
We believe much of the artificial intelligence industry is chasing the wrong prize. Frontier model vendors, such as Anthropic and OpenAI Group, may have shifted their commercial focus toward enterprise customers, but they’ve not changed their fundamental architecture.
Specifically, they’re still trying to concentrate ever more intelligence inside a generalized model. We agree with Databricks Inc. Chief Executive Ali Ghodsi that the practical definition of artificial general intelligence has actually been achieved. Moving the goalpost to superintelligence — or what we’ve called Messiah AGI in a prior Breaking Analysis — does little to create differentiation for enterprise customers.
The real prize as we see it is what we call enterprise AGI. What do we mean by that? Specifically, we’re talking about intelligence that is unique to and owned by each enterprise.
Enterprise AGI is all about harmonizing proprietary data, business processes, policies and the tacit human knowledge behind decisions without formal processes that we frequently discuss on Breaking Analysis. The idea is to then turn those artifacts into governed assets which can orchestrate the collective activity of humans and agents.
The frontier model is an important ingredient in this equation as part of an ensemble of models, but the enterprise system of intelligence, what we call the SoI — think enterprise ontology or digital twin — is the linchpin of achieving enterprise AGI. This is where true business value is derived for enterprises. This is distinct from “data communism,” a term we’ve introduced before. Data communism is where everyone consumes essentially the same intelligence embedded in the frontier model. Rather, we’re advocates of “data capitalism,” in which each company captures, controls, governs and compounds its own intellectual property.
In this week’s Breaking Analysis, we build on our previous work, discuss the implications of what we heard at Databricks’ Data + AI Summit, and put these findings in the context of our SoI framework.
The Real Prize Is Enterprise AGI
Much of the AI industry is racing toward the wrong finish line. Our opening visual uses George’s Wile E. Coyote metaphor to make the point: Sam Altman races past the enterprise opportunity and off the superintelligence cliff, while Ali Ghodsi and Satya Nadella watch from the edge. The serious version of the joke is that Databricks, Microsoft, Google, AWS, Snowflake, Palantir, SAP, Salesforce, Celonis, and RelationalAI and other enterprise platforms are running a different race entirely — one centered on building the system of intelligence layer that turns a company into a working model that coordinates humans and agents.
Key Points
- The pivot is commercial, not architectural — the industry has turned toward enterprise buyers, but frontier vendors are still building ever-smarter generalized models instead of changing the underlying approach.
- Enterprise AGI is an asset problem, not a bigger model — the prize is turning proprietary data, business processes and tacit knowledge into governed assets that models can reason over and agents can act on. That system of intelligence is the linchpin because it captures how one specific enterprise actually works.
- The whole field is converging — Databricks, Microsoft, Snowflake, Google, AWS, Palantir, Salesforce, SAP and others are approaching the same prize from different starting points.
- What this episode covers — Databricks’ latest announcements, especially Genie Ontology, as a lens on where the market is heading and what is still missing.
For several years the dominant narrative ran from AGI to superintelligence — what we’ve called Messiah AGI. In our view that race has already passed the point of practical enterprise relevance. The real economic prize is not generalized intelligence in the abstract; it is Enterprise AGI.
Pivoting commercially is not the same as pivoting architecturally. Many frontier vendors have moved to the enterprise because that is where the money is, but selling smarter models into companies is not the same as building enterprise intelligence. The labs are still concentrating intelligence inside the model; Enterprise AGI instead requires capturing a company’s proprietary data, processes and tacit knowledge as governed assets that models can reason over and agents can act upon.
Those assets become both the context and the control plane for AI. Traditional enterprise vendors and modern data platforms increasingly see that durable advantage comes from turning data, processes and institutional knowledge into assets agents can reason over — acting within enterprise-specific constraints and coordinating with humans toward collective outcomes. Neither siloed agents nor siloed applications can do this.
Palantir pioneered much of this hard work, connecting proprietary data, operational processes and domain knowledge into a model of how an enterprise runs. Now the field is converging on this SoI or context layer from every direction: frontier labs will likely extend their harnesses to accommodate shared organizational memory and state, cornerstone SaaS vendors are building data clouds with built-in process definitions, hyperscalers are building knowledge graphs or ontologies, and data platforms such as Databricks and Snowflake are trying to turn governed data foundations into systems of intelligence.
Key Takeaway: The enterprise AI prize will not be won by generalized intelligence alone. It will go to platforms that convert each enterprise’s proprietary data, processes and tacit knowledge into a system of intelligence that agents can reason over and act through.
Approach #1: Data Communism
The first approach to enterprise intelligence is what we call data communism — and we think it falls short. The visual pairs the frontier-model worldview with a Marxian metaphor: the world’s smartest people contribute reasoning traces to frontier models, and the resulting intelligence is packaged into the model and redistributed to everyone. The promise is a powerful common intelligence layer. The problem is that everyone gets essentially the same built-in intelligence.

Key Points
- Training data is getting more specialized — the first generation of models learned from the public web; the next phase needs expensive, narrow reasoning traces from expert work, such as how an investment-banking analyst values an acquisition.
- Once bottled, that knowledge is shared with everyone — those traces improve the model for all customers, producing a common capability layer rather than enterprise-specific differentiation.
- Common intelligence is not advantage — the Enterprise AGI prize requires intelligence particular to each enterprise, grounded in its own data, processes and tacit knowledge.
A frontier model can be extraordinarily capable and still not understand how a specific enterprise operates. It may know general finance, sales, software engineering, healthcare workflows and support patterns — but general intelligence is not the same as specific enterprise intelligence.
The next frontier of training data is far more specialized. Early models absorbed enormous amounts of public-web knowledge, which produced strong general-purpose capability. Pushing deeper into enterprise use cases requires reasoning traces from expert work. Valuing an acquisition, for instance, takes more than generic financial knowledge — it takes the analyst’s workflow, assumptions, judgment calls, data sources and preferred outputs. The same holds across underwriting, supply-chain planning, fraud investigation, clinical operations and procurement.
But here is the catch: once that knowledge is bottled into the model, it becomes a shared capability. It may make the model smarter for everyone, yet it creates no proprietary advantage for any single enterprise. The model improves; the enterprise does not necessarily become more differentiated.
The distinction is renting versus owning. Frontier models supply generalized reasoning, but Enterprise AGI requires each company to capture its own operating knowledge as data and treat it as a governed, reusable, compounding asset. Data communism lifts the floor for everyone; it does not raise the ceiling for anyone. The real prize is a system that learns how each enterprise actually works.
Key Takeaway: Data communism creates a common intelligence layer, but common intelligence is not competitive advantage. Enterprise AGI requires each organization to turn its own data, processes and tacit knowledge into proprietary intelligence assets.
Approach #2: Data Capitalism – Enterprise Intelligence as a Proprietary Asset
Data capitalism is the alternative to data communism — and the architecture we believe wins. Frontier models stay fundamental, but generalized intelligence will be widely available; the differentiator is the intelligence particular to each enterprise — its proprietary data, processes, policies, tacit knowledge and operating model. The stack shows how those assets flow up from data platforms and systems of record into a system of intelligence, then into systems of agency and engagement.
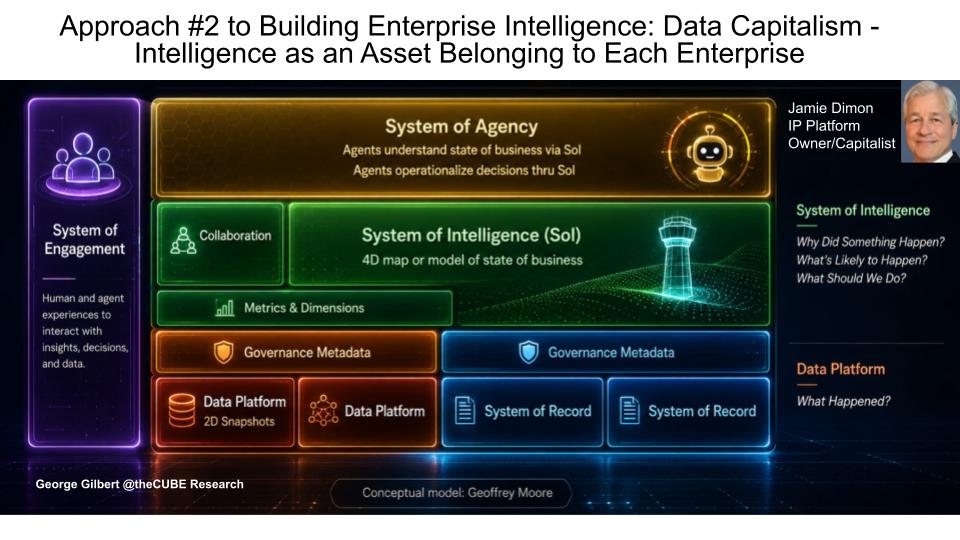
Key Points
- Advantage comes from what’s unique, not what’s shared — generalized intelligence raises the floor for everyone; durable advantage comes from proprietary data, processes, corporate rules and tacit knowledge.
- The system of intelligence is the critical layer — it is the digital representation of how the enterprise actually operates. Where data platforms and systems of record tell you what happened, the system of intelligence explains why it happened, what is likely to happen and what to do next.
- Agency and engagement sit on either side of it — the system of agency lets agents act through that intelligence rather than around it, while the system of engagement becomes the new work surface where people, agents, intent and outcomes meet. The two must be co-designed: the client teaches the back end and the back end improves the client.
- It reorganizes the firm — the next era of enterprise scale will be organized around intelligence as a governed corporate asset, not only around physical assets or labor hierarchies.
The source of advantage moves to what is unique. Frontier models remain fundamental — generalized reasoning, language, code generation and multimodal capability, all increasingly powerful. But if that capability is broadly available, it cannot be the basis of sustainable differentiation. Advantage remains with a company’s customers, products, workflows, operating rules, institutional memory, regulatory constraints, decision rights and culture.
Data platforms and systems of record tell you what happened; they do not explain the business. They store transactions, events, records and snapshots, but they do not know why something happened, what is likely to happen next or what action to take.
That is the role of the system of intelligence — a live, digital representation of the state of the business. It connects governed data with business meaning, metrics, policies, processes, relationships and tacit knowledge. In the industrial age, companies organized around physical assets — railroads, warehouses, factories, assembly lines. In the AI age, we believe they will organize around intelligence assets: the modeled representation of how the enterprise actually works.
This is why the management analogy matters. The popular image of a billion-dollar company run by one person and an army of agents captures individual productivity but misses the organizational opportunity. Grounded in a system of intelligence, humans and agents gain a substrate that supports planning, control, coordination, resource allocation — the core functions of management. This points toward larger, more complex forms of economic organization, not merely smaller teams; the lesson of Amazon is that scale advantage comes from an operating platform that lets employees, suppliers, and partners coordinate across many domains.
Agents should act through the system of intelligence, not around it. Above the intelligence layer, the system of agency is where agents answer questions, weigh options, plan and operationalize decisions — within the rules, constraints, metrics and trusted data the intelligence layer provides. Beside it, the system of engagement is where users express intent, resolve ambiguity and approve actions, and where the language, questions and corrections that teach the system of intelligence are captured. The two reinforce each other: the system of engagement collects intent and behavioral signals, the intelligence layer turns them into governed context, and the agency layer acts with growing confidence on a richer model of the enterprise.
The hardest design choice is top-down versus bottom-up. A purely top-down enterprise model can take so long to build that it is obsolete on arrival; a purely bottom-up model learns fast from users and queries but risks silos and inconsistency. The most promising architecture does both — inferring what it can from the bottom up, governing what must be standardized from the top down, and continuously reconciling the two.
So data capitalism is not really about owning data; it is about owning the intelligence production system. Enterprises build advantage by turning proprietary data, processes and tacit knowledge into governed, reusable, compounding assets — and the more those assets are used and connected to decisions, the more valuable they become.
Key Takeaway: Data capitalism treats enterprise knowledge as a proprietary asset. The system of intelligence becomes the new organizing layer of the firm.
Databricks Moves Up the Enterprise Intelligence Stack
Databricks’ real story at its Data + AI Summit was architectural, not the product list. The slide maps our enterprise intelligence framework onto the Databricks stack. Behind a laundry list of announcements (to 30,000-plus attendees), the company is moving up from data infrastructure into the higher-value layers of the emerging AI stack: engagement, intelligence and agency. Genie is the agentic client layer, Genie Ontology is the emerging intelligent back end, and Agent Bricks plus Unity AI Gateway support building, operationalizing and governing agentic work.
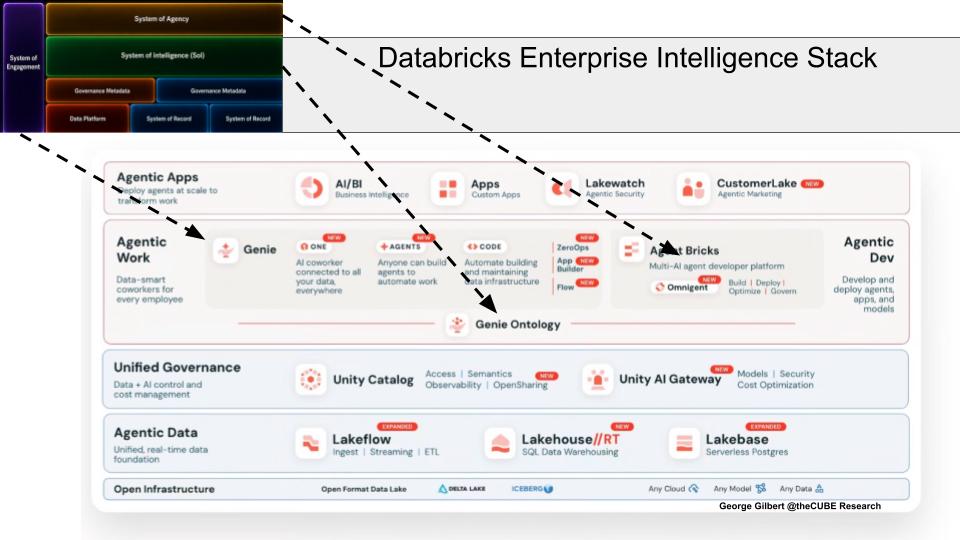
Key Points
- Databricks is climbing the stack — no longer positioning only as data infrastructure, it is moving up into the engagement, intelligence and agency layers where value is concentrating.
- Engagement is the Genie family — Genie One anchors business users in governed data, dashboards and apps, while role-specific Genies (Code, ZeroOps, Agents, App Builder, Flow) understand the Databricks environment and operate with less supervision.
- Intelligence is Genie Ontology; agency is Agent Bricks and AI Gateway — the ontology sits in the middle as the emerging map of enterprise data and meaning, building on Unity Catalog, while Agent Bricks and Unity AI Gateway form the agency layer. Omnigent connects 3rd party agentic clients to AI Gateway.
- The open question is whether it closes the loop — the data layer increasingly looks like infrastructure and the new platform is the ontology or digital twin, but that only pays off if these pieces reinforce one another by learning from users, apps, governed data and agent activity.
This climb is not unique to Databricks. Snowflake is making a similar move, though Databricks’ vision looks more comprehensive. Modern data platforms recognize that infrastructure, while necessary, is not sufficient: the higher-value play is turning governed data into business context and that context into agentic action — which takes a front end where users express intent, an intelligent back end that understands enterprise meaning and a governance fabric over how agents act.
Engagement is represented by Genie One and the wider family of Genies. Genie One, the business-user client, is less a dashboarding tool than a data-aware coworker connecting users to dashboards, apps, Genie Spaces, tables and governed metrics — and because it is anchored in business data, the interface itself becomes a source of signal about how people ask, clarify and consume. Databricks is extending the pattern to other roles: Code, ZeroOps, Agents, App Builder and Flow are tuned around the Databricks world, so they understand its assets and workflows and need less hand-holding than generic tools.
That role-specific design is a clue to the broader Enterprise AGI architecture. Just as Databricks can post-train agents on its own environment, an enterprise can build its own system of intelligence so its own agents, either out-of-the-box or post-trained, can understand the company’s environment. The enterprise needs a map — its data, entities, relationships, policies, metrics and workflows — and that is where Genie Ontology becomes strategically important.
Genie Ontology runs through the middle of the stack as the intelligence layer, with the system of agency above it. In our framework the system of intelligence is the map of the enterprise: it lets agentic clients navigate business context and lets agents act with confidence. Today Genie Ontology is an early step toward a digital twin — a set of definitions, not a complete operational model, but a deliberate move toward a governed representation of enterprise data and meaning. Above it, Agent Bricks is becoming a platform to build, deploy, optimize and govern agents; Omnigent connects external clients and coding assistants into Databricks governance; and Unity Catalog and Unity AI Gateway provide the policy, access control, routing, model governance, tracing and cost controls that expanding agentic workloads require.
This is where the stack comes together. The intelligence layer provides the map, the Genies use it to help users work with enterprise context, Agent Bricks builds agents that make and operationalize decisions, and Unity governs what is allowed. The more these layers reinforce one another, the more Databricks moves from data platform to enterprise intelligence platform.
Key Questions Remain
Three open questions will decide how far this goes:
- How deeply are engagement and intelligence co-designed? The client should not just query the ontology; it should teach it. Questions, corrections, clarifications and accepted-or-rejected answers can improve the enterprise map — a loop that is far stronger when Databricks controls the client experience and gets murkier when third-party clients sit in front of the back end.
- How far can Genie Ontology evolve? Today it is strongest as a semantic and contextual layer over governed data. Enterprise AGI needs more: a governed, executable model of how the business operates, including actions, preconditions, effects, policies, workflows and live state. Databricks has the ingredients, but the full system of intelligence is still emerging.
- Where does the value line get drawn? Databricks and others are making data formats and infrastructure less visible — encouraging, as Ryan Blue’s on-stage banter with Ali Ghodsi during the day-1 keynote suggested. Customers shouldn’t have to care whether the format is Delta or Iceberg. But that is still an aspirational state. That will pushe data infrastructure toward hardware economics — necessary, powerful, increasingly standardized — while the differentiating platform becomes the ontology or digital twin and the applications on top become agents.
This is the strategic leap Databricks is attempting — turning its governed data foundation into an enterprise intelligence platform and using agents as the application layer above it. If it works, Databricks won’t just help enterprises store, govern and analyze data; it will help them model how the business works and let humans and agents act through that model.
Key Takeaway: Databricks is trying to move from data platform to enterprise intelligence platform. The critical test is whether Genie, Genie Ontology, Agent Bricks and Unity governance become a self-reinforcing system that learns how each enterprise operates and uses that knowledge into to support coordinated action by humans and agents.
Genie One – The Agentic Client for Business Users
Genie One is Databricks’ bid to own the engagement layer, not just modernize BI. This slide zooms in on the system of engagement. Genie One is the business-user agentic client — a data-smart coworker that brings dashboards, Genie Spaces, apps and governed data into a common experience. It may look like a new analytic workspace, but the intent is deeper: this is where business users express intent, ask questions, clarify ambiguity and create the signals that make the intelligent back end smarter.
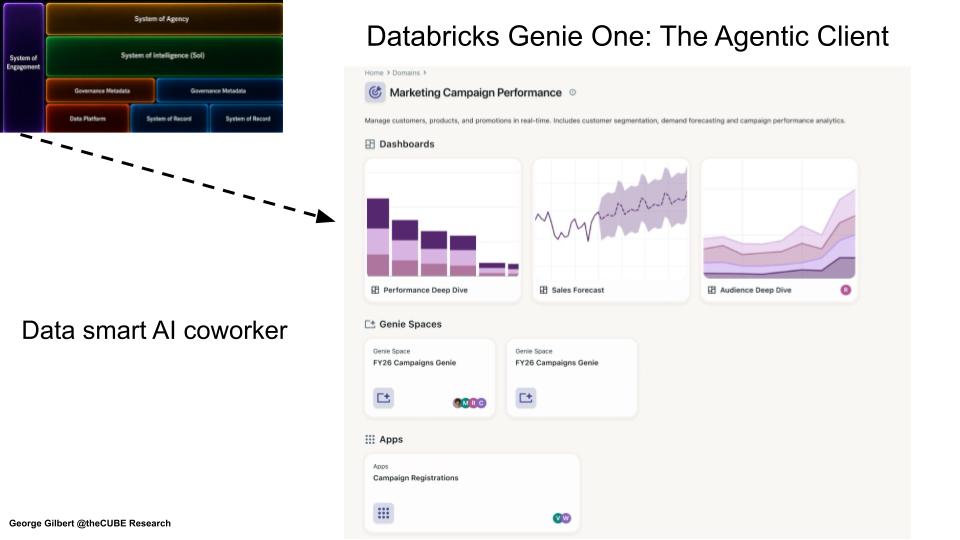
Key Points
- A coworker, not a dashboard — Genie One is the business-user front door, pulling dashboards, Genie Spaces, apps, governed tables, metrics, notebooks and queries into one data-aware workspace.
- Expanding from native to messy — the initial focus is native Databricks assets, but the ambition reaches external files, documents, unstructured content and SaaS data, where connectors grant access but the hard part is mapping meaning.
- Ground truth is the edge — grounding in trusted “gold” data gives the ontology an authoritative anchor to connect everything else to.
- Owning the client is the strategic point — user questions, corrections and clarifications teach the system of intelligence, so whoever owns the work surface captures a critical signal.
Genie One is best understood as the business-user work surface, not a better BI tool. A year ago Genie mostly fetched dashboards; now it brings together AI/BI dashboards, Genie Spaces, Databricks Apps, governed tables and datasets, metrics and semantic objects, notebooks and queries — moving from a dashboard front end toward an intelligent workspace where intent, context and feedback are captured.
The next phase reaches beyond native Databricks assets. Genie One is being connected to local files in Genie Spaces (Excel, CSV) blended with Unity Catalog data, to documents and unstructured content from SharePoint, Google Drive, Confluence and Glean, and to more than 80 connectors across CRM, support, productivity and file storage. But connectors are only the first step; the hard part is mapping meaning — knowing that “customer” in one system is “account” in another, or that a revenue metric must be computed consistently across systems.
Databricks’ potential edge here is ground truth. Because it starts from governed, verified “gold” data, the ontology has an authoritative anchor to connect other assets to — otherwise the hardest part of building an enterprise graph.
The deeper point is that Genie One is a learning surface, not just a front end. Every query, accepted or rejected answer, clarification and correction can feed the intelligent back end (a loop we examine later). The enterprise doesn’t need a chatbot over dashboards; it needs a client that learns the company’s language, assets, definitions and workflows. How far Genie One gets will depend on how well it expands from clean analytic assets into the messier world of files, documents and SaaS.
Key Takeaway: Genie One is more than a business-user interface. It is Databricks’ attempt to own the engagement layer where enterprise intent is captured and fed back into the system of intelligence. Its long-term value depends on turning user interaction into governed enterprise context.
Databricks’ Many Genies – Role-Specific Coworkers Built on a Shared Enterprise Map
Genie One is the front door; the broader bet is a data-smart coworker for every role. This graphic expands the Genie concept beyond business users to developers, data engineers, data scientists, analysts, app builders and agent creators. The slide’s message is “Everyone. Everywhere. Everything.” The strategic point is that these role-specific experiences can draw from, and contribute back to, the same governed enterprise context through Unity Catalog and Genie Ontology.
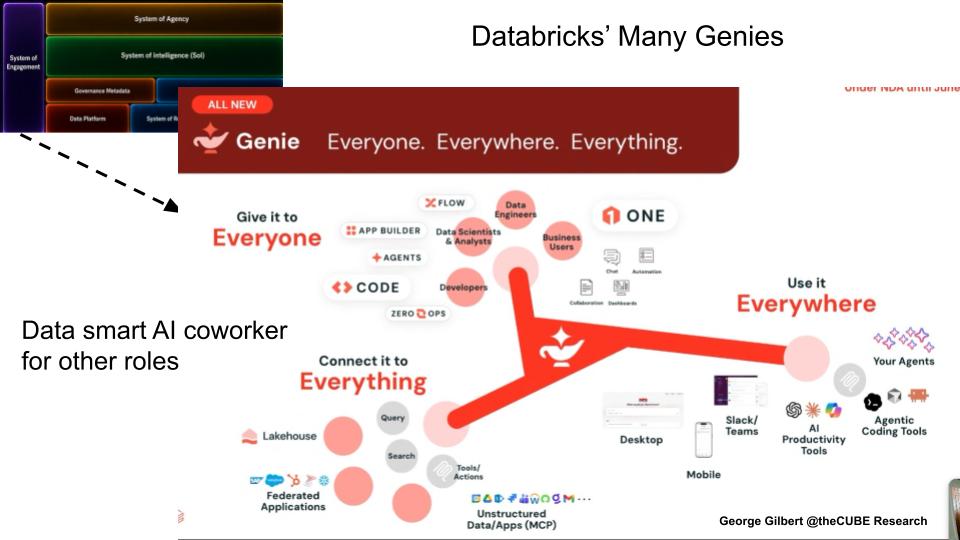
Key Points
- Agents are commodity; integration is not — the market is full of copilots and agent development tools, so differentiation comes from integrating agents with a company-specific data and action space, which Genie Ontology and Unity Catalog provide as the enterprise map and governance layer.
- Each role gets a grounded coworker — Genie Code builds apps and pipelines, ZeroOps diagnoses and remediates, and data-science and analyst experiences work from governed metrics — all understanding the Databricks environment and needing less supervision.
- The strategy has three vectors — give Genie to everyone, connect it to everything, and let users reach it everywhere.
- Pervasiveness drives the learning loop — and the risk — the more surface Databricks observes, the more it can improve the ontology; the danger is that if third-party clients own too much of the engagement layer, Databricks loses the signal it needs.
Genie One is the business surface, but the bet is much broader. Databricks is extending Genie across roles — developers, data engineers, data scientists, analysts, app and agent builders — because Enterprise AGI won’t arrive through one generic chatbot. The market is already crowded with copilots, so the differentiator is not the interface or the model; it is whether the agent is integrated with the company’s specific data and action space. That is what Genie Ontology and Unity Catalog begin to provide: a map of the enterprise and a governance layer around it, rich enough for role-specific agents to know how the company works, which data is trusted, which metrics matter, which permissions apply and which actions are allowed.
Each role gets a coworker grounded in that same back end. Genie Code builds Databricks applications and pipelines because it understands the environment; ZeroOps diagnoses and remediates because it understands the infrastructure; data-science and analyst experiences work from governed metrics and semantic objects. Business users come in through Genie One, but the pattern is identical across roles.
The strategy runs along three vectors:
- Everyone — business users, developers, analysts, data engineers and agent creators.
- Everything — the lakehouse, governed metrics, federated applications, queries, search, tools, actions and unstructured data, through mechanisms such as MCP.
- Everywhere — desktop, mobile, Slack, Teams, AI productivity tools, agentic coding tools and eventually the user’s own agents.
That “everywhere” reach is what powers the learning loop. The engagement layer is a learning surface, not just a consumption layer: the more of it Databricks observes, the more it can improve the ontology, and the better the ontology, the more useful the Genies. It also explains why engagement is among the most contested layers in enterprise AI. Microsoft, Snowflake, Google, Amazon, the frontier labs and the SaaS players all want their client to be ubiquitous, because whoever owns it gets privileged access to the behavioral exhaust that teaches the back end.
Databricks’ edge is governed data; its challenge is distribution. Microsoft has the productivity surface, SaaS vendors have application workflows, frontier labs are rapidly capturing client unit share. Databricks has to make Genie pervasive enough to capture the signal that strengthens Genie Ontology while still accommodating the third-party clients enterprises will inevitably use. So Many Genies can’t be product sprawl — it has to turn role-specific engagement into one shared learning system. Connected to the same governed map, the Genies reinforce one another; fragmented into disconnected copilots, they lose the flywheel.
Key Takeaway: Databricks’ many Genies strategy differentiates from other copilots. Its focus is creating role-specific engagement surfaces that share one governed enterprise map – and continually teach the intelligent back end how the business works.
Genie Ontology – The Core of the Intelligent Back End
Genie Ontology is where Databricks tries to turn governed data into shared business meaning — the heart of the intelligent back end. It defines the business’s resources. It connects business terms, metrics, authoritative data sources, semantic definitions and expertise. The current capability is best understood as semantic harmonization — helping an organization agree on what its data actually means. That is a major step toward a system of intelligence, but not yet a complete digital model of how the enterprise operates.
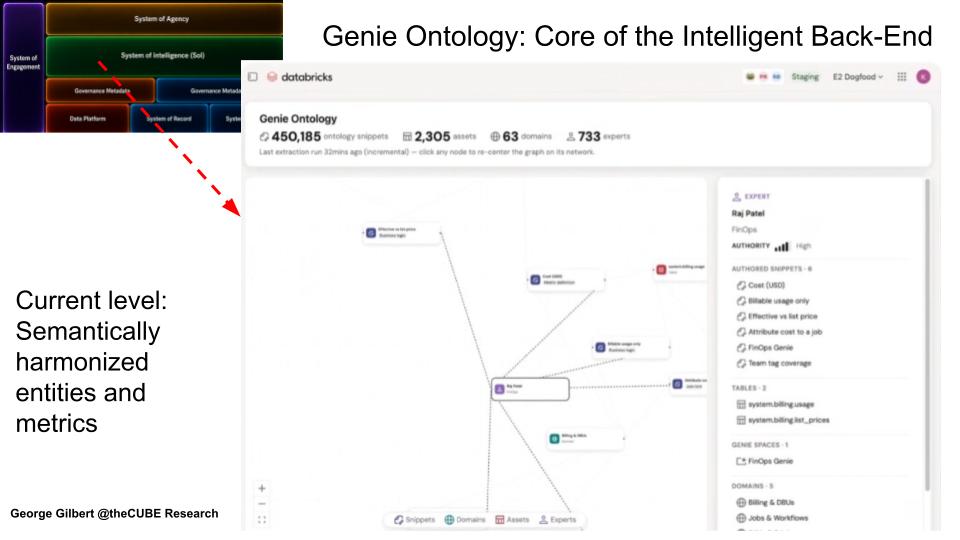
Key Points
- What it is — the emerging system of intelligence layer: a map of the enterprise’s data and meaning, built by extracting knowledge “snippets” (metric definitions, authoritative sources, entity relationships, rule-like semantics) from tables, queries, dashboards, documents, pipelines and connected apps.
- What it does well today — semantic harmonization, learned bottom-up rather than authored top-down, and anchored in ground truth by tying inferred knowledge back to certified “gold” data.
- Where it still falls short — encoding business process logic — policy, preconditions, effects and operational rules — remains the hard part.
- Why ownership matters — whoever owns the definitions can generate the user experience and control agent activity, which makes the ontology a major enterprise software control point.
Genie Ontology answers the central question of Enterprise AGI: how does the system know how the business actually operates? Rows and columns aren’t enough. A table can store revenue, customers, orders or invoices, but it doesn’t know which revenue figure is authoritative, how “active customer” is defined, how a metric is calculated or which process rule governs a decision. Enterprise AGI requires that meaning to be captured, governed and made available to agents.
It builds the map by extracting knowledge snippets and ranking them. From tables, queries, dashboards, pipelines, documents and connected apps, it pulls metric definitions, authoritative-source pointers, entity relationships, synonyms, SQL expressions, joins and formatting rules — then ranks them by provenance, authority, usage frequency and freshness while enforcing Unity Catalog permissions. In practice that lets it encode statements like: revenue comes from a specific certified finance table; an active user is deduplicated across platforms; NRR uses an approved formula; a given dashboard is the single source of truth. This is the semantic plumbing that separates trusted answers from merely plausible ones.
Its current strength is semantic harmonization, and much of it is learned bottom-up. Helping enterprises agree on what data means across users, dashboards and domains is real progress, since most still wrestle with duplicated metrics and competing versions of the truth. Historically these semantic layers were authored top-down — experts curating the model — which is consistent but slow and brittle. Databricks and Snowflake show that part of the map can instead be learned from real usage: queries, dashboards, metric definitions, documents and accepted answers.
But bottom-up learning does not solve the whole problem. It works well for entities, relationships, measures and definitions; it is much harder for business process logic — the operating rules governing qualification, credit and revenue recognition, which must be explicitly taught, approved and governed as they change. We return to this structure-versus-rules boundary in detail later.
This is the line between a descriptive and an executable ontology. Today Genie Ontology is strongest as a descriptive, read-context layer that grounds agents in enterprise semantics. A full system of intelligence must go further — representing typed objects, actions, preconditions, effects, workflows, live state and policy constraints — so agents can not only answer but act with confidence.
The strategic implication is that whoever owns the ontology starts to define the business. In the AI era that matters more than owning the dashboard: if the system knows the authoritative metrics, entities and relationships, it can generate the visualization, narrative, app or agent workflow on demand. The dashboard becomes an output, not the control point.
That is why the semantic layer is becoming a battleground. Microsoft’s reported blocking of Databricks Unity metrics in Power BI underscores the stakes: if Power BI owns the definitions, Microsoft can push them into Fabric as authoritative; if Databricks owns them through Unity Catalog and Genie Ontology, Power BI becomes less central because the visualization can be generated from Databricks’ governed layer. This is the next platform fight. The system of record captured transactions, the BI layer captured reporting, the data platform captured storage and analytics — and the system of intelligence aims to capture the definition of the enterprise itself, a higher-value control point because it is the foundation for agents, applications and action.
None of this means the work is finished. Genie Ontology is not yet a complete enterprise digital twin and does not model the business in real time — but it is a meaningful step toward the intelligent back end and a credible path from governed data platform to enterprise intelligence platform.
Key Takeaway: Genie Ontology turns governed data into business meaning. Its current strength is semantic harmonization, but the strategic prize is larger. It’s owning the enterprise definitions, rules and context that agents will need to reason, decide and act.
How Genie Ontology Learns – The Living Context Graph
The ontology is built bottom-up — inferred from real usage, not hand-modeled top-down. This slide explains how Genie Ontology is built and kept current: from KPIs, SQL queries, business vocabulary, user interactions, corrections, accepted answers, Unity Catalog schemas, Lakeflow pipelines and unstructured workplace content. The result is a living context graph that ranks knowledge by provenance, authority, frequency and freshness before using it to ground agent responses.
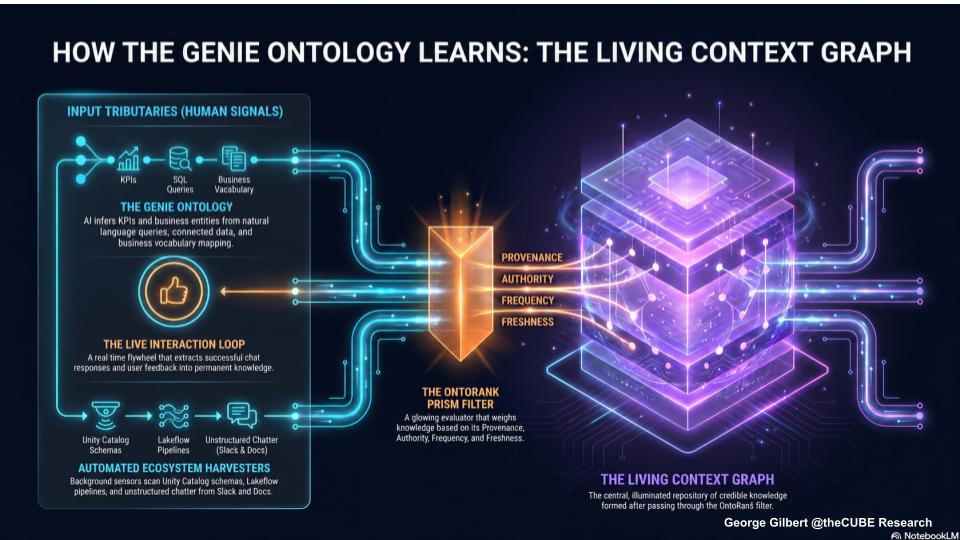
Key Points
- Three input streams feed it — human signals (KPIs, SQL, business vocabulary), system signals (Unity Catalog schemas, Lakeflow pipelines, unstructured content), and behavioral exhaust from user questions, answers and corrections.
- OntoRank decides what’s authoritative — a PageRank-style filter weighs provenance, authority, usage frequency, freshness and links to certified “gold” assets, so inferred knowledge is grounded in ground truth. (Why they didn’t call it “OntologyRank,” we can’t say.)
- This is a real shift from top-down — unlike hand-authored layers such as AtScale, Looker’s LookML, and PowerBI, it reduces manual curation and can solve much of the enterprise-context problem on its own.
- But it has a ceiling — bottom-up learning works for entities, relationships, measures and vocabulary; it cannot reliably capture process rules — what must happen, what must not, and why.
The real test of an ontology is not what it knows but how it learns and stays current. Genie Ontology matters because Databricks isn’t building it as a static, top-down semantic layer. Historically those layers were authored by experts and governance committees — consistent but slow, and often obsolete by the time they’re done. The design center here is a bottom-up learning loop.
It learns from three input streams and ranks what it finds. The Genie Space workshop captures user-defined KPIs, SQL and vocabulary; the live interaction loop turns successful answers, feedback and clarifications into permanent knowledge; and automated harvesters scan Unity Catalog schemas, Lakeflow pipelines and unstructured content like Slack and documents. A PageRank-style filter then weighs provenance, authority, usage frequency, freshness and connections to certified assets to decide which definitions and sources most likely represent ground truth.
Ground truth is the critical advantage. Many knowledge graphs collect information but can’t tell what’s authoritative. Databricks can anchor inferred knowledge to governed Unity Catalog assets — certified dashboards, approved metric views, trusted tables — giving the ontology a reference layer to evaluate everything else against. And because engagement is part of the learning system, the questions, corrections and clarifications users produce become signal that teaches the back end.
Without heavy curation, this approach goes surprisingly far. It can learn who the domain experts are, which fields are joined, which metric is preferred for a question, and which dashboards are authoritative — strong coverage for BI, analytics, entity resolution and semantic harmonization.
But it has a ceiling: ontologies aspiring to executable models require explicit authoring. Behavioral signals show what people do, not what the business requires. Query logs expose types, grain, joins and vocabulary, but they can’t reliably enforce policy, obligation, prohibition or intent — what must happen, what must not, which rule wins, or why a process exists. That level of ontology can’t be inferred or learned.
So the living context graph is both encouraging and revealing in its limits. It lets the enterprise learn from usage instead of depending entirely on top-down modeling, but reaching higher ontology maturity means combining bottom-up inference with explicit teaching, governance and promotion of business logic into shared assets.
Key Takeaway: Genie Ontology’s bottom-up learning loop is a breakthrough for semantic harmonization. But these definitions can only show what happened – they cannot fully define must happen or what must not happen. To become Enterprise AGI, the ontology must combine inferred context with governed business rules and explicitly taught operating logic.
The Clarification Loop – How the Client Teaches the Ontology
The clarification loop is the simplest picture of the core principle: the client teaches the back end. A business user asks, in company-specific language, “Show me lost revenue from platinum customer segment.” Rather than guess, Genie recognizes that “platinum customer segment” is ambiguous and asks for clarification. The user defines it — platinum customers are accounts that generated more than $10K in revenue in any given month — and that definition becomes reusable enterprise context for future users and agents.

Key Points
- The client asks instead of guessing — when the ontology lacks confidence, Genie surfaces the ambiguity and captures the user’s answer as reusable enterprise context.
- Company-specific language is the payload — terms like “platinum customer” carry local meaning, and the clarification loop excels at definitions, metrics and vocabulary.
- Owning the client is owning the signal — whoever owns the work surface captures the queries, ambiguities and corrections that train the back end; without it, a vendor can own data or models and still miss the loop.
- Governance is the boundary — when a clarification implies policy, permissions or process rules, one user’s answer can’t become enterprise truth, so the system must know when to ask, route for approval, or promote.
The platinum-customer example looks trivial, but it captures the core principle: the client has to teach the back end. “Platinum customer segment” is not self-evident — it could mean top accounts by revenue, customers above a lifetime-value threshold, a loyalty tier or premium-support accounts. A generic model guesses; a governed enterprise system shouldn’t. So Genie asks how the term should be defined, the user answers (accounts generating more than $10K a month), and that answer becomes reusable enterprise context rather than a one-time instruction.
That makes the client a teaching instrument, and the mechanism depends on tight co-design. The ontology has to recognize a gap in its knowledge, route a clarification to the user, capture the response with provenance and authority, and then decide whether the new definition stays local, goes for approval, or is promoted into broader enterprise context.
Owning that client is owning the critical teaching signal. A vendor that controls the work surface captures the natural-language query, the ambiguity, the clarification and the usage that follows; a vendor that doesn’t may still answer questions but loses the behavioral exhaust that improves the ontology. That is why everyone is fighting for the agentic work surface — Snowflake with CoWork, Microsoft (through 365 Copilot), AWS Q, Google Gemini Enterprise, OpenAI with the merging of ChatGPT and Codex, and Anthropic CoWork. The prize isn’t interface real estate; it’s the learning loop.
There is a deeper platform implication too. As the agentic client becomes the center of gravity, traditional applications risk becoming tools the client invokes rather than destinations users visit — office documents, dashboards, BI reports, CRM screens and workflow apps turning into editable artifacts or endpoints inside a broader agentic experience. The vendor that owns the client shapes how those tools are called and captures the feedback that trains the back end.
But the loop has a governance boundary. It works well for company-specific language, metric definitions and semantic ambiguity. When a clarification crosses into policy, permissions, compliance or operational rules, a single user’s answer cannot become enterprise truth — so the system must know when to ask, when to route for approval, when to keep context local and when to promote it. That is where bottom-up learning begins to meet top-down control.
Key Takeaway: The agentic client is not just the front end for Enterprise AGI. It is the teaching surface. Whoever owns the clarification loop can capture the company-specific language, definitions and intent that make the system of intelligence smarter over time.
Ontology Maturity – From Semantic Context to Agent Coordination
Databricks sits around levels 5–6 on our nine-stage maturity curve — at the transition from diagnostic intelligence to agent coordination. The core principle: the richer and more faithful the enterprise model, the more sophisticated the analytics and the greater the scope and confidence of agentic action.
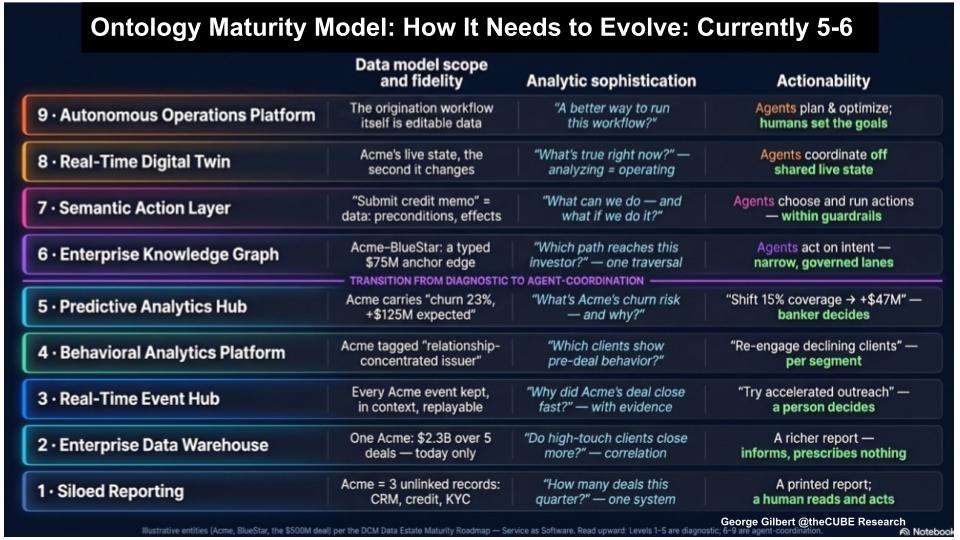
Key Points
- Where Databricks sits — Genie Ontology is meaningful but not yet a fully executable enterprise ontology; we place it around levels 5–6, the move from diagnostic intelligence toward agent coordination.
- The governing principle — the richer the enterprise model, the more sophisticated the analytics and the broader and more confident the agentic action.
- The hard jump is 6 → 7 and above — it cannot be reached by bottom-up inference alone; it requires explicit teaching, business-process modeling, governance and human-in-the-loop validation, with forward-deployed AI engineering as the bridge from descriptive ontology to executable operations.
The maturity model clarifies where Databricks is and what comes next. Genie Ontology sits around levels 5–6 — strong relative to most enterprise data environments, but short of the upper end of Enterprise AGI. The governing principle is simple: as the enterprise representation gets richer, analytics get more sophisticated and agents act with broader scope and greater confidence.
The nine stages run from siloed reporting to autonomous operations:
- Levels 1–5 (diagnostic) — from siloed reports a human reads, up through warehouses, event hubs and behavioral and predictive analytics. By level 5 the system can answer a question like a customer’s churn risk and why, and recommend an action — shifting sales coverage, say — but a human still decides. This is where Genie Ontology is increasingly relevant.
- Level 6 (enterprise knowledge graph) — people, resources, accounts, products, transactions and relationships are connected so the system can reason over paths (who can reach this investor and how important they are likely to be to completing an offering), and agents act within narrow, governed lanes.
- Level 7 (semantic action layer) — actions like “submit credit memo” or “reassign sales coverage” become modeled data with preconditions, effects, permissions and guardrails, so agents can choose and run actions, not just recommend them.
- Level 8 (real-time digital twin) — the twin becomes the shared source of truth for the live operating state that coordinates human and agent activity; analysis works on live operational state, and agents coordinate off shared, deterministic state instead of passing messages between each other or an orchestrator as a single point of failure.
- Level 9 (autonomous operations platform) — the workflow itself becomes editable data; agents plan, optimize and adjust while humans set objectives, constraints and goals.
Why we put Databricks at 5–6: Genie Ontology is more than a BI semantic layer — it learns terms, metrics, entities, authoritative sources and relationships from governed data and usage. But it doesn’t yet fully meet the stricter definition of level 6, where typed relationships exist, and it doesn’t yet implement executable rules that turn it into a live model.
The jump from 5–6 to the higher levels needs a different learning mechanism. Bottom-up inference goes a long way — types, joins, vocabulary, common metrics, even some rule-like semantics — but it can’t know from behavior alone which remediation actions are allowed, which approvals are mandatory, which policy wins, or why a process exists. Those rules must be taught, authored, governed and validated, which makes human-in-the-loop design more important, not less. Palantir, Microsoft’s emerging FabricIQ, Celonis, RelationalAI, SAP Business Data Cloud, and Salesforce Data 360 encode processes out of the box or by explicit authoring. These more advanced ontologies can’t be learned.
Forward-deployed AI engineering is part of that bridge — something Ali Ghodsi referenced in his day-1 keynote, and a capability Databricks now appears to have. Moving from descriptive to executable ontology takes people who can help customers capture operating logic, clarify rules, connect processes to governed data and promote local knowledge into enterprise assets. Automation will cut the manual modeling, but the upper levels still require explicit business-process meaning.
So Databricks has the ingredients, but the climb isn’t automatic. To own the system of intelligence, Genie Ontology must evolve from a semantic knowledge layer into a governed operational model — from understanding metrics and entities to understanding actions, policies, state, workflows and decision rights. Agent Bricks, MCP tools, Lakebase and Unity AI Gateway can help, but the open question is whether they converge into one system of intelligence or remain separate product islands.
Key Takeaway: Databricks is at a meaningful point on the maturity curve – around levels 5 to 6 – but the next jump is harder. To reach the higher levels of Enterprise AGI, Genie Ontology must evolve from a descriptive semantic layer into a governed, executable model of business actions, policies, workflows and live state.
Constructing a Governed, Executable Ontology
Getting to an executable ontology means pairing bottom-up skill harvesting with top-down governance. This slide shows the bridge from a descriptive ontology to an executable one. Bottom-up learning can reveal structure, vocabulary and recurring work patterns, but behavior alone can’t tell the system what must happen, what must not, which policy has priority or why a rule exists. Moving beyond levels 5 and 6 requires both.

Key Points
- Three layers, increasing difficulty — bottom-up inference handles structure (objects, relationships, grain, naming) well, operating logic (process steps, conditions, workflows) less well, and authority (policy, regulation, contracts, prohibitions) least of all.
- Skill harvesting bridges some of the gap — agents emerge first through personal productivity, so the move is to harvest user-authored skills and run them through a promotion pipeline: author locally, abstract, route by risk, review by governance committee, promote.
- The winning architecture meets in the middle — pure bottom-up becomes a Tower of Babel and pure top-down is too slow and brittle; the answer is local contribution, top-down approval, and continuous promotion or demotion of shared logic.
- It will take time — this is hard organizational work requiring humans in the loop and governance, because the system must learn not just what happens but what should happen.
This step is harder than semantic harmonization. Bottom-up learning exposes structure, shared vocabulary and recurring patterns of work — but it cannot fully capture what the enterprise requires. The graphic frames the problem as three layers of increasing difficulty:
- Structure — the foundation: business objects (customers, orders, invoices, products, accounts, suppliers), how they connect, the grain of the data and shared naming. Bottom-up learning is strongest here — query logs, schemas, joins and vocabulary reveal how the enterprise describes itself.
- Operating logic — harder: metric calculations, each step’s conditions and outcomes, and how a process actually runs. Not “what does platinum customer mean?” but “what happens after a platinum customer misses a payment?” or “which workflow fires when risk crosses a threshold?”
- Authority and cross-cutting norms — hardest: company policy, regulatory obligations, contractual constraints, required actions, deadlines, prohibitions and the rationale behind each. These can’t be learned safely from behavior, which may be incomplete or wrong; they need explicit governance over what is allowed, required and forbidden.
Skill harvesting is what bridges the gap. Agents are emerging first through personal productivity: users author local skills, prompts and automations that carry real tacit knowledge about how work gets done. Left alone, that produces fragmentation — lots of useful local automation, no shared system of intelligence. The fix isn’t to suppress local authoring but to build a promotion pipeline: author locally, abstract (an LLM or tooling layer makes the skill legible and spots duplicates and conflicts), route by risk, govern, and promote into shared operating logic — demoting or re-fragmenting whatever proves wrong, stale or too narrow.
This is the real transition from behavioral signal to executable ontology. Behavioral exhaust shows what people do; user-authored skills show how people think the work should be done; governance decides whether that logic becomes enterprise truth. It’s also where many Enterprise AGI strategies will mature or stall — pure bottom-up becomes a Tower of Babel, pure top-down is too slow to keep up, and the winning architecture meets in the middle: local innovation at the edge, abstraction and harmonization in the middle, policy and governance from the top.
For Databricks, this is the next major challenge. Genie Ontology has a credible path as a bottom-up semantic layer, but reaching levels 7–9 means explicitly teaching actions, rules, policies, and process logic so it can represent the live state of the business. That’s a completely different design center. Agent Bricks development, Unity Catalog, Unity AI Gateway governance and partner ecosystems can help — but they have to converge into one governed, executable ontology rather than stay a collection of separate features. That won’t happen overnight; capturing tacit knowledge, resolving conflicts and governing shared logic is hard organizational work, and even as models automate more of the translation, the upper levels still need humans in the loop.
Two caveats temper the scenario. First, competition, inertia and platform affinity will likely create silos of intelligence that add friction to the new operating model. Second, some argue the whole approach is too complex for enterprises to adopt, and that simpler systems — perhaps from research labs or startups, possibly via partnerships led by the leading LLM players — will emerge to provide an integration layer across those silos.
Key Takeaway: The path from semantic ontology to executable Enterprise AGI requires a hybrid architecture. Specifically, bottom-up skill harvesting, top-down governance and a promotion pipeline that turns local know-how into shared business logic. Without that middle layer, agents may become useful personal tools, but they will not become a governed operating system for the enterprise.
Omnigent – Governing a Heterogeneous Agent Estate
Enterprises won’t have agentic clients from one vendor — they’ll have many, and Omnigent is Databricks’ bid to govern them all. This graphic shifts from Databricks’ native Genie experience to the broader reality. Omnigent is Databricks’ open-source metaharness for connecting third-party systems of engagement — coding assistants, enterprise copilots, external agents — into Unity AI Gateway, where the enterprise applies common governance across models, agents, MCP tools, skills and collects telemetry. Omnigent also enables enterprises to seamlessly manage ensembles of multi-vendor agents to satisfy requests, freeing customers from single vendor dependencies. The value proposition is openness with control. The open question is whether third-party clients can contribute the same rich semantic feedback that native Genie clients use to improve Genie Ontology.
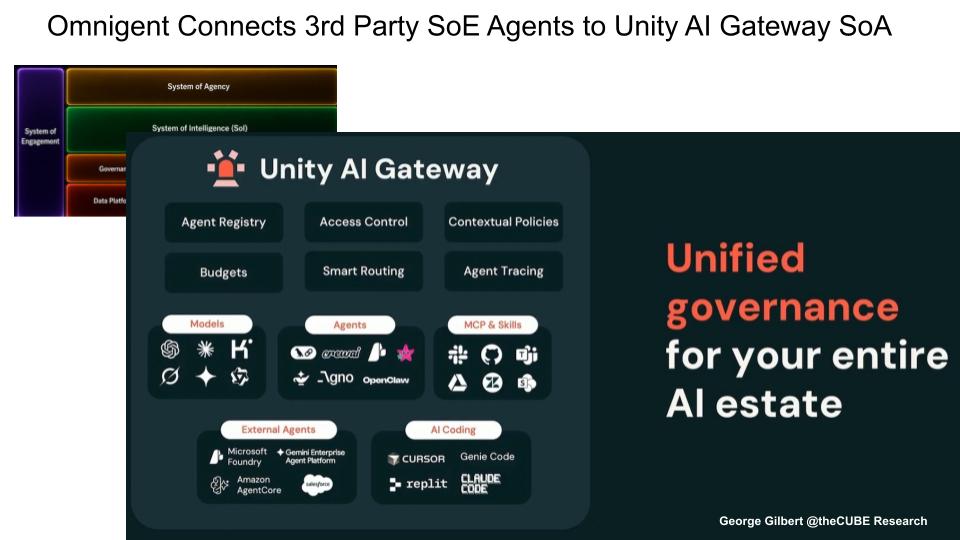
Key Points
- Openness with control — Omnigent is an open-source “harness of harnesses” connecting third-party agentic clients into Unity AI Gateway — the control point for access, policy, routing, budgets, tracing and registry — so the enterprise can govern a heterogeneous estate of agents rather than assume all work happens in Genie.
- Governance doesn’t enable learning — external clients may not expose the natural-language queries, clarifications and corrections to the Genie Ontology, so Databricks can administer and observe outside agents without capturing the same semantic feedback.
- Agent traces are the new behavioral exhaust — like clickstreams in the web era, reasoning traces, tool calls and overrides become a major (and enormous) class of enterprise data, making agent observability strategic.
- Durable execution and agent reliability become first-class concerns — long-running agents need recovery, rollback and a source of truth for their state, expanding business continuity to cover process state, intent and reasoning — even as the industry risks fragmenting into competing ontologies.
Enterprises will run a heterogeneous fleet of agents — Genie, Microsoft 365 Copilot, Claude, ChatGPT/Codex, coding assistants, SaaS and hyperscaler agents, custom builds — and no vendor will own them all. If every client wires up to models, tools and data independently, the result is fragmentation, inconsistent permissions, runaway spend and weak observability. Omnigent is Databricks’ answer: an open-source “harness of harnesses” that sits around external agent harnesses and routes them into Unity AI Gateway and Unity Catalog governance — registry, access control, contextual policies, budgets, smart routing and tracing across models, agents, MCP tools, skills and AI coding tools.
The leverage is that Omnigent lets Databricks participate even when it doesn’t own the front end. Whether an enterprise standardizes on Claude, ChatGPT/Codex, Microsoft 365 Copilot, Cursor, Replit, Salesforce or Amazon Q, Databricks can still supply governance, routing, policy, permissions, cost controls and observability through Unity AI Gateway — openness without surrendering control.
But governing a third-party client is not the same as co-designing one with the system of intelligence. A native Genie experience can ask a clarifying question when the ontology is uncertain, capture the answer and turn it into persistent context — the loop that teaches Genie Ontology. It’s not clear Omnigent can fully replicate that for outside clients: it can govern, trace and route them, but pushing a clarification (“what do you mean by platinum customer?”) back into a third-party interface likely needs deeper integration than a governance harness provides. So the next platform fight isn’t only about governance; it’s about learning. Governance keeps Databricks in the flow of third-party usage; native engagement lets it learn directly.
Agent traces are becoming a new — and enormous — class of enterprise data. As clickstreams powered web-era analytics, reasoning traces in the form of chain of thought, tool calls, action paths, failures, retries and human overrides will power the AI era, helping enterprises diagnose and improve agents and train the broader system. Because agents generate reasoning and intermediate state over many steps, these traces can dwarf traditional telemetry, making observability a strategic capability well beyond troubleshooting.
Durable execution and continuity also become first-class concerns. As agents move from short tasks to processes that run for hours or days, the enterprise needs a source of truth for an agent’s state — where it was, what it had done, what intent it pursued, how to recover or roll back — much like the long evolution of transactionality and recovery in databases. That expands business continuity itself: resilience now has to cover process state, reasoning state and intent, not just data, and we expect new forms of protection to emerge around agent, ontology and process state.
The bigger implication is fragmentation. The industry almost always fragments when powerful vendors chase the same value, and it’s already happening: SaaS vendors embedding agents and building process-oriented data platforms, LLM vendors pushing clients and plug-ins, hyperscalers building agent platforms with context graphs, data platforms building ontologies. Omnigent doesn’t eliminate that. What it doesn’t solve is the deeper problem of multiple systems of intelligence emerging inside one enterprise, and how to reconcile and rationalize them so the company doesn’t inherit a new generation of AI silos.
Key Takeaway: Omnigent gives Databricks a pragmatic way to govern third-party agents in a fragmented enterprise AI landscape. But governance is not the same as learning. The key question is whether Databricks can capture enough traces, feedback and clarification from external clients to improve Genie Ontology – or whether the richest learning loop remains reserved for native Genie experiences.
The Race to Enterprise AGI
The race to Enterprise AGI is a wide-open jump ball, and all roads lead to the same control point. Enterprise AGI isn’t about eliminating workers. It’s about the shared, live context that can coordinate the work of armies of humans and agents. This slide zooms out from Databricks to the broader field. The major camps enter from different positions — frontier labs and copilots through the system of engagement, data platforms through governed enterprise data, SaaS and process vendors through systems of record and workflows — but each is converging on the system of intelligence, where business logic, skills, rules, relationships and tacit knowledge become governed corporate assets.
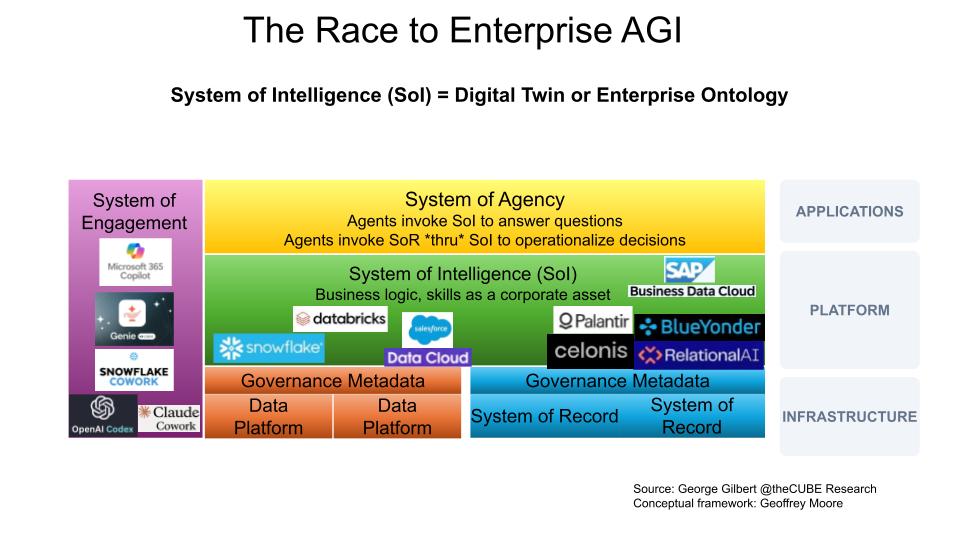
Key Points
- Three camps, one destination — frontier labs and copilots enter through engagement, data platforms (Databricks, Snowflake) climb up from infrastructure, and SaaS and process vendors (Salesforce, SAP, Palantir, Celonis, Blue Yonder, RelationalAI) start near systems of record — but the highest-value real estate they’re all converging on is the system of intelligence, the enterprise ontology or digital twin.
- The enterprise starts as thousands of islands — packaged apps, custom apps, analytic systems, spreadsheets and unstructured content, each with its own definitions and logic; harmonizing portions of the estate reduces the islands and makes a shared map plausible, whereas a list of connectors is not a map — access isn’t understanding.
- The frontier path runs through memory and skills — memory becomes state and skills become logic, but personal automations must be abstracted, harmonized, governed and promoted into shared enterprise assets to become a system of intelligence rather than ungoverned sprawl.
- It takes two kinds of intelligence, and the best architecture doesn’t always win — Enterprise AGI needs adaptive intelligence from LLMs and deterministic intelligence from rules, policies, state and tacit knowledge; volume, distribution and brand also shape outcomes (OS/2 vs Windows).
Every camp sees the prize, but each enters from a different starting point. Frontier model vendors and copilots come in through the engagement layer — Microsoft has business ubiquity through 365 Copilot, OpenAI has ChatGPT and Codex, Anthropic has Claude — and sit closest to user intent. Data platforms like Databricks and Snowflake are climbing from infrastructure into semantics, catalogs, metrics and ontologies. SaaS and process vendors — Salesforce Data 365, SAP Business Data Cloud, Palantir, Celonis, Blue Yonder, RelationalAI — begin closest to how work actually gets done, but none owns the whole enterprise.
They all converge on the system of intelligence — and the starting point is messy. Enterprises have thousands of islands, each with its own definitions, permissions, process logic and data model. Enterprise AGI can’t emerge from that fragmentation unless the estate gets more harmonized, which is why the moves from Salesforce, SAP, Snowflake and Databricks matter: they don’t solve the whole problem, but fewer islands are easier to bridge, and a shared overlay map becomes plausible once large portions are organized into coherent domains.
A list of connectors is not a map. Connectors give access, not meaning: a Salesforce connector doesn’t explain how the enterprise defines a qualified lead, a SharePoint connector doesn’t say which policy is authoritative, a Slack connector doesn’t know which escalation rule applies. Without a system of intelligence underneath, an agent sees endpoints, not a business. That’s also why traditional BI clients are no longer the center of engagement — the new layer is agentic, capturing the intent, clarifications, corrections and approvals that teach the back end.
The frontier vendors will move into the system of intelligence because they have to. Their path starts with memory and skills — memory becomes state, skills become logic — beginning personal (preferences, prompt patterns, saved automations) and expanding toward workgroup and enterprise. But a pile of user skills is not a system of intelligence; without governance it is just ungoverned sprawl. To become Enterprise AGI those skills must be abstracted, harmonized, approved and promoted into business logic — something that looks far more like an ontology, rules engine or digital twin than a generic chatbot.
Enterprise AGI needs two kinds of intelligence. LLMs supply adaptive intelligence — reasoning, language, code generation, planning, flexibility across a range of models, including frontier and open weight; the system of intelligence supplies deterministic intelligence — rules, policies, permissions, state, relationships, workflows and tacit knowledge. A very smart model can’t substitute for capturing a company’s own operating knowledge as governed assets. That said, volume matters: the largest model vendors have enormous usage, brand affinity and training feedback loops, and history is a reminder that the best architecture doesn’t always win — OS/2 versus Windows is the cautionary tale.
The market won’t resolve into one clean layer imposed from the top. Partnerships will form and shift, friends will become competitors, model vendors will move down into context while data platforms move up into intelligence and SaaS vendors defend process control. The winners will be those that connect all three layers — engagement, intelligence and agency — into a closed loop: engagement captures intent and feedback, intelligence turns enterprise knowledge into governed assets, and agency lets agents act through that context and through systems of record. Any vendor missing a layer will have to partner, acquire or build.
Key Takeaway: The race to Enterprise AGI is not a race to the smartest standalone model, the best data platform or the most popular copilot. It is a race to own the system of intelligence – the governed enterprise map that combines adaptive LLM intelligence with deterministic business logic, state, rules and tacit knowledge.
Enterprise Software Splits Into Two Categories – Above the Ice and Below the Ice
This is where architecture meets economics — the stack is splitting into two layers. Below the ice sits infrastructure: data platforms, storage, compute, formats, pipelines and procedural applications — essential, but increasingly standardized and priced like utilities. Above the ice is where the modeled enterprise lives: the system of intelligence, system of agency and system of engagement, where differentiation and pricing power concentrate.

Key Points
- Three layers, relocated for the AI era — data becomes the new infrastructure (foundational, but not where the highest margins sit), the system of intelligence becomes the new platform that makes data actionable, and agents become the new application layer acting through that model and systems of record.
- Data is the new hardware, not the new oil — data tells you what happened and who was involved; it becomes valuable only when a model turns it into why, what’s likely and what to do next, and as the twin gets richer, agents act with more confidence and the system becomes the shared coordination substrate for humans and agents.
- Economics split at the ice line — above-the-ice platforms can move toward value- or outcome-based pricing, while below-the-ice infrastructure stays exposed to consumption pricing and margin compression.
- Outcomes reset the negotiation — even short of pure outcome pricing, a vendor that can show it reduced churn, improved win rates or shortened cycle time has far more pricing power than one selling usage units, and the resulting switching costs (definitions, policies, skills, process logic, live state) are technical, operational and organizational.
The split is ultimately about economics. Below the ice is infrastructure — data platforms, storage, compute, formats, pipelines, procedural applications — vital, but increasingly standardized, interchangeable and exposed to utility-style pricing. Above the ice is where differentiation happens: the system of intelligence, agency and engagement coming together to learn the business from modeled data and let humans and agents coordinate around shared outcomes.
“Data is the new oil” is increasingly the wrong metaphor. Data tells you what happened, who was involved and which transaction occurred — but it becomes valuable only when a model puts it in context and makes it actionable. Data is closer to the new hardware: foundational infrastructure that must be present, but whose value is unlocked by the platform above it. That platform is the business-process model — the system of intelligence — which captures operating logic, rules, tacit knowledge, relationships and state, and moves the enterprise from “what happened?” to “why?”, “what’s likely?” and “what next?”
The richer the model, the more agents can do — and the more it becomes a coordination substrate. This ties back to the maturity model: as more of the business is captured in an ontology or digital twin, agents act with greater confidence across more scenarios, and at the higher levels they coordinate with each other and with humans through a shared representation of the live business. Enterprise AGI isn’t one agent finishing one task; it’s a shared substrate of signals, state, goals, policies and context that humans and agents operate through.
That is why economics change above the ice. A vendor providing only infrastructure is priced like infrastructure — consumption, usage, seats, capacity. A vendor that can model the business and contribute to outcomes has a stronger claim on value-based pricing. Outcome pricing won’t be simple — customers may resist paying what feels like a royalty on their own results — but even short of it, the ability to measure contribution changes the negotiation. A vendor that can credibly show it reduced churn, improved win rates, optimized inventory or shortened cycle time is in a far stronger position than one selling generic usage units.
The value sits in the modeled enterprise, not the parts. The data platform alone, the copilot alone, the model alone — none is enough. The strategic battle is moving above table formats and warehouse architectures: the new platform layer is the system of intelligence, the new application layer is agents, and the new pricing frontier is business outcomes. For customers, the real question isn’t which model is smartest or which platform is fastest, but which one helps them capture their unique operating knowledge as an asset — one that grows harder to migrate because it holds definitions, policies, skills, process logic and live state, making switching costs technical, operational and organizational. For vendors, the message is that value accrues above the ice: infrastructure stays large and important, but the best economics belong to platforms that learn how the business operates and improve measurable outcomes.
Key Takeaway: Enterprise software value is moving above the ice. Data becomes infrastructure, the business-process model becomes the platform, and agents become the applications. The vendors with the strongest pricing power will be those that turn enterprise knowledge into a governed system of intelligence and tie that system to measurable business outcomes.
Action Item for Business Technology Executives
Don’t treat AI as a model-selection exercise — treat it as an enterprise-intelligence construction project. Within 90 days, every executive team should name a single accountable owner to begin building its own governed system of intelligence: a living enterprise map that captures data, metrics, business rules, process logic, skills and tacit knowledge as corporate assets that agents can reason over and act through.
The mandate is to pick one high-value business domain, model the critical objects, define authoritative metrics, harvest user-authored skills, govern the rules, and connect agents only where the enterprise has enough context to act safely. The companies that do this will compound proprietary intelligence; those that simply plug frontier models into fragmented systems will rent generic intelligence and call it transformation.


