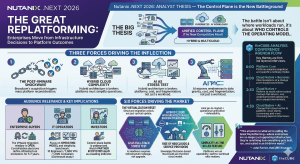
Premise: Big data pro’s have a plethora of mix and match tools from which to choose in building applications. What’s not clear, however, is whether they actually fit together in practice as well as they do in theory.
Based on the experiences of leading Internet companies’ experiences, common application design patterns have been emerging for mainstream big data pro’s. Using these common designs, mainstream companies can mix and match open source as well as proprietary tools (see Figure 1). While vendors may have solved the problem of selection, the mix and match approach has side effects in operational and development complexity. Some vendors have begun making progress in solving complexity by designing more of the services to work as a single unit. We’ve highlighted these issues before (here and here). But most vendors of popular services haven’t solved the problem of administrative or operational simplicity.
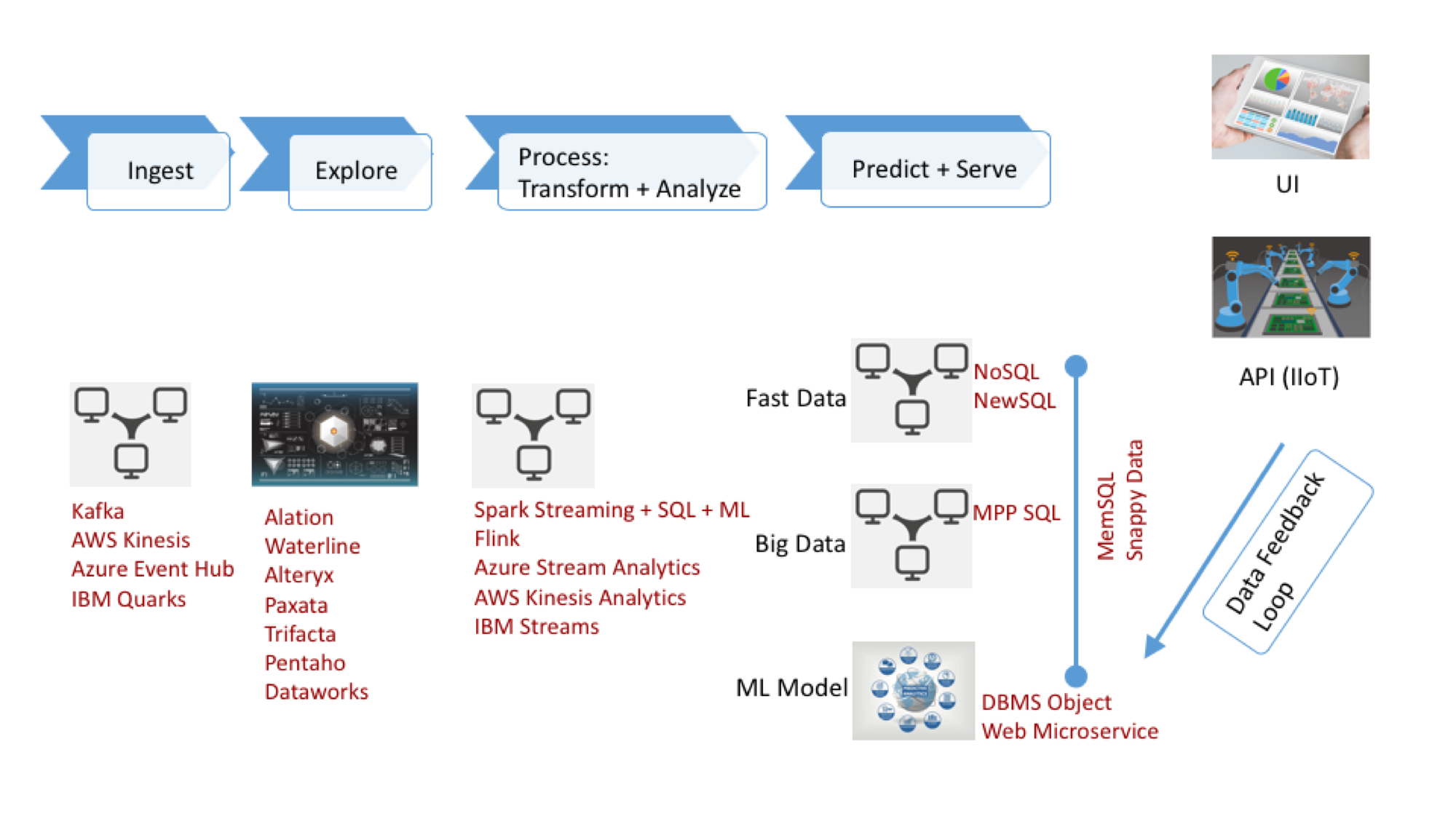
Wikibon groups the administrative functions of big data applications into four categories, each with one or more tasks. The challenge for administrators is that virtually every application service has its own way of implementing all administrative tasks. That matrix of application services versus administrative tasks is what is slowing big data deployments outside the largest or most sophisticated organizations (see Figure 2).
- Trusted systems require authentication, authorization, and data governance. Where trusted systems tend to break down is in the “cracks” between the boundaries of the analytic services.
- Scalability requires elasticity, but separate clusters for separate products adds latency and complexity in different data distribution schemes. Both latency and differing data distribution schemes are the enemy of simple and fast data pipelines.
- Resilience builds on availability & recovery and resource isolation. If different services handle availability and recovery differently, the analytic data pipeline is likely to be in an inconsistent state.
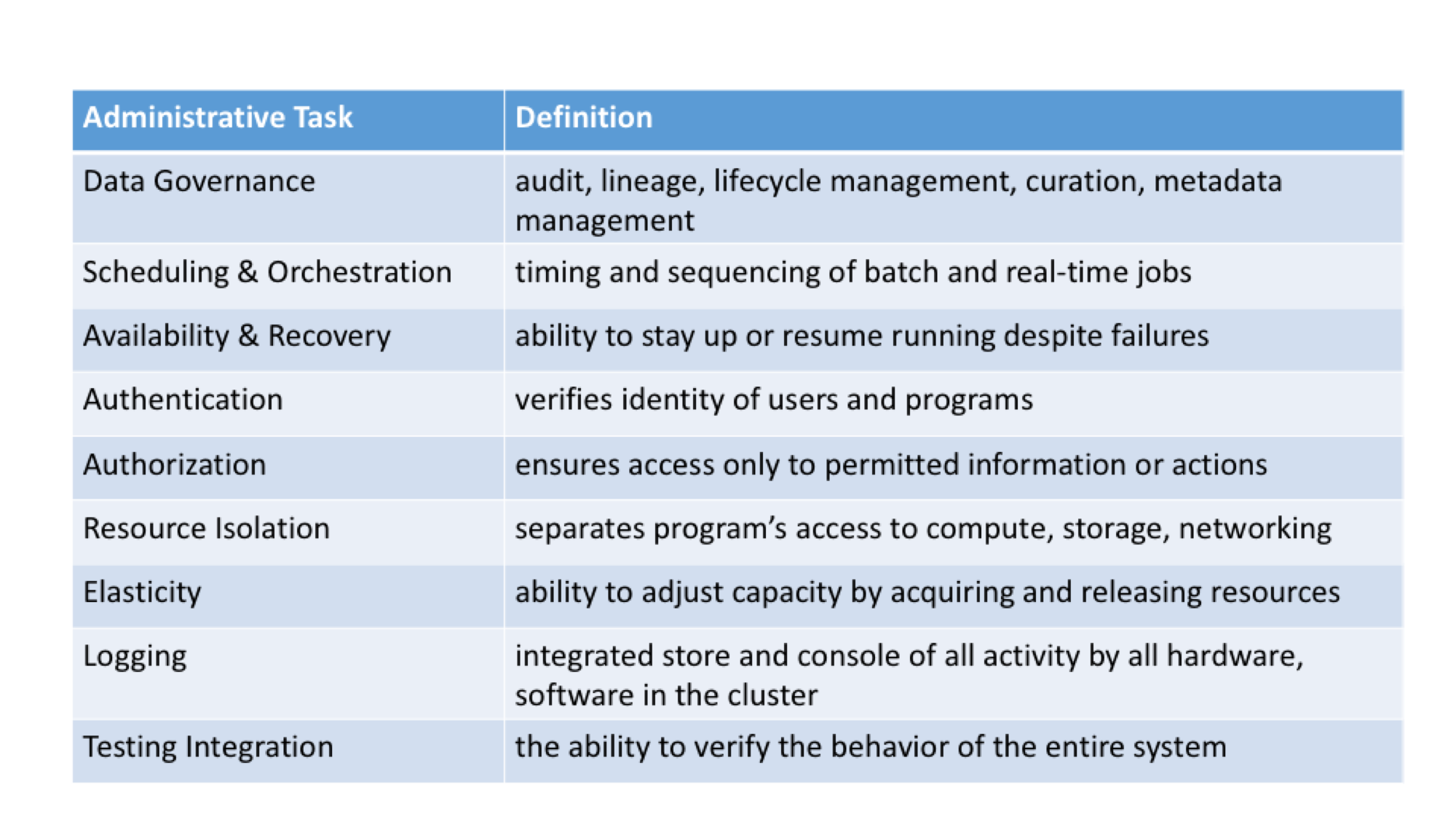
- Automation requires scheduling & orchestration, testing integration, and logging. More services from more vendors increases the likelihood that they will use different technology for scheduling and orchestration nodes across a cluster.(For a detailed definition of the administrative tasks that are the source of complexity see Figure 3).
Trusted systems require authentication, authorization, and data governance.
Sharing common authentication and authorization services across Hadoop components has been a challenge; sharing these services across the wider ecosystem of services now required to build a pipeline is an even greater problem. Some services use Kerberos and some LDAP. Some of the Hadoop-originated services use one or more of Knox, Sentry, and Ranger for authorizing different access permissions, depending on the vendor. But many Hadoop services don’t support these yet. And non-Hadoop services support something entirely different. Kafka stores permissions in Zookeeper and plans to store them internally. MemSQL manages permissions within its DBMS. Data governance, which includes audit, lineage, lifecycle management, curation, and metadata management has the same challenges. Cloudera built its own solution, Navigator. But it doesn’t extend beyond Cloudera services.
Trust in the integrity of the process and its output requires the following: knowing which people or programs accessed the pipeline, that they only accessed what the were allowed to see, and that any changes to the data were tracked in a continuous “chain of custody” across the pipeline. Perhaps the most promising product in this area is Alation. Alation claims to handle data governance tasks across products without requiring them to be modified in order to work with it.
Scalability requires elasticity but separate clusters for separate products adds latency and complexity in different data distribution schemes.
Big data services scale elastically, enabling them typically to add storage or compute as necessary. With Hadoop, several services such as Hive and HBase might share a common store, with the underlying data residing in HDFS.
This elasticity gets challenging when data has to move across compute and/or storage clusters belonging to different services within the pipeline. Data gravity slows this process way down. Having the data partitioned and sharded across servers (i.e. elastically scaled) differently between clusters makes the problem much worse. If data ingested into a Kafka cluster isn’t divided up the same way it’s divided up in Spark, it has to get reshuffled when it moves between the clusters. That reshuffling is extremely expensive because it taxes network and/or storage bandwidth, both of which are typically tight.
Resilience builds on availability & recovery and resource isolation.
Distributed systems in the enterprise have to be able to continue operating even if some nodes go offline. They also have to bring the offline nodes up to date when back online. Resilience also means multiple services can share access to infrastructure by isolating which service can access which infrastructure resources.
Again, a mix and match approach to services makes an end-to-end pipeline difficult to operate. Most Hadoop-based services use YARN for resource isolation and tend to use Zookeeper to keep track of which services are online and healthy. Outside the Hadoop ecosystem, services might use Mesos instead of YARN. Availability and recovery also typically work differently. Kafka and Spark are examples of two products that reinforce each other with availability and recovery. Spark doesn’t yet handle well sudden spikes of high speed incoming data. Kafka can operate as a buffer to keep pressure from building up while Spark works through data at a more measured pace. Maintaining high availability within a service also depends on a protocol that all the nodes in the service use to communicate their health with each other. When different services use different protocols, they can react differently to the same failure event, like a network partition going down. In other words, the different parts of the pipeline can be out of kilter.
Automation requires scheduling & orchestration, testing integration, and logging.
By definition, an analytic data pipeline is a sequence of operations that ingests raw data and turns it into actionable insight. Scheduling and orchestration makes sure all the services properly share resources and run and complete in the proper sequence.
Here, there are also a multitude of choices for scheduling and orchestration just in the container ecosystem. Although the resilience section talked about YARN for resource isolation, it’s also relevant for scheduling. Resource managers like YARN work with schedulers to make sure services are on the right servers and can deliver required performance. YARN competes with Mesos for products outside the Hadoop-originated ecosystem and Mesos couldn’t be more different. Mesos handles coarse-grained scheduling on its own but relies on each service to handle its own concurrency needs for scheduling activities within the service. An MPP SQL DBMS would typically have a sophisticated concurrency capability that YARN may not know how to interact with.
Action Item: Wikibon recommends mainstream companies look to public cloud providers as partners in building and deploying big data applications. The public cloud vendors can make operating the services in the open source ecosystem simpler and they also offer increasingly simple proprietary services. While the proprietary services come with a greater lock-in trade-off, they are becoming more accessible as well.