
The market is trying to price a transition it hasn’t fully internalized. It sees Nvidia’s market cap with a 5-handle and assumes the valuation is too high to grow further. We believe that’s the wrong mental model and it underestimates the market potential. While the shift underway resembles the RISC to x86 transition, it is far more substantive. While x86 became the de facto standard, it largely grew proportional to normal server and PC refresh cycles. The dynamic powering Nvidia is much more powerful and underestimated by many in our view. Nvidia is creating a new platform by becoming the default substrate for enterprise computing, and that platform pulls everything else into its ecosystem. In this cycle, the unit driving growth isn’t a PC or a server, it’s the AI factory, which is a rack-scale system that turns power, data, compute and software into intelligence through tokens, reasoning, and automated workflows.
Our core premise suggests Nvidia is assembling a new enterprise platform that will impact all aspects of business, not just the IT department. Nvidia is making workloads run faster and enabling new work but the story is much bigger. The AI factory in our scenario will absorb the enterprise functions x86 historically provided around execution, storage, databases, recovery, security, management, and compatibility. But it will apply these capabilities to do much more than we’ve ever been able to do with computing.
Specifically, the outputs of the AI factory will become the ingredients for new business models and sources of revenue by completely changing how organizations operate. Organizational structures will flatten and silos of data and process will be disassembled and refactored to drive unprecedented levels of productivity. The nuance is enterprises really don’t run clean, deterministic systems today, they run fragmented application estates held together by human semantic reasoning. Humans reconcile exceptions, make corner case approvals and often are required to do manual recovery. The AI factory’s promise is not only faster compute in isolation; it’s also automating these edge cases that currently require people to interpret, coordinate, and rationalize inconsistencies. The result will enable organizations to scale with far less labor.
To support this transition, the underpinning of computing infrastructure is changing. The rack now becomes the computer. This is not just Nvidia marketing – it is that – but it’s also profound. Nvidia’s annual cadence comprising CUDA, DGX, Mellanox, Grace/Hopper, Spectrum-X, Blackwell, Mission Control, Rubin, Omniverse, and eventually Feynman, deepen work around storage and context. To us, this looks like a deliberate buildout of a full-stack, enterprise-wide operating platform. Critically, we believe x86 doesn’t vanish – it gets absorbed– and the new operating model leverages trusted systems built up over decades. In other words, we see an architectural adoption path where deterministic workloads are preserved while the AI-factory grows around them…lowering migration friction, learning from the reasoning traces of humans, monetizing intelligence, all while the new platform earns loyalty (aka lock-in) through capabilities and superior economics .
In this Breaking Analysis – we build on several years of work at theCUBE Research, catalyzed by George Gilbert, to lay out the profound changes coming across compute, networking, storage, databases, software, recovery, security, and operations. We share why the transition will be more significant than prior platform shifts as frontier models become the migration tools while the platform is being built. Our goal is to replace market confusion with a coherent map to describe what’s already here, what’s missing, and where enterprises and vendors will need to adapt – whether they want to or not – and how it will change the technology model, the operating model and the business model of every organization on the planet.
Semi stocks show a disconnect: NVIDIA fundamentals vs. market movements
The chart below shows a strange dynamic happening in this semiconductor boom. Year-to-date, Intel is up nearly 200% and AMD is up 91% (as of Friday pre-market), while NVIDIA is up only about 13% despite being the clear outlier on fundamentals. The table underneath reinforces the dissonance. NVIDIA is projected to be far larger on revenue, grow faster, and generate dramatically more free cash flow than its peers, yet it trades at a forward P/E that is lower than everyone listed except Qualcomm. The market’s typical explanation is NVIDIA is too big, has already run, and its moat is being disrupted by competitors, including AMD and Intel, plus hyperscaler silicon like Google TPUs and AWS Trainium, and adjacent players like Broadcom.
Our opinion is that this logic is flawed. We believe the market is pricing in a share-loss story that is not showing up in the market. NVIDIA’s volume position, combined with its ecosystem and installed base is its flywheel advantage. It enables faster reinvestment, stronger ecosystem affinity, and better access to what the company needs from the supply chain to keep on its annual innovation cadence. That’s the core advantage here, and it’s why we believe NVIDIA can hold share in accelerated computing and may even gain share, as counterintuitive as that sounds.
Key takeaways:
- The market is skeptical that Nvidia can maintain its lead and is rewarding alternatives – looking for new sources of opportunity even while NVIDIA remains the leader and fundamental outlier on scale, growth, and cash generation.
- NVIDIA’s lower forward P/E (relative to the peer group) suggests the market is still discounting its durability, largely on competition eating into its moat and “too big to grow” logic.
- We believe NVIDIA’s 85%+ share can hold and become a durable advantage because it funds velocity, supports a yearly improvement cycle, and keeps NVIDIA in a stronger position than its competition.
Bottom line: the market action is sending a mixed signal – momentum is chasing the challengers, while the fundamentals still point to NVIDIA as the best-positioned company in the group. Markets typically reward the leader with outsized multiples but in this case it is doing the opposite. Our view is that NVIDIA’s volume-driven flywheel and yearly cadence are the right way to handicap the next leg of the cycle and unless Nvidia fumbles its execution the story will revert to normal valuation dynamics.
Core premise: Nvidia rebuilds the enterprise platform layer
This slide below sets up our core thesis in three steps. First, token economics becomes the unit of value – measured by cost per watt to generate tokens inside a power-constrained AI factory. In our view, that’s why tokenomics is so important. If operators have a mostly fixed power envelope, yearly step-function improvements inside the same power constraints translate directly into better economics. In other words, I can’t add more power so if I can get orders of magnitude better performance with the same power it means I’m more profitable.
Second, frontier models become the migration engine. They do more than generating tokens. They also interpret, rewrite, and operate against existing systems. As the models improve, they pull more workloads into tokenized workflows and drive more demand for tokens. That flywheel is moving very fast.
Third, the x86 stack doesn’t get ripped out – it gets absorbed. Most enterprise data and applications still sit in x86 environments, and we believe the winning strategy is to carry that deterministic world into GPU/CPU/DPU fabrics and modernize it in place. On the slide we calls this x86 absorption, and we believe the migration is capability first, then economics, then platform affinity, locking in an ongoing cycle of innovation and spending. The Nvidia/Intel deal we analyzed in a previous Breaking Analysis is a win-win-win for Nvidia (access to x86 installed base), Intel (cash + relevance in AI + a foundry customer) and customers (smoother transition to the future).
A few points worth calling out:
- Frontier models drive demand because each improvement increases token volume and expands the set of tasks enterprises can accomplish;
- Token economics are critical because power is fixed – orders-of-magnitude gains inside the same power envelope translate into real dollars for operators;
- x86 absorption is the bridge and the Intel–NVIDIA joint initiative to bring Intel’s x86 into the platform (in the same way ARM CPUs show up today) is a key enabler. It allows racks of x86 to be linked into the same fabric with DPUs and networking so legacy workloads can be carried forward, modernized in place, and progressively absorbed into the accelerated stack.
Bottom line: We believe the joint Intel–NVIDIA move is a pivotal and practical step that is being under-valued. It’s how the accelerated platform reaches the messy middle of enterprise computing, where the apps and the data still live.
Enterprise software today: The “Deterministic Myth”
We often stress the importance of deterministic software but there’s an unspoken truth that we need to address. Enterprises talk as if they run deterministic systems – ERP, CRM, finance, HR, security, analytics, manufacturing – but what they really run is an application jungle with different data models, different definitions, and different versions of the truths that varies by department. The glue that brings this all together is human reasoning. Domain experts interpret. They reconcile. They make exceptions, approvals, interpret meaning, they cleanup in spreadsheets and they reconcile differences in hallway conversations. That human semantic judgement is productive, and it’s also probabilistic – you don’t always get the same answer twice because the system is really a mix of tools plus interpretation.
This is the big productivity unlock.
On the right side of the slide, the outcomes are what we all recognize in practice – delayed truth, conflicting semantics, high coordination cost, and manual recovery when things break. A data warehouse helps, but it’s still a time-lagged mechanism. It creates a historical lookback version of truth and it doesn’t eliminate semantic drift. The BI industry has created a $50B business out of metrics and dimensions, but even the best metric catalog doesn’t magically create real-time shared semantics across the enterprise.
- The core point we often stress is plugging an LLM into a vectorized database sounds cool, but it doesn’t automatically deliver enterprise-grade outcomes;
- The enterprise value becomes more tangible when deterministic software and probabilistic systems are blended – so the model can reason and create, but the environment can govern and guide;
- The new platform has to automate the work people do at the seams – reconciling definitions, resolving conflicts, and turning “tribal knowledge” into shared semantics that can operate in real time.
The implication is simple but uncomfortable. The deterministic enterprise has been a story vendors sell and customers buy, because it’s the best they have today. The next platform wave has to shrink the manual reasoning work that keeps the story alive, and replace it with real-time semantics that can be executed and trusted across the enterprise.
Economic inflection: From CPU refresh cycles to token factories
The slide below gets at the core economic shift we believe is underway. AI infrastructure is turning compute from a back-office IT cost center into a direct production system for tokens, reasoning, and automation. On the left, the chart shows Nvidia’s revenue scaling sharply from FY2024 ($60.9B) to FY2025 ($130.5B) to FY2026 ($215.9B). As we said in the first slide, consensus estimates are well north of $350B in 2027 and we believe the figure will potentially top $370B, which is a key assumption in the P/E ratio shown.
On the right, we highlight two other ideas: 1) A working hypothesis that the AI-factory capital pool will be >10x the old CPU refresh cycle, and 2) A view that Nvidia’s 65% revenue growth is being powered by data center AI and will actually accelerate in FY2027. The key nuance called out on the slide is x86 revenue can still grow inside AI servers, but the CPU-centric enterprise architecture becomes subordinate to the AI-factory architecture. We also believe Nvidia will have excellent CPUs that are optimized for the new era and be more efficient than traditional CPU architectures.
The practical reason this expands the market is the scope of what gets rebuilt. The previous era was largely driven by refresh cycles. In this AI wave, we’re talking about an operating-model replacement with integration, security, databases, recovery, analytics, and automation moving to a new framework. That’s why the TAM looks nothing like the last three decades of Moore’s Law-driven refresh cycles.
We note a key point on what this does to company economics. We’re already seeing new companies start from frontier models and look fundamentally different – with revenue per employee running ~10x what traditional companies look like. That isn’t a small productivity bump. It’s a change in the shape of the organization, where a small team can drive very large revenue because the “glue work” (data harmonization, semantic reconciliation, systems not talking to each other, coordination overhead) becomes a solved problem at machine speed.
Key points from this slide:
- AI factories pull compute into the line of business – tokens become the unit of output, and the economics attach to what those tokens can do;
- The early AI-native companies are showing order-of-magnitude changes in revenue per employee, and that becomes the benchmark legacy firms are forced to chase;
- NVIDIA’s growth rate is still constrained more by supply than demand – in our view, the north of 70% growth discussion is happening inside a supply-constrained reality, which is unusual at this scale.
Bottom line: This is why we keep coming back to the idea that enterprises will monetize intelligence. When token factories move from experimental infrastructure to production systems, the spending discussion changes from refresh to build capacity for revenue. And as supply constraints ease over time, the growth rates and the downstream operating leverage can move faster than most people are modeling today. This is what we wrote about when we discussed Jensen’s “Pareto Curve” business model Slide.
Historical parallel: RISC → x86 → AI factories
The slide below draws on an approximation using previous platform histories that somewhat echo today. In the 1990s, the enterprise market was defined by proprietary RISC systems that were high-performance Unix islands. But PC volumes created scale economies that allowed x86 to dominate enterprise markets. In the 2000s–2010s, x86 plus virtualization won by becoming the common enterprise platform for CPUs, VMs, storage, and applications. Our belief is that for the 2020s–2030s, AI factories win in a similar way – not just with faster chips, but by becoming the volume platform for reasoning, data, and operations, with token economics pulling more deterministic workloads into real-time reasoning systems.
In our view, the late-’80s/early-’90s RISC vs. x86 battle is still the closest platform parallel – even though today’s transition is more complex and moves faster. Back then, every major vendor (Sun, DEC, IBM, HP, DG, etc.) touted its own RISC variant and MIPS was another instruction-set contender, trying to standardize on its silicon. x86 and Intel ultimately won on economics and volume – the PC market created scale, and Wintel became the standard that later climbed into the data center. That climb took years as x86 proved it could handle heavier and heavier workloads.
The bet now is that the AI factory transition goes faster. The raw power of tokens – reasoning and intelligence delivered through frontier models – becomes the migration fuel. It’s not just that enterprises shift compute; it’s that models help interpret, rewrite, and operate legacy systems while the platform is being built. That’s why we believe the second transition is compressed – i.e. the “new” is creating the tools that pull the “old” forward.
- x86 took most of a decade to move up the stack into higher-value workloads;
- AI factories still take about a decade to play out, in our opinion, but a large portion of the shift happens in the first five years because tokens and reasoning accelerate adoption pressure and migration tooling at the same time.
Bottom line: The RISC-to-x86 transition was driven by volume economics and standardization. The AI factory transition is driven by capability first, then economics, then platform lock-in – and the rate of change is faster because frontier models help move the workload while the platform is forming.
Nvidia’s evolution from graphics card vendor to platform architect
This next slide captures the idea that Nvidia is building a platform, not a chip line. The sequence starts with CUDA as the software moat, then DGX as the integrated system, then Mellanox as fabric ownership. From there it pulls the stack upward and out toward CPU integration with Arm and Grace/Hopper, AI Ethernet with Spectrum-X, rack-scale inference with Blackwell/NIM, operations control with Mission Control, and now the next wave with Vera Rubin plus LPX and the STX storage architecture. With an annual cadence toward the next generation Feynman and new territory into physical AI with Omniverse. The message is Nvidia is assembling the full stack required for a replacement enterprise architecture, with hardware, software and libraries tied together through extreme co-design.
This portfolio expansion and the speed of its buildout is breathtaking especially because it’s deliberate. Each layer is designed to remove a bottleneck and keep the factory running as one system – hundreds of thousands of GPUs operated as a single machine. The early emphasis was on efficiency with better utilization, lower latency to generate tokens, and the ability to scale out without collapsing under networking or storage constraints. As the platform gets deeper functionality, it starts to change what companies can do with the system, moving from back-end acceleration to something that can drive how the enterprise runs and how it grows revenue.
We believe the market still under-appreciates how fast Nvidia is moving, and why that pace is hard to match. The platform is compounding value across its ecosystem. Every year adds new capability, and the stack gets more complete.
- CUDA and compatible software keep the installed base current and lower friction for upgrades;
- Mellanox plus Spectrum-X makes the network an asset, not a tax – in underutilized environments the network pays for itself quickly;
- Mission Control and the systems approach focus on operating the factory, not just buying components;
- LPX and the STX storage work mean low-latency inference and data movement are now first-class citizens.
The bottom line is this is not a vendor simply increasing the granularity of its offerings via different price points. It’s an architecture being built in plain sight, step by step. As enterprises shift from general purpose computing to token production, the winners will be the stacks that can run end-to-end, absorb existing systems, and keep improving on a yearly cadence.
Rack-scale compute becomes the new unit
The slide below expresses the core architectural shift in that the system is no longer the server or a blade. The unit of compute becomes the rack-scale fabric, designed to deliver intelligence. On the left is a GB200 / Rubin NVL rack – a tightly coupled NVLink domain with 72 GPUs and 36 CPUs. On the right are the functional blocks that turn that rack into an AI factory component, including frontier models for reasoning and agents, Mission Control for scheduling and recovery, Spectrum-X / InfiniBand for scale-out, BlueField DPUs for storage and security offload, context storage for KV cache and the data layer, and databases as the real-time truth substrate. The point is the rack is engineered as a system, not a collection of parts.
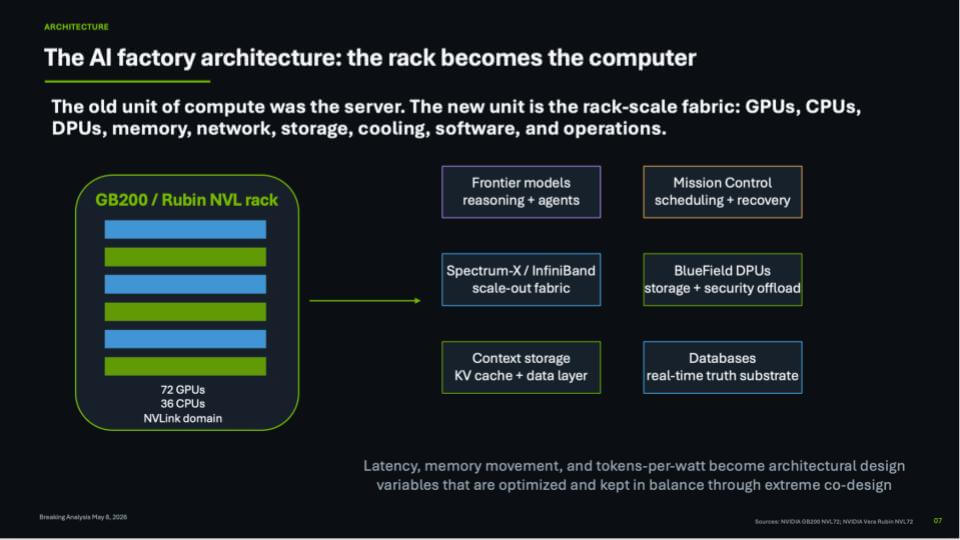
We believe this is important because Nvidia is defining what gets bought and deployed as a single system, rather than leaving the customer to assemble a server, then attach networking, then attach storage, then figure out where memory and data movement bottlenecks live. The rack pulls those variables into the design to manage latency, memory, data movement, and ultimately efficiency, which drives tokens-per-watt; keeping the system elements in balance through extreme co-design.
- The rack is a full-stack product – GPUs, CPUs, DPUs, memory, networking, storage, cooling, software, and operations – tuned for token production rather than generic compute;
- KV cache becomes a high order layer because context and memory movement dominate user experience and throughput once models move into agentic workflows;
- “Absorption” is the transition mechanism – x86 doesn’t disappear; it gets pulled into the rack-scale architecture so existing data and apps can move without a rip-and-replace disruption.
The bottom line is this is how Nvidia turns accelerated computing into a platform, not a DIY set of components. The rack becomes the purchase unit, the operating unit, and the optimization target. As this scales up, out, and across data centers, we expect developers to follow. The best software and the best builders will migrate toward the system that delivers the lowest cost per token inside a fixed power envelope.
How x86 gets absorbed
The next slide is the bridge. On the left is the legacy x86 estate – ERP/CRM transaction apps, SQL databases, VMs, SAN/DR, compliance control systems. In the middle is the absorption path – NVLink Fusion, “Intel + Nvidia x86 with NVLink,” and an AI control plane for placement and policy. On the right is the AI factory platform – a GPU/CPU/DPU rack-scale fabric, a real-time truth database plus context, and agents that operate across old and new systems.
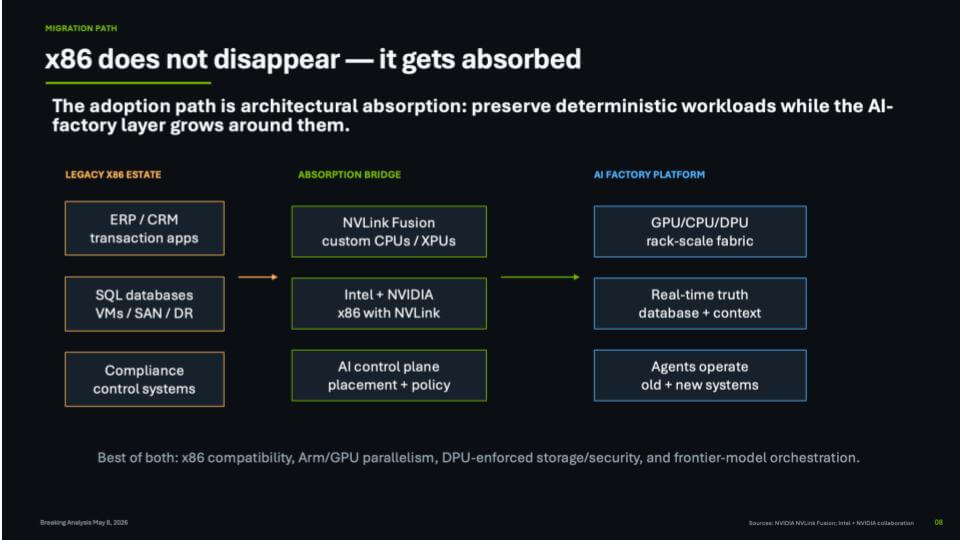
Our view is there is no plausible rip and replace path from today’s fragmented enterprise stack to a clean AI factory future. The migration has to be stage-by-stage, business process by business process. The way this works in practice is to pick a domain (inventory is a good example), apply frontier models and agents across the systems that touch it (purchasing, warehouse, planning, finance), and then do the hard work of resolving semantics between those systems. That’s not magic. That’s experienced people working the seams, gradually pulling the deterministic x86 world into tandem operation with the new platform.
This is where the Intel + Nvidia deal becomes more relevant. The legacy estate doesn’t evaporate – it gets pulled into the rack-scale fabric so CPUs, GPUs, DPUs and networking operate as one system. The old CPU-to-GPU ratio conversation is a good example of why the market is getting whipsawed by headlines. The ratio was talked about as 8:1, then 4:1, and Lisa Su has suggested it could go to 2:1. Our take is those ratios are a snapshot of immature utilization. If 14% CPU utilization is considered good (lower utilization is common), then the opportunity is to drive that toward something like 40%+ as the platform gets better at managing utilization across the whole system. If that happens, the CPU requirement is very likely lower than today’s headline ratios imply, and it lands somewhere in the middle.
A second factor is investor psychology. The tape is treating “Intel = CPU” and “AMD = CPU” as obvious winners. We understand why that narrative is attractive, but we think the more important point to focus on in the long term is function. In the Moore’s Law era, Intel went from a PC microprocessor provider to an ecosystem leader spanning the full set of platform functions – data center, networking, wireless, I/O, storage, graphics, security, the whole thing. We believe the AI factory platform is doing something similar, and advantage will confer to the companies that assemble the functions into an integrated architecture, not the companies that sell one component in isolation.
- The migration path we see is “architectural absorption” – preserve deterministic workloads while the AI factory layer grows around them;
- Frontier models help resolve semantic conflicts across systems – but people still do the heavy lifting process by process until agents can take over;
- CPU/GPU ratio headlines are potentially misleading when utilization is single digits – the platform opportunity is to drive utilization toward ~40% across the system;
- The market is keying off CPU narratives today while the real story is platform functions – who owns the integrated architecture is what matters most in our view.
The bottom line is x86 remains the enterprise substrate for some time, but it will increasingly live inside the AI factory architecture rather than standing apart from it. That’s the point of the absorption bridge. It gives enterprises a way to modernize without breaking everything, and it positions the winners around end-to-end platform function.
x86 functions get rebuilt inside the AI factory
Our next slide shows how we make the pivot from general purpose to accelerated computing. The path goes through what actually matters – i.e. functions. The x86 won the day and became the control point for enterprise execution, storage, databases, recovery, security, and management. Our view is that the AI factory has to reimplement those functions differently, using a hybrid execution model across GPU / CPU / DPU rather than treating the CPU as the sole point of control.

The key idea is that x86 became the control plane for the enterprise stack. It orchestrated storage, ran databases, coordinated recovery, and underpinned security and management – especially in mission critical environments. That’s why the slide below calls out each function explicitly and maps it to what it becomes in an AI factory – i.e. hybrid execution across GPU/CPU/DPU, integrated context memory plus a parallel data layer, a real-time semantic truth substrate, recovery that includes semantic state reconstruction, security that spans code/data/APIs, and an AI factory control plane with autonomous operations.
- Execution moves to hybrid GPU / CPU / DPU execution;
- Storage becomes integrated context memory plus a parallel data layer;
- Databases move toward a real-time semantic truth substrate;
- Recovery becomes semantic state reconstruction vs a restart;
- Security becomes continuous across code, data, and APIs;
- Management becomes an AI factory control plane plus automated operations.
The implication is that this is a rebuild of the enterprise platform layer around new bottlenecks and new physics – network speeds that outstrip what traditional x86 buses can manage, storage and database behaviors that must become more parallel and more semantic, and security that has to span everything because adversaries will use frontier models and agents too. We believe this is why the AI factory becomes the front line of the business. Once companies run revenue workflows on it, resilience and operational control become existential.
Networking becomes the system fabric
Mellanox belongs on the Mount Rushmore of strategic acquisitions in enterprise computing. VMware-EMC (virtualization era), Amazon-Annapurna, IBM-PwC (services pivot), IBM-Red Hat (open source), Oracle-Sun (hardware + software integration). Our view is Mellanox stacks up against all of them because it more than an adjacency play or a TAM expansion move. It was the missing piece Nvidia needed to make AI at scale work and create a new computing paradigm.
Nvidia paid about $7B for Mellanox. Today, networking is a core value chain component – the company’s networking business is running at a roughly $40B–$45B run rate inside a firm with a ~$5T market cap. Put differently, without networking, there isn’t an “Nvidia as we know it today.” The key insight was that AI factories can’t scale on traditional networks connected to servers approach. They require a new networking model that becomes the execution fabric for distributed memory, inference, storage, and recovery.
The slide below lays out how Nvidia turned networking into a system fabric – and then extended it:
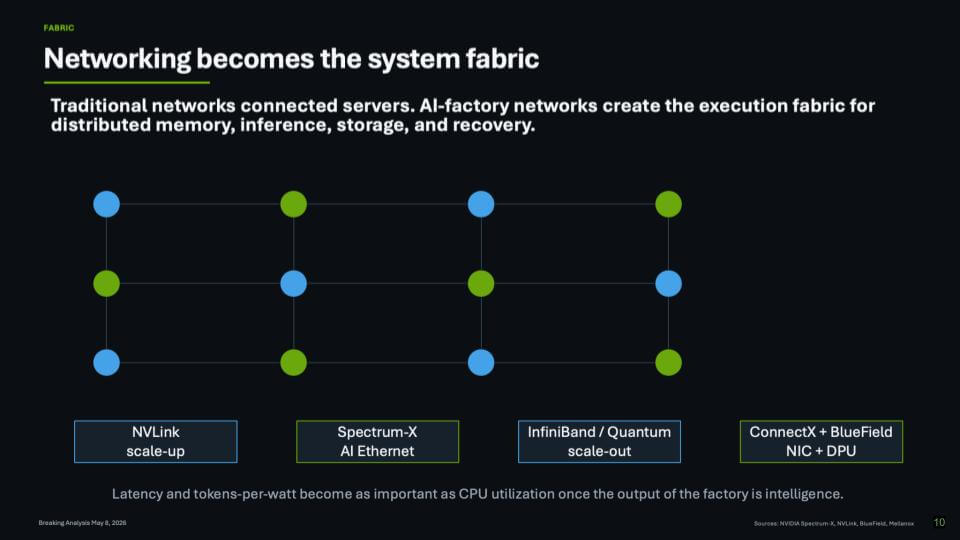
- NVLink scale-up – the rack-scale domain where the system behaves like one machine;
- InfiniBand / Quantum scale-out – the clustering backbone for large distributed systems;
- Spectrum-X AI Ethernet – purpose-built Ethernet tuned for AI, supporting scale-out and scale-across;
- ConnectX + BlueField – NIC + DPU as a control and offload layer that pulls storage and security closer to the fabric.
That’s why Mellanox became the foundation that made the AI factory viable as a platform. Once you’re connecting hundreds of thousands of GPUs and treating them as a single unit, the fabric dictates latency, recoverability, and utilization. Nvidia has been investing heavily across both hardware and software here – and you can feel the effects in the steady stream of improvements around scaling, latency reduction, and operational recovery.
The key point is scale. When you’re wiring up hundreds of thousands of GPUs and trying to run them as a single unit, networking is the foundation. That’s how Nvidia keeps driving down latency, improving recoverability, and sustaining velocity across the whole stack. There’s constant iteration here -small but meaningful improvements in software and capabilities show up continuously, and they accelerate value.
Bottom line – without fabric, there is no AI factory at scale. Mellanox gave Nvidia the networking primitives to turn lots of GPUs into a coherent system, and Spectrum-X plus BlueField extend that advantage into Ethernet-heavy enterprise environments where AI factories will actually get deployed.
Storage becomes context memory
This next slide describes the storage transition in a picture. On the left is the classic x86 storage world -SAN/NAS, object stores, backup tiers – with separate systems and separate teams and a lot of “copy + wait.” On the right is the new AI context layer: GPU-adjacent context memory, KV cache/agent memory, parallel vector + stream data paths, and DPU policy/security/integrity, all optimized for low-latency shared context across the pod.
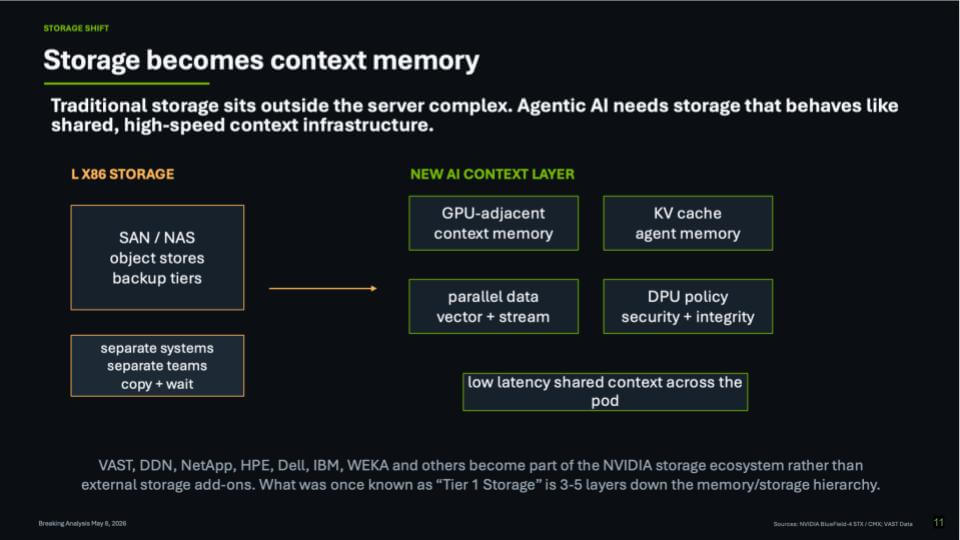
The key point is that what used to be Tier 1 storage (think EMC Symmetrix) is getting pushed down the hierarchy. The storage stack is being redefined around proximity to compute and the need to preserve and reuse context. In this model, storage isn’t a box you attach to servers. It’s a shared, high-speed context infrastructure that keeps the AI factory balanced.
We believe Nvidia’s messaging here is effectively a mandate to the ecosystem. Not in a vendor -arrogance way – in a physics and economics way. If the system is going to run at AI-factory speeds, the old approach of routing data movement and I/O orchestration through the CPU becomes a bottleneck. The new architecture normalizes things like RDMA and direct communication, so the system doesn’t have to bounce through traditional chokepoints.
This is why you see VAST, DDN, WEKA and other HPC-native players well positioned in the middle of the conversation – and why incumbents like Dell are moving with things like Project Lightning. The market is moving them to new requirements: Low latency + parallelism + policy baked into the data path. It also puts pressure on x86-era interfaces (PCIe-centric thinking) as the fabric takes over more of the movement and coordination.
- Key points:
- Storage in the AI factory era behaves like context memory – it’s designed around KV cache, agent memory, and low-latency sharing across the pod;
- RDMA and direct paths become the norm, not the exception – because going “through” the CPU/GPU for everything doesn’t scale;
- The ecosystem is being pulled into Nvidia’s reference model: partners don’t get to ignore the new hierarchy if they want relevance.
Bottom line: The storage stack is being repositioned as part of the AI factory’s context and data plane, not an external add-on box. That shift is creating new opportunities and forcing fast adaptation; pushing classic Tier 1 further down the hierarchy beneath HBM, SRAM, DRAM, low power memories and KV cache.
Data platforms become the real-time truth layer
The next slide emphasizes the “don’t forget the data” message. Nvidia’s five-layer cake is compelling, but it lacks a data. component. Without a data layer the enterprise can’t get to agentic outcomes that are reliable. The modern data stack – the warehouse and lakehouse era, defined by Snowflake and BigQuery – delivered better analytics, but it largely delivered a historical lookback version of truth. The enterprise runs in real time. And as long as operational systems remain siloed, a single source of truth remains aspirational because humans are still reconciling semantics across departments.
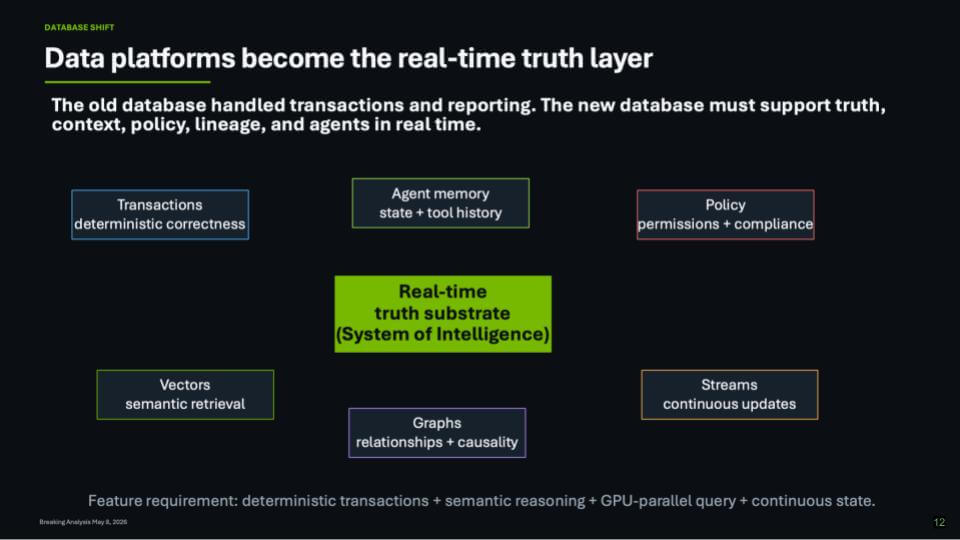
The change we believe is required is a real-time truth substrate – a system of intelligence (SoI)- that sits above systems of record and analytics. It becomes the high-value layer in the new AI software stack. This is where the enterprise digital twin starts to become practical in the form of a real-time representation of people, places, assets, and processes that agents can reason over and act on with confidence. In this view, the database and data platform stop being transactions plus reporting, and become a live coordination layer that blends deterministic correctness with the context agents need.
A few elements on the slide are noteworthy:
- Transactions remain table stakes – deterministic correctness still matters;
- Vectors, graphs, and streams move into the core – semantic retrieval, relationships/causality, and continuous updates;
- Policy becomes inseparable from data – permissions and compliance live in the truth layer, not bolted on later;
- Agent memory becomes first-class – state and tool history have to persist so agents can operate safely and repeatedly.
Underneath the frontier models, the value comes from the full stack of APIs, toolsets, and workflows that connect models to enterprise systems. The system of intelligence (SoI) is where the enterprise maps itself onto that new platform with semantic resolution, compliance, security, and agent development. That is why we think this layer becomes the heart of the transition – it’s the only way to move from “what happened” and “why did it happen” toward “what’s likely to happen next” and “what should we do now” with a next-best-action posture.
Bottom line: The enterprise doesn’t get sustainable agentic value from “LLM + vector DB” alone. It gets there by building a real-time truth layer that can harmonize semantics across silos, maintain continuous state, enforce policy, and feed both humans and agents with decision-grade context in real time.
Recovery becomes semantic reconstruction
Recovery is a tell. When vendors come in to see us with analyst briefings, the fastest way to expose the real architecture is to ask “walk me through exactly how you recover when something goes wrong?” In the AI factory era, “restart the system” is not straightforward recovery sequence. The platform has to restore state – not only physical uptime, but the last valid reasoning state – and do it in a way that lets the business resume safely.
This slide below lays out why recovery now spans multiple layers that used to be handled in isolation. We’re dealing with failures that range from a rack going down to an agent failing mid-task. The recovery capability has to be a combination of existing x86 disciplines and the new controls and instrumentation that come with the Intel – Nvidia absorption path. The shift is that the platform can treat recovery as a system problem across the company, not just a database problem inside one application.

Key elements of recovery that now have to come back together – in order – are:
- Physical / rack state – power, cooling, network, GPU health;
- Database state – transactions, lineage, time ordering;
- Index + context state – vector indexes, KV cache, context memory;
- Agent state – plans, tool calls, intermediate outputs;
- Human approval state – permissions, signoffs, escalation path.
The point is that recovery now has to preserve both the operational state and the semantic state. If the platform can’t answer “what did the agent know, what did it touch, what policy constrained it, and what state is safe to resume,” then the organization ends up back where it started – humans doing manual recovery and reconciliation, with delayed truth and high coordination cost.
Bottom line: In our view, recovery becomes one of the defining requirements of the AI factory platform. It forces the stack to be engineered as a full system – hardware, data, context, agents, and approvals – because that’s the only way to restore confidence and keep the business running when the inevitable failures occur.
Frontier Models Become the Migration Engine
The most important implication of the AI factory is that frontier models become a new migration engine for the enterprise. They will crawl through codebases, database schemas, APIs, workflow engines, logs, tickets, documents and human procedures to infer how the business actually operates – not how the architecture diagrams claim it operates.
This is the breakthrough. For decades, enterprises have lived with an application jungle in which ERP, CRM, finance, supply chain, HR, security, analytics and industry-specific systems each carry their own definitions of customers, products, transactions, approvals, exceptions and truth. The integration layer has largely been human. People reconcile meanings, interpret exceptions, approve workarounds, chase tickets and recover from failures. The AI factory thesis changes that equation by putting frontier models in the middle of this mess and asking them to inspect, map, diagnose, integrate, operate and improve the enterprise continuously.
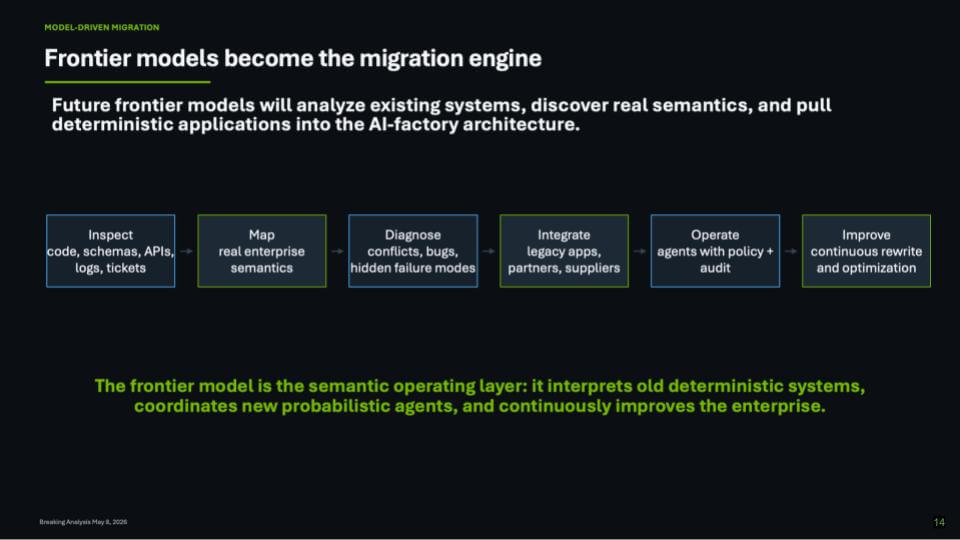
In our view, this is why the phrase “migration engine” is powerful but incomplete. Yes, frontier models will help migrate legacy systems into the AI factory architecture. But migration is only the first act. Once the model understands the code, the data, the workflows and the human procedures, it becomes a semantic operating layer for the enterprise.
A migration engine implies a project with a beginning and an end. A semantic operating layer implies a persistent system that interprets old deterministic applications, coordinates new probabilistic agents, enforces policy and continuously improves the business. The slide above frames this directly. Frontier models inspect code, schemas, APIs, logs and tickets; map real enterprise semantics; diagnose conflicts and hidden failures; integrate legacy systems; operate agents with policy and audit; and improve through continuous rewrite and optimization.
Some experts use the phrase “enterprise nervous system,” which is appealing because it captures the biological metaphor and signals moving across the organization, sensing anomalies, coordinating responses and learning from feedback. But it overstates where the market is today. Enterprises are not yet ready to trust a frontier model as the nervous system of the company. They are, however, ready to use these models to discover semantics, assist migration, automate integration and operate governed agents in bounded domains.
Frontier models start as the migration engine, mature into the semantic operating layer, and over time become the enterprise nervous system.
That progression gives the argument more credibility and acknowledges that this will take a decade to unfold. It also acknowledges the immediate use case – modernization and migration – while pointing to the larger architectural shift. The strategic bottom line is that Nvidia’s AI factory platform is not just a faster compute substrate. It is the infrastructure foundation for a new enterprise control plane, where frontier models turn fragmented deterministic systems into a continuously improving, semantically coherent operating environment.
Security and governance in the AI factory
This next slide focuses on a point that tends to get underweighted in the bubble cycle. Specifically, when intelligence becomes operational, security becomes an operating problem. We’ve heard it directly from security operators like Nir Zuk’s comment that the “last 1%” humans used to mop up is no longer manageable when adversaries can scale with AI. In our opinion, that’s the right setup for governance in the AI era, because the attacker’s advantage grows with automation – both outside the enterprise and inside it.
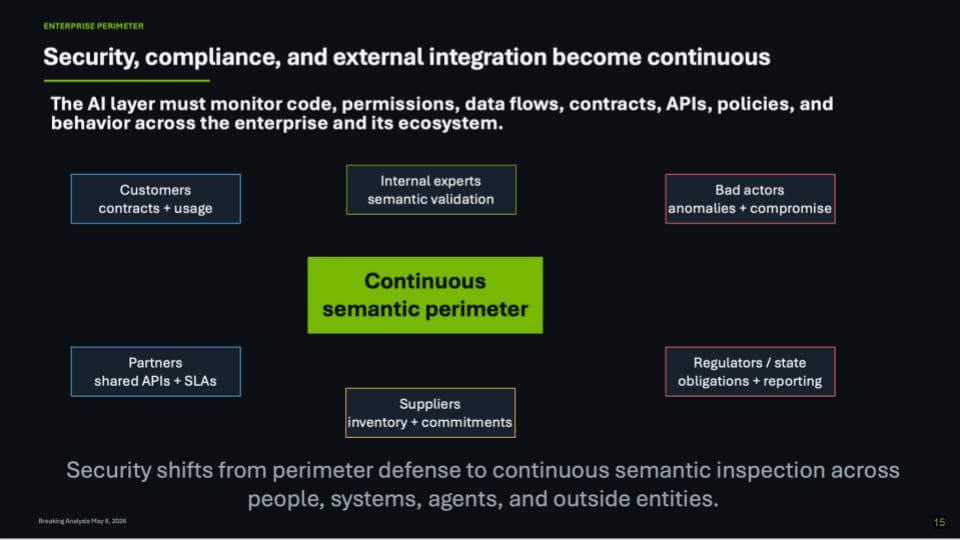
Our view is governance has to live inside the system, not in a separate manual process. As organizations move toward agentic workflows, the ability for black hats and insiders to do damage increases. That makes monitoring the changes that are being made a core capability. The platform has to watch what the system is doing as it evolves – e.g. what it’s touching, what it’s changing, what it’s attempting, and what signals indicate the system is drifting into an unsafe state.
- The security surface expands because the system changes faster – more actions, more tool calls, more state updates, more opportunities to introduce badness;
- Governance becomes continuous monitoring of change – catching the risky deltas, highlighting anomalies, and enforcing the boundaries that make the system safe to operate;
- A likely operating reality is a “model running the model” – one model managing day-to-day operations while governance checks the changes being made and flags what could go wrong.
The takeaway is the AI factory can’t rely on yesterday’s security assumptions. As automation scales, governance becomes part of the operating system – monitoring change, constraining action, and reducing the blast radius when something inevitably goes sideways.
The New Cloud Is Distributed, Sovereign and Federated
The cloud conversation is changing. For the past decade, the industry framed cloud largely as a destination to move workloads to hyperscale platforms, consume elastic infrastructure, and let centralized services handle scale. But in the AI era, we believe that model is morphing. AI factories will not live only in centralized public clouds. They will emerge as distributed systems spanning hyperscale regions, enterprise data centers, telco and regional facilities, industrial edge locations, sovereign sites, and defense or national infrastructure.
The reason is AI brings compute to where the data, power, latency, policy and sovereignty requirements live. As AI becomes more deeply embedded in business processes and national infrastructure, organizations will increasingly need local execution with global learning. That is the architectural shift represented in this slide.
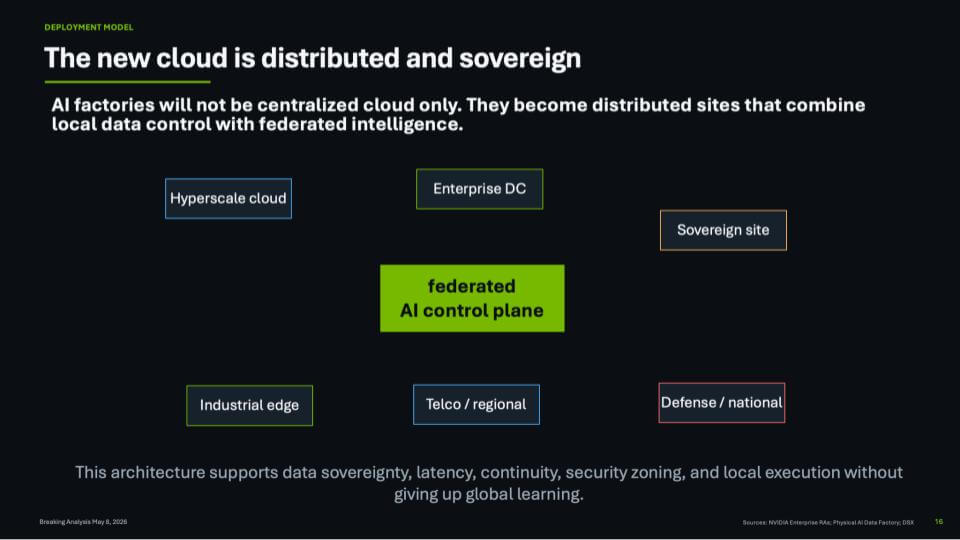
At the center of this evolution is the need for a federated AI control plane. In our view, this becomes a critical abstraction layer that allows work to move across different AI factory nodes while preserving policy, security, availability and data control. This is not simply hybrid cloud with a new label. It is a distributed AI operating model.
Several forces are driving this transition:
- Sovereignty is no longer just a geopolitical issue. Governments clearly want national control over AI infrastructure and data. But regulated industries – financial services, healthcare, energy, defense, telecommunications and critical infrastructure – also want sovereign-like control over their AI stacks.
- Latency and locality. AI workloads that depend on real-time operational data, industrial systems, edge devices or regulated records cannot always ship data back to a centralized cloud region.
- Continuity and resilience require distributed execution. If power, network access or regional availability is constrained in one location, the system must be able to shift work, recover state, and preserve operational continuity.
- Data movement must become more selective. The future is not about moving all data everywhere. It is about moving the right metadata, model updates, embeddings, policies, small state objects and recovery artifacts so that distributed systems can learn globally while operating locally.
- Networking becomes foundational, but insufficient. High-performance, secure networking is essential. But the architecture also requires orchestration, recovery, security zoning, policy enforcement, workload placement and lifecycle management across locations.
This is why the notion of a single cloud becomes less useful. The new cloud is a distributed fabric. It combines centralized scale with local control. It allows enterprises and governments to place AI where it belongs — sometimes in hyperscale cloud, sometimes on-premises, sometimes at the edge, sometimes in a sovereign national environment — while still participating in a broader federated intelligence system.
The key point is that AI factories will not be monolithic. They will be networked. They will operate across multiple control domains. They will need to support local compliance and execution without sacrificing global optimization. In our view, that is the next phase of cloud, not cloud as a place, but cloud as a federated AI operating model.
AI Economics: CapEx, token costs and scaling without labor
The economic case for AI factories is more than GPUs or refresh legacy x86 infrastructure. The deeper idea is that AI replaces part of the human coordination layer that sits around fragmented applications, siloed data and brittle business processes. That is why the economics are so intensely debated. The capital intensity is enormous, but so is the potential for a step-function change in productivity.
We believe the next several years will be defined by a difficult but potentially powerful tradeoff where enterprises will spend materially more on AI infrastructure, tokens, platforms and automation, but over time they will reduce the labor required to reconcile, interpret, approve, integrate, monitor, recover and manage exceptions across the business. In other words, the enterprise will shift spending from human glue to machine-mediated coordination.
The slide below captures that operating model shift. On the left, capital expands. AI factory CapEx sits on top of the traditional infrastructure refresh cycle. This is a major step up in spend. It is a new layer of capital required to build the systems that manufacture, orchestrate and operationalize intelligence. That includes accelerated compute, networking, storage, software, energy, cooling, data pipelines and model infrastructure.
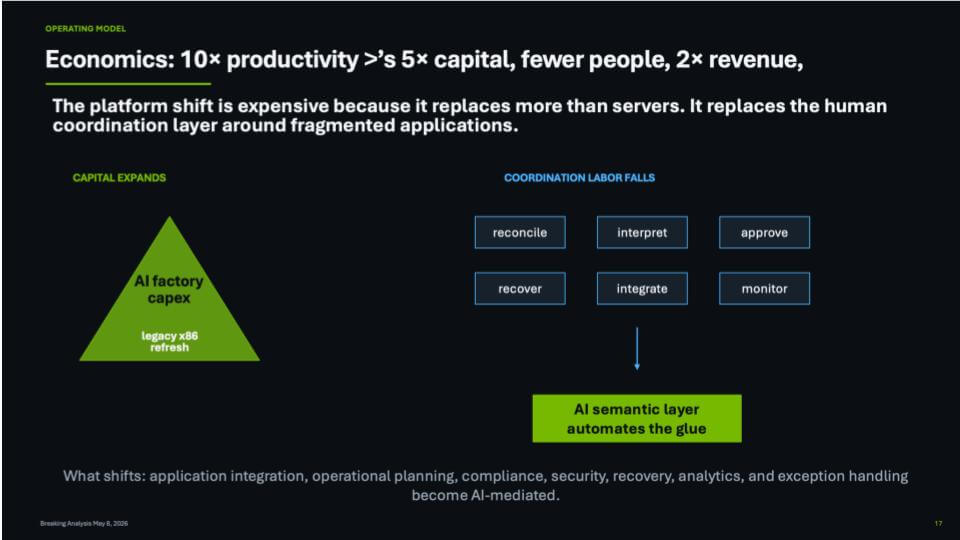
But the right side of the slide is where the business impact shows up. Today, too much enterprise work is coordination work:
- Reconciling conflicting records across systems;
- Interpreting reports, logs, policies and exceptions;
- Approving workflows that cross application boundaries;
- Integrating data and processes after the fact;
- Monitoring operations manually;
- Recovering from outages, errors or compliance gaps.
The promise of the AI semantic layer is that more of this work becomes automated, mediated or accelerated by AI. Not all of it disappears. But the role of people changes. Human labor moves away from repetitive coordination and toward judgment, oversight, exception management and new value creation.
That is where the productivity argument comes in. The 10x number is not meant to be a precise forecast for every company in every industry. It is a directional model for what the best AI-native or AI-reengineered organizations will target over a three- to five-year horizon. Newer companies are already showing dramatically higher revenue per employee than traditional enterprises. The question is whether incumbents can use AI to bend their own productivity curves in a similar direction.
This is why the AI business case cannot be judged only by near-term infrastructure cost. The payback curve will take time. In prior analysis, we modeled a long crossover period because the industry must absorb enormous upfront capital commitments before the productivity dividend fully pays back. The CapEx is felt immediately. The labor and revenue benefit arrive more gradually.
But once that operating model takes hold, the effect could be profound. Better services, faster execution, lower unit costs and more intelligent operations should increase demand and expand revenue capacity. In that scenario, a company may be able to double revenue without doubling headcount – and in some cases with far fewer people than its legacy operating model required.
The key point is that AI factories are expensive because they replace more than servers. They replace the manual coordination fabric of the enterprise. Application integration, operational planning, compliance, security, recovery, analytics and exception handling all become increasingly AI-mediated. That is the real business imperative behind the migration to this new platform.
In our view, the companies that win will not be the ones that merely spend the most on AI. They will be the ones that convert AI CapEx into a new productivity architecture – one where capital intensity is offset by lower coordination costs, faster scaling and materially higher revenue per employee.
NVIDIA’s AI Factory Roadmap: From Accelerated Compute to AI-Native Enterprise Architecture
The final question is how long it takes for the AI factory architecture to absorb the major functions of the x86-era enterprise. That is the roadmap captured in this slide below. NVIDIA’s platform becomes truly dominant only when the AI factory is not merely a training and inference machine, but the operating foundation for enterprise computing.

In our view, this transition will take the better part of a decade. It will not happen all at once. It will unfold as a sequence with compute first, then networking fabric, then context storage, then x86 integration, then semantic databases, recovery and ultimately unified operations. Each stage expands what the AI factory can absorb from the traditional enterprise stack.
The early phases are already underway. Rack-scale GPU systems are moving the industry from the server as the unit of computing to the rack as the unit of computing. NVIDIA’s networking and DPU fabric extends that model by offloading more network, storage and security functions into an accelerated infrastructure layer. These are the foundational pieces. They are in market today and will continue improving through hardware and software iteration.
The next layer is context storage. Traditional storage was built around files, blocks, objects and databases. AI systems require something different. Specifically, low-latency access to embeddings, key-value memory, agent state, metadata, policies and enterprise context. In other words, storage evolves from a passive repository to an active memory layer for agents and AI workflows.
Then comes the critical enterprise bridge: x86 integration. This is the migration path. The enterprise does not get to rip and replace decades of applications, databases and process logic. The AI factory must absorb and interoperate with the x86 estate. That means compatibility, workload migration, observability, security, policy and operational continuity have to be built into the AI fabric. Without that bridge, the AI factory remains a powerful new island. With it, migration accelerates.
The latter half of the decade is where the architecture becomes more transformative. Real-time semantic databases become the truth layer for agents and applications. These systems will need to take advantage of parallelism, distributed resources and AI-native data structures. The database stops being only a system of record and starts becoming a system of context, reasoning and action.
Semantic recovery is another essential piece. Traditional recovery is about restoring systems, data and application state. AI recovery must go further. It must support the safe resumption of reasoning workflows, agent decisions, context windows, policies, approvals and task state. As more business processes become AI-mediated, recovery becomes semantic, not merely transactional.
Ultimately, the architecture requires a unified control plane. That control plane must span workloads, sites, policies, recovery, data movement and execution environments across hyperscale cloud, enterprise data centers, edge locations and sovereign infrastructure. This is where the AI factory moves from being a compute architecture to becoming an enterprise operating model.
Investment Roadmap and Timing
Each stage builds on the prior one. Compute creates the foundation. Fabric connects and secures it. Context storage feeds it. x86 integration opens the migration path. Semantic databases give agents a real-time truth layer. Recovery makes AI workflows operationally safe. The unified control plane turns the pieces into a platform.
The timing is not overnight. Migration will likely start slowly because enterprises are complex, risk-averse and deeply invested in existing systems. But once the x86 integration layer, context storage and semantic database components mature, the rate of migration could accelerate materially. The likely inflection window is the late 2020s into the early 2030s, when AI-native architectures begin to look less experimental and more like the default model for enterprise operations.
By 2035, companies that have not materially migrated may find themselves operating with a structural disadvantage. Their cost base will be higher. Their coordination labor will be heavier. Their application estates will be more fragmented. Their ability to automate decisions, recover intelligently, govern distributed AI and scale revenue without proportional headcount growth will be constrained.
That is why this roadmap is so important. It reframes Nvidia’s opportunity beyond GPUs. The long-term goal is not just accelerated compute. It is the migration of enterprise computing itself toward an AI-native architecture. In our view, that is the platform battle now underway. It goes beyond training the largest models and relies on an ecosystem to build the operating foundation for the next generation of enterprise management.
Action Item: CXOs should treat AI as a fundamental operating model transition that requires a deliberate roadmap. The immediate mandate is to identify where the enterprise is still held together by human coordination – e.g. reconciling data, interpreting exceptions, approving workflows, integrating systems, monitoring operations and recovering from failures – and begin shifting that work into an AI-mediated semantic layer. That means funding AI factories with discipline, modernizing the application and data estate, building a federated control plane across cloud, on-prem, edge and sovereign environments, and demanding a clear line of sight from AI capital investment to productivity, revenue and resilience outcomes. The endgame is to redesign how your company operates so intelligence becomes embedded in the platform, the process model and the financial model of the business.


