

Premise: Machine learning can help IT administrators stay ahead of the rising tide of system complexity. However, there is no single best approach to simplifying IT operations management (ITOM). A new generation of application performance and operational intelligence (AP&OI) applications builds on big data and machine learning to improve IT productivity. Each solution has tradeoffs, however, with different sweet spots.
This report is the first in a series of four reports on applying machine learning to IT Operations Management. As mainstream enterprises put in place the foundations for digital business, it’s becoming clear that the demands of managing the new infrastructure are growing exponentially. This report summarizes the approaches. The following three reports go into greater depth:
Applying Machine Learning to IT Operations Management for End-to-End Visibility – Part 2
Applying Machine Learning to IT Operations Management for High-Fidelity Root Cause Analysis – Part 3
Each generation of applications builds on prior generations. Web and mobile applications, often in the form of systems of engagement, built on systems of record to execute business transactions. Big data and machine learning applications integrate with and inform decisions within business transactions and systems of engagement. But administrative complexity has been one of the main impediments to the spread of big data applications and their integration with prior generations of applications. Big data applications have grown in complexity in multiple dimensions, to the degree that:
- AP&OI has to make admin productivity compensate for the complexity of big data apps. The use of plastic and ephemeral resources and services, as well as multi-tenant infrastructure, require specialized administrative skills in quantities possessed that only by the most sophisticated enterprises.
- It takes big data to manage big data. The volume of operational telemetry requires a big data repository capable of supporting many administrative perspectives over time. Ironically, ITOM systems for application portfolios that make heavy use of big data require something like a data lake to work.
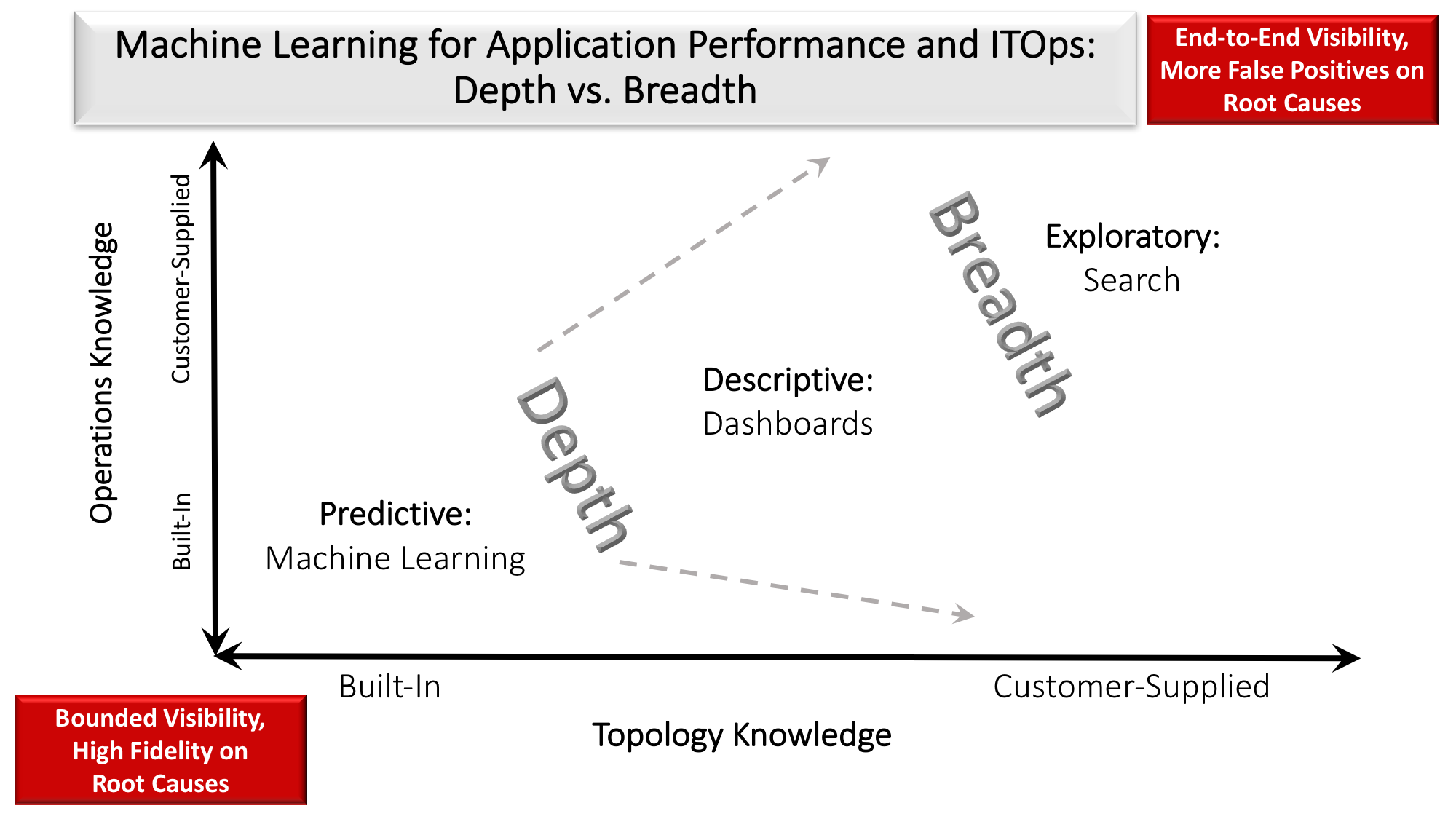
- It takes big data apps to manage big data apps. Two types of ITOM analytics are required to put machine learning shoes on the IT cobbler’s children: breadth-first and depth-first (see Table 1). All the intelligence that goes into a conventional analytic data pipeline is necessary to manage the analytic data pipeline that is the foundation for AP&OI apps.
| Breadth-first | Depth-first | |
| Scope | End-to-end, system-wide visibility | Optimization of specific resource pool or technology domain |
| Source of operations intelligence | Customer adds rules to built-in analytic platform | Vendor-supplied digital twins of a resource or domain |
| Output | Alerts with modest remediation because of root cause false positives. | High-fidelity root cause diagnostics with option for automated remediation |
| Challenges | – False positive during training process. – Lack of models allows problems to cascade upstream and downstream. |
Local optimization conflicts. |
Table 1: All IT Operations products ultimately have to make a trade-off in their approach. Scope, source of operations intelligence, and output distill the two approaches.
AP&OI Has to Make Administrator Productivity Compensate for Complexity of Big Data Apps
Application performance and operations intelligence may well emerge as one of the most sophisticated applications in IT portfolios (see figure 2). Pioneering AP&OI vendors appear ready to open up the bottleneck on the deployment of big data applications. 18 months ago it was not uncommon to hear of sophisticated customers running a 10-node Hadoop pilot with 5 admins, each with a different specialization. New AP&OI apps promise to greatly improve the productivity of admins with less specialized training and make it possible for more mainstream enterprises to build big data apps. Opening up this bottleneck is akin to the early days of the telephone 100 years ago. If we didn’t make operators more productive by turning every user into their own operator, we would have needed millions of people at switchboards. For IT operations productivity, AP&OI products from across the spectrum of IT domains can be categorized by their approaches to breadth and depth (see table 2).
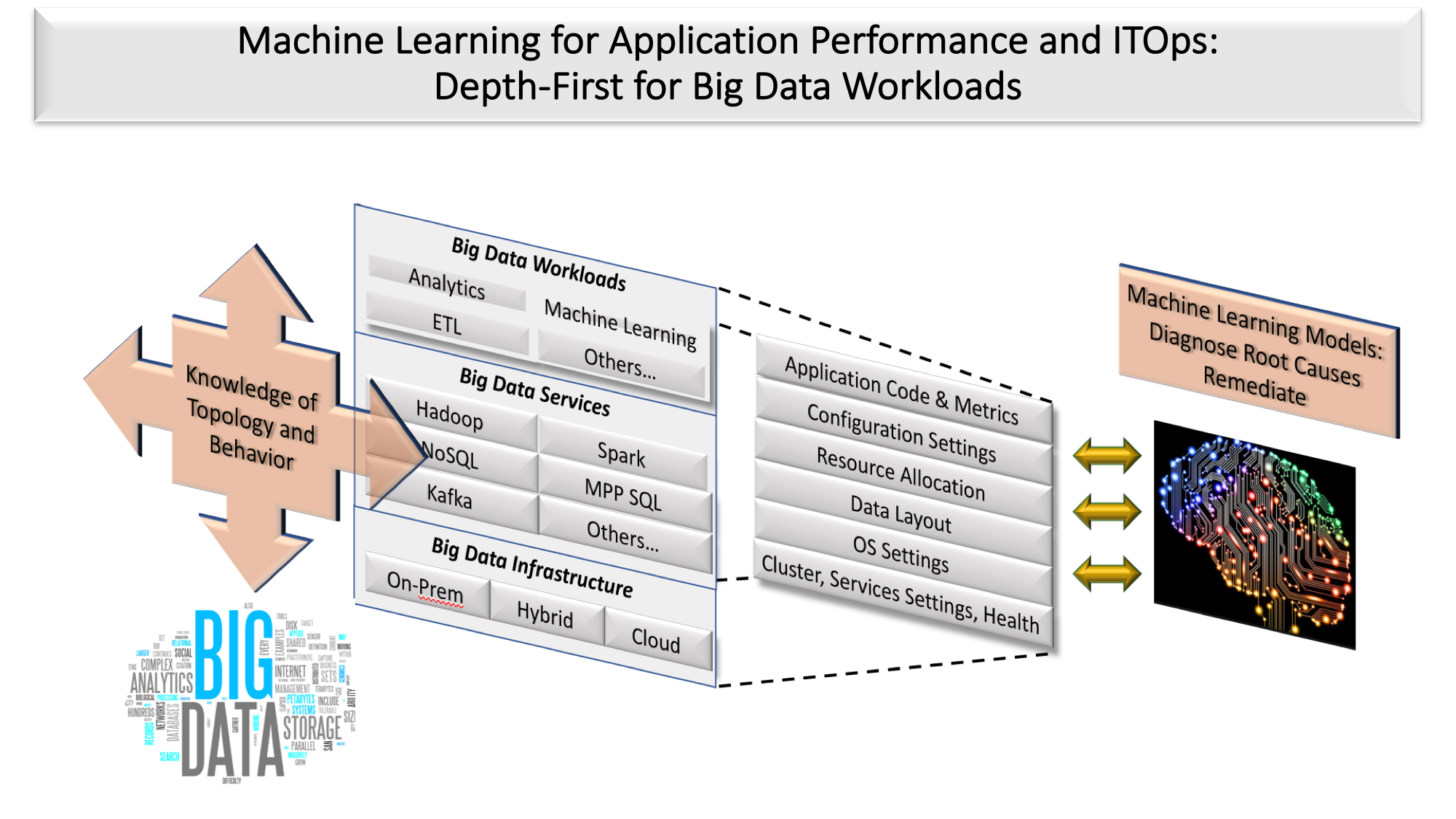
AP&OI apps built on machine learning enable customers to shrink the number of admins managing big data workloads by an order of magnitude or more. Just as significant, the new management technology enables customers to use less specialized big data administrators. The sophistication of the most intelligent management technology can be so precise in its instructions or, more significantly, its automated remediation of problems, that customers don’t need specialized administrators for each component in the big data stack. For example, rather than requiring a traditional DBA to know how to repartition data and add new indexes in order to fix performance problems, an AP&OI application built on machine learning could either make that precise recommendation or change the data layout itself (see figure 3).
It Takes Big Data to Manage Big Data
Tooling for improving systems of record administration have been available for some time, largely because the base knowledge for tuning and managing these types of systems has been maturing for 30 years. Big data applications, in contrast, are woefully complex — and poorly understood. The complexity that needs to be managed has grown in many dimensions — and exceeds the rate of diffusion of big data administrative knowledge and practices. The dimensions include:
- Configuration complexity spurred by the use of multi-tenant entities supporting apps that might plastically fluctuate between dozens of servers and tens of thousands of servers;
- Distributed complexity generated by the use of many more ephemeral entities such as specialized services, containers, microservices, functions, and other constructs;
- The geometric growth in data where customer interactions are 10-100x business transactions and data about operational infrastructure is yet another 10-100x in volume; and
- The need to accommodate edge, private cloud, and multi-public cloud platforms.
- Impedance mismatch between data science and application development cycles
AP&OI apps have to collect a prodigious amount of data about the applications and the infrastructure on which they run. For example, big data infrastructure generates more aggregate operational telemetry than IoT devices. Prior application generations were simpler. There were far fewer moving parts in client-server apps where the unit of work was a business transaction. New Relic and AppDynamics helped manage Web and mobile apps by tracking the performance of client requests across services and tiers, such as calls to Ruby on Rails, PHP, or .NET components and database queries. With Web and mobile apps, the unit of work tracks user interactions, which typically might generate between 10 and 100 system events for every business transaction.
Big data applications are far more complex to manage. The ecosystem of APIs that are part of big data platforms emits an audit trail of events about HTTP requests, SQL query audits, network and other infrastructure activity, security activity, application performance data, and events from a wide variety application workloads and data services, among others. Such infrastructure-intensive applications require tracking low-level data such as network and storage IOPS, network traffic, and similar information. Put all those sources together and big data applications generate one or two orders of magnitude system events than mobile or web apps (e.g., 100-to-1000 events per transaction). That data is ever more important in an era of plastic and multi-tenant resources. As a result, supporting the new class of applications requires AP&OI applications to handle potentially a firehose of 100,000s of metrics per second while storing hundreds of terabytes per day. 100s of terabytes per day may sound large. But AP&OI apps may need to store that for several years for later forensic analysis.
It Takes Big Data Apps to Manage Big Data Apps
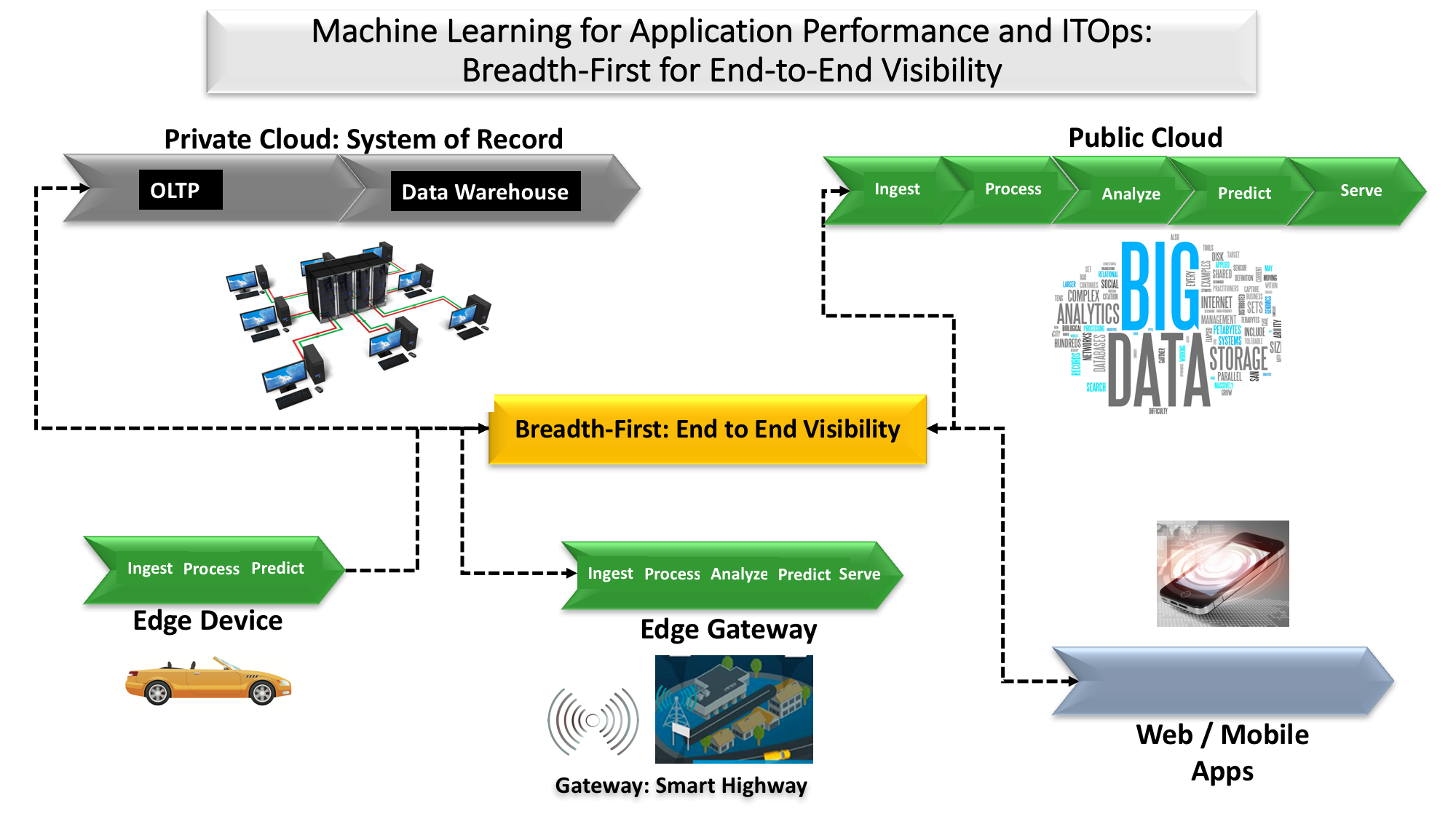
Big data applications, ironically, need data lakes as repositories for all their telemetry. In a data lake, the telemetry is searchable in infinite directions using technology as simple as faceted text search, which provides the ability to search for individual attributes of semi-structured text data. The repository becomes even more valuable if it’s the destination for events from other applications and their infrastructure, including network traffic information, security event data, as well as all kinds of custom application metrics. AP&OI applications can refine all this telemetry into an ever better understanding of the structure and behavior of the source applications, first into a curated data warehouse and over time using machine learning to model how the managed application works. (see Figure 1.).
Making sense of the telemetry sourced from big data applications and sinking to data lakes requires a more comprehensive solution than prior generations of management. Enterprise system of record applications had data warehouses as repositories for reporting and analysis of business transactions. Now, the refining process for big data telemetry includes many tasks long familiar to data warehouse practitioners: routing, transporting, ETL, cleansing, filtering, lifecycle management, and lineage and governance. This process of refining the telemetry can transform it from a searchable soup to a query-able data warehouse. Ultimately, admins or the AP&OI application itself can add deep domain expertise in the form of machine learning models that suggest actions or remediate problems automatically.
| Breadth-First | In Between | Depth-First | |
| Built on machine learning | Splunk Enterprise Rocana BMC TrueSight |
Appnomic
Cisco/AppDynamics Perspica |
Unravel Data Extrahop Pepper Data AWS Macie Splunk UBA |
| Not built with machine learning | VMware vCloud Suite New Relic AppDynamics Datadog |
BMC Control-M for SAP SignalFX |
CA Network Operations & Analytics |
Table 2: Examples of a variety of IT domains that classify products into breadth-first or depth-first categories. Products from one vendor can be in different categories, such as Splunk Enterprise, which is a breadth product and Splunk UBA, which is a depth-first product in security.
Action Item
IT organizations must invest in new IT management platforms that use machine learning technology that improves their optimization and control of an increasingly complex application and infrastructure portfolio. Enterprises that fail to do so will lose control of their crucial digital assets just as these assets gain increasing competitive importance.
https://wikibon.com/applying-machine-learning-operations-management-diagnostics-remediation-optimization/


