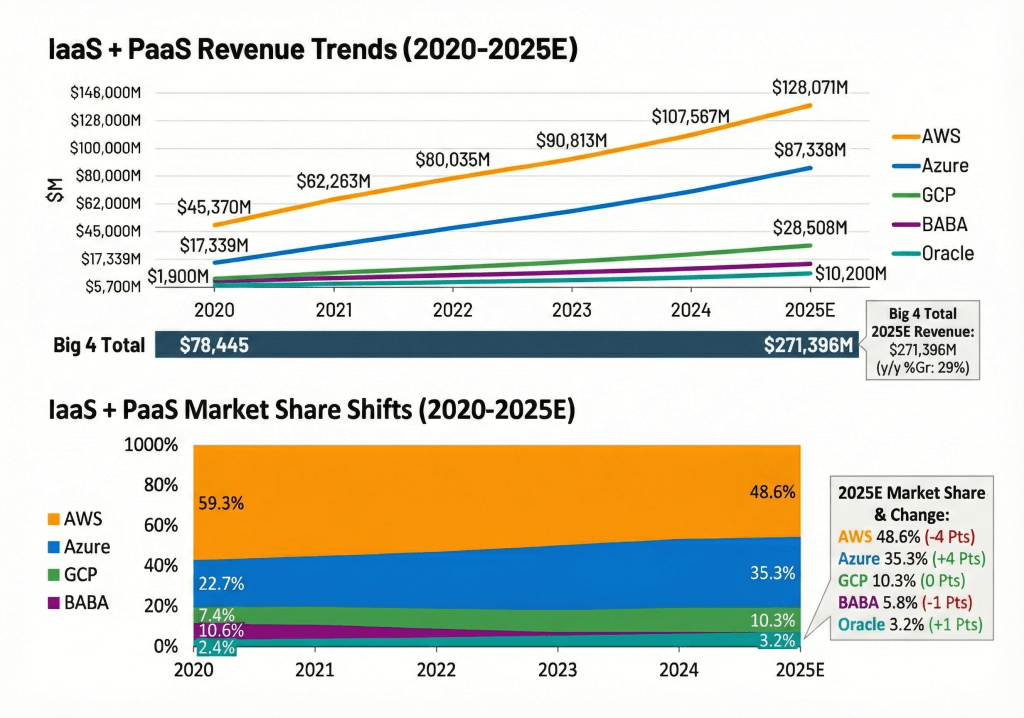
This picture will change going forward as Oracle has altered the game with a debt-laden entry into the GPU cloud marketplace. Moreover, neocloud upstarts like Coreweave, Lambda, Nebius, and others, underscore an emerging market for GPU cloud specialists. As we hinted in our introduction, the investment requirements for this new market may be vastly different from extending legacy cloud infrastructure with incremental services that simplify the lives of builders. AWS must show that it can serve its massive installed customer base and still be considered the platform for innovative startups. Indeed, in the war of wordsmithing, Google claims roughly 90% of GenAI unicorns run on GCP. Meanwhile, AWS claims approximately 96% of ML/AI unicorns run on its cloud.
Last year at re:Invent on theCUBE, Andy Jassy addressed the choices customers face: Modernize infrastructure or invest in AI. And the answer he gave was ‘yes.’ His premise, however, is you really can’t do the latter without first doing the former. The recent re-acceleration in AWS’ business would suggest this is the case.
Listen to Jassy’s full comments on this topic.
One of the key drivers of AWS’ growth is storage generally and S3 specifically, one of AWS’ first services offered to external customers. Storage is hot again and is a major contributor to AWS’ performance. According to Garman, S3 now stores more than 500 trillion objects and handles approximately 200 million requests every second. AWS operates at massive scale -38 regions and 120 availability zones, with another 34 AZs in the pipeline. Behind the scenes, AWS added 3.8 gigawatts of new data center power in the last year and expanded its private global network footprint by 50% to a total of 9 million kilometers of fiber.
This is just a glimpse of the platform powering everything AWS must build next.
Infrastructure for the AI Factory Era – “The Campus is the New Computer”
A major theme of Garman’s keynote was the deep engineering work required to support the next generation of models and the customers building them. AWS highlighted its investments in GPU reliability – including work with NVIDIA down to BIOS-level debugging – to eliminate reboot patterns that plague long-running training jobs.
New P6e GB300 instances, powered by NVIDIA’s GB300 NVL72 systems, mark the next step in high-performance GPU clusters. At the same time, AWS is embracing a multi-pronged silicon strategy centered around custom accelerators. The company hit a milestone of 1 million Trainium chips deployed, and announced general availability of Trainium 3 Ultra with:
- 4.4X more compute
- 3.9X more memory bandwidth
- 5X more AI tokens per megawatt
AWS also announced new instances based on both Intel and AMD chipsets, touching all the bases in its silicon supply chain.
Amazon announced AWS AI Factories, dedicated AI infrastructure that customers can deploy in their own data centers. These systems function like private AWS regions, run on either Trainium Ultra servers or NVIDIA GPUs, and expose higher-level services such as SageMaker and Bedrock. For customers with sovereign, regulatory, or ultra-low-latency requirements, AI Factories represent the highest-end expression of AWS’ AI infrastructure.
In an exclusive interview with John Furrier, Garman provided additional detail as follows:
“I think that there’s going to be a small number of customers who want to have these dedicated AI factories as we call them, where they can go and we’ll put large amounts of compute next to where they’re going to be. These are going to be sovereign nations, these are going to be US governments and secret agencies. These are going to be really, really, really large customers. However, I think that the vast majority of customers are going to continue to take advantage of this technology inside of an AWS cloud.”
This is the trillion-dollar question, of course. Will organizations move their data into the cloud, or will they bring intelligence to their data? Unquestionably, the services and tooling available in the major clouds far exceed the capabilities of on-premises solutions of today. But many organizations cite cloud costs, latency, and other concerns as catalysts for building their own AI stacks on-prem. Most firms, however, lack the data center power, liquid cooling, and supporting infrastructure to deliver AI at large scale. Collocation facilities are an option as are neo clouds.
Like the universe – the cloud continues to expand. According to Garman:
“We’ve talked about our Project Rainier, which is together with Anthropic, 500,000 Trainium2 chips, all in basically the same data center campus. And we used to say some phrases like the rack is the new computer and the data center is the new computer. Now we kind of say the campus is the new computer because it really is. These are massive, massive compute installations and for the very largest customers. But I think the cool part about that is the innovation that comes back to every customer out there who’s interested in going and building models. And not every customer is going to go spend tens of billions of dollars to go build a frontier model, but every customer wants to be able to take advantage of AI, every customer wants to be able to go and build.
And some of the announcements that we have at re:Invent are really targeted at how do we help customers be able to go get that value out of all of this spend that’s going in there. And as you mentioned, AWS is spending a large amount of capital to go and build out data centers all around the world to land compute infrastructure, to land network infrastructure, to land storage infrastructure so that customers can keep seamlessly scaling. And we’re landing different new types of compute, we’re landing new types of clusters, and we’re landing new services to help them take advantage of all this technology that’s coming out.“
Bedrock’s Growth and the Nova 2 Model Family
Amazon Bedrock is the centerpiece of AWS’ generative AI strategy. According to Amazon, more than 100,000 companies now use Bedrock for inference, with the customer base more than doubling year over year. Over 50 organizations have processed more than one trillion tokens each.
AWS’ model portfolio continues to expand with new additions from Mistral AI, Google Gemma, and NVIDIA’s Nemotron family. But the biggest announcement was the Nova 2 series, AWS’ next-generation reasoning and multimodal models:
- Nova 2 Lite for cost-optimized reasoning
- Nova 2 Pro for highest-end reasoning intelligence
- Nova 2 Sonic for next-generation speech-to-speech workflows
- Nova 2 Omni, a unified multimodal model that combines reasoning, vision, and image generation in one system
It has been AWS’ intention to compete directly in the model game while supporting a broad range of enterprise-centric use cases. Why, you may ask, does AWS need to build its own models when so many options are available on the marketplace? The reason is that it gives AWS more control over its stack. It allows the company to optimize performance and tightly integrate with its own silicon. This has implications for not only performance and cost but also security.
Nova Forge: Custom Frontier Models for Every Enterprise
Perhaps the most important innovation unveiled at re:Invent is Nova Forge, a new approach that allows customers to create their own custom models by blending proprietary enterprise data with Amazon’s curated training sets during the training process – not after.
The result is a private “Novella” – i.e., a model that preserves all foundational reasoning capabilities while incorporating deep domain knowledge unique to the customer. Reddit used Nova Forge to reach moderation accuracy levels that were impossible with fine-tuning alone. Sony spoke at the keynote and is applying it to compliance review workflows with a targeted 100X efficiency improvement.
For enterprises that want frontier-level intelligence without frontier-level training costs or data exposure, Nova Forge may be the most significant feature AWS has shipped in years, and, along with its AI Factories announcement, recognizes the importance of data sovereignty and propriety. This move aligns with our prior research looking at How Jamie Dimon Becomes Sam Altman’s Biggest Competitor, a metaphorical look at the need for open-weight models to create proprietary advantage for enterprises.
AgentCore: Building and Governing Agents at Scale
As generative AI shifts from chat interfaces to systems of agency, AWS introduced AgentCore, a platform for building, governing, and observing agentic systems. Amazon claims the platform’s flexibility comes from its modular design and two core capabilities:
- Policy: Natural-language governance rules enforced by the Cedar policy engine, an open-source language evaluation tool developed by AWS for defining and enforcing fine-grained authorization policies in applications and services.
- Evaluations: Continuous monitoring using 13 pre-built evaluators that detect drift, degradation, or unexpected agent behavior
According to Amazon, AgentCore’s purpose is to provide enterprises with a safe, auditable path to deploying agents that operate on production-grade corporate systems. This, in our view, is another example of table stakes for enterprise customers. Necessary but insufficient to successfully deploy agentic fleets. It remains unclear how AWS is simplifying data preparation and providing a more facile path to data semantics. Mai-Lan Tomsen Bukovec discussed the imperative for a semantic understanding of data in her keynote presentation, but there was no indication of a knowledge graph or higher-level system of intelligence to harmonize data and simplify the development and execution of agents.
Enterprise Agents Take Center Stage
AWS showcased several key agent-powered applications that it claims are already operating at scale:
- Amazon Q, the internal AI productivity layer used by hundreds of thousands of Amazon employees, enabling teams to complete tasks up to 10X faster
- Amazon Connect, which now exceeds a $1B annualized run rate
- Writer, which integrates Bedrock guardrails to enforce compliance and editorial consistency
These examples support AWS’ broader strategy of coupling high-performance models with agentic workflows to transform everyday enterprise tasks.
Frontier Agents & The Kiro Development Environment
AWS is also moving into long-running autonomous agents, which it calls “frontier agents.” The star of this movie is Kiro, a type of autonomous AI agent announced this past summer, designed for software development. Kiro learns team preferences, coding styles, and repository structures, maintaining context across sessions. According to Garman, it is already AWS’ standard internal development environment, and the results are meaningful. According to Amazon, a project originally estimated at 30 developers over 18 months was completed by six developers in 76 days using Kiro.
AWS also introduced Security Agent for automated pen-testing and DevOps Agent for incident response and operational optimization. These agents represent early examples of what high-autonomy systems can accomplish inside an enterprise.
Rapid-Fire Service Enhancements Across the Portfolio
Garman closed his keynote with a lightning round of core service updates – 25 announcements in 10 minutes – underscoring AWS’ continued investment across its fundamental services. These include:
- Compute: Compute: C8a (Compute), M8azn (General Purpose), and X8a (High Memory) – all based on 5th Generation AMD EPYC ‘Turin’ processors.
- Storage: S3 object size limit increased to 50TB; batch operations now 10X faster
- Databases: SQL Server storage limit raised to 256TB; new savings plans offering up to 35% cost optimizations
- Security: GuardDuty now covers all containers; Security Hub adds real-time analytics
- Lambda: durable functions enable long-running workflows with built-in state management
These improvements reinforce AWS’ balancing act – i.e., expand at the high end with novel AI capabilities while continuously iterating on the core services that run millions of workloads.
What is the Future of the AWS Cloud?
Matt Garman’s re:Invent 2025 keynote was short on hype and dove right into the details. It revealed an AWS trying to reshape itself around the demands of AI at every layer of the stack. AWS’ task is daunting and requires multi-gigawatt data center campuses, custom-trained Novella models and autonomous agents like Kiro. AWS is tasked with building a platform where infrastructure, models, and agents converge into a unified AI-first cloud that sits on top of nearly two decades of cloud infrastructure. What wasn’t clear from the keynote is AWS’ vision of the cloud’s future. Is it a collection of AI services? Or does Amazon see the future cloud as an intelligent, continuously learning system that harmonizes data and facilitates the next generation of enterprise applications?
In many ways, Garman’s close with 25 announcements in 10 minutes says the former is more likely than the latter.


