
I spent most of the week at the NVIDIA GPU Technology Conference (GTC) in San Jose with 30,000-plus attendees. The highlight of the event is Founder Jensen Huang’s Monday address, and as usual, this year’s keynote lived up to the hype. The talk was packed with history, vision, and innovation. Jenson underscored a significant transition in the AI market: the conversation is no longer just about faster chips or larger models. It is increasingly about building full-stack AI factories that generate, manage, and monetize tokens at scale (Tokenomics). Throughout the keynote, Jensen Huang positioned NVIDIA not simply as a silicon supplier but as a vertically integrated, horizontally open computing platform company spanning accelerated computing, software, data processing, inference, agentic AI, digital twins, and robotics.
From an enterprise perspective, the message was clear. The next phase of AI adoption will depend less on isolated model experimentation and more on the ability to operationalize intelligence efficiently, securely, and repeatedly across business functions. That requires infrastructure, software, data pipelines, and ecosystems that work together as a system.
From accelerated computing to AI factories
One of the clearest themes from the keynote was NVIDIA’s framing of the data center as an “AI factory.” This is more than branding. It reflects a meaningful change in how enterprises and service providers should think about AI investments.
Historically, data centers stored files, hosted applications, and supported transactional systems. In the AI era, Huang argued that these environments are evolving into token-generation platforms, where throughput, latency, and power efficiency become the primary measures of value. In practical terms, that means infrastructure is increasingly judged by how effectively it can convert power and compute into useful AI output.
At the center of NVIDIA’s announcements is the Vera Rubin platform, a next-generation AI infrastructure system that integrates CPUs, GPUs, LPUs, networking, storage, and specialized inference accelerators into a unified architecture.
The platform combines:
- Vera CPU (AI-optimized for agentic workloads)
- Rubin GPU (high-performance compute for training and inference)
- Grok LPU for ultra-low latency token generation
- NVLink and Spectrum X networking
- Spectrum Ethernet
- BlueField DPUs for data movement and security
- BlueField-4 STX AI native storage accelerators

This represents a continued evolution toward rack-scale and system-level design, where performance gains come not just from faster chips, but from how all components work together. NVIDIA refers to this as “Extreme Co-design” and the company is deeply invested in this principle.
This framing matters because it ties technical architecture directly to business outcomes. If AI becomes embedded in software development, customer service, search, operations, analytics, and industrial automation, then token production is no longer an abstract metric. It becomes a proxy for productivity, responsiveness, and revenue generation.
For enterprises, the implication is straightforward: AI infrastructure decisions must now be evaluated in the context of long-term utilization, workload diversity, and operational economics. Raw performance still matters, but performance without efficiency or software optimization is less compelling.
CUDA’s enduring role in enterprise AI
The keynote also served as a reminder that NVIDIA’s current position is rooted in a long-term software strategy, not just hardware leadership. Huang repeatedly returned to CUDA as the core of the company’s flywheel: a large installed base attracts developers, developers create new algorithms and applications, and those applications further expand the installed base.
That is particularly relevant for enterprise buyers. AI infrastructure is not valuable simply because it is powerful on day one. It is valuable if it continues to improve over time through software updates, library enhancements, and broader ecosystem support. NVIDIA’s argument is that its architectural compatibility, extensive library portfolio, and broad deployment footprint extend the useful life of its systems and lower total cost over time.
This is a critical point in the broader market. Enterprises are moving beyond pilots and into production AI, where infrastructure longevity and software portability become essential. The more an organization can reuse infrastructure across training, inference, analytics, simulation, and domain-specific workloads, the stronger the business case becomes.
Data acceleration becomes central to AI outcomes
Another important takeaway was the elevation of structured and unstructured data processing as first-order AI priorities. Huang described structured data as the “ground truth of business” and positioned accelerated frameworks for data frames and vector stores as foundational to enterprise AI. To deliver on this, they announced the BlueField-4 STX AI storage architecture, which is intended to support AI-native storage and better manage the context memory and key-value cache requirements of agentic workflows and large language models.
This may sound like a supporting detail, but it addresses a real challenge. AI performance depends not only on processors, but also on how quickly systems can access, retrieve, and maintain context. As models process larger context windows and agents maintain state over more steps, traditional storage architectures can become bottlenecks that limit responsiveness and utilization.
For enterprises, this means storage and data-path design are becoming increasingly important parts of AI architecture. AI success will depend not only on model choice and GPU availability, but on whether the surrounding data infrastructure can keep up with the demands of real-time, context-rich workloads
That is an important shift. For the last two years, most market attention has focused on foundation models and GPU availability. But in practice, enterprise AI outcomes depend heavily on data access, preparation, retrieval, and context. If agents and reasoning systems are going to interact with enterprise systems in real time, then the surrounding data infrastructure must also be accelerated.
The examples cited across IBM, Dell, Google Cloud, and others reinforce this point. Faster SQL processing, lower-cost analytics, and improved handling of semantic data are not peripheral benefits. They are increasingly core to how enterprises scale AI responsibly and cost-effectively.
In that sense, NVIDIA is expanding its relevance beyond model execution and into the broader enterprise data stack. That has strategic implications for partners, cloud providers, and software vendors, especially as structured data, vector data, and inference pipelines converge.
Inference is becoming the main event
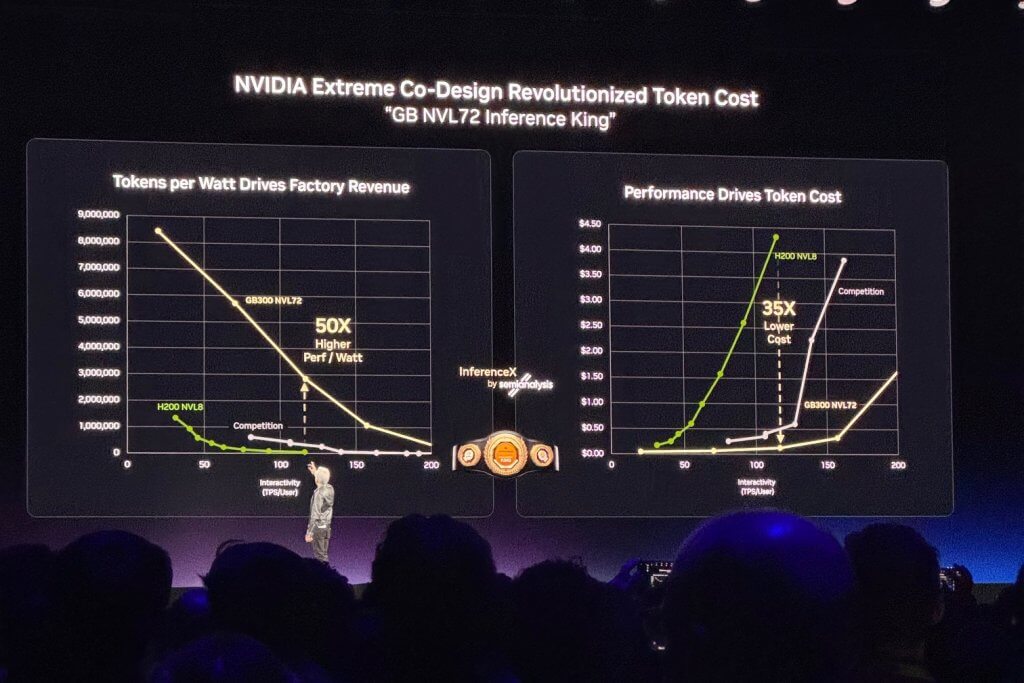
If there was a central strategic message in the keynote, it was that inference has become the dominant force shaping demand for AI infrastructure. Huang argued that reasoning models, agentic systems, and tool-using AI dramatically increase compute requirements, pushing the market beyond training-centric economics.
That aligns with what many enterprises are beginning to see. Training remains important, but the value of production AI is increasingly realized during inference, when models answer questions, generate content, reason through tasks, access enterprise data, and take action. As AI moves into everyday workflows, the volume and complexity of inference rise significantly.
This matters because inference is where technical decisions most directly affect user experience and business value. Faster token generation improves responsiveness. Better efficiency lowers cost. Higher throughput enables broader deployment. Lower latency supports more sophisticated reasoning and agentic behaviors.
NVIDIA used this argument to justify both its new system architectures and its emphasis on software-hardware co-design. Whether enterprises accept all of the performance claims at face value or not, the broader takeaway is sound: inference optimization is becoming one of the most important battlegrounds in enterprise AI.
A key announcement in this space was NVIDIA’s AI grid, built around integrations with Nokia and T-Mobile, which is particularly relevant to telecom providers. NVIDIA’s message is that wireless infrastructure is evolving from a connectivity platform into a distributed AI execution environment that supports deterministic, low-latency applications at the network edge.
For telcos, this matters because it expands the strategic role of the network. Rather than serving only as transport for cloud applications and wide-area network traffic, the network edge can become a location where AI services are executed in real time. That creates opportunities to support use cases such as video analytics, public safety, infrastructure monitoring, and other applications that require predictable performance and local processing.
This opens a path for service providers to move further up the value stack. AI-capable edge infrastructure can help telcos create new managed services, differentiate enterprise offerings, and better monetize their network footprint. As demand for distributed AI services grows, operators that can pair connectivity with local AI execution may be better positioned to capture that opportunity.
Agentic AI shifts enterprise software expectations
The keynote also introduced a broader vision for agentic AI, anchored by a discussion of OpenClaw and NVIDIA’s related enterprise framework NemoClaw and OpenShell. Huang characterized this as a major platform shift, comparable in significance to Linux, HTML, or Kubernetes.
That analogy may be ambitious, but it reflects a real trend. Enterprise software is moving from systems of record and human-operated tools toward systems that can reason, act, orchestrate workflows, and interact with other tools autonomously. This has implications not only for application design, but also for governance, security, and infrastructure.
The most practical insight here is that agentic AI cannot be deployed as a simple extension of consumer AI tools. In enterprise environments, agents must operate within guardrails. They may access sensitive data, execute code, or interact with external systems. That means policy enforcement, privacy controls, and secure orchestration are not optional features; they are prerequisites.
For software vendors, Huang’s point that SaaS companies may increasingly become “agentic-as-a-service” providers is worth watching. Even if that evolution happens unevenly, the direction is credible. Customers will increasingly expect enterprise applications not just to present information, but to help complete work.
Physical AI broadens the opportunity set
Beyond digital agents, NVIDIA devoted substantial attention to robotics, autonomous vehicles, and simulation. This extends the AI factory concept into the physical world, where synthetic data, simulation, world models, and embedded compute all play essential roles.
For enterprises in manufacturing, automotive, logistics, retail, and telecommunications, this is an important signal. Physical AI is no longer just a research topic. It is becoming part of mainstream infrastructure planning, especially where labor constraints, safety requirements, and real-time decision-making intersect.
What stands out here is NVIDIA’s attempt to unify digital and physical AI on a single platform. The same company that accelerates data processing and inference in the data center also wants to provide the simulation, training, and runtime stack for robots and autonomous systems. That broadens NVIDIA’s addressable market considerably, but it also reflects a larger industry truth: AI’s long-term opportunity extends well beyond chatbots and copilots.
Final thoughts
This GTC keynote was not just a product showcase. It was a strategic narrative about the next phase of the AI market. NVIDIA is betting that enterprises, cloud providers, and software companies are moving toward a world where intelligence becomes an operational resource produced by AI factories, consumed by agents, engineers, and developers, and extended into physical systems.
For business and technology leaders, the most important takeaway is not any single chip, rack, or benchmark. It is the recognition that AI is becoming a systems problem. Success will depend on how well organizations align infrastructure, data, software, security, and operational models to support intelligence at scale. Business leaders are encouraged to become well-versed in “Tokenomics” and the key metrics to track for their business.
That is a much bigger challenge than deploying a model. But it is also where the most durable value is likely to be created.


