
With George Gilbert
When Apache Spark became a top level project in 2014, and shortly thereafter burst onto the big data scene, it along with the public cloud disrupted the big data market. Databricks cleverly optimized its tech stack for Spark and took advantage of the cloud to deliver a managed service that has become a leading AI and data platform among data scientists and data engineers. However, emerging customer data requirements and market forces are conspiring in a way that we believe will cause modern data platform players generally and Databricks specifically to make some key directional decisions and perhaps even reinvent themselves.
In this Breaking Analysis we do a deeper dive into Databricks. We explore its current impressive market momentum using ETR survey data. We’ll also lay out how customer data requirements are changing and what we think the ideal data platform will look like in the mid-term. We’ll then evaluate core elements of the Databricks portfolio against that future vision and close with some strategic decisions we believe the company and its customers face.
To do so we welcome in our good friend George Gilbert, former equities analyst, market analyst and principal at Tech Alpha Partners.
Databricks Current Momentum is Impressive
Let’s start by taking a look at customer sentiment on Databricks relative to other emerging companies.
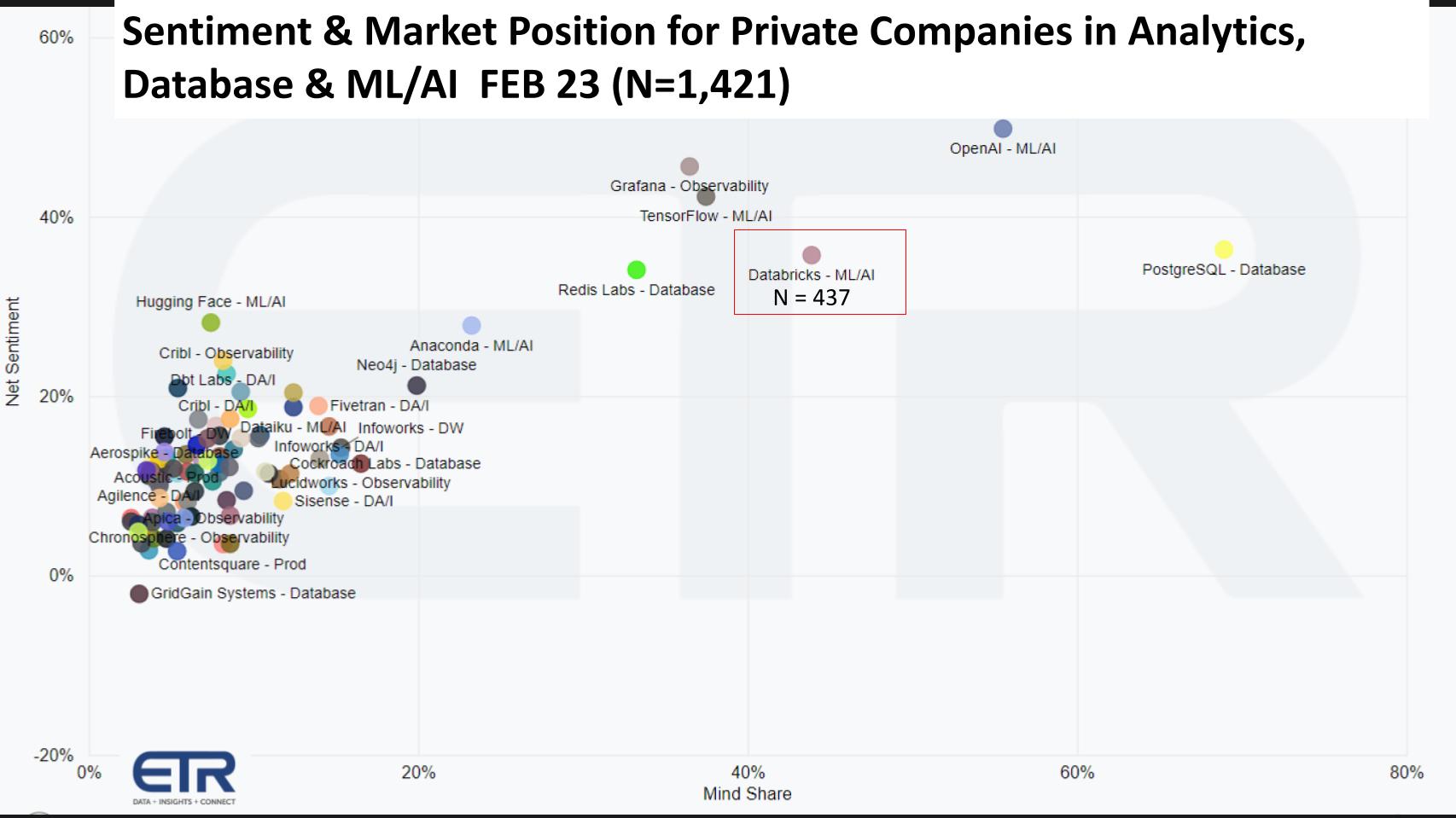
The chart above shows data from ETR’s Emerging Technology Survey (ETS) of private technology companies (N=1,421). We cut the data on the analytics, database and ML/AI sectors. The vertical axis is a measure of customer sentiment, which evaluates an IT decision maker’s awareness of a firm and the likelihood of evaluating, intent to purchase or current adoption. The horizontal axis shows mind share in the data set based on Ns. We’ve bordered Databricks with a red outline. The company has been a consistent high performer in this survey. We’ve previously reported that OpenAI, which came on the scene this past quarter, leads all names but Databricks is prominent, established and transacting deals, whereas OpenAI is a buzz machine right now. Note as well, ETR shows some open source tools just for reference. But as far as firms go, Databricks is leading and impressively positioned.
Comparing Databricks, Snowflake, Cloudera & Oracle
Now let’s see how Databricks stacks up to some mainstream cohorts in the data space.
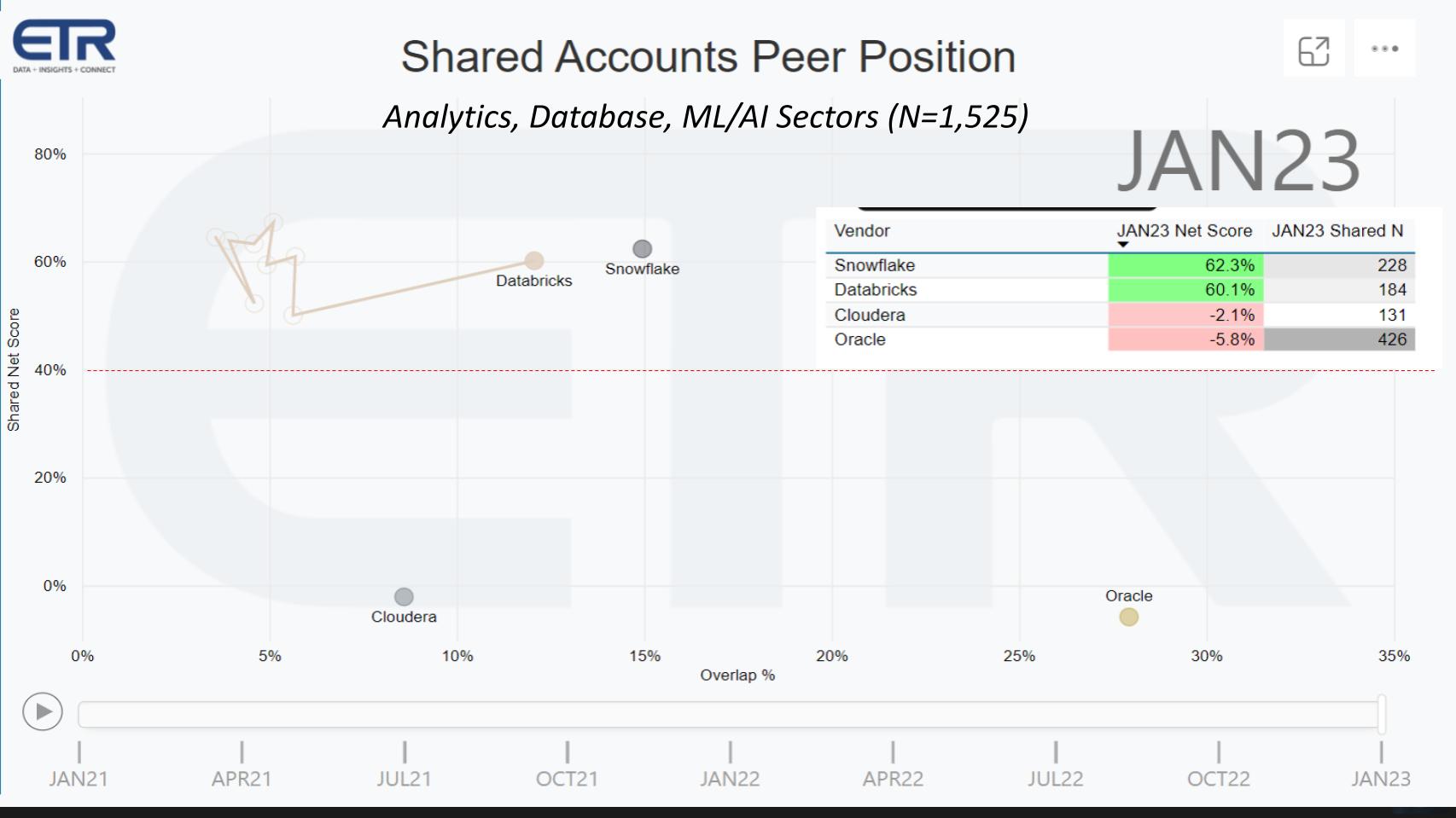
The chart above is from ETR’s quarterly Technology Spending Intentions Survey (TSIS). It shows Net Score on the vertical axis, which is a measure of spending momentum. On the horizontal axis is pervasiveness in the data set which is proxy for market presence. The table insert informs how the dots are plotted – Net Score against Shared N. The red dotted line at 40% indicates a highly elevated Net Score. Here we compare Databricks with Snowflake, Cloudera and Oracle. The squiggly line leading to Databricks shows their path since 2021 by quarter and you can see it is performing extremely well…maintaining an elevated Net Score, now comparable to that of Snowflake, and consistently moving to the right.
Why did we choose to show Cloudera and Oracle. The reason is that Cloudera got the whole big data era started and was disrupted by Spark / Databricks, and of course the cloud. Oracle in many ways was the target of early big data players like Cloudera. Here’s what former Cloudera CEO Mike Olson said in 2010 on theCUBE, describing “the old way” of managing data:
Back in the day, if you had a data problem, if you needed to run business analytics, you wrote the biggest check you could to Sun Microsystems, and you bought a great big, single box, central server. And any money that was left over, you handed to Oracle for a database licenses and you installed that database on that box, and that was where you went for data. That was your temple of information. -Mike Olson, Former CEO of Cloudera
[Listen to Mike Olson explain how data problems were solved pre-Hadoop].
As Mike Olson implies, the monolithic model was too expensive and inflexible and Cloudera set out to fix that. But the best laid plans as they say…
We asked George Gilbert to comment on the success of Databricks and how it has achieved success. He summarized as follows:
Where Databricks really came up Cloudera’s tailpipe was they took big data processing, made it coherent, made it a managed service so it could run in the cloud. So it relieved customers of the operational burden. Where Databricks is really strong is the predictive and prescriptive analytics space. Building and training and serving machine learning models. They’ve tried to move into traditional business intelligence, the more traditional descriptive and diagnostic analytics, but they’re less mature there. So what that means is, the reason you see Databricks and Snowflake kind of side by side is there are many, many accounts that have both Snowflake for business intelligence and Databricks for AI machine learning. Where Databricks also did really well was in core data engineering, refining the data, the old ETL process, which kind of turned into ELT, where you loaded into the analytic repository in raw form and refined it. And so people have really used both, and each is trying to get into the other’s domain.
Customer Perspectives on Databricks
The last bit of ETR evidence we want to share comes from ETR’s round tables (called Insights) run by Erik Bradley along with former Gartner analyst Daren Brabham.

Above we show some direct quotes of IT pros, including a data science head and a CIO. We’ll just make a few callouts – at the top…like all of us we can’t talk about Databricks without mentioning Snowflake as those two get us all excited. The second comment zeroes in on the flexibility and the robustness of Databricks from a data warehouse perspective, presumably the individual is speaking about Photon, essentially Databricks’ BI data warehouse. And the last point made is that despite competition from cloud players, Databricks has reinvented itself a couple of times over the years.
We believe it may be in the process of doing so again. According to George Gilbert:
Their [Databricks’] big opportunity and the big challenge, for every tech company, it’s managing a technology transition. The transition that we’re talking about is something that’s been bubbling up, but it’s really epochal. First time in 60 years, we’re moving from an application-centric view of the world to a data-centric view, because decisions are becoming more important than automating processes.
Moving from an Application-centric to a Data-centric World
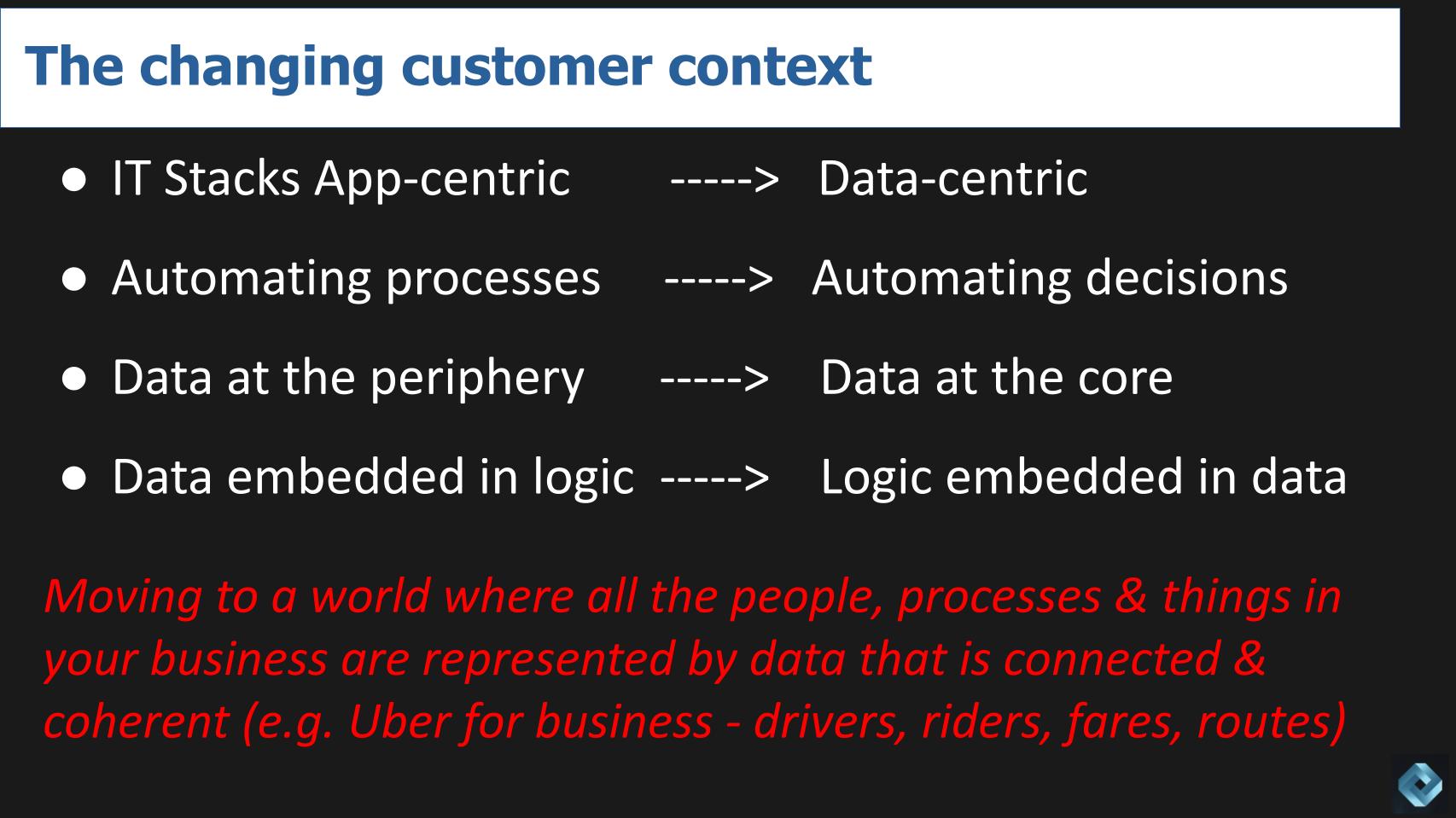
Above we share some bullets on the changing customer environment where IT stacks are shifting from application-centric silos to data centric stacks where the priority is shifting from automating processes to automating decisions. Data has historically been on the outskirts in silos but organizations like Amazon, Uber and Airbnb have put data at the core. And logic is increasingly being embedded in the data instead of the reverse. In other words, today the data is locked inside the apps – which is why people need to extract data and load it into a data warehouse.
The point is we’re putting forth a new vision for how data will be used and we’re using an Uber-like example to underscore the future state. George Gilbert explains as follows:
Hopefully an example everyone can relate to. The idea is first, you’re automating things that are happening in the real world and decisions that make those things happen autonomously without humans in the loop all the time. So to use the Uber example on your phone, you call a car, you call a driver. Automatically, the Uber app then looks at what drivers are in the vicinity, what drivers are free, matches one, calculates an ETA to you, calculates a price, calculates an ETA to your destination and then directs the driver once they’re there. The point of this is that cannot happen in an application-centric world very easily because all these little apps, the drivers, the riders, the routes, the fares, those call on data locked up in many different apps, but they have to sit on a layer that makes it all coherent.
We asked Gilbert to explain why if the Ubers and Airbnbs and Amazons are doing this already, doesn’t this tech platform already exist? Here’s what he said:
Yes, and the mission of the entire tech industry is to build services that make it possible to compose and operate similar platforms and tools, but with the skills of mainstream developers in mainstream corporations, not the rocket scientists at Uber and Amazon.
What Does the “Modern Data Stack” Look Like Today?
By way of review let’s summarize the trend that is propelling today’s data stack and has become a tailwind for the likes of Databricks and Snowflake.

As shown above, the trend is toward a common repository for analytic data. That might be multiple virtual warehouses inside of a Snowflake account or Lakehouses from Databricks or multiple data lakes in various public clouds with data integration services that allow developers to integrate data from multiple sources.
The data is then annotated to have a common meaning. In other words, a semantic layer enables applications to talk to the data elements and know that they have common and coherent meaning.
This approach has been highly effective relative to monolithic approaches. We asked George Gilbert to explain in more detail the limitations of the so-called modern data stack. Here’s what he said:
Today’s data platforms added immense value because they connected the data that was previously locked up in these monolithic apps or on all these different microservices. And that supports traditional BI and AI/ML use cases. But now if we want to build apps like Uber or Amazon.com, where they’ve got essentially an autonomously running supply chain and e-commerce app where humans only care and feed it. But the thing is to figure out what to buy, when to buy, where to deploy it, when to ship it…we needed a semantic layer on top of the data. So the data that’s coming from all those apps, the different apps in a way that’s integrated, not just connected, but it all means the same. The issue is whenever you add a new layer to a stack to support new applications, there are implications for the already existing layers. For example, can they support the new layer and its use cases? So for instance, if you add a semantic layer that embeds app logic with the data rather than vice versa, which we’ve been talking about, and that’s been the case for 60 years, then the new data layer faces challenges in the way you manage that data, the way you analyze that data. It’s not supported by today’s tools.
[Listen to George Gilbert explain the limitations of todays modern data stacks].
Performing Complex Joins at Scale will Becoming Increasingly Important
Today’s modern data platforms struggle to do joins at scale. In the relatively near future, we believe customers will be managing hundreds or thousands or more data connections. Today’s systems can maybe handle 6-8 joins in a timely manner, and that is the fundamental problem. Our premise is that a new big data era is coming and existing systems won’t be able to handle it without an overhaul.
Here’s how George Gilbert explains the dilemma:
One way of thinking about it is that even though we call them relational databases, when we actually want to do lots of joins or when we want to analyze data from lots of different tables, we created a whole new industry for analytic databases where you sort of munge the data together into fewer tables so you didn’t have to do as many joins because the joins are difficult and slow. And when you’re going to arbitrarily join thousands, hundreds of thousands or across millions of elements, you need a new type of database. We have them, they’re called graph databases, but to query them, you go back to the pre-relational era in terms of their usability.
[Listen to the discussion on complex joins and future data requirements].
What Does the Future Data Platform Look Like?
Let’s lay out a vision of the ideal data platform using the same Uber-like example.
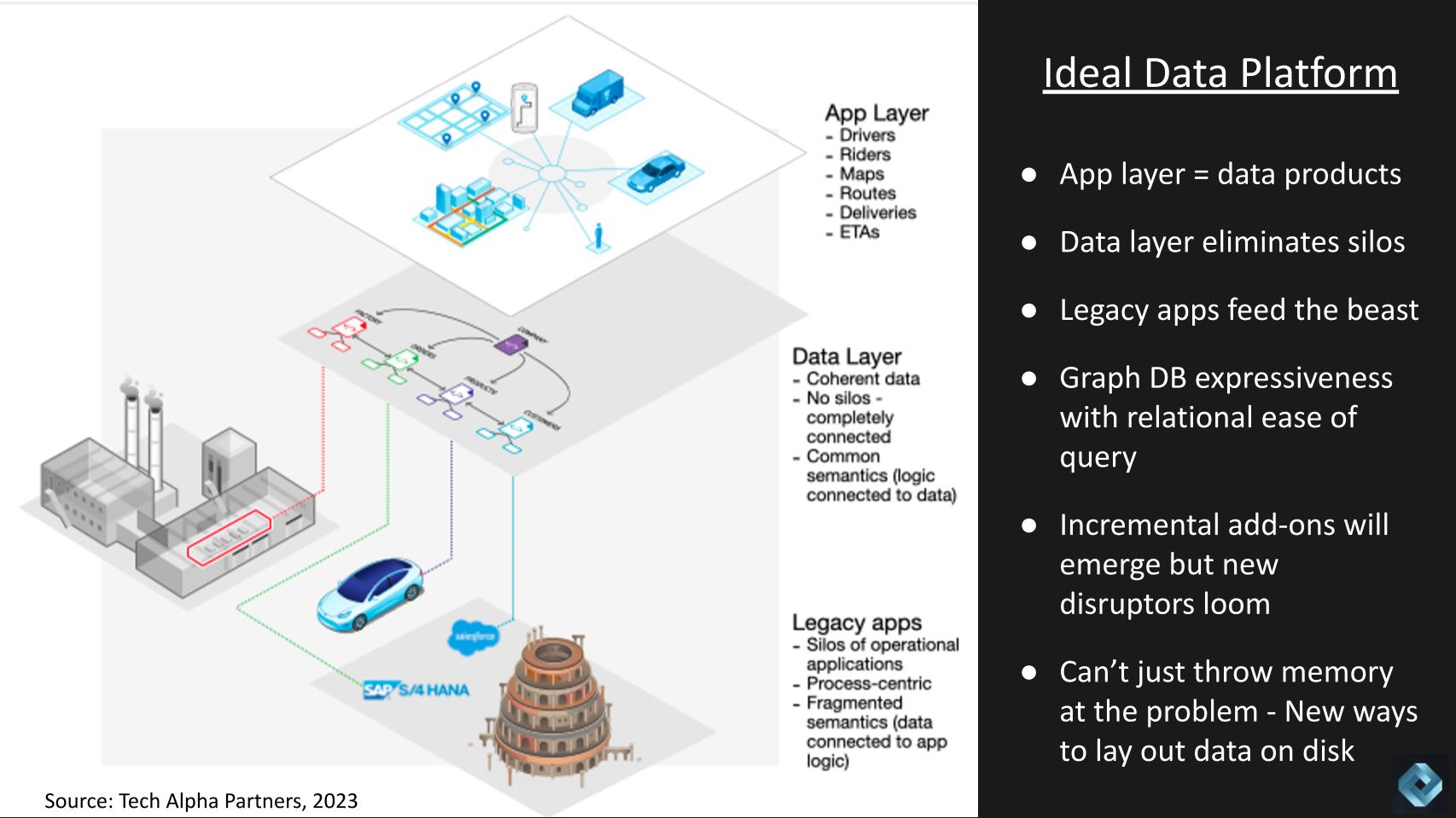
In the graphic above we show three layers. The application layer is where the data products reside – the example here is drivers, riders, maps, routes, etc. the digital version of people, places and things.
The next plane shows the data layer, which breaks down the silos and connects the data elements through semantics. In this layer, all data elements are coherent and at the bottom, the operational systems feed the data layer.
Essentially this architecture requires the expressiveness of a graph database with the query simplicity of relational databases.
We asked George Gilbert why can’t existing platforms just throw more memory at the problem to solve the problem. He explained as follows:
Some of the graph databases do throw memory at the problem and maybe without naming names, some of them live entirely in memory. And what you’re dealing with is a prerelational in-memory database system where you navigate between elements, and the issue with that is we’ve had SQL for 50 years, so we don’t have to navigate, we can say what we want without how to get it. That’s the core of the problem.
Gilbert further explains:
Graphs are great because you can describe anything with a graph, that’s why they’re becoming so popular. Expressive means you can represent anything easily. They’re conducive to, you might say, in a world where we now wantthe metaverse, like with a 3D world, and I don’t mean the Facebook metaverse, I mean like the business metaverse when we want to capture data about everything, but we want it in context, we want to build a set of digital twins that represent everything going on in the world. And Uber is a tiny example of that. Uber built a graph to represent all the drivers and riders and maps and routes.
But what you need out of a database isn’t just a way to store stuff and update stuff. You need to be able to ask questions of it, you need to be able to query it. And if you go back to pre-relational days, you had to know how to find your way to the data. It’s sort of like when you give directions to someone and they didn’t have a GPS and a mapping system, you had to give them turn by turn directions. Whereas when you have a GPS and a mapping system, which is like the relational thing, you just say where you want to go, and it spits out the turn by turn directions, which let’s say, the car might follow or whoever you’re directing would follow. But the point is, it’s much easier in a relational database to say, “I just want to get these results. You figure out how to get it.” The graph database, they have not taken over the world because in some ways, it’s taking a 50 year leap backwards.
Mapping Databricks’ Offerings to the Ideal Future State
Now let’s take a look at how the current Databricks offering maps to that ideal state that we just laid out. Below we put together a chart that looks at key elements of the Databricks portfolio, the core capability, the weakness and the threat that may loom.
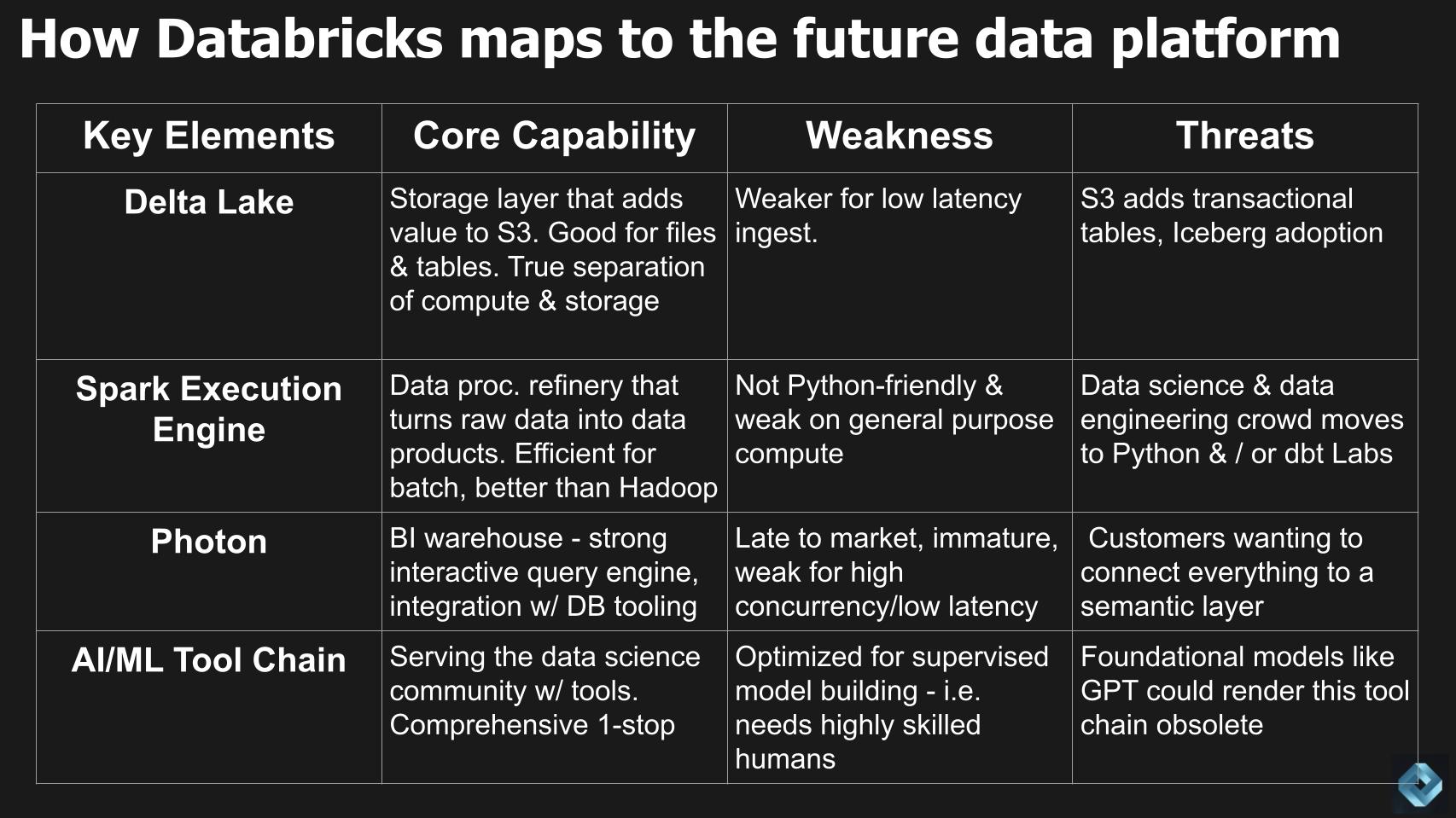
Delta Lake
Delta lake is the storage layer that is great for files and tables. It enables a true separation of compute and storage as independent elements but it’s weaker for the type of low latency ingest we see coming in the future. Some of the threats are AWS could add transactional tables to S3 (and/or other cloud vendors to their object stores) and adoption of Iceberg, the open source table format, could disrupt.
George Gilbert adds additional color:
This is the classic competitive forces where you want to look at what are customers demanding? What competitive pressures exist? What are possible substitutes? Even what your suppliers and partners might be pushing. Here, Delta Lake is at its core, a set of transactional tables that sit on an object store. So think of it in a database system, as this is the storage engine. So since S3 has been getting stronger for 15 years, you could see a scenario where they add transactional tables. We have an open source alternative in Iceberg, which Snowflake and others support.
But at the same time, Databricks has built an ecosystem out of tools, their own and others, that read and write to Delta tables, that’s what comprises the Delta Lake and its ecosystem. So they have a catalog, the whole machine learning tool chain talks directly to the data here. That was their great advantage because in the past with Snowflake, you had to pull all the data out of the database before the machine learning tools could work with it, that was a major shortcoming. Snowflake has now addressed and fixed that. But the point here is that even before we get to the semantic layer, the core foundation is under threat.
[Listen to George Gilbert’s drilldown into Delta Lake].
The Databricks Spark Execution Engine
Next we take a look at the Spark execution engine which is the data processing refinery that runs really efficient batch processing and disrupted Hadoop. But it’s not Python friendly and that’s an issue because the data science and data engineering crowd are moving in that direction…as well as increasingly using dbt.
George Gilbert elaborates as follows:
Once the data lake was in place, what people did was they refined their data batch and Spark. Spark has always had streaming support and it’s gotten better. The underlying storage as we’ve talked about is an issue. But basically they took raw data, then they refined it into tables that were like customers and products and partners. And then they refined that again into what was like gold artifacts, which might be business intelligence metrics or dashboards, which were collections of metrics. But they were running it on the Spark Execution Engine, which it’s a Java-based engine or it’s running on a Java-based virtual machine, which means all the data scientists and the data engineers who want to work with Python are really working in sort of oil and water.
Like if you get an error in Python, you can’t tell whether the problems in Python or where it’s in Spark. There’s just an impedance mismatch between the two. And then at the same time, the whole world is now gravitating towards dbt because it’s a very nice and simple way to compose these data processing pipelines, and people are using either SQL in dbt or Python in dbt, and that kind of is a substitute for doing it all in Spark. So it’s under threat even before we get to that semantic layer…it so happens that dbt itself is becoming the authoring environment for the semantic layer with business intelligent metrics. But that’s again, this is the second element that’s under direct substitution and competitive threat.
The Photon Query Engine
Moving down the table above now to Photon. Photon is the Databricks business intelligence warehouse that is layered on top of its data lake to form its lakehouse architecture. Photon has tight integration with the rich Databricks tooling. It’s newer and not well suited for high currency low latency use cases that we laid out earlier in this post.
George Gilbert adds additional color as follows:
There are two issues here. What you were touching on, which is the high concurrency, low latency, when people are running like thousands of dashboards and data is streaming in, that’s a problem because a SQL data warehouse, the query engine, something like that matures over five to ten years. It’s one of these things, the joke that Andy Jassy makes just in general, he’s really talking about Azure, but there’s no compression algorithm for experience. The Snowflake guys started more than five years earlier, and for a bunch of reasons, that lead is not something that Databricks can shrink. They’ll always be behind. So that’s why Snowflake has transactional tables now and we can get into that in another show.
But the key point is, so near term, it’s struggling to keep up with the use cases that are core to business intelligence, which is highly concurrent, lots of users doing interactive query. But then when you get to a semantic layer, that’s when you need to be able to query data that might have thousands or tens of thousands or hundreds of thousands of joins. And that’s a SQL query engine, traditional SQL query engine is just not built for that. That’s the core problem of traditional relational databases.
As a quick aside. We’re not saying that Snowflake is in a position to tackle all these challenges either. Because Snowflake is focused on data management and has more experience in that field, they may have more market runway, but many of the challenges related to graph databases and the challenges today’s modern data platforms face around complex joins apply for Snowflake as well as Databricks and others.
The Databricks AI/ML Tool Chain
Finally coming back to the table above we have the Databricks AI/ML tool chain. This has been a competitive differentiator for Databricks and key capability for the data science community. It’s comprehensive, best of breed and a one stop shop solution. But the kicker here is that it’s optimized for supervised model building with highly skilled professionals in the loop. The concern is that foundational models like GPT could cannibalize the current Databricks tooling.
We asked George Gilbert why couldn’t Databricks, like other software companies, integrate foundation model capabilities into its platform? Here’s what he said:
The sound bite answer to that is sure, IBM 3270 terminals could call out to a graphical user interface when they’re running on the XT terminal, but they’re not exactly good citizens in that world. The core issue is Databricks has this wonderful end-to-end tool chain for training, deploying, monitoring, running inference on supervised models. But the paradigm there is the customer builds and trains and deploys each model for each feature or application. In a world of foundation models which are pre-trained and unsupervised, the entire tool chain is different.
So it’s not like Databricks can junk everything they’ve done and start over with all their engineers. They have to keep maintaining what they’ve done in the old world, but they have to build something new that’s optimized for the new world. It’s a classic technology transition and their mentality appears to be, “Oh, we’ll support the new stuff from our old stuff.” Which is suboptimal, and as we’ll talk about, their biggest patron and the company that put them on the map, Microsoft, really stopped working on their old stuff three years ago so that they could build a new tool chain optimized for this new world.
Strategic Options for Databricks to Capitalize on Future Data Requirements
Let’s close with what we think the options and decisions are that Databricks has for its future architecture.

Above we lay out three vectors that Databricks is likely pursuing either independently or in parallel: 1) Re-architect the platform by incrementally adopting new technologies. Example would be to layer a graph query engine on top of its stack; 2) Databricks could license key technologies like graph database; 3) Databricks can get increasingly aggressive on M&A and buy in relational knowledge graphs, semantic technologies, vector database technologies and other supporting elements for the future.
George Gilbert expands on these options and addresses the challenges of maintaining market momentum through M&A:
I find this question the most challenging because remember, I used to be an equity research analyst. I worked for Frank Quattrone, we were one of the top tech shops in the banking industry, although this is 20 years ago. But the M&A team was the top team in the industry and everyone wanted them on their side. And I remember going to meetings with these CEOs, where Frank and the bankers would say, “You want us for your M&A work because we can do better.” And they really could do better. But in software, it’s not like with EMC in hardware because with hardware, it’s easier to connect different boxes.
With software, the whole point of a software company is to integrate and architect the components so they fit together and reinforce each other, and that makes M&A harder. You can do it, but it takes a long time to fit the pieces together. Let me give you examples. If they put a graph query engine, let’s say something like TinkerPop, on top of, I don’t even know if it’s possible, but let’s say they put it on top of Delta Lake, then you have this graph query engine talking to their storage layer, Delta Lake. But if you want to do analysis, you got to put the data in Photon, which is not really ideal for highly connected data. If you license a graph database, then most of your data is in the Delta Lake and how do you sync it with the graph database?
If you do sync it, you’ve got data in two places, which kind of defeats the purpose of having a unified repository. I find this semantic layer option in number three actually more promising, because that’s something that you can layer on top of the storage layer that you have already. You just have to figure out then how to have your query engines talk to that. What I’m trying to highlight is, it’s easy as an analyst to say, “You can buy this company or license that technology.” But the really hard work is making it all work together and that is where the challenge is.
A couple of observations on George Gilbert’s commentary:
- It wasn’t so easy for EMC, the hardware company, to connect all its boxes together and integrate. Likely because these hardware systems all have different operating systems and software elements;
- We’ve seen software companies evolve and integrate. Examples include Oracle with an acquisition binge leading to Fusion – although it took a decade or more. Microsoft struggled for years but its desktop software monopoly threw off enough cash for it to finally re-architect its portfolio around Azure. And VMware to a large extent has responded to potential substitutes by embracing threats like containers and extending its platform via M&A into new domains like storage, end user computing, networking and security;
- That said, these three examples are of firms that were established with exceedingly healthy cash flows;
- Databricks ostensibly has a strong balance sheet given that it has raised several billion dollars and has significant market momentum. As a private company it’s difficult to tell as outsiders but it’s likely the company has inherent profitability and some knobs to turn in a difficult market whereby it can preserve its cash. The argument could be made both ways for Databricks. Meaning as a less mature company it has less baggage. On the other hand as a private emerging firm it doesn’t have the resources of an established player like those mentioned above.
Key Players to Watch in the Next Data Era
Let’s close with some players to watch in the coming era as cited in #4 above. AWS, as we talked about have options by extending S3. Microsoft was an early go to market channel for Databricks – we actually didn’t address that much. Google as well with its data platform is a player. Snowflake of course – we’ll dissect their options in the future, dbt Labs – where do they fit? And finally we reference Bob Muglia’s company, Relational.ai.
George Gilbert summarizes his view of these players and why they are ones to watch:
Everyone is trying to assemble and integrate the pieces that would make building data applications, data products easy. And the critical part isn’t just assembling a bunch of pieces, which is traditionally what AWS did. It’s a Unix ethos, which is we give you the tools, you put ’em together, ’cause you then have the maximum choice and maximum power. So what the hyperscalers are doing is they’re taking their key value stores, in the case of AWS it’s DynamoDB, in the case of Azure it’s Cosmos DB, and each are putting a graph query engine on top of those. So they have a unified storage and graph database engine, like all the data would be collected in the key value store.
Then you have a graph database, that’s how they’re going to be presenting a foundation for building these data apps. dbt Labs is putting a semantic layer on top of data lakes and data warehouses and as we’ll talk about, I’m sure in the future, that makes it easier to swap out the underlying data platform or swap in new ones for specialized use cases. Snowflake, what they’re doing, they’re so strong in data management and with their transactional tables, what they’re trying to do is take in the operational data that used to be in the province of many state stores like MongoDB and say, “If you manage that data with us, it’ll be connected to your analytic data without having to send it through a pipeline.” And that’s hugely valuable.
Relational.ai is the wildcard, ’cause what they’re trying to do, it’s almost like a holy grail where you’re trying to take the expressiveness of connecting all your data in a graph but making it as easy to query as you’ve always had it in a SQL database or I should say, in a relational database. And if they do that, it’s sort of like, it’ll be as easy to program these data apps as a spreadsheet was compared to procedural languages, like BASIC or Pascal. That’s the implications of Relational.ai.
Regarding the last point on Relational.ai, we’re talking about completely rethinking database architectures. Not simply throwing memory at the problem but rather rearchitecting databases down to the way data is laid out on disk. This is why it’s not clear that you could take a data lake or even a Snowflake and just put a relational knowledge graph on top of those. You could potentially integrate a graph database, but it will be compromised because to really do what Relational.ai is trying to do, which is bring the ease of Relational on top of the power of graph, you actually need to change how you’re storing your data on disk or even in memory. So you can’t simply add graph support to a Snowflake, for example. Because if you did that, you’d have to change how the data is physically laid out. And that would break all the tools that have been so tightly integrated thus far.
How Soon will the Next Data Era be Here & What Role Does the Semantic Layer Play?
We asked George Gilbert to predict the timeframe in which this disruption would happen. Here’s what he said:
I think something surprising is going on that’s going to sort of come up the tailpipe and take everyone by storm. All the hype around business intelligence metrics, which is what we used to put in our dashboards where bookings, billings, revenue, customer, those were the key artifacts that used to live in definitions in your BI tools, and dbt has basically created a standard for defining those so they live in your data pipeline or they’re defined in their data pipeline and executed in the data warehouse or data lake in a shared way, so that all tools can use them.
This sounds like a digression, it’s not. All this stuff about data mesh, data fabric, all that’s going on is we need a semantic layer and the business intelligence metrics are defining common semantics for your data. And I think we’re going to find by the end of this year, that metrics are how we annotate all our analytic data to start adding common semantics to it. And we’re going to find this semantic layer, it’s not three to five years off, it’s going to be staring us in the face by the end of this year.
We live in a world that is increasingly unpredictable. We’re all caught off guard by events like the top VC bank in Silicon Valley shutting down. The stock market is choppy. The Federal Reserve is trying to be transparent but struggles for consistency and we’re seeing serious tech headwinds. Oftentimes these trends create conditions that invite disruption and it feels like this could be one of those moments where new players and a lot of new technology comes to the market to shake things up.
As always, we’ll be here to report, analyze and collaborate with our community. What’s your take? Do let us know.
Keep in Touch
Many thanks George Gilbert for his insights and contributions for this episode. Alex Myerson and Ken Shifman are on production, podcasts and media workflows for Breaking Analysis. Special thanks to Kristen Martin and Cheryl Knight who help us keep our community informed and get the word out. And to Rob Hof, our EiC at SiliconANGLE.
Remember we publish each week on Wikibon and SiliconANGLE. These episodes are all available as podcasts wherever you listen.
Email david.vellante@siliconangle.com | DM @dvellante on Twitter | Comment on our LinkedIn posts.
Also, check out this ETR Tutorial we created, which explains the spending methodology in more detail.
Watch the full video analysis:
Image: Postmodern Studio
Note: ETR is a separate company from Wikibon and SiliconANGLE. If you would like to cite or republish any of the company’s data, or inquire about its services, please contact ETR at legal@etr.ai.
All statements made regarding companies or securities are strictly beliefs, points of view and opinions held by SiliconANGLE Media, Enterprise Technology Research, other guests on theCUBE and guest writers. Such statements are not recommendations by these individuals to buy, sell or hold any security. The content presented does not constitute investment advice and should not be used as the basis for any investment decision. You and only you are responsible for your investment decisions.
Disclosure: Many of the companies cited in Breaking Analysis are sponsors of theCUBE and/or clients of Wikibon. None of these firms or other companies have any editorial control over or advanced viewing of what’s published in Breaking Analysis.


