
 The “big four” megatrends of cloud, mobile, social and Big Data are putting new pressures on IT departments. These high level forces are rippling through to create demands on infrastructure as follows:
The “big four” megatrends of cloud, mobile, social and Big Data are putting new pressures on IT departments. These high level forces are rippling through to create demands on infrastructure as follows:
Cloud – Amazon has turned the data center into an API. This trend is forcing CIOs, as best they can, to replicate the agility, cost structure and flexibility of external cloud service providers. Unlike outsourcing of the 1990’s, which had diseconomies of scale at volume, cloud services have marginal economics that track software (i.e. incremental costs go toward zero). This trend will put added pressure on IT to respond to the cloud.
Mobility – Most practitioners in the Wikibon community say they have a “love/hate” relationship with mobile. On the one hand, like many end user initiatives, accommodating mobile creates extra cycles for IT. However with mobile, the IT pros are all mobile users so they are part of the drive toward mobile.
Social – is not something that many IT pros traditionally may have time for during business hours but that is changing. Social is becoming an increasingly popular form of collaboration, information gathering and messaging. And social contributes to data creation.
Big Data – in a recent survey of 300 Wikibon practitioners, 95% said that they’d either already shifted resources away from traditional data warehouse infrastructure, toward Hadoop (65%) or they would by the end of 2014 (30%). Big Data has turned data growth from a problem of management into an opportunity.
These four trends are stressing traditional storage system designs which are changing rapidly. One of the most fundamental changes is the increasing use of large memories and flash-first architectures within storage systems, particularly at the high end of the market.
Memory Storage
Using large memories in storage is not new. For decades, storage function has been offloaded from the processor, out to the storage network—powered by mechanical spinning disk and large caches. When EMC invented Symmetrix in the late 1980s, the significant innovation was not only that it used smaller 5.25” disks drives to replace larger devices; but also that it used a large memory cache combined with a giant backend using many spinning disks. This was important because the traditional Achilles heel of disk systems has been writes. The higher the write intensity (in general) the more challenging performance becomes.
As such the bottleneck of even cached disk systems designs has been the ability to de-stage the cache to spinning disk. What Symmetrix showed us is that having a huge disk backend, while expensive, delivered the highest performance in the most challenging write environments.
The declining costs of memory combined with the consumer volumes of flash are changing storage infrastructure dramatically. New storage system designs are combining large memories and flash to take advantage of multicore processors, delivering new levels of performance. What’s different and new is the flash layer is persistent.
Flash-First
A lynchpin of storage infrastructure transformation is memory storage generally and flash-first architectures specifically. When we talk about flash-first, we mean that a write completes to the persistent flash layer, not to a spinning disk.
David Floyer in a research note last year explained the nuances of flash-first using a ZFS appliance as an example. The ZFS box is a good reference for memory storage because it uses very large memories, large caches and is progressing in a way that strongly underlines the flash trends we’ve been talking about at Wikibon for years, namely:
- Flash costs are declining faster than those of spinning disk
- Flash-first will deliver better scale, lower CAPEX and lower OPEX than traditional arrays that signal a write is complete only when it hits the spinning disk layer
- Big flash and large memory-intensive designs have the potential to exploit multicore processors better than traditional arrays
Floyer’s argument was that flash-first architectures scale (in terms of IOs) much better than flash cache approaches – i.e. those designs that use cache as a read buffer and don’t signal a write as complete until it hits the spinning disk.
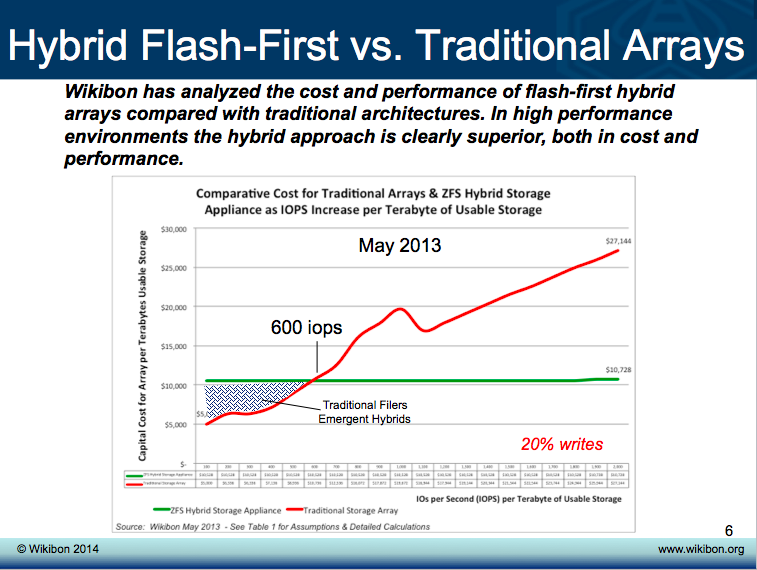
This chart shows data from May of 2013. It shows CAPEX (normalized per TB) on the X-axis and IOPS on the horizontal axis (from 500 to 20,000 IOPS). The workload has a 20% write intensity. Note the crossover point at 600 IOPS. In other words, at 600 IOPs or less it will be cheaper to use traditional filers/array designs.
Fast forward about one year:
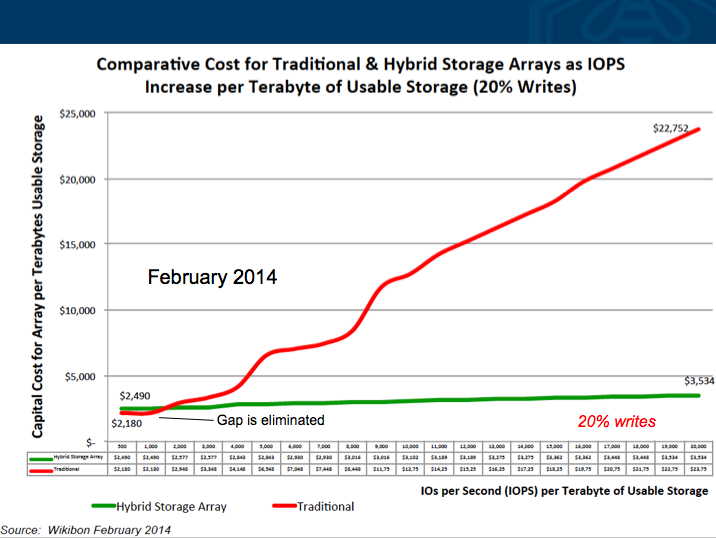
What you see one year later is the effect of memory/flash-intensive storage exploits rapidly declining flash costs and advances in multi-core. The result is less stuff to do the same amount of work and a equalization of the low end gap. This obviously ripples through to total cost of ownership, as maintenance and OPEX will be reduced.
There are other flash-first approaches on the market, notably all-flash arrays of course, such as those from IBM/TMS, Pure, XtremIO, 3PAR, SolidFire, etc. These, unlike the ZFS line of products are better suited for OLTP-intensive workloads.
ZFS arrays fit in the so-called hybrid array category – i.e. those that utilize both spinning disk and flash. The ZFS series again is notable in its aggressive use of memory. Oracle’s latest announcement (ZS3-2/4) uses huge amounts of DRAM (512GB – 2TB) and write flash (4-10TB). Of all the vendors we track, Oracle appears to be the most aggressive with respect to its use of large memories and flash capacities.
The question we’re often asked by Oracle customers—is this a general trend for the industry or a niche product for Oracle? We respond with two points:
- Oracle’s ZS line of products is an up-scale enterprise product geared toward bandwidth workloads – i.e. moving files fast. So things like backup and ETL within Oracle environments are the best fit.
- Oracle appears to be eyeing new workloads. The recent announcement of RESTful APIs for ZS3-2 indicates an affinity toward OpenStack and perhaps VMware…but clearly these will be in situations where Oracle customers want to connect into these management layers (rather than as a general purpose storage platform).
Other hybrid arrays tend to be succeeding in workload-specific situations. For example, Tintri, a VMware specialist, has a flash-first architecture with large memory storage. Tegile does well in lower-end mixed Microsoft workloads while hot IPO company Nimble is trying to expand its TAM beyond the low end and move up scale.
All of these companies are eying a large TAM, playing off the popularity (thanks to NetApp) of NFS and the growth of unstructured data. NetApp is fighting hard with Clustered ONTAP to address scalability issues that have challenged large NetApp installations. Everyone trying to scale or thinking about scale is driving toward memory storage.
Takeways
Flash use by Wikibon IT pros tends to be dominated by jamming flash into existing arrays. This is a smart move because it can extend the life of an array and deliver better application performance. But we often tell our community this is a Band-Aid approach that will not survive the onslaught of new memory-intensive architectures that are designed for flash at scale. We also stress:
- Without a “write to flash first” architecture, the cost of software and hardware at high-end scale becomes prohibitive; for low-end workloads this is not an issue.
- This ripples thru to OPEX because the amount of effort required at scale to tune systems is expensive.
- Traditional arrays today don’t scale well- i.e. Ones that use “Flash Cache” (reads) and SSD (writes). The problem w/SSD is you have to manually allocate the volume – too hard and too expensive to scale humans.
Memory-intensive architectures, to include DRAM and flash-based systems, will gain prominence. Flash-first hybrid systems will dominate the high end and midrange, ultimately becoming cheaper than traditional disk arrays. This doesn’t mean you should go rip and replace your existing array assets. What it does mean however, when it’s time for a refresh, don’t just blindly buy the next generation offered – take a look around and see how the incumbent’s latest and greatest compares with memory storage.


