
Premise
We believe GTC ’26 marked another step-change in the industrialization of AI. Nvidia is moving well beyond “faster GPUs” toward a full-stack AI factory model designed to lower the cost of tokens and expand what customers can build and monetize. We sat down at GTC with Charlie Boyle, VP of DGX at NVIDIA, who tied nearly every major announcement back to a laser-like focus on more tokens at lower cost, delivered through a rack-scale architecture that integrates compute, networking, storage, and power controls.
Nvidia’s thesis is straightforward but incredibly complicated to execute. Specifically, lower token cost – and in particular lower cost/watt due to a fixed power envelope – expands the market. Nvidia has gone from chip builder to building full AI factories at unprecedented scale.
Vera Rubin as the flagship: cost per token per watt becomes the optimized metric
We asked Charlie Boyle for his biggest GTC takeaway. His response was Vera Rubin, the new racks, and the “AI factory” concept work together to “dramatically lower the cost of delivering tokens.” The argument is that lower cost tokens are both an engineering target and the throughput of a new business model (as described in the concluding segment of last week’s Breaking Analysis). More tokens create more business opportunities, and new classes of applications become feasible when token economics improve.
There’s also an important second-order point embedded in that narrative in that lowering token cost not only helps manage a fixed power envelope, it also unlocks new revenue streams that weren’t practical before. In Boyle’s words, the new platform makes it possible to deliver “brand new sources of revenue that were never possible before.”
Jensen stressed that “every CEO in the world needs to understand where they are on the Pareto” (see graphic at the end of this note). Selling throughput to train models (vertical axis) or creating superb user experiences through low latency and excellent interactivity (horizontal axis) – or both dimensions.
Bottom line
Rubin is positioned as an economics engine. Nvidia is explicitly selling token production as the new unit of competitive advantage, cost reduction and revenue generation.
The annual cadence: extreme co-design plus software compatibility
Boyle reinforced the idea that Nvidia’s cadence is not a one-off gimmick. It’s purposeful, repeatable, and anchored in a software layer that is backward compatible. He called out the “35x faster than Grace Blackwell” claim for Vera Rubin, and referenced the prior year’s skepticism when Jensen put “35x” on a slide and independent tests later showed “50x” (i.e. Dylan Patel’s sandbagging comment).
Two themes stand out from Boyle’s commentary:
- Extreme co-design is Nvidia’s operating model. This is a hardware and software engineering feat, not transistor density math. The throughput gains come from building the platform as a system and optimizing all aspects – compute, storage, networking, optics, software, libraries, algorithms, etc.
- Compatibility is the flywheel and Nvidia’s competitive advantage. Boyle emphasized CUDA’s 20-year arc and DGX’s 10-year lifespan – i.e. software that ran on the DGX-1 in 2016 runs on Rubin today. That continuity and the ever-growing installed base is what makes a 12-month cadence attractive to customers developers. Customers don’t rewrite everything; they “intersect what system you have in that generation” and the platform gets faster while the software stays intact.
Bottom line
The one-year cadence is feasible because Nvidia’s software foundation reduces adoption friction. Compatibility makes the investment feasible.
OpenClaw: “ideas to prototype” becomes a new productivity loop
Boyle’s excitement around OpenClaw matched that of Jensen’s and others on his staff. It was about compressing the distance between an idea and a working product – e.g. business workflow.
He described a familiar enterprise situation in that business leaders have ideas for apps and workflows but hesitate to interrupt developers because it “takes a while.” OpenClaw changes that initial barrier. For example, someone can ask for something, see it quickly, and then, if it works, developers step in to harden it, optimize it, and scale it.
Boyle’s point is that OpenClaw does not eliminate developers. It changes the front end of innovation. It moves ideation and prototyping closer to the business user and turns development into an optimization and scale function once a workflow proves valuable.
Bottom line
OpenClaw accelerates experimentation and increases the “let’s try it” capacity and reduces risk of experimentation. At the same time, it brings new cybersecurity risks that are not fully understood. Developers will be the front line of defense for security and compliance, which is sometimes a tricky situation as they prefer to build and create, rather than secure code.
DGX to “day-one AI factory”: the partner ecosystem and time-to-market
Boyle used the DGX history to show how Nvidia turned a “reference design” into an ecosystem advantage.
He recalled the DGX-1 debut at this same San Jose convention center, behind velvet ropes, with the number one question: “What could I possibly need eight GPUs for?” The headline story is the industry has moved so far that this question now feels trite – and it signals how quickly demand has scaled.
The more relevant point is Nvidia’s go-to-market model has matured. Boyle described building a vertically integrated stack, making it usable, and then sharing it as a reference design so partners can scale. He contrasted the early timeframe – partners taking a year or more—with today’s “same day” time-to-market where partners ship systems when Nvidia ships software. We saw this in obvious volume at GTC 2026
Bottom line
Nvidia’s advantage both technology and ecosystem alignment/speed. Reference designs have become trusted, although ever-changing supply lines.
Vertical integration with horizontal openness: why Nvidia builds internally first
Boyle gave an explanation of what “vertical integration” actually looks like operationally. Nvidia invests billions to build internal clusters so engineers can “beat on that,” develop software, and test at scale with networking, fabric, and storage. The company’s claim is that when the first production rack ships – whether directly or via partners – Nvidia already knows the design works because they’ve run it themselves.
This is perhaps one of the most underappreciated parts of Nvidia’s stragegy. Specifically, “AI factory in three weeks” a recipe and a repeatable process that’s been validated internally. Jensen said at scale they’ll be pumping out 200 AI factories per week.
Bottom line
Nvidia’s internal build-first discipline reduces customer risk and compresses deployment timelines. This is how “factory” becomes real. It also represents an enormously complex engineering feat.
Mellanox and the fabric advantage: the best networking is the networking you don’t notice
Boyle called fabric “so important” and pointed out something many may miss – i.e. DGX shipped with Mellanox cards long before Mellanox was acquired. The fabric was critical early even when “nobody was clustering anything.” As clustering arrived (SuperPOD era), fabric became foundational because the goal is any application and any resource can reach anything else in the AI factory.
Our key observation in this regard is that most developers benefit from high-performance fabric without seeing it. CUDA, NCCL, and Nvidia’s software stack optimize the fabric and keep it out of the developer’s way. Boyle also highlighted Spectrum-X as the next step for scaling Ethernet-based AI factories.
Bottom line
Networking is part of the invisible machinery. Nvidia’s best move with fabric was making it disappear into the software stack.
Agentic infrastructure: more agents means more data, even more agents and isolation requirements
Boyle’s “building a house” analogy maps to agentic technical realities. In other words, a “general contractor agent” spawns specialty agents. The infrastructure implication is that thousands of agents require access to memory, storage, and secure sandboxes – at the same time, in the same AI factory.
He underscored a new dynamic in that agents create, store, monitor, and destroy data at machine speed. That changes the storage and data path requirements and raises the stakes on isolation and policy: “my agent is running securely, your agent is running securely,” and data separation is in place unless explicitly shared.
Bottom line
Agentic systems push the bottlenecks down-stack into data paths, IO, isolation, and lifecycle management controls. This allows the AI factory becomes a multi-tenant machine, which has major economic advantages.
Storage as a performance layer: STX and “processing moves closer to the physical data”
Boyle cited Nvidia’s storage work as enabling the ecosystem rather than “selling storage.” He described STX as a reference architecture built for what agents need from storage, anchored by a stack that includes BlueField-4, ConnectX-9, and Vera in the storage rack itself.
The key idea is to move processing closer to physical data so agentic workflows can run faster and more securely. Boyle emphasized why storage partners are “all in” because they can put their software stacks on a new reference architecture without funding the R&D themselves, then pursue new business opportunities tied to agentic workflows.
While true, the fact is Nvidia has completely reset the agenda for storage ecosystem partners. Our view is that every data storage supplier must respond and align to NVidia’s reference architecture or risk being left at the station as the AI train speeds away. Moreover, NVidia is redefining the storage hierarchy with multiple memory tiers, pushing what used to be viewed as “tier 1” primary storage further down the value chain. As such we believe this necessitates strategies that are value-oriented where STX exploitation is table stakes. Data proficiency (harmonization, semantics, sharing, security, etc.) become value added services that can drive monetization.
Boyle also highlighted a practical enterprise hook – i.e. permissions and access controls are already encoded in storage systems. If those can be built into agentic workflows, developers don’t have to re-litigate permissions that IT has already managed for years.
Bottom line
Nvidia is turning storage into an AI performance and governance layer. Forcing storage partners to move quickly to preserve monetization and find white space to add value. Nvidia sets the architecture, storage partners battle it out to differentiate.
Power becomes the gating constraint: DSX, Max-Q, and “use every watt you pay for”
Boyle’s most pointed operational claim was about power utilization. He argued that in a gigascale AI factory, the old data center approach wastes enormous amounts of power. If a customer provisions 1 GW, they may only be using ~600 MW on average – a roughly 60% utilization.
Nvidia’s response is DSX design plus chip-to-software controls that let customers set a power limit and operate within it while maximizing token output. Boyle described it as eliminating “humans and phone calls to turn knobs,” replacing that with automated controls that keep utilization high “but doing it safely.”
Max-Q was described as a practical mechanism to run GPUs slightly slower for most workloads, allowing 30–40% more GPUs in the same power envelope, because real workloads don’t sit at peak power all the time. The outcome is more work done per data center and better token economics.
In our view, the trick will be to educate grid companies and convince AI factory operators to allow their SLAs to be more flexible. In other words, structure the SLA to be more granular where mission critical workloads maintain the highest levels but “crapplications” get a dialed down service levels when power is constrained. The point is the grid is over-provisioned and could be run more efficiently by ditching the brute force approach and injecting more intelligence into the equation.
Bottom line
Power efficiency is a revenue lever. Nvidia is building controls that convert stranded power into tokens – assuming grid and AI cloud operators play ball.
The Pareto curve and tiered monetization: throughput plus responsiveness plus LPX
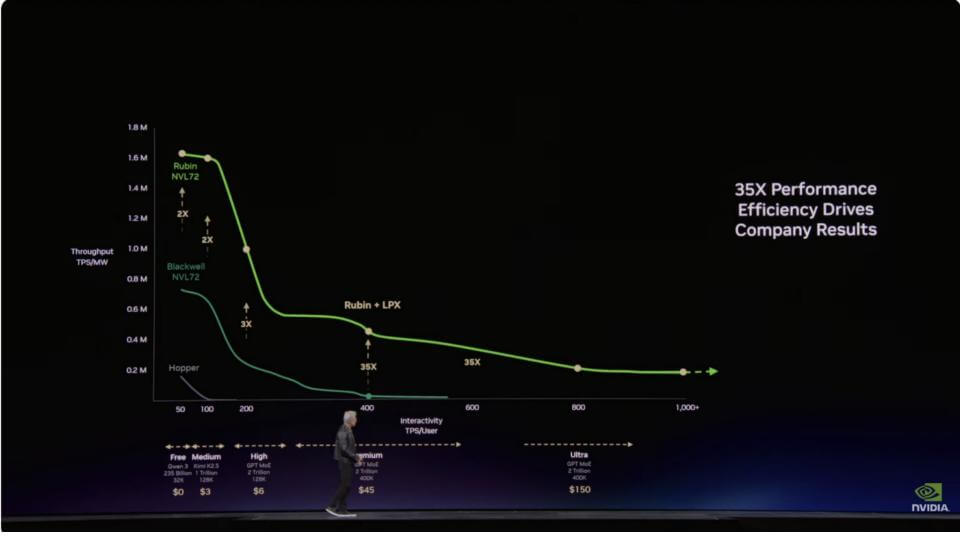
Boyle validated what Jensen has been signaling and what we described in the graphic above – I.e. there’s a new revenue dimension emerging around responsiveness and low-latency execution. He pointed directly to the LPX rack and Groq-derived technology as the enabler for that far-right end of the curve – high throughput with extremely low latency.
He described a tiered service logic inside the same AI factory: free-tier experiences on one end, and “I don’t care what it costs, I need it done” tasks on the other. Boyle’s examples were a quarter-end close, CEO-level problems, mission-critical shipping – work where latency and certainty have more value.
Bottom line
The inference era adds a monetization dimension. LPX is positioned as the mechanism for premium, low-latency value capture. We stress this is both a new business model that requires understanding the unit economics around token costs and the revenue side of the equation.
Conclusion | Our take: Nvidia’s flywheel is intact, but the “adoption gap” is the risk
We remain ultra bullish on Nvidia’s position. The discussion with Charlie Boyle reinforces our core thesis that Nvidia is both shipping faster GPUs and is industrializing the AI factory with a repeatable model that comprises compute, fabric, storage, and power controls – then scaling it through partners at unprecedented time-to-market.
The biggest risk is not “competition catches up” in our view. NVidia has no equal. The real risk is whether the industry can keep up with Nvidia’s pace across three fronts:
- Partner ecosystem readiness – reference architectures are only as good as the ability to manufacture, deploy, and support them at global scale.
- Supply chain elasticity – packaging, memory, power delivery, and factory throughput must match a 12-month platform cadence.
- Customer adoption – enterprise adoption moves slower than platform innovation. The data we track consistently shows pilots are everywhere and common, ROI at scale is still an elusive outcome, and governance/security/operating model changes remain a critical bottleneck.
In our opinion, Nvidia understands this risk and is actively trying to address it – by making the AI factory more turnkey, by validating designs internally before shipment, and by shifting complexity out of the customer’s critical path. That’s a strong play and unique in the industry. Still, the “agentic gap” remains a governor. The platform is sprinting. Customers are still in “spring training,” building the muscles to run it.
Bottom line
Nvidia’s strategy is straightforward, albeit extremely complex to execute: lower token costs, expand monetization, and make the AI factory deployable at scale. The limiting factor is not demand; its execution capacity across the ecosystem and enterprise absorption speed.


