
After a series of one-on-one conversations focused on the developer impact at Google Cloud Next 2026, I was really excited to see the deep dive discussions in the developer keynote with Brad Calder, Richard Seroter, Bobby Allen, and Yinon Costica. A theme emerged at Google Cloud Next 2026: we’re witnessing a fundamental shift from experimental AI agents to engineered, observable, and governed systems. This is not iteration, it’s maturation.
According to theCUBE Research AppDev data, over 62% of enterprises are now piloting or deploying multi-agent architectures, but fewer than 25% report confidence in reliability, governance, and repeatability. What Google showcased this week is a direct response to that gap—turning fragile experimentation into structured, production-ready systems.
Let’s start this analysis by going backstage before the Developer Keynote….

Behind the Scenes: Inside the Demo Environment Before the Developer Keynote
Before the developer keynote even kicked off, there was a very different kind of story unfolding backstage, one that offered a clearer view into how much engineering discipline now sits behind what looks like a seamless AI demo on stage.
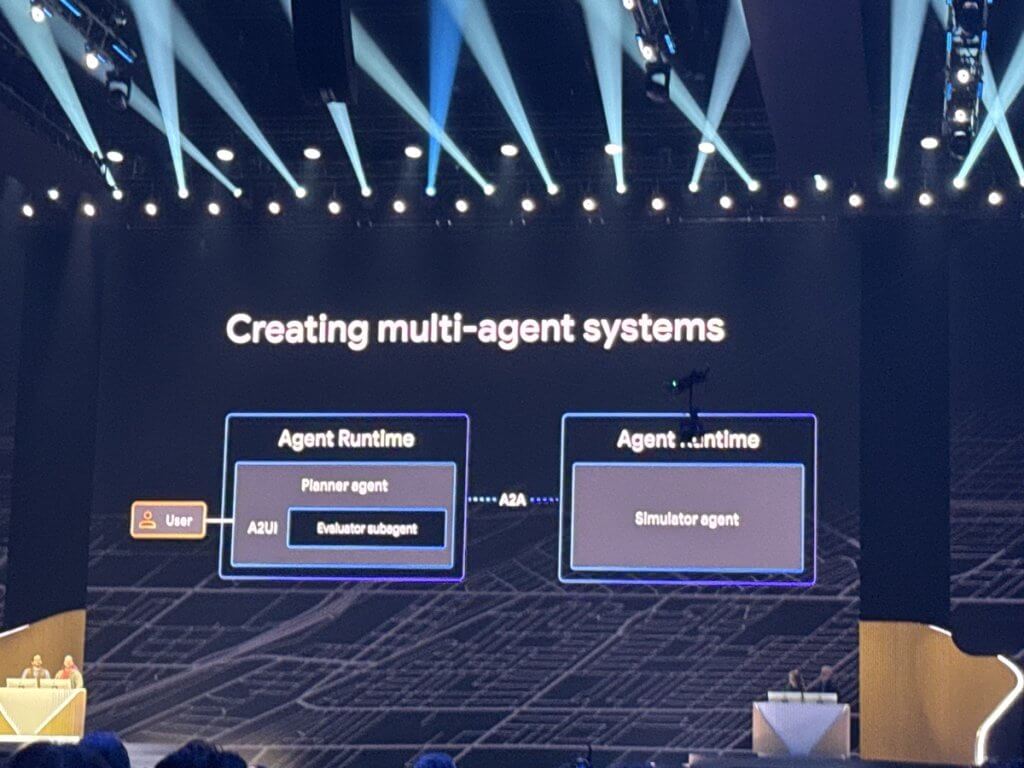
Walking through the live demo environment with Richard Seroter, it was immediately obvious that this wasn’t a scripted, static showcase. What the audience would eventually see was backed by a fully operational, production-grade multi-agent system running in real time. The focus wasn’t on flashy prompts; it was on ensuring that every component, from Planner to Evaluator to Simulator, could handle variability, failure, and scale without breaking.
The backstage setup reflected the same architectural themes highlighted later in the keynote:
- Live simulation environments were actively monitored, not just triggered
- Agent interactions were instrumented with observability tooling, including traces and token usage tracking
- Fallback paths and guardrails were pre-configured, anticipating edge cases rather than reacting to them
In conversations ahead of the keynote with speakers like Brad Calder, Bobby Allen, and Yinon Costica, a consistent message emerged: the biggest risk in live AI demos isn’t model accuracy, it’s system reliability under pressure.
That reality shaped how the keynote itself was designed.
Rather than relying on a single linear flow, the demo architecture supported parallel execution paths and real-time recovery mechanisms. If a simulation lagged or a token threshold was exceeded, the system could adapt without derailing the narrative. This aligns directly with what we’re seeing in the enterprise: AI success is less about perfect outputs and more about resilient systems that can recover gracefully.
There were also subtle pre-announcements embedded in those backstage discussions that didn’t always make the slides but mattered just as much:
- A stronger push toward standardizing agent interoperability (A2A) beyond Google’s ecosystem
- Continued investment in Agent Registry as a discovery and governance layer
- Deeper integration between security (Wiz) and developer workflows, shifting remediation earlier into the lifecycle
From an analyst perspective, the backstage access reinforced an important point: what looks like a polished keynote demo is now a reflection of real enterprise architecture, not a prototype.
And that’s a shift.
A few years ago, these demos were aspirational. Today, they’re increasingly representative of how systems are actually being built and operated, with observability, governance, and resilience designed in from the start

Transitioning from Fragile Agent Loops to Evaluated Expert Networks
The most important architectural evolution on display was the move away from unpredictable, looping agents toward evaluated networks of expert agents.
Instead of a single agent trying to do everything (and often failing silently), Google demonstrated a multi-agent system composed of distinct roles: Planner, Evaluator (LLM-as-Judge), and Simulator. These agents collaborate in structured loops with real-time scoring, feedback, and iterative refinement—essentially bringing software engineering discipline to agent behavior.
What stood out:
- The Evaluator agent applies both deterministic metrics (e.g., exact constraints like distance) and non-deterministic criteria (intent alignment, community impact) using a severed-context model.
- Simulation at scale—thousands of concurrent “runners”—validates outcomes before deployment.
- Dynamic UI generation (A2UI) eliminates the need for custom dashboards, rendering insights instantly.
From a research standpoint, this aligns with a growing trend: evaluation is becoming the control plane for AI systems. theCUBE Research data shows that teams implementing formal evaluation frameworks see up to 40% improvement in output consistency.
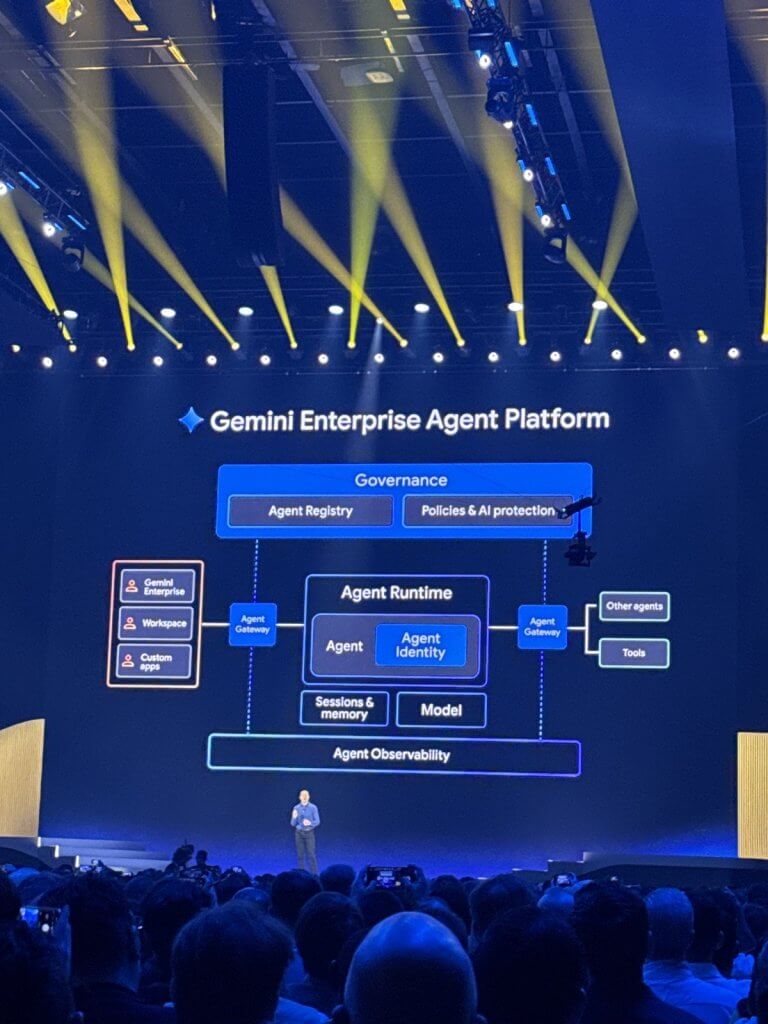
Equally important is the introduction of A2A (Agent-to-Agent protocols) and the Agent Registry. By removing custom API contracts, Google is effectively standardizing how agents discover and interact with each other—something the industry has been missing. Bottom line: This is the transition from “agents that act” to “systems that reason, measure, and improve.”

Context Engineering, Stateful Agents, and Data Integration
Stateless agents are quickly becoming obsolete. Google’s emphasis on stateful agents with memory, sessions, and context engineering reflects what enterprise developers have been asking for: continuity and learning over time.
Enhancements to the Planner agent were surprisingly lightweight—roughly 20 lines of code unlocked:
- Persistent memory via Memory Bank
- Retrieval of structured and unstructured data (via AlloyDB and Document AI)
- Semantic rule enforcement (e.g., local regulations through RAG)
This is where theCUBE Research AppDev data reinforces the narrative: 78% of enterprise AI failures are tied to poor context management—not model quality.
What Google demonstrated is a fix to that problem. By combining RAG, memory, and session awareness, agents can:
- Recall prior simulations
- Adapt to local rules dynamically
- Improve outcomes across iterations
The before-and-after simulation results, old routes vs. optimized paths, highlighted measurable gains driven purely by better context utilization. Bottom line: Context is now the differentiator, not the model.
Operational Learnings: Reliability and Observability at Token Scale
One of the more candid and valuable parts of the keynote was the discussion around failure.
Introducing LLMs into systems creates entirely new failure modes—especially at scale. The Simulator agent hitting Gemini’s 1M token limit is a perfect example. This wasn’t a theoretical issue; it was a real production bottleneck.
The resolution—introducing token-aware event compaction- highlights a new operational reality:
- Token management is now a first-class reliability concern
- Observability must extend beyond infrastructure into model behavior
- Debugging requires traceability across agents, tools, and context
theCUBE Research data shows that only 31% of organizations have full-stack observability for AI systems, and those that do resolve incidents 2.5x faster. Google’s approach, combining Agent Observability with Gemini Cloud Assist, points toward autonomous operations:
- Detect
- Diagnose
- Recommend fixes
- Deploy via CI/CD
AI systems require a new SRE model—one that understands tokens, context, and agent interactions.
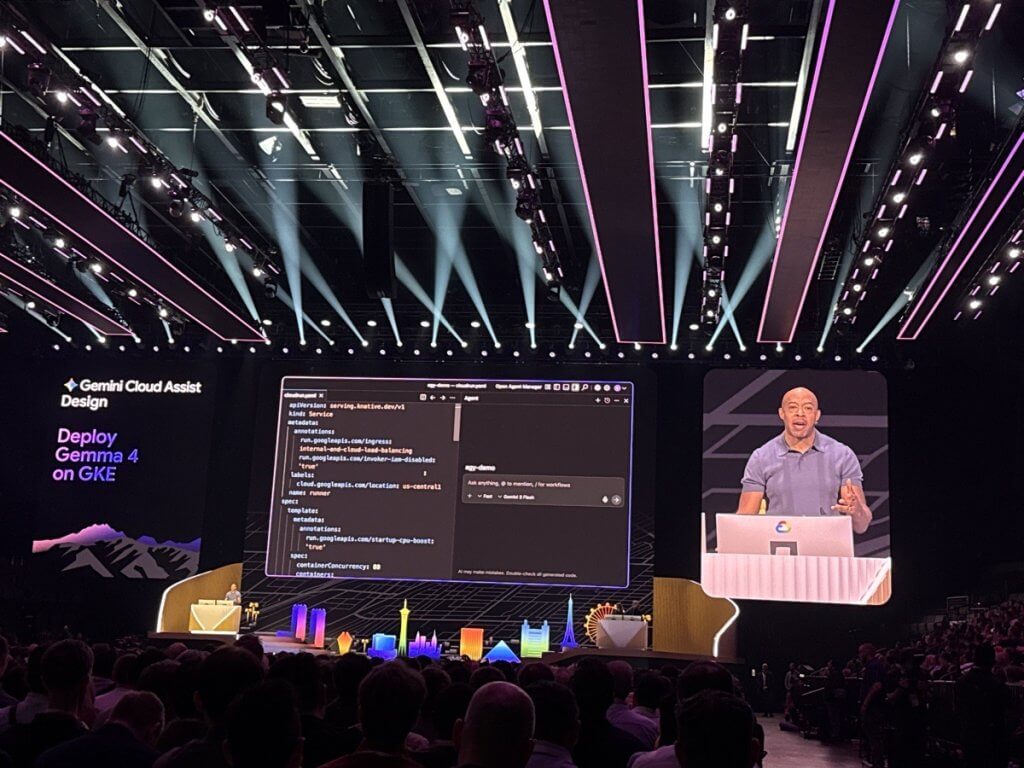
Infrastructure Evolution: GKE, Gemma 4, and Performance at Scale
On the infrastructure side, the migration from Cloud Run to GKE and the integration of fine-tuned Gemma 4 models signal a shift toward performance-optimized, customizable inference environments.
But the real story was in the bottlenecks:
- GCS Fuse couldn’t keep up with model loading demands
- Latency stalled simulations at scale
The solution—adopting Lustre—wasn’t just a performance tweak; it was an architectural pivot.
This reflects a broader trend in theCUBE Research data: 65% of AI workloads are being re-architected within 12–18 months of initial deployment due to performance constraints. What stood out here was the role of AI-assisted tooling:
- Gemini Cloud Assist translated intent into infrastructure changes
- Generated manifests and best practices automatically
- Traced issues from runtime to code
Bottom line: Infrastructure is becoming adaptive—and increasingly co-designed with AI.
Developer Productivity and the Rise of Composable Agent Systems
Google is clearly betting on developer experience as the adoption lever.
With Gemini Codex, Agent Designer, and the Agent Platform, the barrier to building multi-agent systems is dropping fast:
- Agents can be created with a single prompt
- Subagents collaborate without explicit orchestration code
- Context can be pulled directly from sources like Google Drive
The marathon planning and logistics example showed how planning, supply chain, and evaluation agents can work together seamlessly.
From theCUBE Research perspective: By 2027, over 50% of enterprise applications will incorporate agent-based workflows, but success will hinge on usability and governance, not raw capability. The Agent Registry further reinforces this by making agents:
- Discoverable
- Shareable
- Reusable across teams
Bottom line: We’re moving toward a marketplace of interoperable agents.
Security and Governance: Shifting Responsibility to the Platform
Security was not an afterthought—it was foundational. Google’s “shift down” model pushes governance into the platform layer:
- Agent identities with immutable credentials
- Centralized policy enforcement via Agent Gateway
- Zero-trust principles applied to agent interactions
The integration with Wiz adds a critical layer:
- Red Agents identify vulnerabilities
- Green Agents prioritize and remediate
- Automated fixes propagate through code and infrastructure
theCUBE Research data echoes the importance: 71% of enterprises cite security and governance as the top blocker to scaling AI initiatives.
What Google is doing here is reducing that friction by:
- Embedding policy enforcement into the runtime
- Automating remediation workflows
- Eliminating reliance on developer discipline alone
Governance must be built-in, not bolted on.
Open Source and What Comes Next
Google’s decision to open source the full demo stack—with architecture guides, labs, and credits—is a strong signal to the developer community: this isn’t just vision, it’s reproducible.
And that leads directly into what comes next:
- Scaling simulations with evaluator-driven optimization
- Expanding RAG pipelines with real-world regulatory data
- Standardizing agent interoperability via A2A and Registry
- Completing production migrations to GKE and Lustre
- Operationalizing governance with Agent Gateway and W

Closing the Loop on Simulation to Continuous Optimization
One of the more subtle, but critical, takeaways from Google Cloud Next 2026 is that this isn’t just about building multi-agent systems. It’s about closing the loop between planning, execution, evaluation, and optimization in a way that continuously improves outcomes over time.
What Google demonstrated goes beyond static orchestration. By combining evaluated expert networks, stateful memory, and large-scale simulation, they’ve effectively created a feedback-driven system where every run informs the next. Evaluator outputs don’t just score performance; they become structured inputs that refine planner behavior, influence simulation parameters, and ultimately reshape future decisions.
This is where theCUBE Research AppDev data provides important context: Organizations that operationalize feedback loops in AI systems see up to 3x faster model and workflow improvement cycles compared to those relying on static deployments.
The architectural implications are significant:
- Evaluator-driven refinement becomes a standard development pattern, not an afterthought
- Simulation environments evolve into testing grounds for production readiness, not just experimentation
- Memory systems act as institutional knowledge, capturing learnings across runs and teams
What’s emerging is a new lifecycle model for AI applications:
- Plan with context-aware, stateful agents
- Simulate at scale with realistic environmental modeling
- Evaluate using deterministic and non-deterministic criteria
- Refine based on structured feedback and stored memory
- Repeat with improved performance and reduced drift
This closed-loop system directly addresses one of the biggest enterprise challenges: agent drift over time. By continuously validating and recalibrating outputs, organizations can maintain alignment with business goals, regulatory requirements, and real-world conditions.
There’s also a governance angle here. As feedback loops become more automated, the need for policy-aware evaluation and controlled refinement pipelines becomes critical. This ties directly into the earlier emphasis on Agent Gateway, identity, and Wiz-driven remediation, ensuring that optimization doesn’t introduce unintended risk. The future of enterprise AI isn’t just multi-agent, it’s self-improving systems built on continuous evaluation and feedback loops.


