
Premise. Big data technology remains user-unfriendly along multiple dimensions, including packaging. As the market gains experience with these technologies — and the problems they help solve — new approaches to simplifying packaging will emerge. Big data micro apps (BDMA) are an example.
Why Micro Apps Are The First Packaged Big Data Apps
While individual big data technologies are maturing rapidly, the market still hasn’t found the recipe for packaging these technologies into coherent software solutions. Why? Because so far big data applications (1) are low volume; (2) require heavy customization and (3) often need to integrate with complex systems of record (SoR) that run operations. Newer, mostly smaller vendors are trying to overcome these challenges by organizing big data technologies into highly focused “micro apps” that can reliably and repeatedly generate profitable businesses, even if on a smaller scale. Big data micro apps (BDMA):
- Target high value problems. Systems of record automate mostly low-value administrative business processes but integrate enough of them to create applications that provide relatively high aggregate value. Given the current state-of-the-art, it’s much harder to integrate many end-to-end big data tasks into big data applications with broad enterprise appeal. BDMA vendors target high-value, narrow-scope problems that support correspondingly high prices.
- Convert early adopter experience into repeatable software solutions. By targeting just one or a few high-value analytic tasks, BDMA vendors are starting to convert big data experience into repeatable software solutions. As a result, BDMAs can be sold nearly “as-is” — without significant customization — to a broader range of customers. While the numbers for BDMAs remain too small to attract big software players like SAP or Oracle, the BDMA market opportunity is large enough to attract VC and mid-sized software company investment.
- Shield brittle Systems of Record (SoR) from disruptive integration. The database systems that underlie SoR are crafted with exquisite care to support explicitly configured application processes. Changing either the databases or the processes typically is difficult and time consuming. Big data systems, in contrast, can be a maelstrom of redesigns and refinements. BDMA are capable of integrating the two disjointed domains by providing carefully scoped integration points. BDMA can inject just the final output of complex analytics like a predicted outcome directly into systems of record.
Narrow scope, but high-value solutions
Traditional enterprise applications automate end-to-end business processes in well-defined domains like finance and HR. Big data implementations, by contrast, anticipate and influence patterns of human interactions in complex, poorly-defined domains like customer engagement. For most of these interaction patterns, the data science isn’t understood to the degree required to construct repeatable models capable of handling variances by product category, industry, or other segment types. Consequently, it’s hard to integrate multitudes of interactions into broad packaged application suites that resemble traditional enterprise applications.
We have cracked the code on several interaction patterns that machine learning can represent — prediction scoring, anomaly detection, classification, and clustering — and these are the domains being addressed by BDMAs. Examples include high-value problems like detecting money laundering from bank transaction patterns; identifying fraud in a range of markets, from financial services to gaming; and anticipating customer churn.
Vertically integrated solutions in place of a customized, horizontal collection of tools
Traditional big data implementations build on a stack of tools from multiple vendors (see the left- hand graphic in Figure 1). At the bottom a database or data lake contains all information collected in a general purpose repository. A data preparation tool extracted a sample of the data in the database for manually exploring, cleaning, and integrating the relevant data. On top of that was a machine learning tool that extracted a smaller sample to build a predictive model. Then on top of that was a visualization tool that extracted a still smaller sample that presented the ultimate end user with actionable information. The challenge of building applications quickly with this approach was three-fold: (1) none of the tools were designed to work with each other; (2) vendor changes to individual products obsoleted costly customizations; and (3) even after integrating general purpose tools, doers had to build any programs or interfaces required to actually solve an analytic problem like “detect money laundering pattern.”
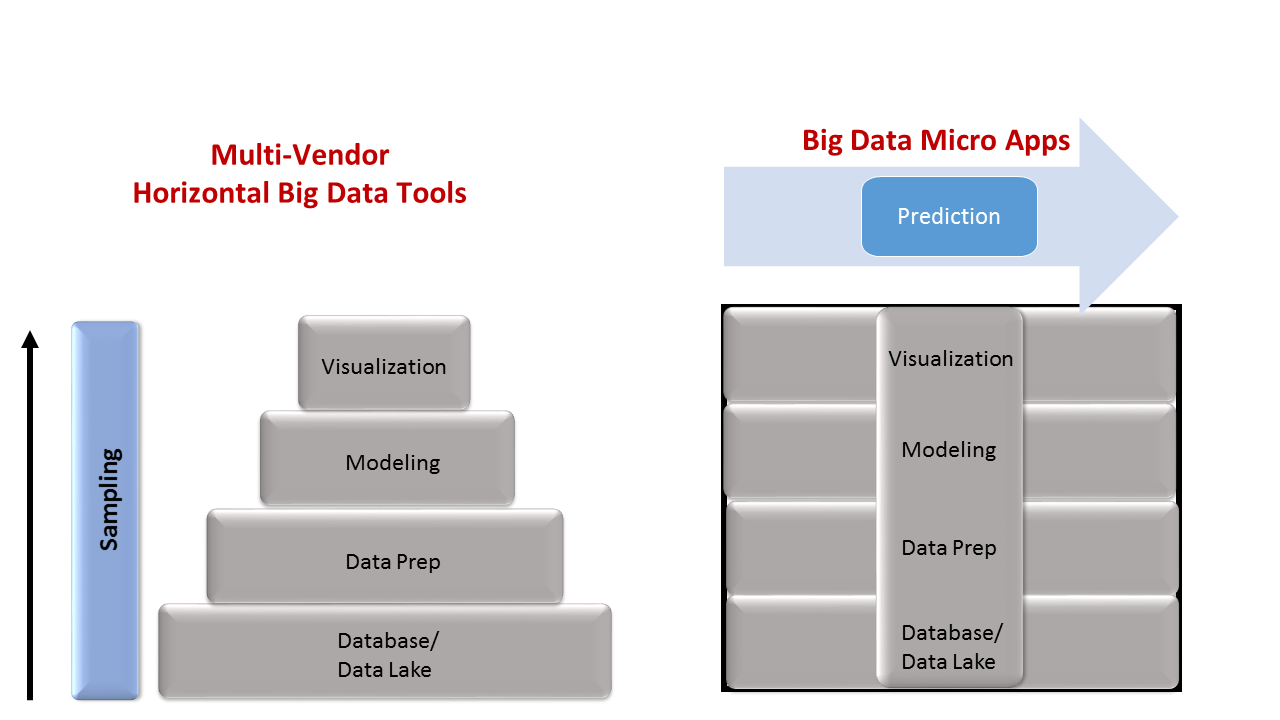
Tresata is one of a growing number of software vendors that are embracing the model of narrowly-scoped, high-value big data solutions and are applying the traditional software business model to take these big data solutions to market. Some traditional application and analytics vendors, including Oracle and SAS Institute have also built anti-money laundering applications, typically as part of a larger suite. Oracle’s, which has over 130 customers, builds on statistical models in the analysis language R within its Financial Services vertical apps. Tresata designed their micro application without the need for an entire suite of financial services solutions. Tresata has enough knowledge of the money laundering patterns to know where to look for problems (see the right-hand graphic in Figure 1). Moreover, it has compiled the right machine learning models to know how to look for those problems. Because it’s designed just around money laundering, Tresata’s BDMA can manage the end-to-end process of collecting, storing, processing, aggregating, and linking data, then picking the right algorithm and presenting the right visualization for the operator to take action.
Minimizing risk to legacy systems (the systems that actually do work)
When a customer places an order on the Web and then the application automatically tells a worker in a distribution center what to pick, pack, and ship, we are seeing end-to-end integration of operations at work. If big data apps want to operationalize their ability to anticipate and influence human interactions, they have to interface with SoR’s.
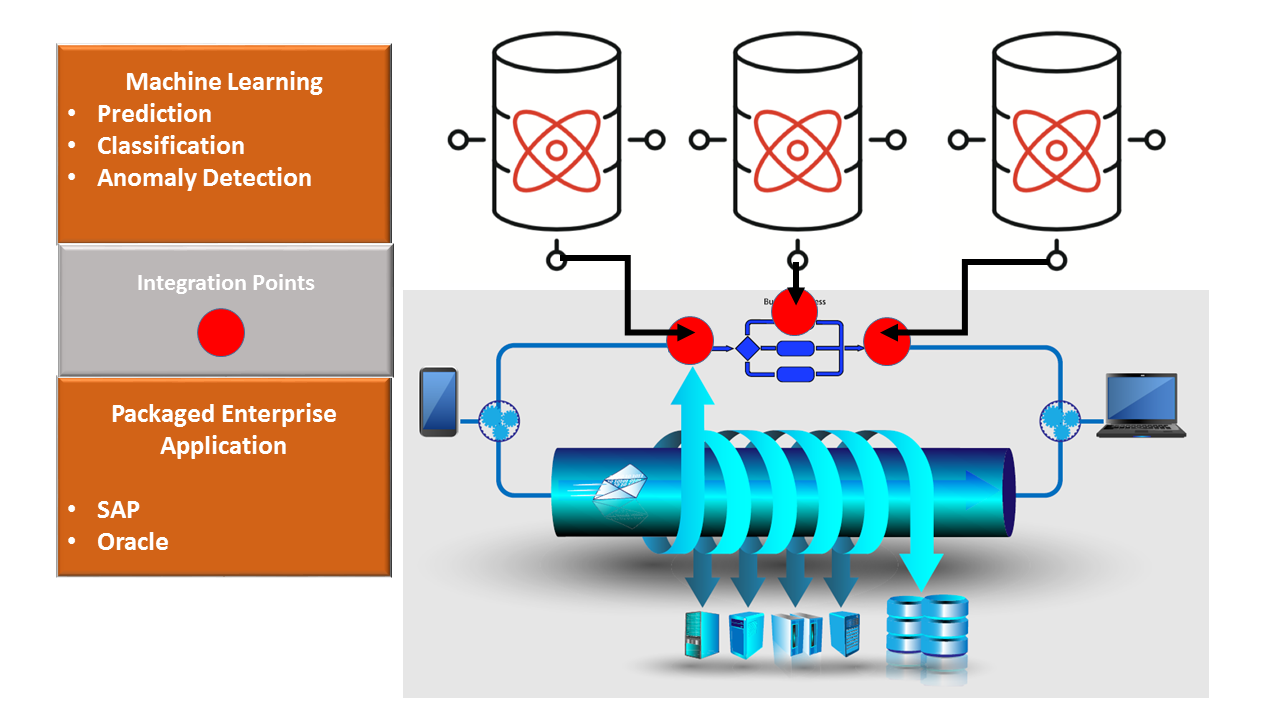
SoR’s are so broad and deeply integrated from the business processes all the way down through the database design that for all intents and purposes they are infrastructure. BDMA’s, by contrast, sit on data lakes with schema-less databases and constantly evolving data sets and algorithms. BDMA’s can coexist with SoR’s with minimal risk if their big data infrastructure is kept separate and they interface through one or a few carefully prescribed points of integration (see Figure 2). The best point of integration is the ultimate output of the predictive model: the predicted outcome and the model’s confidence in its prediction. A money laundering app might predict that a series of transactions is likely illegal and trigger a process in the system of record that then rejects the transactions. Wikibon sees this emerging approach to integration as one of the marketplace’s first solutions to making big data apps coexist with SoR’s.


