Here at theCUBE Research, we are committed to informing you about the latest developments shaping AI’s future. We will help you stay updated on emerging technologies, use cases, vendors, and real-world ROI. Additionally, we will provide recommendations on how you can prepare and stay one step ahead.
We believe that the combination of agentic AI, causal reasoning, and SLMs (with “S” representing attributes like small, specialized, sovereign, and secure) will shape the future of AI. In this next frontier, autonomous agents will assist us in problem-solving, decision-making, and even acting on our behalf.
In this research note, we will explore OpenAI’s new “reasoning” capabilities delivered in the first of a series of ChatGPT Strawberry models (o1). We will start by considering today’s language models (LLM) limits, how OpenAI has helped us move toward more capable models, and where it’s all heading from here. And, of course, what you should know to prepare for the future of AI agent systems that can actually reason and problem-solve.

Today’s AI Capabilities
Let’s start with some context on where we have been, where we are now, and where we are heading on the journey to AI reasoning.
The decades-long methodology of structured programming has entered a phase of diminishing returns. Humans are algorithmic by nature. We sequence through steps to accomplish things. The advent of computers allowed us to program common, repeatable steps to become more productive. We then interconnected them, infused interactive experiences, enabled anywhere access, and instrumented real-time data. The ROI from this approach has been transformative, to say the least.
These algorithms were mostly PRE-programmed and couldn’t RE-program themselves to improve outcomes. Because they rely on human intervention, making changes is costly and time-consuming. This creates inherent limitations, rendering them powerless to solve future problems, especially in today’s highly complex, dynamic digital world. In fact, it’s estimated that the average ROI impact of structured programming is now 65-70% lower than just a decade ago.
AI is changing this, powered by LLMs. It’s revolutionizing how we program. AI algorithms can now process massive amounts of data, learn new sequences of steps, and continuously improve themselves. This approach harnesses its predictive capabilities by analyzing correlations between variables in a dataset to understand how one variable changes in relation to others. It can derive specific observations from general information or infer general observations from specific information. Essentially, today’s AI can generate predictions, forecasts, and content based on certain conditions.
Its promise of value is being acknowledged: new Enterprise Technology Research (ETR) survey data demonstrates the enterprise’s rapid adoption of machine learning/artificial intelligence (ML/AI) technologies. Among the 1551 surveyed accounts, ML/AI represents the strongest spending trajectory across all technology categories.
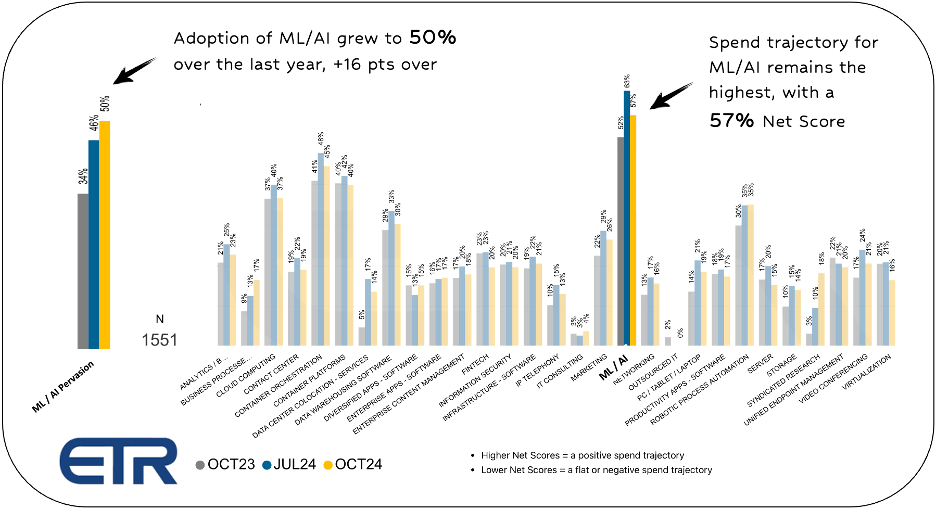
Yet, despite the rapid adoption and innovation of the last many years, AI is only in its infancy stage. While today’s generative LLMs are highly impressive, they are still constrained by the limitations of their correlative designs. They swim in massive lakes of existing data to identify associations, relationships, and anomalies that are then used to predict, forecast, or generate outcomes based on prompts.
They operate based on brute force: the ability to process immense amounts of data through numerous layers of parameters and transformations. This involves decoding complex sequences to determine the next token until it reaches a final outcome. This is why you often see the words “billions” and “trillions” associated with the number of tokens and parameters in Large Language Models (LLMs).
However, their abilities are based on analyzing statistical probabilities, which represent our knowledge of a STATIC world. In order for AI to “reason,” it needs to comprehend causality, which explains how these statistical probabilities shift in a DYNAMIC world with different circumstances, influences, and actions. Enhancing the algorithmic connection between probability and causality is crucial for enabling AI to assist humans in reasoning, problem-solving, making better decisions, and influencing future results.

The end result of a predictive or generative LLM model, no matter how advanced it may be, is only to establish a connection between a behavior or event and an outcome. However, it is important to note that establishing a connection does not necessarily mean that the behavior or event directly caused the outcome. Correlation and causation are not the same – there can be correlation without causation. In addition, while causation implies correlation, its influence can be so minor that it is irrelevant compared to other causal influences. Treating them as equivalent can lead to biased outcomes and false conclusions, undermining the fundamental principle of reasoning, which involves understanding cause and effect and why events occur.
So, how can we begin bridging the gap between the AI worlds of correlative designs and algorithmic reasoning? OpenAI’s new “reasoning” techniques take baby steps on the long-term path to AI systems that can truly reason and thus problem-solve.

OpenAI’s Step Forward
OpenAI’s ChatGPT o1 brings improvements that move us closer to AI “reasoning” by better handling complex tasks and reducing hallucination rates. We’ve put “reasoning” in quotes because ChatGPT o1 still lacks the ability to truly mimic human reasoning, which involves understanding cause and effect. More on that later.
The recent development by OpenAI, however, does represent a significant advancement. Their new architecture introduces a crucial element to the process of creating models capable of reasoning. This is achieved by dedicating more time to carefully analyzing a prompt, breaking it down into a sequence of logical steps, and then rendering a verdict. This often involves backtracking to consider different possibilities, alternate strategies, and past learnings. It also delivers enhanced contextual comprehension, greater originality, and better handling of ambiguity.
The progress in these areas will have significant implications for developing future-state LLMs, SLMs, and agentic AI systems. Increasing levels of “reasoning” capabilities will enable various new high-ROI use cases that were previously not feasible.
OpenAI o1 can now solve complex problems in science, math, and programming domains. This ability can also be utilized in other areas where multi-step reasoning and a large amount of contextual information are required, such as solving crossword puzzles, deciphering written logic, and even developing strategies for case law.
Consider a simple example: Many current LLMs struggle with basic questions because they don’t understand what you are asking or what you want to achieve. In the example below, it made a guess based on its training, possibly associating a long string of characters as a security key. The point is nobody knows how or why it thinks it’s a 20-character string. But note how the new o1 model got it right and provided a summary of its reasoning, allowing the user to gain insight into how it solved the problem.

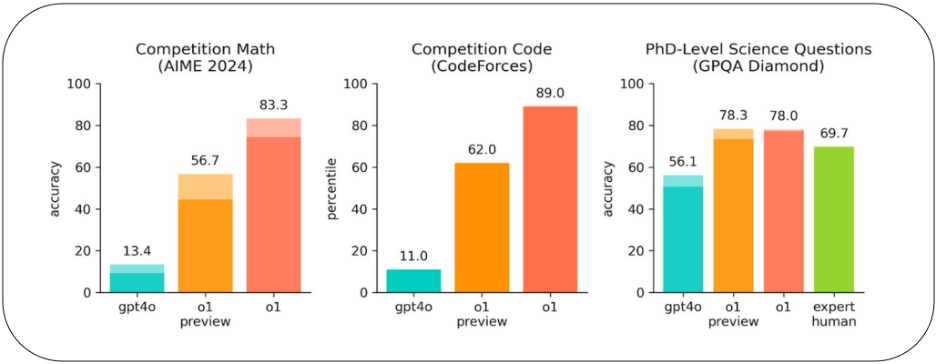
The good news is that LLMs are now capable of becoming even smarter. The OpenAI o1 benchmarks are highly impressive. As shown below, o1 significantly improved ChatGPT’s score in the American Invitational Mathematics Exam, the Codeforces Programming Competition, and the GPQA Diamond proficiency test. The benchmarks also demonstrated reduced hallucination rates from 0.61 to 0.44, resulting in higher quality and more reliable outcomes.
So, how did OpenAI accomplish these results? They achieved it using a new machine learning technique called Chain-of-Thought (CoT).
CoT enables models to process complex prompts in a way that is similar to how humans solve problems by breaking down a problem into a series of step-by-step tasks. It also imitates how humans “think aloud,” pausing at times to reconsider each step and sometimes modifying and revising previous steps as we gain a better understanding of the overall problem. Its ability to assess steps before, during, and after is truly impressive.
CoT reasons autonomously, continuously refining its strategies through advanced reinforcement learning methods. These methods identify and correct mistakes without human guidance. Human feedback further fine-tunes the model’s “reasoning” using Reinforcement Learning Human Feedback (RLHF) reward methods. Unlike traditional RLHF methods, CoT’s granular steps (CoT Tokens) representing intermediate reasoning steps are also incorporated into the reward model, not just the prompt and response. This allows the model to continuously improve its skills and thought process as it gains real-world problem-solving experience over time.
The new capabilities allow for a more thoughtful and nuanced approach compared to the brute-force process of statistical correlation used by most LLMs today. Current LLMs generate sequences of “next likely tokens” without understanding the problems they’re trying to solve. However, an LLM with COT will spend more time in the inference stage to break down problems into logical steps and reason about how to best solve them. The illustrations below visualize the increased time spent on inferential thinking about the problems compared to traditional LLMs.
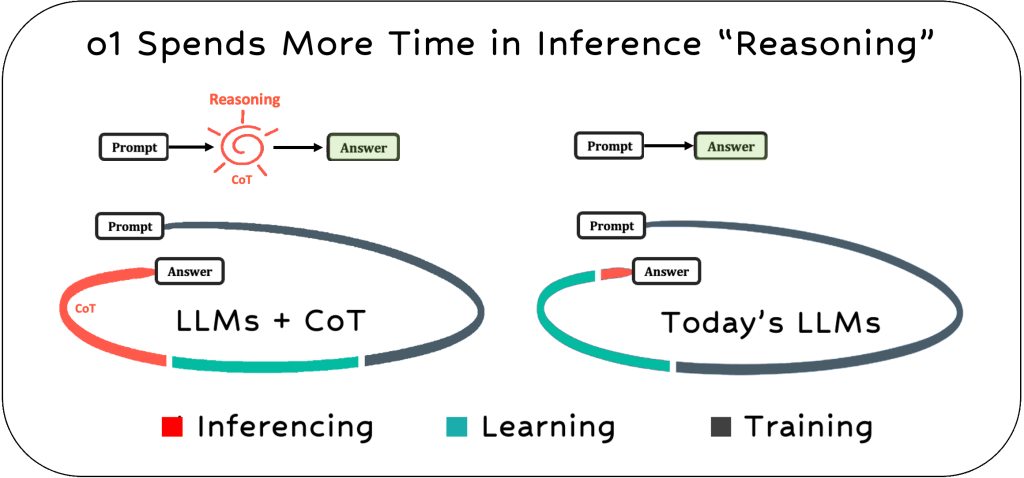
During the extended inference time, the model is trained to begin by generating the CoT tokens needed to solve the problem. After that, it follows the earlier process to think through and produce the final response. In other words, it dedicates more time to “reasoning” and double-checking accuracy than traditional LLMs. However, this has some limitations, especially in the near term.
The CoT model has thirty times longer response times than previous models. Additionally, it is three times more expensive for input tokens and four times more expensive for output tokens ($15 per million input and $60 per million output). The model also lacks transparency in its reasoning process, as the CoT Tokens are hidden from the user, and the responses lack detailed explanations. So, while o1 now achieves the highest quality, it also comes with the highest cost and slowest response times, as the ArtificialAnalysis reports. Do note that the o1-mini improves speed and cost while retaining quality.

Nevertheless, there is no doubt that CoT represents an important advancement that will continue to mature over time and become a key ingredient in the AI reasoning cookbook. It’s also important to recognize that OpenAI is not alone in this endeavor, as others are also developing similar reasoning architectures. For example, Google DeepMind and Stanford University are working on their Self-taught Reasoner (STaR) method, which is similar to CoT as it also aims to infuse “reasoning” capabilities into AI models through a process of self-supervised learning.
The key point is that these AI advancements in reasoning are just that – advancements. Amid all the excitement about OpenAI’s new CoT methods and related methods like STaR, it’s important to note that they lack some crucial ingredients for mimicking human reasoning – notably causality and the science of why things happen.

The Missing Ingredient
Understanding causality and the science of how and why things happen is the missing ingredient in CoT, and STaR, for that matter, as stated by OpenAI’s new o1 model.

Causality, however, is crucial for enabling AI systems to truly assist humans in reasoning, problem-solving, strategizing, and making optimal decisions. Probabilities help us comprehend a static world, while causality helps us understand how probabilities change in a dynamic world. Current LLMs, including those using CoTand/or STaR, primarily rely on statistical correlations and thus lack the most important ingredient in mimicking human reasoning – understanding the impact of actions and how to problem-solve. And often confuse correlation with causation, which can be fatal in the business world.

This is where the AI causality and the science of why things happen come into play. It’s an umbrella term for an emerging branch of machine learning that can algorithmically understand cause-and-effect relationships in both problem sets and datasets by quantitatively identifying how various factors influence each other. These capabilities are made possible by a growing toolkit of new AI methods, which are being integrated and productized by an increasing number of vendors. Importantly, these products are designed to complement today’s LLMs and generative AI tools, rather than replace them.
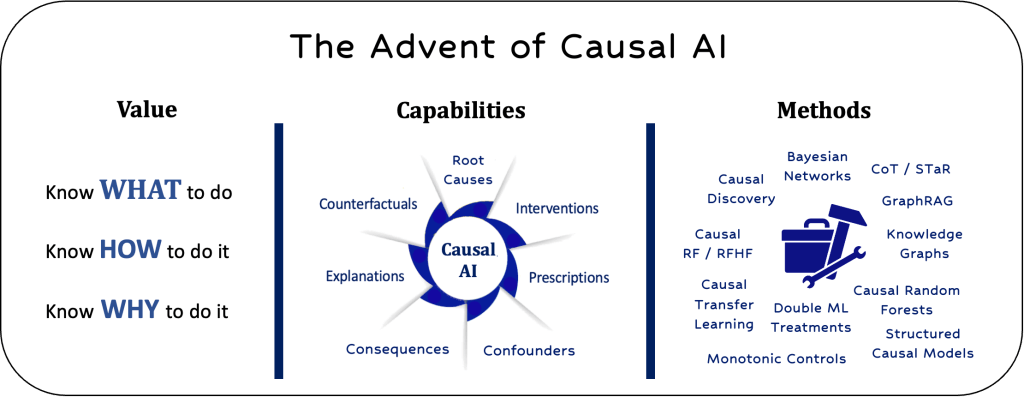
In upcoming research notes, we will discuss our belief that Causal AI is necessary and inevitable for the abovementioned reasons. For example, the 2024 Gartner AI Hype Cycle predicts that Causal AI will become a “high-impact” AI technology within the next few years. Additionally, spending on AI causality is expected to grow at a 41% CAGR through 2030, nearly twice the growth rate of traditional AI. These projections are supported by a recent DataIku / Databricks survey of 400 data scientists, which found that causal AI was ranked as the top new AI technology respondents plan to adopt next year.
As these technologies and best practices mature, they will empower businesses to do more than make predictions, generate content, identify patterns, and isolate anomalies. It will also allow them to simulate numerous scenarios to understand the outcomes of different actions, explain the causal factors driving their business, and solve problems analytically. This will help businesses better understand what to do, how to do it, and why certain actions are better than others.

The Future of Agentic AI
As the future unfolds, we anticipate the emergence of Agentic AI platforms that orchestrate armies of potentially hundreds of collaborating AI agents to help enterprises:
- More fully integrate and automate processes
- Re-imagine digital experiences and workflows
- Identify and address emergent trends
- Solve challenging problems quickly and efficiently
We believe that Agentic AI platforms need to be able to understand and carry out tasks autonomously, especially in fast-paced and dynamic business environments. This can be achieved through microservice architectures incorporating correlative and causal-based AI reasoning methods using a network of LLMs and domain-optimized SLMs. The goal is to create agents that can collaborate, assess the impact of different actions, and fully explain their decisions and reasoning. Most importantly, they should engage with humans to gain domain-specific knowledge and tacit know-how to help achieve desired outcomes.
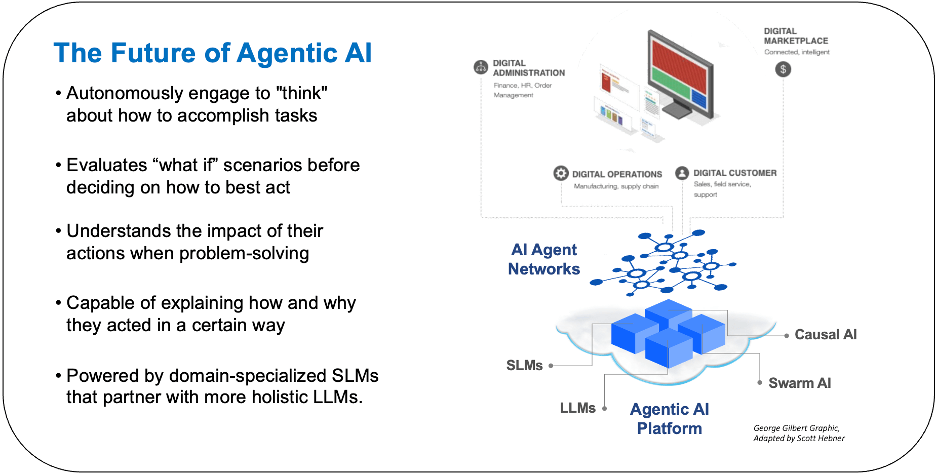
In terms of enabling AI reasoning in Agentic AI platforms, the integration of Chain-of-Thought (CoT) and Causal AI techniques promises to create a powerful system combining the strengths of both approaches: self-supervised iterative learning and the principled understanding of cause-and-effect relationships. Integrating causal knowledge into the model’s reasoning sequence can help it better understand which reasoning paths are most likely to produce the correct answer by ensuring alignment with known causal mechanisms in a problem set. This would help the model avoid common pitfalls, such as confusing correlation with causation. Finally, the integration promises to deliver a new class of AI use cases that rely on counterfactual reasoning and evaluating hypothetical problems.

What to Do and When
With the commercialization of OpenAI’s chain-of-thought technology (CoT) and the emergence of new Causal AI tools and platforms, we may find that the journey to AI reasoning is closer than we think. Perhaps the time is now to start preparing for this new frontier in AI. As we have witnessed in past technological evolutions, some will lead, some will lag, and some will eventually fail. It’s never too early to start the evaluation process.
We’d recommend you:
- Experience OpenAI’s new o1 model
- Build a competency in Causal AI
- Evaluate potential new use cases
- Develop a future-state Agentic AI strategy
- Let us know if we can help you
Stay tuned for a series of future research notes that build upon the topics covered in this note, including deeper dives into causal AI technologies, use cases, and vendors.
Thanks for reading. Feedback is always appreciated.