Executive Summary
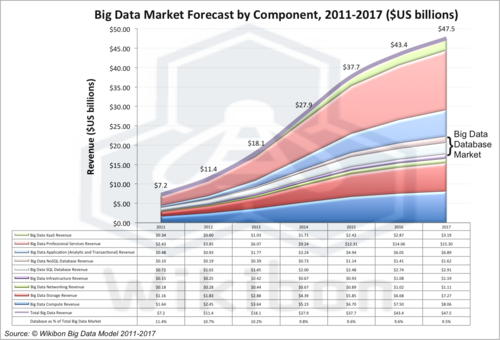
Wikibon’s latest Big Data Vendor Revenue and Market Projections, 2012-2017 study, details the components that go to make up the Big Data marketplace. This is shown in Figure 1 below.
Source: © Wikibon Big Data Model 2011-2017
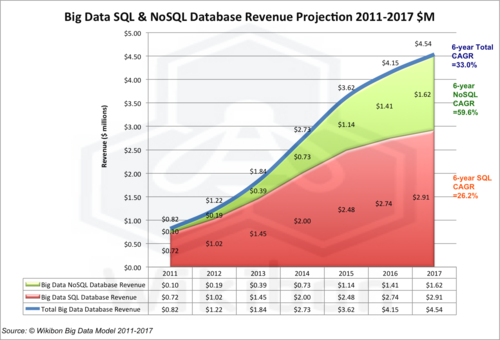
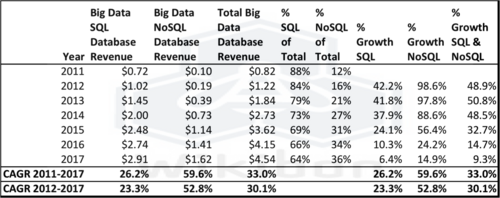
The research behind this article drills down into the database components, Big Data SQL database revenue, and Big Data NoSQL database revenue, highlighted in Figure 1. The total represents 10.4% of total Big Data in 2012, and remains at about 10% of total through 2017. Figure 2 shows the projection detail for the SQL & No SQL components. Some observations:
- The overall Big Data database 6-year CAGR projection is 33%, slightly lower than the Total Big Data 6-year CAGR of 37%.
- The NoSQL projections are very strong from a small base, with a 2011-2012 growth rate of 99%, a 2012-2013 growth rate of 98%, and an overall 2011-2017 (6-year) projection of 60%.
- The NoSQL base is $0.2 billion in 2012, only 16% of the combined SQL and NoSQL database market, and grows to $1.6 billion in 2017, 36% of the combined market.
- The equivalent SQL 6-year CAGR projection is 26%, from $1.0 billion in 2012 (84% of market) to $2.9 billion in 2017 (64% of market).
- Technology progression in Data-in-DRAM-Memory and Data-in-Flash-Memory will improve the scalability of SQL databases.
- Almost all applications are easier to program and require lower maintenance if SQL is used; NoSQL has greater scalability and lower technology costs for very large big-data applications.
- The last line of the table within Figure 1 shows the % of the total Big Data market that is attributed to database. This declines from 10.7% in 2011 to 9.5% in 2017. The amount of data managed by databases will grow rapidly, but the cost of database per unit of data will decrease. NoSQL databases are significantly lower cost than traditional SQL databases, and as they grow as a percentage of the market they will manage the lion’s share of data. SQL Big Data databases will migrate to manage smaller amounts of higher value data later in the cycle.
Source: © Wikibon Big Data Model 2011-2017
Both SQL and NoSQL databases have strong roles to play in Big Data solutions. CIO should ensure that the IT organizational structure does not become the cause of religious wars between different SQL and NoSQL factions. One solution is a focus on developing cross-trained application and operation groups that can use the right database technology for the appropriate business challenge. The biggest potential impact on Big Data processing costs (apart from Moore’s law) is likely to come from algorithmic advances from small start-ups. CIOs and CTOs should have a process for identifying these opportunities from among the megaphone noise of established vendors.
Big Data Characteristics of SQL & NoSQL Databases
The two types of database revenue components in the Wikibon model have very important differences:
SQL Database Revenue
- SQL is a relational database structure originally defined by IBM, based on Codd’s relational model described in his groundbreaking paper from 1970 “A Relational Model of Data for Large Shared Data Banks”. A SQL ANSI standard exists, however the standards are ambiguous, different SQL database vendors add unique extensions and do not implement the standard correctly. The result is vendor lock-in.
- SQL databases confirm to ACID properties (Atomicity, Consistency, Isolation, Durability), defined by Jim Gray soon after Codd’s work. These properties guarantee database transactions are processed reliably.
- SQL databases rely upon locking to implement the ACID capabilities. Locking database records ensures other transactions do not modify it until the first transaction succeeds or fails. Two-phase commit and other techniques are often applied to guarantee full isolation.
- The leading SQL databases from Oracle, IBM, and Microsoft are the most complex and sophisticated production software ever created, and power the transaction and query systems of the world.
- These SQL databases are extremely expensive. Recent Wikibon research shows that the cost of Oracle database software is about 90% of the cost of a database server. The cost of servers, storage and infrastructure software is only about 10%. Clearly this cost and complexity is a major constraint to the effective deployment of traditional SQL in Big Data systems.
- Traditional SQL systems used for queries are constrained by the single-thread performance of servers and the performance of IO. The result is significant performance constraints and poor scalability, especially with operations such as JOIN applied to very large datasets.
- Complex transactions can lock large numbers of records, resulting in significant overhead and serialization of transactions. The serialization means that the larger the system, the faster the processor required. IO performance is also a critical factor in the scalability of SQL databases. The faster the IO and the lower the variance of IO latency, the greater the scalability of database systems. – at as cost.
- The explosion of use of flash to solve these database problems by Internet companies such as Facebook and Apple is fueling the rapid growth of flash innovation companies like Fusion-io.
- Future SQL systems will increasingly make use of Open Source deployments such a MySQL on Linux, large DRAM servers using Open Source software such as Memcache, flash used as an extension of memory and flash-only arrays will all help SQL databases to scale significantly better over the next five years.
- The SQL databases hide the complexity of locking from the programmer, and allow good productivity in developing very complex systems.
- SQL will grow slower than NoSQL over the next five years, but from a much higher starting percentage (84%) point of the market in 2012.
- SQL will continue to be important and prominent database technology in Big Data over the next five years. SQL and especially Open Source SQL will be the default database technology for Big Data, because of greater programming efficiency, and greater data protection. However, Figure 2 shows that NoSQL Big Data revenues will grow much faster (60% CAGR 2011-2017 for NoSQL vs. 26% for SQL ).
- SQL databases will be focused on the later part of the Big Data Cycle, on smaller databases with higher value.
NoSQL Database Revenue
- NoSQL database systems evolved as solutions to the challenges in dealing with Big Data. Much of the initial drive came from internet companies, such as Amazon, Facebook & Google, to enable them to deal with huge volumes of data beyond the capability of conventional SQL database solutions.
- NoSQL database systems do not necessarily follow a fixed schema.
- NoSQL databases do not use SQL as a query language.
- NoSQL databases cannot necessarily guarantee ACID properties, Usually only eventual database consistency is guaranteed, or only simple transactions limited to a single data element.
- Deploying NoSQL means that consistency has to be dealt with by the designer and programmer, with very significant overheads in programming. Testing and maintenance are significantly more difficult in NoSQL environments.
- NoSQL Data can usually be partitioned across different servers as a distributed, fault-tolerant architecture. In this way, the system can easily scale out horizontally by adding more nodes/servers. Failure of a node can be tolerated.
- NoSQL databases can be implemented to manage large amounts of data, where performance and time-to-result is more important than data consistency.
- Early examples of NoSQL include the indexing of documents, managing the serving of pages on high-traffic web sites, delivering streaming media, and managing internet streaming data for advertising bidding.
- The current revenue growth rate of NoSQL databases is very high – 99% from 2011-2012, and 98% from 2012-2013 (See Table 1 in Footnote below). This declines with the maturity of the market, but is alway greater than SQL.
- NoSQL databases will focus more on the early stages of Big Data analysis cycle, and will account for the lion’s share of data under databases. NoSQL will be less prevalent in the later parts of the cycle, she the data volumes are not so high, and there is greater value on ease of programming and time to change.
Both SQL and NoSQL databases have strategic fit areas in both transactional and analytic Big Data. NoSQL Databases have advantages of scaleability and lower software and infrastructure costs. SQL databases have the advantage of easier programming and maintenance, software that works, ability to ensure data consistency and a rich ecosystem of tools. Some of the limitations of SQL databases, such as the requirement for single thread server performance and low IO latency will be mitigated by the use of Data-in-DRAM & Data-in-Flash technologies.
One of the characteristics of market maturity in High Performance Computing (HPC) has been the introduction of improved algorithms, which have drastically reduced compute requirements. An example is the reduction in compute required for DNA sequencing. Big Data would expect similar algorithmic improvements in all parts of the stack – processors, RAM memory, Flash as an extension of memory, storage and database. These improvements are likely to extend the range of Big Data projects that SQL can address. As Big Data projects get larger, NoSQL will become increasing important, especially in Data Brokers who want to create near realtime data extracts for specific verticals.
The overall conclusion is that both SQL and NoSQL databases will continue to have strong roles to play in Big Data solutions. Traditional SQL pricing models will need to change to be more Big Data friendly, or will be crowded out of the market. NoSQL databases vendors will struggle initially to gain a foothold in enterprises, but are likely to have more success in the cloud services market.
Big Data Revenue by Vendor
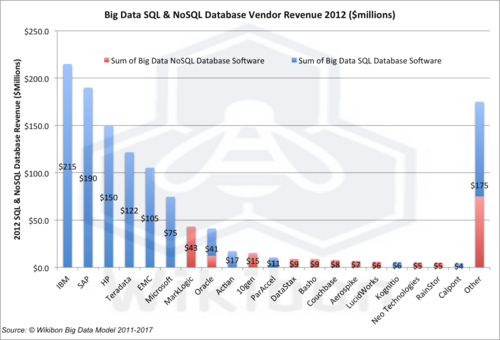
Figure 3 shows the 2012 Big Data Revenue by Vendor, split into SQL and NoSQL components. Observations include:
- The top six vendors all sell SQL solutions
- IBM with DB2 and Netezza is the leading Big Data Vendor with $215 million revenue, all from SQL products. IBM has 18% of the Big Data database revenues.
- SAP with HANA data-in-memory and sybase is in second place, with $190 million from SQL products. SAP has 18% of the Big Data database revenues.
- HP with Vertica is in third place, with $150 million from SQL. HP has 12% of the Big Data database revenues.
- Terradata has $122 million from its wide range of products and installed base and has 18% of the Big Data database revenues.
- EMC has $105 million in Big Data SQL revenue coming from its Greenplum purchase. EMC has 9% of the Big Data database revenues.
- MarkLogic is the leading NoSQL vendor, with $43 million in NoSQL products. MarkLogic has 4% of the Big Data database revenues.
- “Other” is the long tail totaling $175 million, with $100 million coming from SQL and $75 million from NoSQL.
Source: © Wikibon Big Data Model 2011-2017
The bottom line: the top five vendors have about 2/3rds of the database revenue, all from SQL-only product lines. Wikibon believes that NoSQL vendors will challenge these vendors hard of the next five years. However SQL will continue to retain over half of revenues for the foreseeable future.
Action Item: NoSQL Databases have advantages of scaleability and lower software and infrastructure costs. SQL databases have the advantage of easier programming and maintenance, software that works and a rich ecosystem. Use of Data-in DRAM & Data-in-Flash technologies and algorithmic improvements can extend the range of Big Data projects that SQL can address. As Big Data projects get larger, NoSQL will become very important. Both SQL and NoSQL databases have strong roles to play in Big Data solutions. CIO should focus on developing cross-trained application and operation groups that can use the right database technology for the right business problem at the right point in the Big Data cycle, and avoid religious wars.
Source: © Wikibon Big Data Model 2011-2017
Footnotes: Table 1 contains the detailed Wikibon Big Data Database findings for 2011 for 2012, and the projections for 2013-2017. This table is the basis for Figure 2 above.