
The enterprise AI market is entering a more consequential phase. Early excitement was driven by what large language models (LLMs) could generate. They are now widely accessible, enabling real users to acquire knowledge, perform analytics, and automate repetitive tasks with fluency and coherence. The next phase, however, will be defined by trustworthy multi-agent architectures that extend beyond LLMs to support decision-making, compliance-heavy workflows, and explainable, defendable outcomes.
That is the central message from a recent conversation with Magnus Revang, Chief Product Officer at Openstream.ai. His argument isn’t against LLMs; it’s that LLMs act as a crucial foundational layer, but on their own, they fall short in enterprise environments. As Magnus explained:
“We see real problems with LLMs that don’t build an architected system around them.”
That observation goes to the heart of the issue enterprises now face. Many current agent strategies are still rooted in LLM-only thinking (LLM+RAG+CoT): prompt in, answer out, explanation attached ad hoc. But for high-stakes workflows, that is not enough. If an AI system cannot be trusted to show why it made a recommendation, what data it used, what controls governed the process, and how the output can be verified, then it is not enterprise-grade. It is a black box with business exposure attached.
Simply put, “because AI said so” is not an audit trail that enterprises will trust.
Watch the Podcast
The LLM reliability problem is architectural
Our discussion began with a difficult truth: companies are expanding AI into areas where errors can have serious consequences. This includes insurance underwriting, investment analysis, compliance-heavy decisions, and other types of knowledge work where the cost of mistakes is high.
Magnus does not dance around the weakness of LLM-only approaches. On plan-based reasoning:
“When you ask an LLM to do a plan, you’re relying on the world knowledge of that LLM. And those plans are not necessarily any good. It might not follow it, but it will pretend it did.”
That is a profound enterprise concern. A system that sounds coherent but cannot reliably execute, verify, or defend its own reasoning is not ready for decision-centric workflows. Magnus makes the point plainly:
“LLMs have lots of strengths, but they also have lots of weaknesses. They deal with linguistic chaos and ambiguity well, but they make mistakes, and not just one kind of mistake.”
Our survey supports Magnus’s point of view that trustworthy multi-agent architectures cannot be built solely on model fluency and coherence. Data from theCUBE Research’s Agentic AI Futures Index shows that enterprises place the highest priority on data provenance and quality assurance at 72%, followed by transparency and explainability at 67%. This reinforces the same message: enterprise trust is an architectural requirement, not a prompt-engineering exercise. In other words, the market is signaling that responsible agentic AI must be grounded in controls, verification, and explainability, which aligns directly with Openstream’s emphasis on high-control, event-triggered systems with built-in checks and balances.
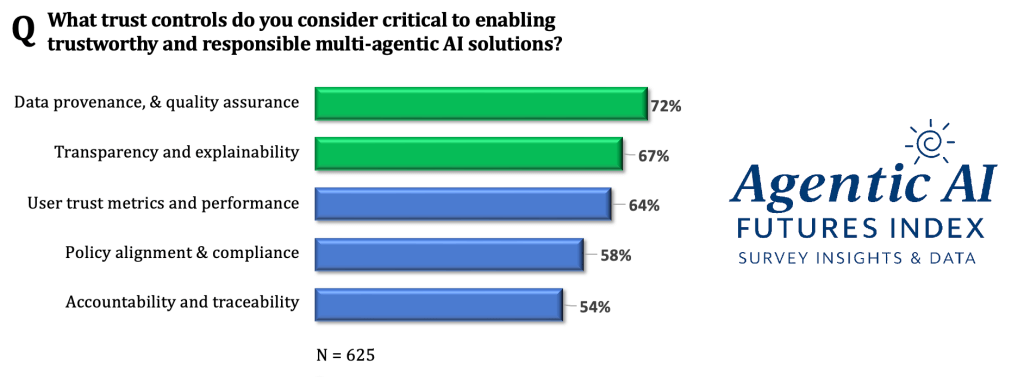
This is why the problem should not be framed as an LLM model problem. It is an AI architecture problem. The question is not whether an LLM can produce a fluent and coherent answer. The question is whether the system around it can constrain, validate, and explain that answer.
Value is in high-control, event-triggered AI
One of Magnus’s interesting perspectives is his way of categorizing AI use cases. He contends that executives must distinguish between two dimensions that are too often confused.
The first is control. Some use cases exist in low-control environments, such as summaries or open-ended chatbot interactions. Others operate in high-control environments where compliance, process discipline, policy alignment, and defensibility matter.
“In a lot of cases and a lot of industries,” he says, “we’re actually in a high-control environment, where we need the user to retain control or the enterprise to retain some control.”
The second is about triggers. Magnus draws a sharp line between prompt-triggered AI and event-triggered AI. Prompt-triggered systems depend on a human asking the right question in the right way. Event-triggered systems are activated by business events, incoming data, files, signals, or process states, and then execute predefined instructions across multiple agents.
This is where his market thesis becomes especially compelling. He argues that too much industry attention has gone toward low-control, prompt-driven AI. But the enterprise value lies in high-control, event-triggered mechanisms.
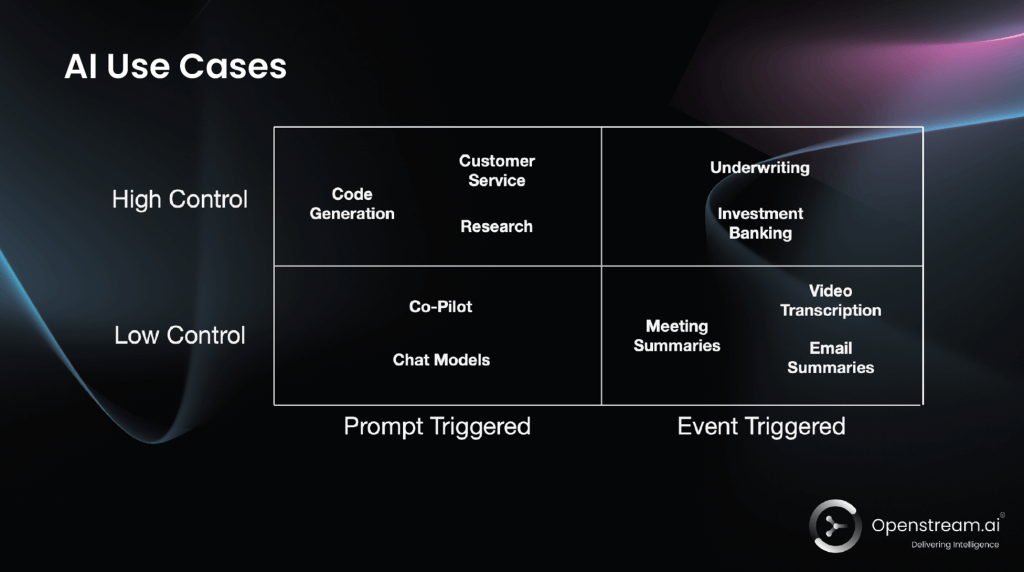
That is an important strategic lens. Consumer-style AI attention is being drawn toward novelty. Enterprise value, by contrast, is concentrated where errors are costly, decisions must be explained, and improved outputs have a direct line to financial results. Take, for example, insurance underwriting, private equity, and investment banking, where better AI performance quickly translates to the bottom line.
Building beyond LLM-only agents
Openstream’s answer is a multi-agent architecture designed to reduce the systemic weaknesses of LLMs rather than simply prompt around them.
Magnus explains the approach this way:
“We employ loads and loads of AI agents, and not all of them are LLM-only based.”
In many so-called multi-agent systems, all the agents are essentially just variations of prompting on top of the same model. Openstream, on the other hand, uses symbolic AI and other methods, such as knowledge graphs, to enable specialized components to handle different parts of a larger problem.
That architectural choice matters because the strengths and weaknesses of LLMs and symbolic systems are almost inverse. The strengths of symbolic AI/knowledge graphs are that they are logically consistent, don’t invent things, and don’t hallucinate at nearly the rate LLMs+RAG+CoT does. The weakness is that it requires much more manual structure and maintenance. The opportunity, asserts Magnus, is a combination:
“We combine them in a way where you eliminate the weaknesses of LLMs and eliminate the weaknesses of symbolic AI.”
He summarized the stack clearly:
“We use knowledge graphs, we use logic reasoning solvers together with LLMs and thinking models, and then build an architecture that maximizes the strengths and minimizes the weaknesses of both methods.”
That is a much more credible enterprise blueprint than simply scaling prompts.
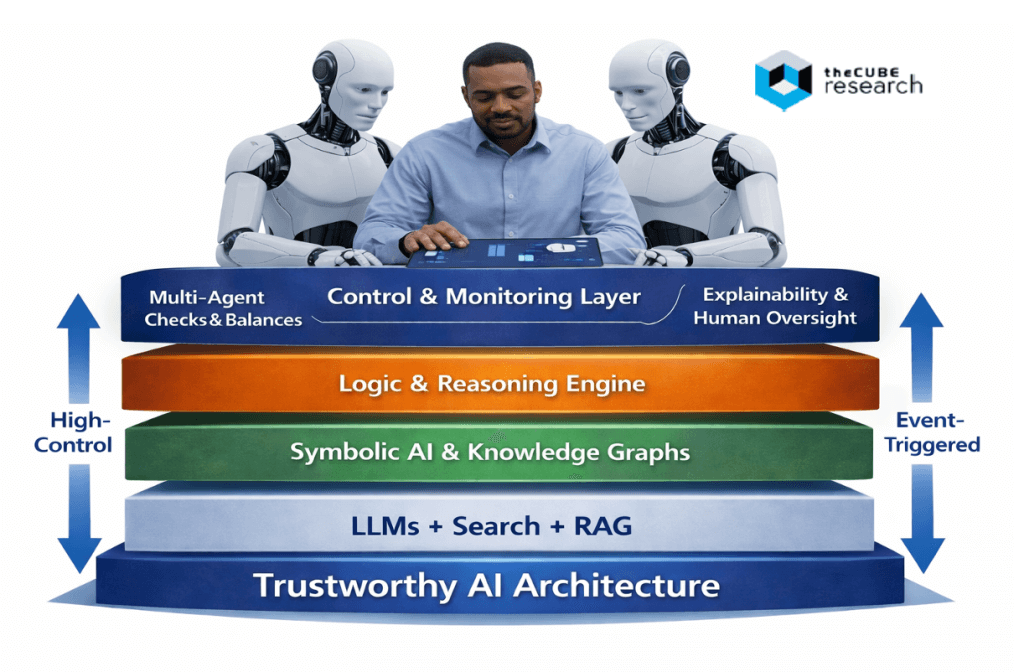
Checks, balances, and explainability by design
This architectural approach comes to life through a concrete underwriting example: assigning an SIC code to a company. In a prompt-only environment, the system may receive a website and return a code based on a superficial interpretation. Openstream breaks the work into specialized agents: one identifies what the company does, another checks available codes, another applies guidelines, and another validates the collaborative result. The result is checks and balances on each other to make sure that the outcome is correct.
In the podcast, Magnus also outlined an Amazon-related case. A simple prompt might classify Amazon mainly as an e-commerce company because that is what appears on the website’s surface. But a more robust agentic system asks whether that is “the real website, or is it a service website,” then traces broader evidence before arriving at a conclusion.
That is the essence of trustworthy enterprise AI. Not just answer generation, but systematic validation. Not just fluency and coherence, but grounded reasoning that is explainable and auditable. Not just output, but provenance.
Multimodal AI needs a control layer
Openstream enhances trust by delivering multimodal, agentic systems that can operate in low-control environments. The challenge is that the interaction layer is tightly coupled to the backend response layer, leaving little room for enterprise intervention or rule-based control. Openstream’s control layer helps address this challenge in enterprise settings.
This matters because multimodal enterprise AI cannot just see, speak, and react. It has to operate within explicit boundaries: what to look for, how to respond, how to reflect brand and policy, and how to keep human oversight in the loop. This is foundational to enterprise AI decision intelligence use cases.
Strategic Advice for the Enterprise
In the Next Frontiers of AI podcast, “Beyond LLM Black Boxes: Building Transparent, Trusted Agents,” Magnus closes with practical guidance that executives should take seriously.
First:
“Include the experts early; it’s actually a sliding scale of quality, since only domain experts can judge whether the system is merely acceptable or genuinely valuable.”
Second:
“Don’t rely on the world’s LLMs model alone. Instead, make everything into closed systems and start using other technologies, such as knowledge graphs, to build upon and enhance value.”
Third:
“Go after event-triggered, mission-critical use cases. Target the cases that are triggered by an event; this is core to your business. If you don’t do this well, you’ll lose long-term. That’s where the value is.”
These are strategic takeaways that all enterprises should take to heart, as enterprise AI will not be defined by the most conversational systems. It will be won by the systems that are most controllable, explainable, and defensible.
Watch the full product to learn more.

📊 More Research: https://thecuberesearch.com/analysts/scott-hebner/
🔔 Next Frontiers of AI Digest: https://aibizflywheel.substack.com/welcome



