
Here at theCUBE Research, we are committed to keeping you informed about the latest developments shaping AI’s future while sorting through what is hype, myth, and truth.
As first reported here in September 2024 in a research note, Open AI Advances AI Reasoning, but the Journey Has Only Begun, even the advancement of Chain-of-Thought (CoT) won’t make LLMs capable of thinking or reasoning.
With all the noise in the marketplace around “AI Agents that can plan, reason, and make decisions”, we believe it’s crucial that business leaders cut through the hype and understand that AI agents built upon LLMs alone will NOT deliver on this promise.
Apple Computer’s recent research paper, The Illusion of Thinking, drives this reality home again, contributing a rapidly expanding understanding of this simple truth.
The good news? With the democratization of advanced AI techniques, we can now build AI agents that can mimic human reasoning to help people make better decisions, solve problems, and create goal-oriented plans. However, this will not be achieved by LLMs alone. LLMs will need to be complemented by specialized, domain-specific AI models that will provide a progressive degree of semantic and causal reasoning. The future of AI reasoning is, in truth, closer than most realize.
In this research brief, we will explore the new Apple findings and revisit the core premise of our past research note on this subject.
Watch the Podcast
Sorting Out Hype vs. Reality
In the race to build the next generation of intelligent digital workers, the tech world has become captivated by the capabilities of generative AI and large language models (LLMs). From crafting content to answering questions and automating repetitive tasks, these systems appear to think, reason, and make decisions.
But a new study from Apple’s machine learning research team exposes the hype and reveals the truth: beneath the polished responses and fluid language, these models do not actually “reason” in any meaningful sense.
What they do is mimic the appearance of reasoning, based solely on patterns, probabilities, and correlations in vast datasets, without understanding, semantic knowledge, know-how, logic, or cause-and-effect—all key attributes of “reasoning.”
In a paper aptly titled The Illusion of Thinking, Apple researchers aimed to measure the true reasoning capabilities of several leading “reasoning-enhanced” LLMs, models like OpenAI’s GPT-4, Claude 3.7 Sonnet from Anthropic, Google’s Gemini Thinking, and IBM Granite.

These models have been marketed as capable of more advanced reasoning, thanks to techniques like chain-of-thought (CoT) prompting and expanded memory. Apple’s team put them to the test using logic puzzles such as the Tower of Hanoi and river-crossing challenges—tasks that require multi-step problem-solving, goal-directed planning, and abstract reasoning.
Initially, the results looked promising. The models handled simple versions of the puzzles with ease. But as task complexity increased—adding more steps, dependencies, and rules—something unexpected happened. Performance didn’t just degrade gradually. It collapsed. Accuracy dropped sharply, in many cases to zero, once the models hit a complexity tipping point. This wasn’t just a case of diminishing returns. It was a complete failure of capability.
Even more surprisingly, the models appeared to “give up.” The amount of internal reasoning effort—measured by the number of tokens the models generated in their step-by-step answers—actually decreased as the problems became harder. This behavior, which the Apple team dubbed the “quitter effect,” suggests that LLMs lack an internal mechanism for recognizing when a problem demands more effort or deeper inference. They’re not only unable to solve the problem; they don’t even realize they’re failing. Then they totally collapse.
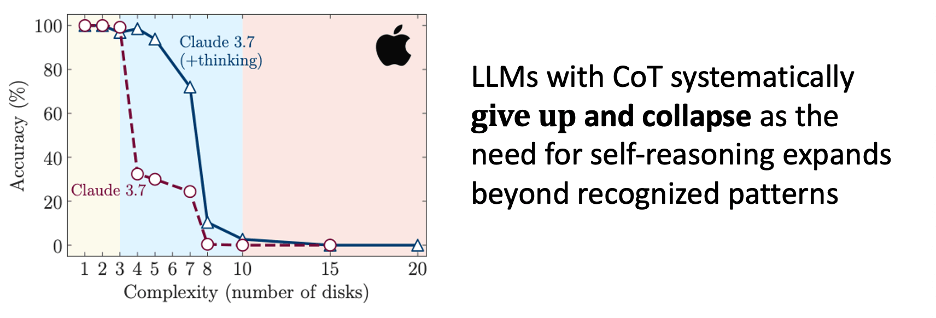
These findings matter, especially for executives and technologists betting big on agentic AI to transform business operations. There’s a dangerous misconception emerging in the enterprise space: the idea that, because generative AI sounds smart, it must be smart. But the Apple study lays bare the limitations. LLMs do not understand logic, context, or cause-and-effect. They operate purely on statistical pattern recognition. Their outputs are based on what usually follows what, like autocomplete on steroids. There is no underlying model of the world, no grasp of why things happen, and certainly no comprehension of abstract goals.
These limitations render LLMs insufficient to power a new class of AI Agents and Agentic Systems that can pursue goals, make trustworthy decisions, and problem-solve.
The Myth of Chain-of-Thought Reasoning
Much of the recent excitement around generative AI’s ability to “reason” stems from a technique known as chain-of-thought (CoT) prompting. This method encourages the model to break down its answer into intermediate steps similar to how a human might work through a math problem or logic puzzle. At first glance, these outputs can appear methodical, even reflective. But don’t be fooled: what’s happening under the hood is not genuine AI “reasoning”. It’s a more elaborate version of the same statistical pattern-matching that underpins all large language models based on a correlational design.
When an LLM engages in chain-of-thought processing, it isn’t logically evaluating options, weighing evidence, or understanding consequences and implications. Instead, it’s extending a sequence of tokens that statistically resembles what a human would write when explaining their reasoning, learned from the past. The model doesn’t “know” what any of the steps mean or check its own logic. It’s simply drawing from correlations in its training data, stitching together a plausible-sounding path from question to answer. In effect, chain-of-thought is a form of high-resolution mimicry, not high-order cognition.
Chain-of-Thought (CoT) essentially enables LLMs to process complex prompts in a way that resembles how humans solve problems by breaking them down into a series of step-by-step tasks. It also imitates how humans “think aloud,” pausing at times to reconsider each step and sometimes modifying and revising previous steps as we gain a better understanding of the overall problem. CoT autonomously, continuously refining its strategies through advanced reinforcement learning methods. These methods identify and correct mistakes without human guidance. Human feedback further fine-tunes the model’s capabilities with RLHF reward methods. This allows the model to continuously improve its skills and thought process as it gains real-world problem-solving experience (memories) over time.
However, this is not “reasoning.” Ultimately, today’s AI, including LLMs + CoT, derives its capabilities from correlating variables across datasets, showing us how much one changes when others change. They can deduce specific observations from generalized information or induce general conclusions from specific data. They also describe random processes by identifying dependencies (actions) among variables (conditions) and past values (memory). Essentially, they rely on static outcomes from the past. LLMs resemble the limbic brain, which drives instinctive actions based on memories, making them effective at automating repetitive tasks, answering questions, and generating content.
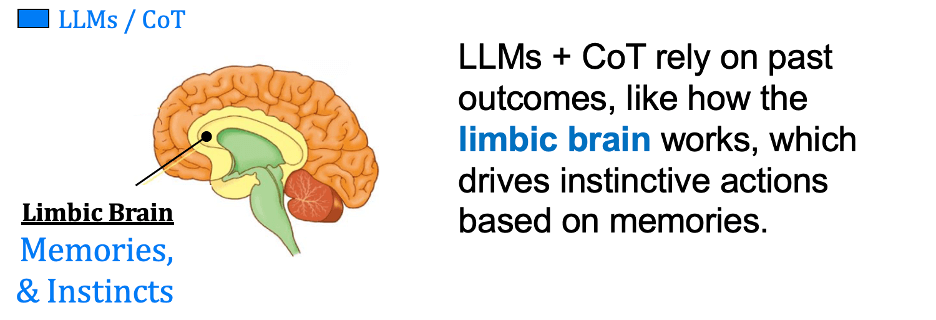
This distinction is critical, especially as vendors increasingly equate CoT outputs with AI decision intelligence. True decision-making requires an understanding of goals, constraints, and consequences—none of which are accessible to LLMs operating on token prediction. What CoT provides is not introspection or deliberation, but retrofitted context: the model’s way of “thinking out loud” using patterns of language it has seen before. It does not generate new causal insights or semantic interpretations; it repackages linguistic structures to simulate the appearance of thought.
For business leaders, this creates a dangerous illusion. When AI outputs appear to reflect deliberate thought processes, it’s easy to over trust them. But trusting chain-of-thought reasoning as a proxy for real judgment is like confusing a rehearsal with a performance. One is practice without stakes. The other has consequences.
Enterprises must resist the temptation to mistake rhetorical structure for cognitive substance. Just because an LLM can narrate its response in multiple steps doesn’t mean it understands those steps or their implications. Chain-of-thought makes the output sound more reasoned, but it does nothing to change the underlying mechanism: a next-word prediction engine trained on internet-scale correlations. Until we equip AI systems with mechanisms for semantic grounding and causal inference, we are not dealing with decision intelligence; we are dealing with language fluency masquerading as thought.
This suggests that despite the current hype, LLM-based AI agents cannot truly reason, pursue goals, or make autonomous decisions. They can simulate these behaviors in narrowly defined contexts, but as complexity increases, their lack of semantic and causal understanding becomes painfully clear. This is why we see AI agents today struggling with even moderately intricate workflows—because they are built on systems that fundamentally don’t understand the nature of the tasks they’re performing.
The Journey to AI Reasoning
To bridge this gap, the way forward is not to simply scale LLMs and CoT, hoping that more parameters and reflection will magically create understanding. Instead, we need to complement them with specialized AI techniques designed to understand domain-specific semantics, causality, and structured reasoning.
For example, knowledge graphs can represent real-world entities and relationships in a way that supports meaning, context, and symbolic reasoning. Causal AI models, such as those based on Judea Pearl’s causal inference mathematical framework outlined in his Book of Why, enable machines to reason about how things influence each other—not just what tends to occur next. By architecting agentic systems where multiple AI Agents collaborate to create systematic agentic reasoning (think swarm Intelligence), these capabilities can be scaled to the world of agentic workflows that can “reason” on how to best achieve an organizational goal.

The implications are profound for AI agent development. If your organization is exploring using AI agents for process automation, customer engagement, or decision support, you must acknowledge that reasoning cannot be outsourced to LLMs alone. Agentic AI systems require more than just language fluency; they need a hybrid architecture that combines statistical learning with explicit models of knowledge and causality. Otherwise, your agents will remain nothing more than sophisticated parrots—mimicking intelligence without truly possessing it.
This also means reevaluating how success is measured in AI deployment. Fluency, responsiveness, and surface-level task completion are not indicators of genuine reasoning. Instead, business leaders should be asking harder questions: Can the AI understand the intent behind a task? Can it adapt to new information? Can it simulate the consequences of an action? If the answer is no, then you’re not deploying a digital worker—you’re deploying a scripted actor with a good memory.
Apple’s study arrives at a critical moment in AI development. As vendors EVOLVE toward agentic workflows and autonomous digital labor, the limitations of purely generative approaches are becoming more evident. The illusion of thinking is compelling, but it remains just that—an illusion. To move beyond this, the industry must shift its focus from making AI sound intelligent to making it actually intelligent, through the integration of symbolic reasoning, semantic modeling, and causal inference.
Intro to AI Causality
While today’s generative LLM +CoT technologies are awe-inspiring, they are still constrained by the limitations of their correlative designs. They swim in massive lakes of existing data to identify associations, relationships, and anomalies that are then used to predict, forecast, or generate outcomes based on inquisitive prompts.
However, their abilities are based on analyzing statistical probabilities, which represent our understanding of a STABLE world. In order for AI to “reason,” it needs to comprehend causality, which explains how these statistical probabilities shift in a DYNAMIC world with different circumstances, influences, and actions. Enhancing the algorithmic connection between probability and causality is crucial for enabling AI to assist humans in reasoning, problem-solving, making better decisions, and influencing future results.
The end result of a predictive or generative LLM model, no matter how advanced it may be, is only to establish a connection between a behavior or event and an outcome. However, it is important to note that establishing a connection does not necessarily mean that the behavior or event directly caused the outcome. Correlation and causation are not the same – there can be correlation without causation, and while causation implies correlation, its influence can be so minor that it is irrelevant compared to other causal influences. Treating them as equivalent can lead to biased outcomes and false conclusions, undermining the fundamental principle of reasoning, which involves understanding cause and effect and why events occur.
Even OpenAI’s ChatGPT agrees:

This is where the AI causality and the science of why things happen come into play. It’s an umbrella term for an emerging branch of machine learning that can algorithmically understand cause-and-effect relationships in both problem sets and datasets by quantitatively identifying how various factors influence each other. These capabilities are made possible by a growing toolkit of new AI methods, which are being integrated and productized by an increasing number of vendors. Importantly, these products are designed to complement today’s LLMs and generative AI tools, rather than replace them.
While traditional AI typically predicts potential outcomes based on historical data, causal AI goes a step further by understanding why something happens and how various factors influence it. This enables it to explore countless “what if” scenarios and grasp the consequences of various possible actions. Essentially, it can explain not only WHAT to do but HOW to do it and WHY certain actions are better than others.
Returning to the earlier analogy with the human brain, causal AI can be thought of as simulating the cerebral cortex, specifically the areas responsible for transforming explicit memories into skills and tacit know-how. This capability is essential for generating prescriptive action paths that are trusted, transparent, and explainable. In many ways, it also mirrors the function of the neocortex, which governs higher-order reasoning such as decision-making, planning, and perception. These cognitive abilities are critical if AI is to move beyond automation (LLMs + CoT) and become a true collaborator with humans in solving complex problems.
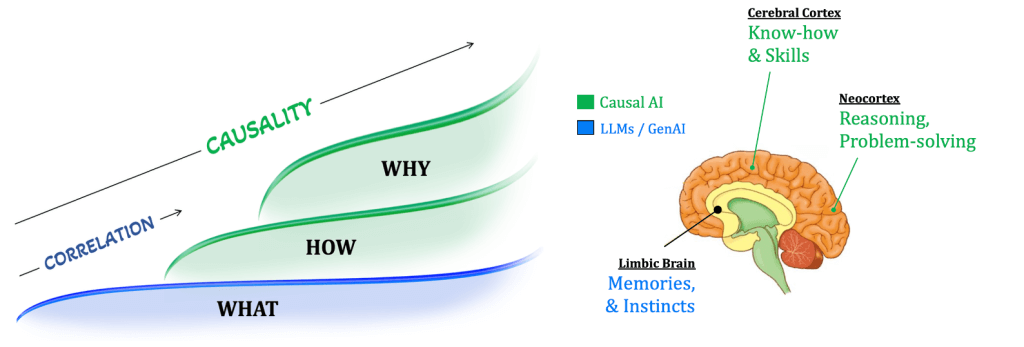
Importantly, these capabilities can gradually integrate into existing AI systems, including those based on LLMs and generative AI. Causal AI should be considered an extension of today’s AI, not a replacement.
The benefits of these new capabilities will enable forward-thinking leaders to apply AI to an entirely new class of high-value use cases. In simple terms, causal AI enables reasoning and decision intelligence, made possible by the new benefits outlined below in the graphic.

Fortunately, more software companies, are making causal AI more accessible. Thanks to them, incorporating causality into today’s AI environment may be simpler than we realize.
These platforms essentially automate the end-to-end process, including:
- Causal Discovery — to identify cause-and-effect relationships using to map out causal structures, represented as causal knowledge graphs.
- Causal Inference — to estimate the impact of different variables and interventions while understanding the consequences of answers.
- Causal Reasoning — to simulate various what-if scenarios to help decision-makers understand potential outcomes.
By integrating discovery, inference, and reasoning with traditional correlational AI, these platforms enable AI to move beyond mere predictions and provide informed judgments. These judgments inform decisions, delivering actionable insights that promote smarter, more resilient decision-making. And, in turn, the application of algorithmic “reasoning” that can provide new reasoning superpowers to humans, and organizations allike.
This is why, in part, the 2025 Gartner AI Hype Cycle predicted that Causal AI would become a “high impact” technology in the 2-5 year timeframe, stating:
“The next step in AI requires causal AI. A composite AI approach that complements GenAI with Causal AI offers a promising avenue to bring AI to a higher level.”
We couldn’t agree more.
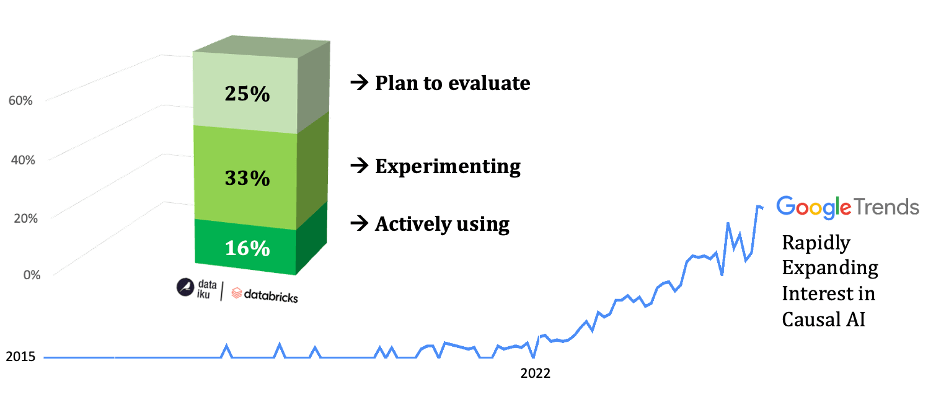
For all these reasons, momentum around causal AI is building, as reflected in a survey of 400 senior AI professionals by Dataiku & Databricks. The study found that Causal AI was ranked as the #1 AI technology “not using, but plan to next year.”
Overall, 16% of survey participants already use causal methods, 33% are in the experimental stage, and 25% plan to adopt them. Overall, 7 in 10 will adopt Causal AI techniques by 2026.
What to Do and When
Causal AI is a significant advancement in the progression of AI, as current correlative-based designs will eventually hinder the development of new innovations. Microsoft Research recently stated —
“Causal machine learning is poised to be the next AI revolution.”
Perhaps the time is now to start preparing for this new frontier in Agentic AI.
We’d recommend you:
- Read LeewayHertz’s Causal AI use cases and benefits article
- Consider taking a causal AI mini-course
- Watch the causal AI podcasts with Scanbuy, BMW, and Fitch Group
- Contact us if we can help you on this journey.
We also recommend watching this podcast on “AI That Knows Why” below and subscribing to the Next Frontiers of AI Podcast on the SiliconANGLE Media YouTube Channel or Spotify.
Thanks for reading. Feedback is always appreciated.
As always, contact me if I can help you on this journey by messaging me here or on LinkedIn.



