We believe enterprise applications are undergoing a profound change. By next year, highly capable agentic systems will emerge to create new application classes and alter the way organizations think about their backend systems, data platforms and user interfaces. The extent of the transformation, we believe, will be more impactful to the application stack than were the changes brought about by innovations seen during the modern GUI, Web, cloud and mobile eras.
While many people are talking about agents, very few in our view have thought deeply about the potential of deploying and orchestrating armies of hundreds or thousands of agents to more fully automate enterprises. These capabilities are likely to come from application vendors, data platform providers, the cloud players and a select few innovators. This trend will most likely affect white collar productivity in a way that mass production boosted labor productivity. Our expectation is that ultimately, intelligent, agent-based systems will be able to complete many common business processes with one tenth of the headcount required today.
In this Breaking Analysis, we build on our previous work on agentic systems and dig deeper into the topic. We specifically focus on how agent-based automation will alter the way applications are built, data is accessed and businesses operate.
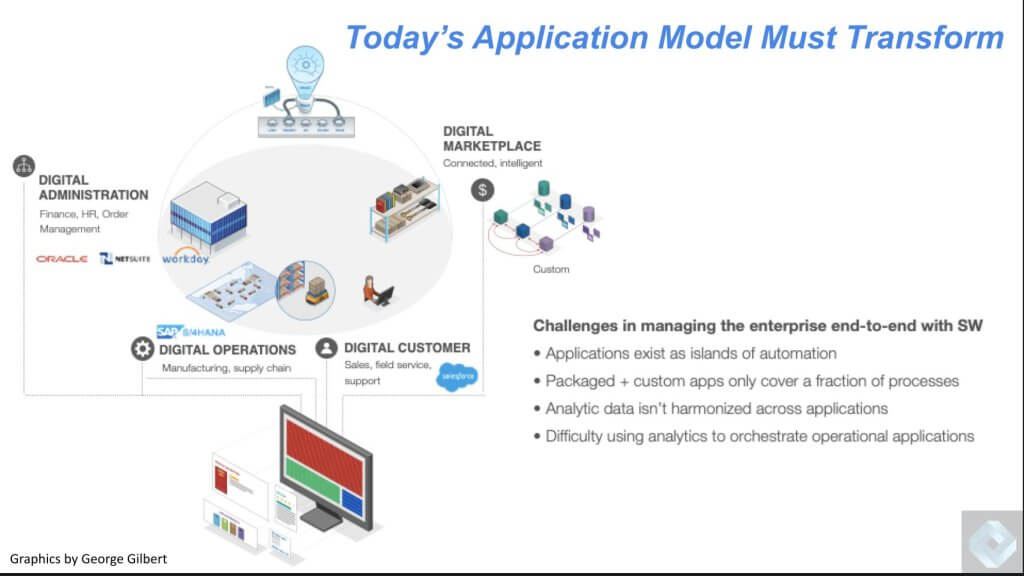
Today’s Applications are Islands of Automation
As we’ve previously discussed, today’s applications are a collection of bespoke systems that have data, business logic and associated metadata locked inside proprietary platforms. Commercial applications generally address narrow business challenges and connections to data in these systems necessitates a separate data platform that serves as the historical version of the truth. Operationalizing the insights from this data is an asynchronous process that falls short of industry promises to create a real-time, 360 degree view of the business.
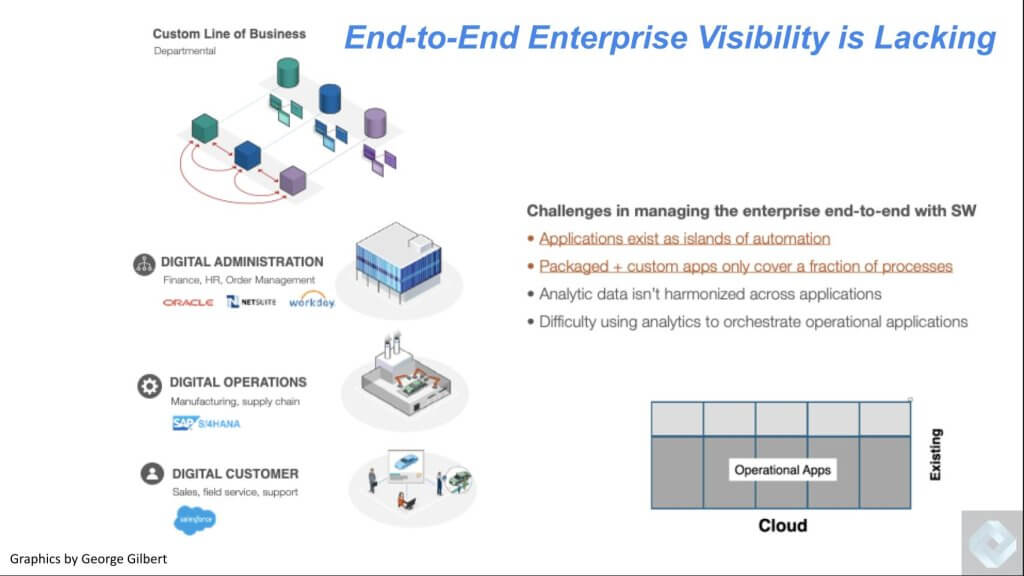
True End-to-End Automation is Virtually Impossible with Today’s Legacy Applications
Below we show some of the leading application platforms. They are most often loosely connected systems, which makes it difficult to view the state of a business in real time. We’ve been trying to bridge these islands of automation for decades. There’s an alphabet soup of acronyms like enterprise application integration or message-oriented middleware, web services, even microservices. But they are all hard to maintain and evolve because they’re too low-level. They’re further challenged because they must translate and navigate between applications that speak fundamentally different languages. As such, they’re brittle and they automate reach a portion of the application estate.
The bottom line is, across enterprises, we’ve essentially created software-defined departments, which feed exhaust data to a central repository that can give us a snapshot of the business at a point in time, but lack organicity and the ability to affect in the moment actions that are trusted.
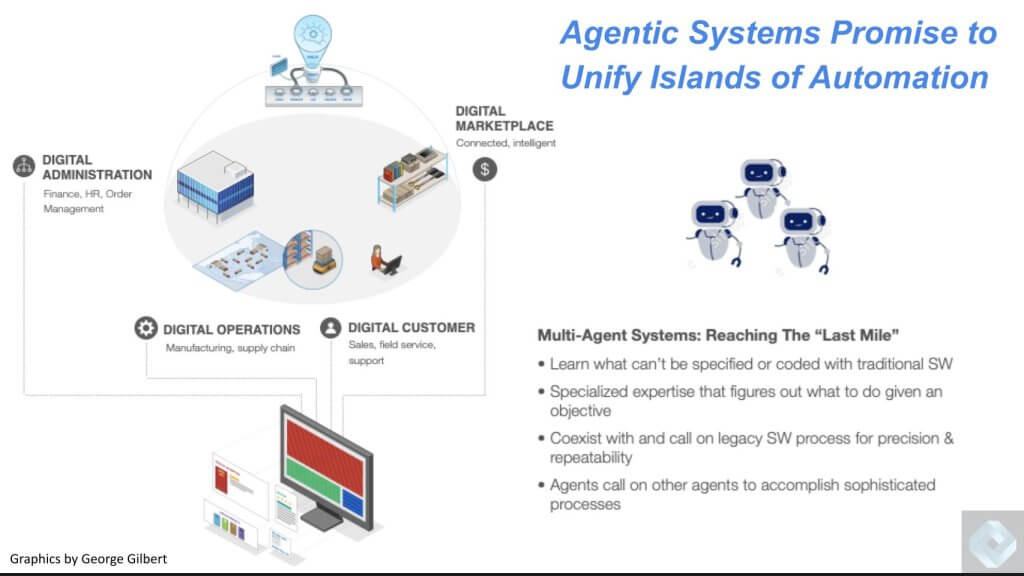
Agentic AI has the Potential to Unify the Silos
We see an emerging opportunity where systems of multiple agents can attack the islands of automation problem. We’ll show you a more full picture in a moment. As a preview we use the graphic below where we envision agents that have authority and resource access to allow them to work with human supervision toward a set of goals that are measured by the same KPIs we have in our dashboards today. Agents will work in a coalition with other agents and respond to actions and changes in the market while optimizing for a top-level business goal such as customer satisfaction, market share, profitability or growth. These agents will complement and augment existing automated processes. Importantly they’ll learn from these existing systems and human actions and do things that can’t effectively be hand-coded.
As such we see an entirely new stack forming on top of today’s existing systems. We don’t see this as a rip and replace but rather an evolution that will take place over the next five to ten years. We believe those firms which can take advantage of the transformation will radically improve their productivity by deploying multiple agents that can work together driving AI-native processes that will disrupt businesses who don’t respond.
Reimagining the Enterprise Software Stack
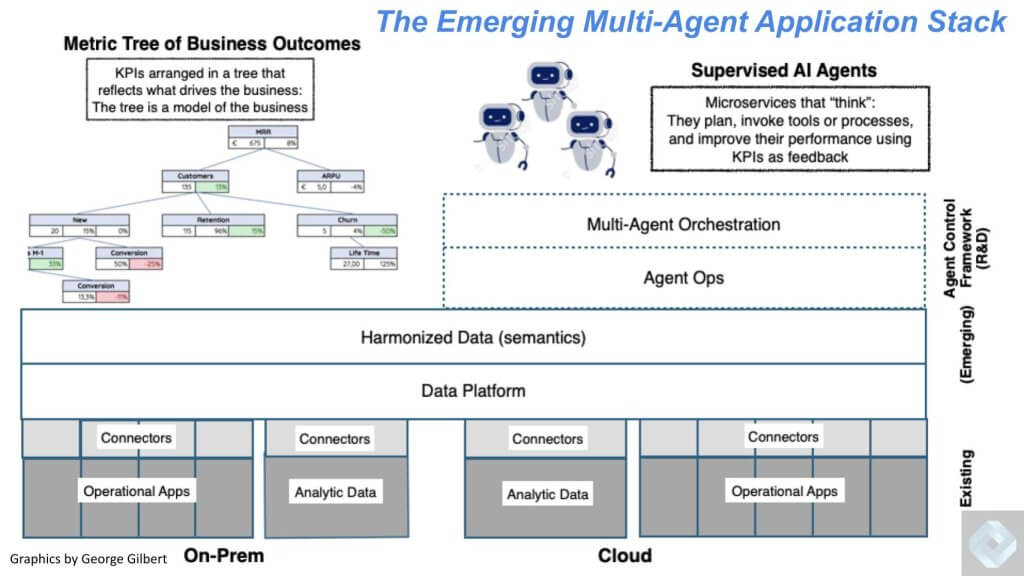
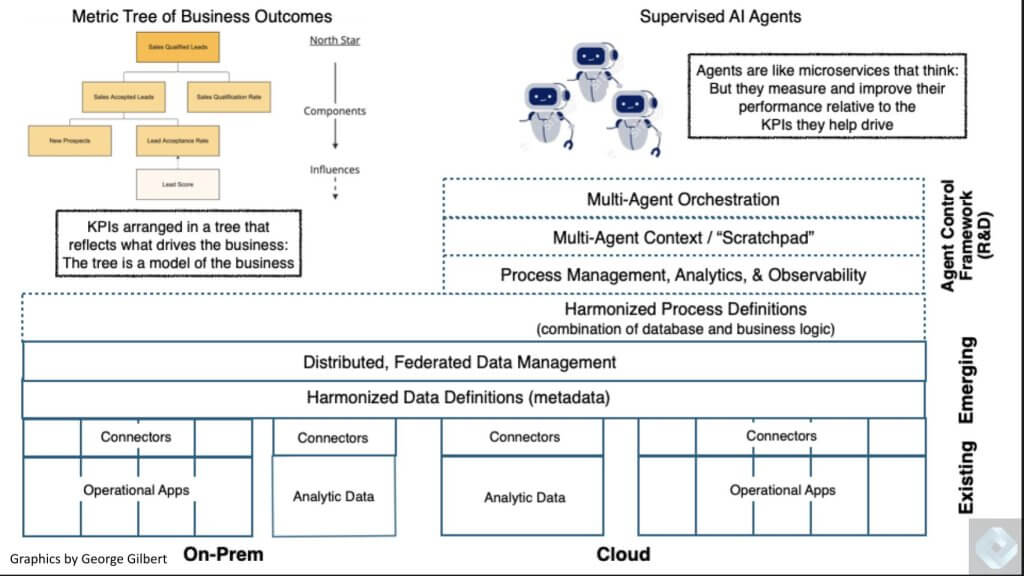
Below is a more comprehensive view of what the emerging intelligent application stack will look like. We’re going to walk through the salient aspects of this diagram but as a setup we see five critical areas within this picture.
The connection to existing backend operational apps and analytic systems (bottom layer)
The data platform architecture above that which will become increasingly abstracted in our view.
A so-called semantic layer which needs to be built that harmonizes all the disparate data elements in the enterprise such that data definitions are consistent, trusted, sharable and of course, governed.
An ability to deploy, manage, orchestrate and optimize multiple agents as shown in the upper right.
The agents are guided by business metrics, represented in the upper left, based on top down goals.
A Bi-directional Model of an Enterprise
Think of this as a bottom-up, top-down model of the business that we believe will dramatically improve productivity and alter the application landscape. In our view, this is a profound transition for the industry, unlike any we’ve seen before because it affects both the demand for the software through UI innovations that make applications accessible in new and different contexts but also radically changes the productivity of every aspect of the software development lifecycle.
Of course, we’ve had top-down “intergalactic” approaches in the past that have attempted to integrate the enterprise. But they’ve never succeeded. One example is enterprise data models that were too difficult for in-house developers to maintain. That’s essentially how commercial off-the-shelf software (COTS) spawned a new breed of applications. As well, we’ve seen bottom-up approaches trying to model everything, for example, in microservices, but that created a “Tower of Babel” that we only partially reconciled downstream by bringing data into a data lake or the modern data stack.
All these approaches resulted in the same islands of automation or analytics that spoke different languages. Agents, which are the next iteration of large language models, (we think of them as large action models) can bridge these islands by helping them work together. Eventually, we envision agents from vendors that might exist in different applications today to talk to each other essentially in natural language. Once we have the proper scaffolding in place as shown in the diagram above.
Not only will agents be able to talk together in this common language, they’ll be able to learn what’s going on in the business by observing the breadcrumbs of business activities, all those activities that can’t be explicitly coded. That brings the bottom-up approach that wasn’t technologically possible before.
Now let’s walk through the above diagram and double click into the salient aspects of the five elements we cited above.
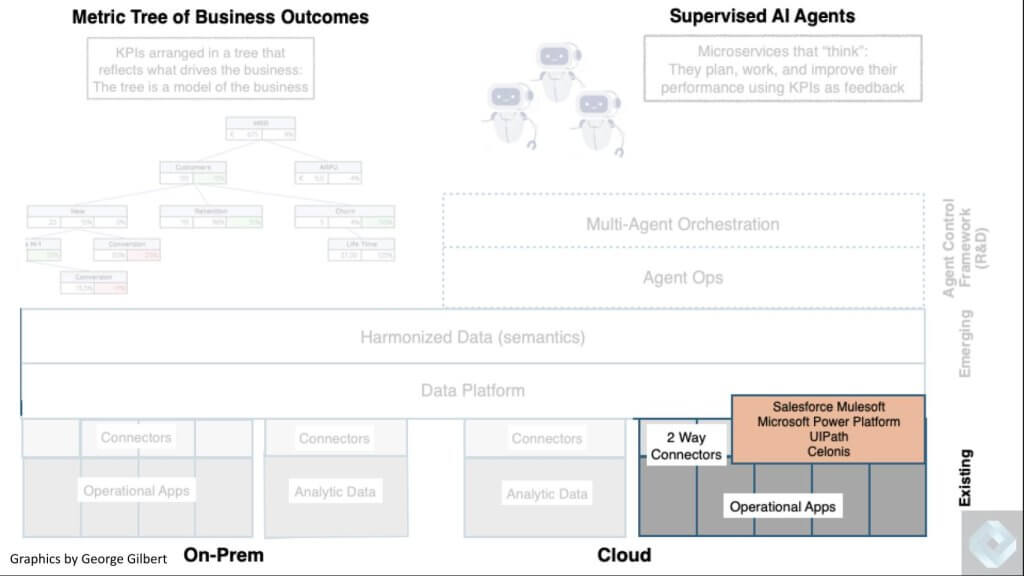
Connecting to Backend Legacy Applications and Data
Below we show examples including Salesforce and its Mulesoft asset. Microsoft Power Platform and automation specialists UiPath and Celonis, as just a few of the firms we see having the potential to contribute to this vision.
It’s important to keep in mind that, like all transitions, we don’t sweep aside everything that came before. These technologies must coexist with and build on the legacy enterprise software stack that has been built over decades investment. To do that, we need to start with these two-way connectors shown above so that agents can be aware of what’s going on in the business by talking to existing systems. The reason we emphasize two-way connectors is they’re going to have to perform transactions to update what’s in the existing systems of record that today are mostly islands.
For example, let’s consider the idiosyncrasies of product returns that require “tribal knowledge” to adjudicate and have many permutations, making them too cumbersome to hand code. An agent that’s assisting a customer service rep talking to a customer about returning a product will need to talk to an order management system, an inventory system, a logistics system, et cetera.
We envision that happening with one or more agents observing the human process, learning over time and ultimately interacting with these connectors that will interrogate and/ or transact with these backend systems. At first, it will only be one agent that will know how to talk to these different systems because they’ll have to be trained or even hard-coded on how to connect. But over time, you’ll have agents that are more adaptable and they’ll be able to talk to and call on each other. Importantly, all the work currently getting done with existing applications will be critical building blocks that agents evolve.
The bottom line is these connectors are the starting point and firms that are building them will have an early advantage.
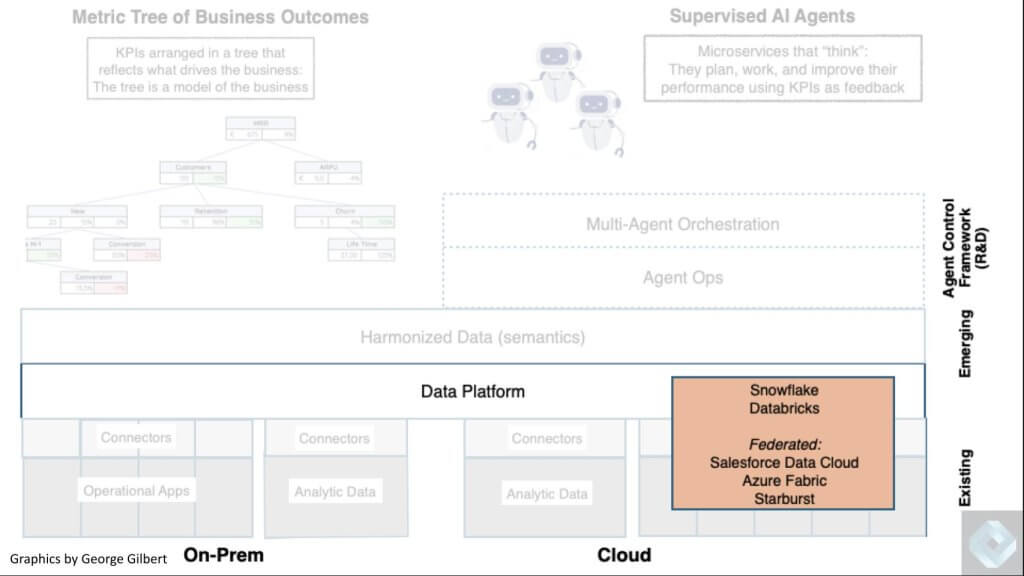
The Evolving Data Platform
Every ten years or so we see the emergence of a novel data platform approach. From the original DBMS to the data warehouse, data marts, Hadoop data stores to today’s modern data platform represented below by Snowflake and Databricks. Innovation in data platforms is constant.
We’ve covered Databricks and Snowflake extensively and the many changes that are occurring in that market. Specifically the shifting point of control from the DBMS to the governance layer, which is becoming more open; and the movement of value up the stack into the application layer.
While there’s lots of work to do, specifically around governance, above we show those two leaders plus some new entrants like Starburst which is taking a federated, data mesh approach, and some existing application vendors like Salesforce with its data cloud and Microsoft building abstractions across its data estate and unifying its metadata and governance model. Of course Google and AWS will be participating as well but we see the five names shown above as actively making moves in this space.
The data layer is the historical source of truth for the enterprise. It captures in one logical place what has happened, why it happened, what will happen and even what should happen. In other words, this is the context that guides agents and their activity, and that’s partly why the move from a DBMS-centric to a metadata-centric approach to the data platform is so important because that’s what allows multiple compute engines or tools to access the analytic data estate at any one time.
Today, those different engines might be machine learning tools or training your own LLM, but in the future we’ll see multiple agents talking to this data. That’s why we’ve stated that a single DBMS as the point of control is a bottleneck. Today’s data platform is unfinished because all the data that it pools has been stripped of the context and meaning that was captured in the apps or those islands of automation.
As Zhamak Dehghani described in detail at Supercloud 7, this business context (metadata, governance, metrics, etc.) has been bolted on top of a centralized data store, fed by brittle data pipelines and has created unmanageable complexity for humans.
The bottom line is all this disparate data needs to be harmonized, which leads us to the next layer of the stack.
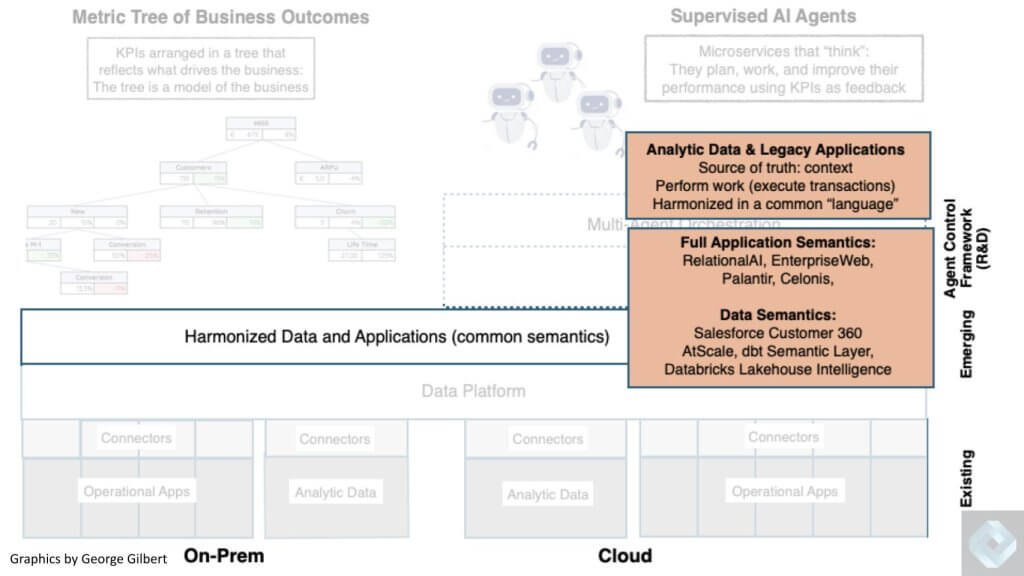
A Layer to Create Common Meaning
Let’s keep moving up the stack and focus on what is sometimes called the semantic layer but we also refer to it below as the harmonized data layer.
This is a big missing link today where we’re trying to rationalize all the complexity around data pipelines and data products and multiple data types, bolted on metadata and governance models, metrics layers that all ultimately feed analytic applications. And we want to bring the data together in a way that speaks a common language of the business and is trusted so that action can be taken or what we show here as transactions. This ties back to the work we did last year with Uber and our vision of Uber for all.
The chart above shows firms coming at this from two directions: 1) The data semantics that we’re seeing emerge from Salesforce with customer 360 (for example); and 2) The metrics layers from firms like AtScale, dbt and Databricks’ Lakehouse Intelligence.
We’re highlighting two approaches above: 1) Salesforce’s Customer 360, which also goes along with Supply Chain 360, Operations 360; and 2) The metric layers with dbt and AtScale as examples. We see these two vectors as two sides of the same coin. They’re all trying to connect what seems like disparate data so that they describe the same thing as part of our theme of moving from strings of data (that databases understand) to people, places and things that are meaningful to the business (i.e. human concepts). In the case of Customer 360, you can understand a customer journey and their preferences, for example. With metrics, you get a description of all the elements for measuring business KPIs such as bookings, billings and revenue. Again, getting away from strings and moving into business language.
But each of these two approaches only solves part of the problem of getting to people, places, things and activities. These standardize the language around things or simple measures. They don’t standardize and harmonize the activities or business processes that link and span all these things. That’s a much harder problem. This is why we show above RelationalAI, EnterpriseWeb, Palantir and Celonis. They are each coming at the problem from a different angle and are trying to solve this harmonization problem.
As an aside, in our view it’s inaccurate to suggest that the so-called modern data platform is not going anywhere and will no longer be important in the age of AI. Some of the pioneers in this space such as Tristan Handy of dbt Labs have written about how interest and valuation from the investment community has moved on from the data platform, which is true from a the perspective of a capital allocator. But there’s a contrary point of view, which is AI will put much more pressure on the data platform to innovate so that it can harmonize first the analytic data and then eventually the processes and the operational apps. Agents will be so much more powerful and productive when they can navigate across these modern data and application estates when they have one uniform map of the world of an enterprise and its ecosystem.
What’s not clear yet is whether today’s data platform vendors (i.e. Snowflake, Databricks, etc.) will lean in to this layer and be the source of the harmonization technology; or a new wave of companies will attack this problem and suck more value out of today’s data platforms.
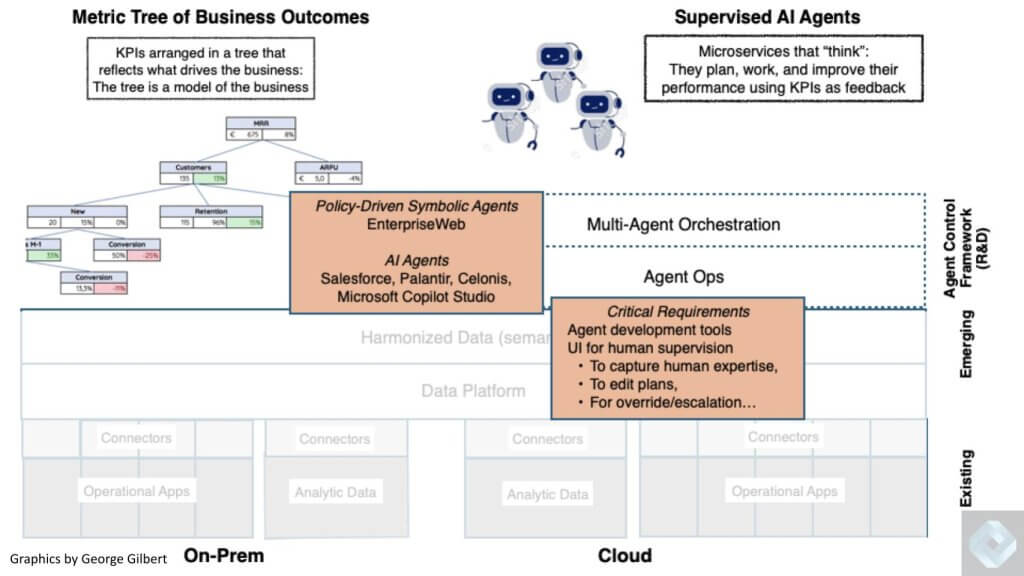
Enter the Intelligent Agent Layer of the Stack
Large Language Models (LLMs) Become Large Action Models (LAMs)
Moving north up the stack into what may emerge as one of the more valuable pieces of real estate in the next ten years, the agent operations in the upper right corner as highlighted below. There’s a lot more work that needs to be done and new tooling that must be created, but this is where the vision becomes reality. Importantly, we’re not taking humans out of the equation, rather we’re enabling agents to work in concert with each other to understand a firm’s objectives, adjust plans as the business evolves and make humans and organizations dramatically more productive by doing repetitive tasks, inferring from human actions and presenting plans to humans for approval.
We predict that the shiny new toy next year that everyone is going to be talking about is agents. This in a way is a reincarnation of LLMs from large language models to large action models. Everyone has been talking about individual agents or copilots. In our view, that’s like talking about individual microservices. They only become really effective when they work in conjunction with other agents (or services) to accomplish more sophisticated, compound tasks, which we call business processes, building on previous organizational muscle memory. To do this, we need an agent control framework. We see this layer as a crucial part of the new application model, or what we call scaffolding, that’s emerging. We used to have an application model that existed in three logical tiers: 1) A data model which was stored in the DBMS; 2) Application logic, which was its own sort of separate tier; and 3) A UI or presentation tier.
This model gave us the islands of automation because each was its own stovepipe, even when we got to the microservice era. While it’s still evolving in our minds, when this new model matures, it will allow agents to talk to each other across applications and from different vendors.
Organizational Metrics Guide the Agents
A tree of metrics shown in the upper left quarter is also critical because it informs and guides the agents. At the very top of that tree are the north star objectives (or OKRs) such as grow the business by X, or expand the ecosystem by Y, etc. At top of the tree, we’re not just looking at financial metrics, rather overall organizational objectives, key results and the actions around them. Beneath that, we envision all the components that drive or influence those north star metrics. This tree of metrics metaphorically measures and represents a model of how the business runs.
Then we envision an this org chart (shown to the right) of all the specialized metrics and the associated responsibilities to optimize these (MRR, NRR, market share, ACV, LTV, CAC etc.). Each agent has specialized expertise, but unlike microservices, they have more intelligence to figure out how to accomplish a task beyond what’s explicitly specified, how to do product returns for example, and they get better over time as they learn and iterate. They do this by: 1) Measuring their performance against the outcomes that are in the metric tree (e.g. customer satisfaction, cost to serve, etc.) and 2) By observing their human supervisors and by capturing the knowledge of domain experts who edit the plans that they generate.
The bottom line is this is different from procedural code that we’ve used for decades because now we can capture tacit knowledge, and we can capture the 80% of enterprise activity and processes that previously couldn’t be specified top-down in some Newtonian mechanical set of rules.
A New Enterprise Application Paradigm Emerges by the End of the Decade
We’ve come full circle here. Let’s bring back the full picture again and summarize our takeaways.
The evolutionary part of this system is it is built on top of existing cloud and on-prem systems with deep connections into these critical operational applications as well as the historical systems of analytic truth.
A unified and cogent metadata model must emerge from a combination of existing data platforms and a system that ties together multiple data estates into a single federated data management system.
A layer evolves that harmonizes the data and business logic as well as the process definitions that are established by the business. This supports a highly valuable agent framework that we believe will be built to orchestrate multiple agents that are working together toward a business outcome, defined by business goals. The progress toward those goals is measured by key performance indicators that comprise OKRs that can be fine tuned and adjusted as business conditions change.
All of this is transparent to human overseers who can adjust plans and provide feedback from which agents can learn over time.
Moving Beyond RAG…How Long will it Take and Where is it Starting?
On the timeframe, Salesforce is most likely to be the first, at least to announce an army of agents and a framework to make it work, we believe, next month at Dreamforce, the company will unveil more clarity that will align with our vision. We believe Microsoft will likely be the second at Ignite, their conference for their partners in November. Both of these firms are moving in this direction and we think they will further demonstrate a vision for this transition to armies of agents as opposed to all the sort of simmering activity we’ve heard about single agents added in the ecosystem.
This is so much more sophisticated and useful than retrieval augmented generation (RAG). In this world we envision agents doing work on behalf of a human supervisor and working in concern with other agents. They learn over time and cooperate with other agents to solve complex tasks by building on simple expertise that each of them possesses.
Crucially, these agents build on the enterprise software that’s been built up over decades. And to be very explicit, what’s in symbolic software, traditional software, is what needs to be repeatable, precise, accurate, and that which can be specified. Think of it as Newtonian mechanics, whereas what’s in agentic AI, there’s a long tail of “dark enterprise matter” of activity that you couldn’t capture in these Newtonian rules, but you could only learn bottom-up. And they have to coexist.
To be clear, this is a piece of our vision that is evolving and is opaque today. Specifically, exactly where that layer of coexistence comes from because in the Newtonian world, you’re still going to want to align all your activity with very precise and repeatable analytics, but at the same time, you’re going to want to align the activity of your agents.
To accomplish this will require a very different mechanism. Where those two alignment technologies come together – i.e. how do I align the Newtonian activities and the agentic activities, is the biggest open question and will take the better part of a decade to evolve.
A key point is it does not make the data platform less relevant. It actually will make it and the layer that it needs to grow into more important. What’s not clear yet is who’s going to innovate and create that layer above the data platform that harmonizes.
To emphasize, agents are going to be the next big thing that captures everyone’s attention, especially armies of agent and the framework that aligns them, but they really need a harmonized estate underneath to make them work and make them perform to our vision.
Spending Data for Some Aspiring Agentic AI Players
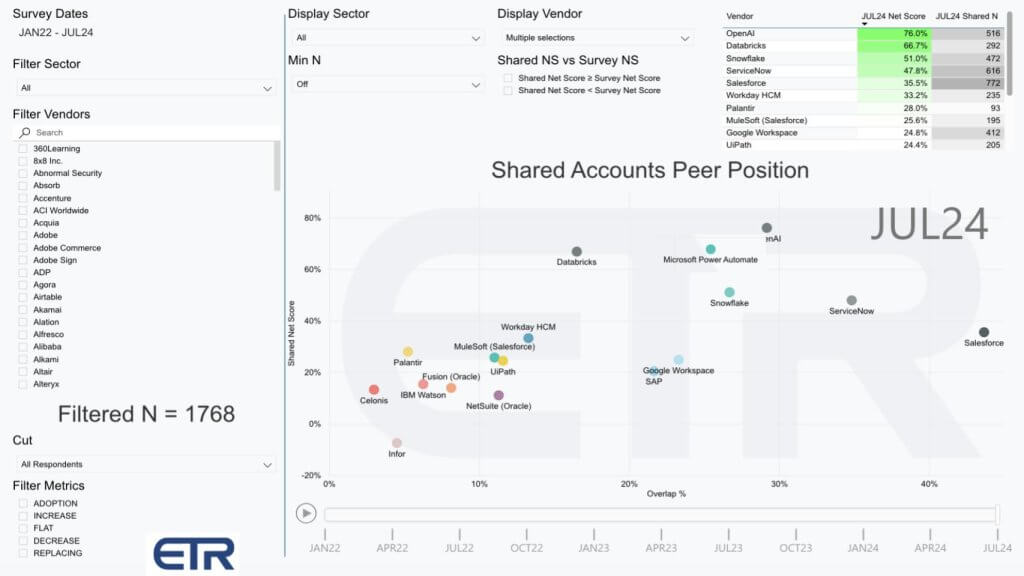
Let’s bring in some of the ETR data. In the chart above, we cherry-pick a number of enterprise application and data platform firms. The data shows Net Score on the Y-axis and penetration or overlap in the data set on X-axis. This is data from more than 1,700 accounts that ETR is surveying here. Net Score is a measure of spending velocity on a platform.
Remember, this methodology measure account penetration and has no indication of actual dollars spent.
Salesforce has a dominant presence, as does ServiceNow. OpenAI continues to lead virtually all companies in terms of Net Score in the enterprise. Snowflake is also prominent. Databricks has momentum as you can see in the vertical axis. Google Workspace and SAP are comparably positioned, and we also show Microsoft’s Power Automate as a representative of its overall Power Platform.
We’re also showing a pack of Workday, Salesforce’s MuleSoft, which is strategic for Salesforce. UiPath, NetSuite, which is Oracle, also Oracle Fusion and IBM Watson, which we think has got a play here. Palantir, which we referenced earlier, as well as Celonis, and then Infor for context as another legacy application company to which there are going to be connections.
Each of these firms has a different approach. The other callout that’s really interesting is the frontier models like OpenAI, Gemini and Anthropic. They’re all trying to build general purpose agents with these open-ended reasoning and planning capabilities. And that’s why we did an earlier Breaking Analysis where we said those building these open-ended consumer models are like adventurous sailors in the Middle Ages who are potentially sailing off into the end of the earth and will fall off the end of a flat plane. It’s a very open-ended, difficult problem.
Whereas you take someone like Salesforce or Microsoft, and their agents just look at a small piece of a well-defined map of the enterprise, and they know it’s not an open-ended search and navigation problem. You have a choice of half a dozen things you might be able to do, and you can mix and match how to get them done. It’s a much more tractable and finite problem. So there’s a little bit of mix and match, apples to oranges, on this chart. And it makes us think back twenty-five years ago. First, we had B2C commerce try and take off, but it was such a general purpose problem that the B2B had a smaller number of customers with much more well-defined activities.
That business took off first in a much more meaningful way. And similarly, we think these enterprise agents are going to get to maturity much faster. So Palantir, for example, has built a mature foundation across largely the legacy transactional systems in the enterprise. Celonis learns the capabilities across different business systems bottom-up by reading the logs and understanding what’s going on. UiPath has the opportunity to learn both from APIs and screens so you can get to legacy apps that don’t even have APIs.
No importantly, they’re not semantically harmonized yet, but they have the richest and easiest to use tools to make it possible to build armies of agents. They don’t yet have the agent control framework for armies of agents, but we think we’ll see that this fall. And we think we’ll see Salesforce put all the pieces together, at least for working in the context of Salesforce, next month at Dreamforce.
The bottom line is we’ll start to see the different approaches bringing some of the pieces together and over time filling in the blanks. No one firm is going to have all the pieces.
Agentic Timeline and Scenarios to Watch
Our research indicates that the evolution towards agentic systems is set to transform the landscape of data management and application development profoundly. As we transition into the 2030s, we believe the emergence of intelligent, multi-agent orchestration will play a pivotal role in bridging the gap between legacy data systems and modern application needs. The growing prominence of open table formats and the evolving concept of data mesh illustrate the ongoing shift towards more flexible, decentralized data architectures. However, significant challenges remain, particularly around governance and the integration of disparate data sources into a unified, harmonized platform.
Looking forward, we expect major cloud providers like AWS, Google, and Microsoft to increasingly focus on simplifying and unifying data management to support the development of intelligent applications. The anticipated advancements in low-code and no-code tools, alongside the push towards comprehensive agent frameworks, are likely to redefine the competitive dynamics in the application platform market. As these trends unfold, traditional data and platform platform vendors will need to adapt quickly, moving beyond their current roles to prevent being overshadowed by new harmonization layers that can dictate feature adoption.
In conclusion, while the path to a fully harmonized and agentic system landscape is fraught with complexities, however the potential for enhanced organizational productivity and agility is immense. As we continue to monitor these developments, it is clear that the ability to adapt and innovate will be crucial for players looking to maintain their competitive edge in this rapidly evolving market.
We see the second half of this decade moving beyond the buzz of generative AI, large language models and opaque ROI in the enterprise. Agents working in concert to dramatically automate businesses has the potential to deliver on the promise of AI and bring productivity improvements that can propel the global economy to new levels of growth and dynamism. While much invention is required to fulfill the promise of AI, the technologies are coming together to make our vision a reality, where an organic and ever-changing digital representation of an enterprise and its ecosystem is delivered as part of a new framework for applications. Built on decades of existing legacy applications and SaaS solutions, we see the future of intelligent agent-based systems as the next evolution in application architecture.
What do you think? Are there firms working on this problem that we’ve not mentioned? Please let us know so we can continue to map the future of enterprise data and applications for the community.
All statements made regarding companies or securities are strictly beliefs, points of view and opinions held by SiliconANGLE Media, Enterprise Technology Research, other guests on theCUBE and guest writers. Such statements are not recommendations by these individuals to buy, sell or hold any security. The content presented does not constitute investment advice and should not be used as the basis for any investment decision. You and only you are responsible for your investment decisions.
Disclosure: Many of the companies cited in Breaking Analysis are sponsors of theCUBE and/or clients of Wikibon. None of these firms or other companies have any editorial control over or advanced viewing of what’s published in Breaking Analysis.
David Vellante
David Vellante is co-CEO of SiliconANGLE Media, as well as co-founder and Chief Analyst at theCUBE Research, the world’s leading open source technology research community.
Dave is a long-time tech industry analyst, entrepreneur, writer and speaker. As co-host of theCUBE – “The ESPN of Tech,” Vellante has interviewed over 5,000 experts since 2010. He is also a co-founder of CrowdChat, an angel funded startup based in Palo Alto using big data techniques to extract business value from social data.
Prior to these exploits, Dave founded a CIO consultancy and spent a decade growing and managing IDC’s largest business unit. He lives in Massachusetts with his wife and four children where he is active in town activities including serving as the president of his town’s local “Kiddie Sports” association. Dave holds a B.S. in Applied Mathematics from Union College.