
Premise: Applications on mainframes often have special needs, but must also become part of data flows among operational, big data, and engagement applications. The market for tools that satisfy both mainframe and big data circumstances will grow to over $2.3 billion by 2020.
The value of data increases as it is correctly used in more contexts. For example, the value of customer data increases as it’s used — in context — across any engagement function, including marketing, sales, fulfillment, product, and service. The notion of context is crucial. Context is maintained if the utilization complies with utilization policies, including those associated with basic definitions, time, ownership, security, privacy, and others. When data doesn’t satisfy those contexts, it can corrupt systems, at best, or upend business and brands, at worst.
Extending the use of mainframe-based data can be especially sensitive to context. That’s because mainframe data often is featured in high-value applications, like finance and other core operational systems that feature absolute time, integrity, regulatory reporting, and security requirements. The need to ensure that mainframe data is properly applied, in context, to analytic systems is a key contributor to historical tension between mainframe app owners and data warehouse owners and admins and a core driver of past, huge investments in ETL systems.
The tension gets even worse in big data because of the unpredictable nature of big data needs. While some shops have established repeatable and predictable analytic pipelines for some percentage of their machine learning, AI, and other big data models and apps, most have not. Even those companies that have established a degree of operational repeatability in their big data-related apps are constantly pressured to extend the use of data lakes and related big data resources, precisely because of the growing recognition that the value of data increases as its use is extended. Simply put, data scientists like to play with data and mainframers typically do not like anyone playing with their data, their machines, or their time.
But mainframes must be brought into evolving digital business platforms (DBP) precisely because of the value of the data resident in so many mainframe applications. Data feedback loops — a key feature of DBPs — must accommodate flowing data from mainframe-based applications into the overall digital business platform. Moreover, advances in analytic model management approaches like machine learning, predictive analytics, and AI, provides new approaches to enhance mainframe-based operational applications through high quality APIs. All data movement is not off the mainframe; strategic financial, customer, and other data is starting to flow back.
Not Your Boss’s ETL
IT shops have been investing in data movement middleware for analytics for years, first in the form of report writer editors and managers, but also in the form of ETL technologies for use in business intelligence and data warehousing. These investments will continue to pay dividends for key classes of analytics, but most are insufficient for big data applications.
Why? The central difference between all “big data” systems and other systems is this: Reporting/BI/DW systems generally feature high foreknowledge of data models, whereas big data systems do not. Figure 1 describes the taxonomy. Reporting systems typically feature both low query and low model uncertainty: Both data model and query can be programmed and report execution scheduled. BI/DW, in contrast, is inherently built to support query unpredictability against known models; this is the basis for most ETL technologies that extract data from production systems, prep it according to a preordained data model, and load it into the BI/DW system. Big data, in contrast, seeks to discover both models and queries based on patterns in the data.
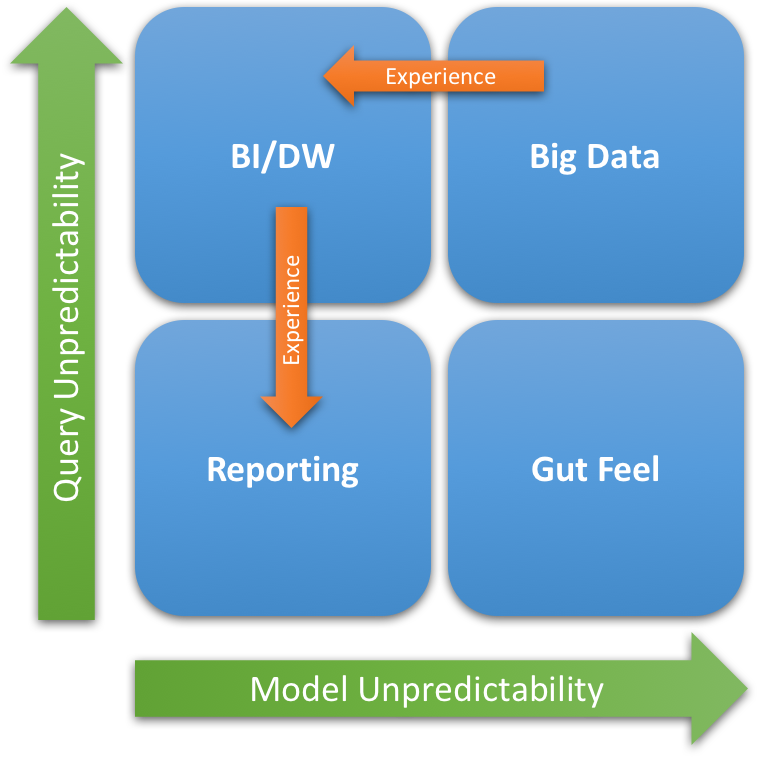
Figure 1: Juxtaposing Reporting, BI/DW, and Big Data Applications
As shops gain experience with both systems and models, the underlying query and model capabilities start to become better understood. Thus, today’s big data application, which generates experience by turning data patterns into data models, starts to take on operational attributes of a BI/DW system. We’re seeing this in shops that are starting to use Hadoop and related tools as a complement or substitute for traditional BI/DW systems. Similarly, as shops gain experience with BI/DW queries, reports can be written and distributed, which reduces the operational burden on the BI/DW system.
Mainframe Data Mover Spending Is A Bright Spot
While the big data ecosystem is built on open source software, the specialized needs of mainframe-to-big-data movement requires specialized tools. Companies like IBM, BMC, Oracle, Syncsort, CA, and others offer technology sets that serve the needs of both mainframe app owners and big data administrators. Moreover, our conversations with users on theCUBE and elsewhere strongly indicate that even the modest degree of operational stability being built into analytic pipelines is enough to encourage greater integration between mainframe sources of data and data link data sinks.
We believe that tools that can assert high quality data movement and security policies will be increasingly in demand from both mainframe and big data constituencies. These tools are becoming more available and better known, which is driving growth in the mainframe-to-big data market at 25% CAGR, to just over $2.3B globally in 2020 (see Figure 2). This is healthy growth, by an measure. Indeed, our research shows that mainframe-to-big-data integration spending will be the primary bright spot in the market for mainframe-based software.
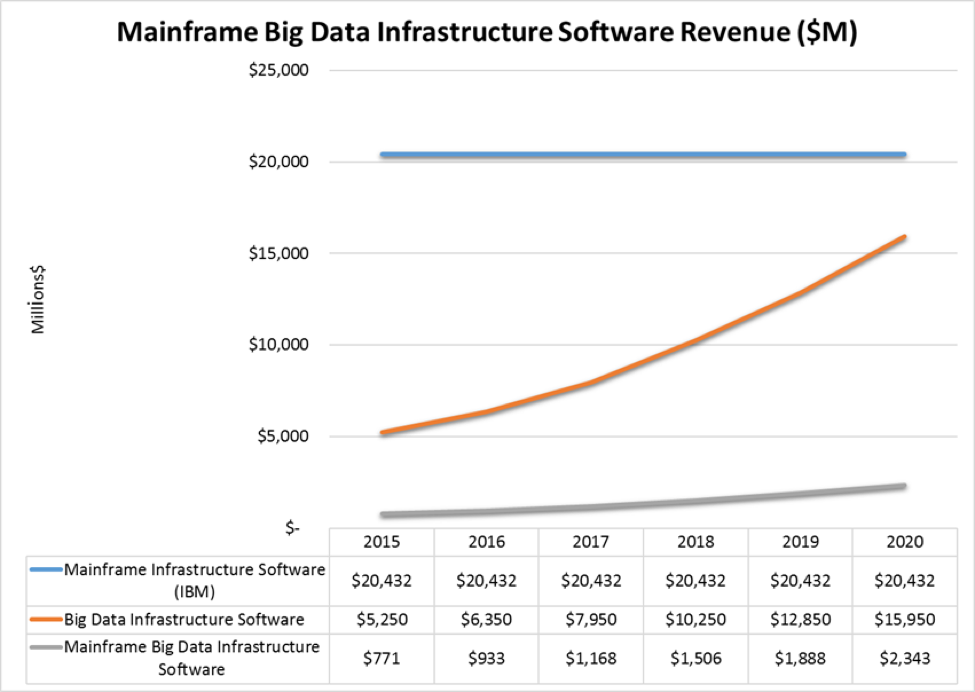
Figure 2: Mainframe Big Data Infrastructure Software


