With George Gilbert
We believe today’s so-called modern data stack, as currently envisioned, will be challenged by emerging use cases and AI-infused apps that begin to represent the real world, in real time, at massive data scale. To support these new applications, a change in underlying data and data center architectures will be necessary, particularly for exabyte scale workloads. Today’s generally accepted state of the art of separating compute from storage, must evolve in our view to separate compute from data and further enable compute to operate on a unified view of coherent and composable data elements. Moreover, our opinion is that AI will be used to enrich metadata to turn strings (i.e. ASCII code, files, objects, etc.) into things that represent real world capabilities of a business.
In this Breaking Analysis we continue our quest to more deeply understand the emergence of a sixth data platform that can support intelligent applications in real time. To do so we are pleased to welcome two founders of VAST Data, CEO Renen Hallak and Jeff Denworth. VAST just closed a modest $118M financing round that included Fidelity at a valuation of ~$9B, which implies a quite minor change to the cap table.
What is the Modern Data Stack?
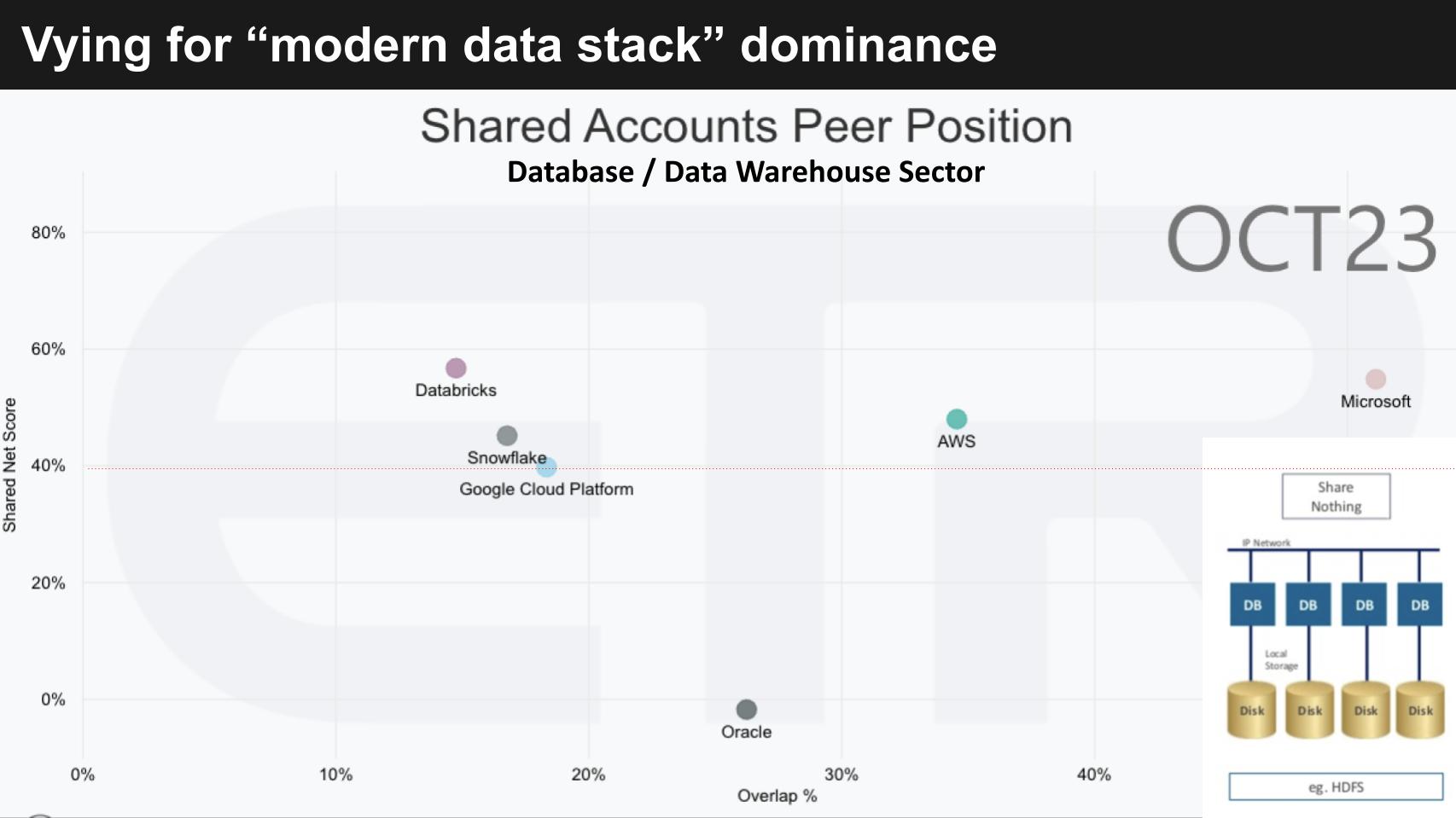
Above we show ETR data with Net Score or spending momentum on the vertical axis and presence in the data set – i.e. the N mentions in a survey of 1,700 IT decision makers – on the horizontal axis. Think of the X axis as as a proxy for market penetration.
We’re plotting what we loosely consider the five prominent modern data platforms including Snowflake, Databricks, Google BigQuery, AWS and Microsoft. We also plot database king Oracle as a reference point. The red line at 40% indicates a highly elevated Net Score.
It’s important to point out that this is the Database/Data Warehouse sector in the ETR taxonomy so there are products represented that we don’t consider to be part of the modern data platform conversation – e.g. Microsoft SQL Server. That is a limitation of the taxonomy you should be aware. Nonetheless, it allows us to look at relative momentum. Also, we’re not focusing in this research post on operational platforms like MongoDB.
Built on Shared Nothing Architectures
The more important point we want to share is shown in the bottom right corner of the chart. It shows a diagram of a shared nothing architecture. In a shared nothing system, each node operates independently, without sharing memory or storage with other nodes. Scale and flexibility are main benefits but ensuring coherence and consistent performance across these nodes is challenging. The modern data stack was built on shared nothing architectures. Oracle and SQL Server originally were not.
The following additional characteristics summarize the attributes of today’s modern data platforms:
Tradoffs of Scale Out, Shared Nothing Architectures
Architectural choices gain traction because they solve specific problems and have headroom to grow. Shared nothing architectures solve the problem of scale because it’s easy to add more nodes to the system. This is especially true in cloud computing environments where spinning up resources is simple.
But there are tradeoffs. Because resources in a scale out, shared nothing architecture are distributed, complexity grows as the system scales and adds more moving parts to manage.
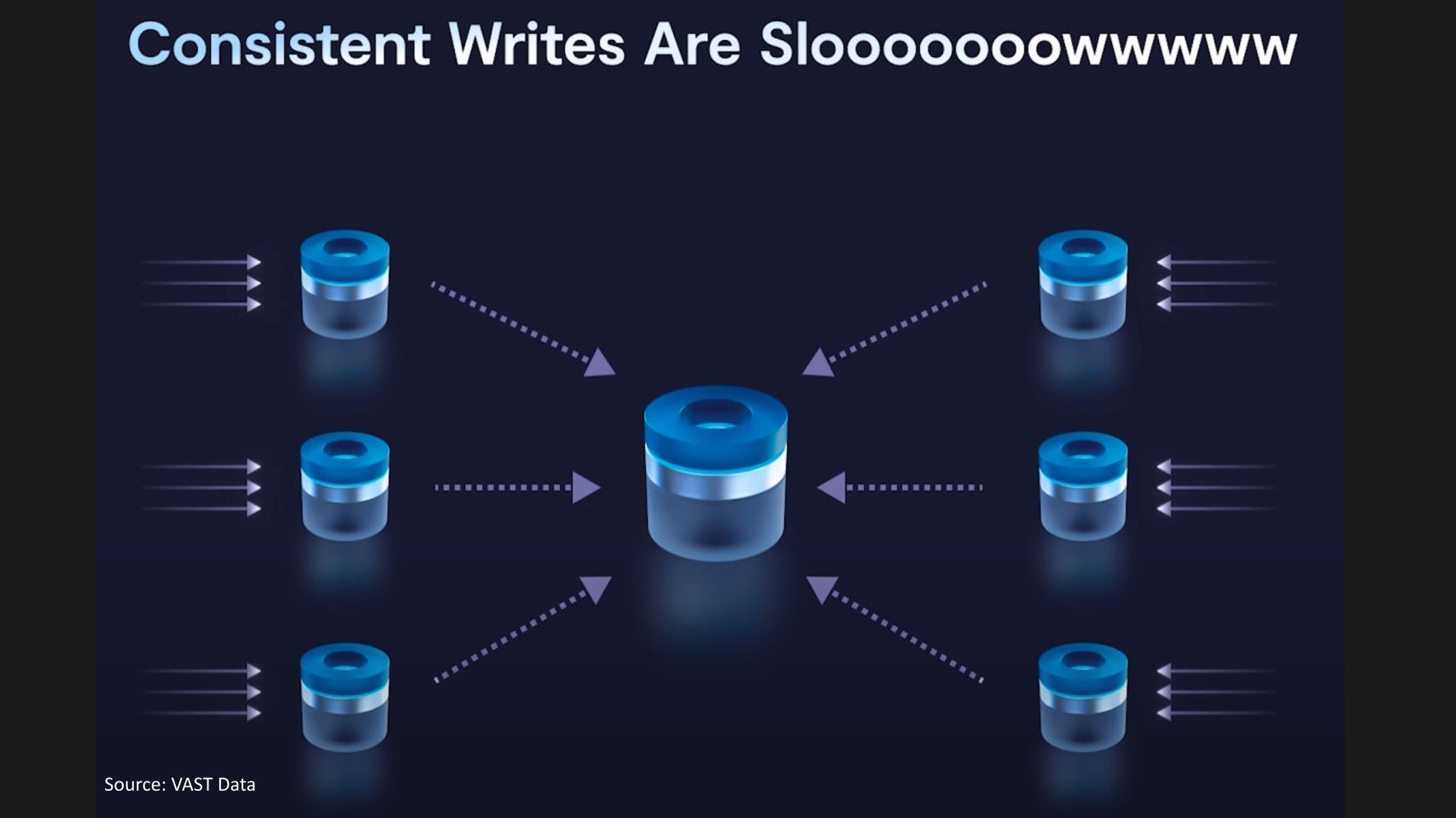
The term of art in the market is shared nothing. Here we’re talking about essentially a systems architecture that was first introduced to the world by Google in 2003. So it’s about 20 years old, and that architecture as you and George just articulated, has challenges. Specifically, all of the nodes within a distributed system have to be kept in contact with each other. Typically for transactional I/O, where transactions have to be strictly ordered, that becomes a real challenge when these systems are also faced with scale, and so very rarely do you find systems that can scale to, in today’s terms, exabyte levels of capability, but at the same time can deliver consistent performance as the systems grow. This is because you have, internally to these architectures, just a ton of east-west traffic, and so this is one of the major problems that we sought out to solve in what we’ve been doing.
[Listen to Jeff Denworth explain the challenges of shared nothing that VAST sought to address].
Limitations of Today’s Modern Data Stack
One of the challenges customers have is their data is everywhere (edge, data center, cloud) and comprises objects, tables, files and other data types that use different formats, have different metadata associated with them and generally are stovepiped. The modern data stack begins to address this problem from an infrastructure standpoint as cloud resources are much more easily deployed and managed. Moreover, most data platform companies are adding capabilities to manage different data types (e.g. transaction and analytic, structured and unstructured, etc.). But more work must be done in our view to unify data types and metadata to provide access to copilots that will power the future of AI infused applications at scale that can reliably take action on behalf of humans.

The chart above depicts a giant global namespace or what VAST calls a DataSpace. And the infinity loop represents edge to on-prem data centers to the cloud. VAST claims its Data Platform integrates unstructured data management services with a structured data environment in a way that you can turn unstructured data into query-able, actionable information. The reason this is important is because it allows the disparate elements shown on this chart – objects, tables, files, etc. to become those “things” that we talked about earlier.
Q. Why aren’t today’s modern data platforms well-suited for this and what’s your point of view on the architecture needed for the future?
Renen Hallak
I think they weren’t designed for it. When these modern data platforms were built, the biggest you could think of was, as you say, strings. It was numbers. It was rows. It was columns of a database. Today we want them to analyze not numerical pieces of information but analog pieces of information, pictures and video and sound and genomes and natural language. These are a lot larger data sets by nature, and we’re requiring much faster access to these data sets because we’re no longer talking about CPUs analyzing the data. It’s GPUs and TPUs, and everything has changed in a way that requires us to break those fundamental trade-offs between price and performance and scale and resilience in a way that couldn’t be done before and didn’t need to be done before, but now it does.
Jeff Denworth
If you think about just the movement that’s afoot now with generative AI technologies like deep learning, for the first time in IT history, we now have tools to actually make sense of unstructured data. So this is driving the coexistence within the VAST Data Platform of structured and unstructured data stores because the thinking is once you have the tools in the form of GPUs and neural networks to go and actually understand this data, well, that has to be cataloged in a place where you can then go and inquire upon the data and interrogate it and, to your point, Dave, you turn that data into something that’s actionable for a business. And so the unstructured data market is 20 times bigger than the structured data market that most BI tools have been built on for the last 20, 30 years. What we view is essentially AI as this global opportunity in the technology space to see roughly a 20X increase in the size of the big data opportunity now that there’s a new data type that’s processable.
Q. What does the pipeline look like for training large language models that’s different from what we might have done with today’s modern data stack training deep learning models but where you one model for each task that you had to train on? What does that look like in data set size? How do you curate it and then how does it get maintained over time? In other words, one thing is you’re talking about is the scale that’s different; and the other thing seems to be the integration of this data and this constantly enriched metadata about it. And trying to unify that. Can you elaborate on where today’s stack falls down?
Jeff Denworth
If you think in terms of scale, for example, if you take the average Snowflake capacity, we did some analysis of the capacity that they manage globally. You divide it by the number of customers that they have and you’re somewhere between, depending upon when they’re announcing, 50 to 200 terabytes of data per customer. Our customers on average manage over 10 petabytes of data. So you’re talking about something that is at least 50 times greater in terms of the data payload size when you move from structured data to unstructured data. At the high end, we’re working with some of the world’s largest hyperscale internet companies, software providers who talk and think in terms of exabytes, and this is not all just databases that are being ETLed into a data lake. It’s very, very rich data types that don’t naturally conform to a data warehouse or some sort of BI tool, and so deep learning changes all of this, and everybody’s conceptions of scale as well as real time really need to change. You know, if you go back to that earlier discussion we were having about shared-nothing systems, the fact that you can’t scale and build transactional architectures has always led us to this state where you have databases that are designed for transactions, you have data warehouses that are designed for analytics, and you have data lakes that are designed for essentially cost savings, and that doesn’t work in the modern era because people want to infer and understand data in real time. If the data sets are so much bigger, then you need scalable transactional infrastructure, and that’s why we designed the architecture that we did.
Scale Up is Back to the Future
A question we’re exploring today is will there be a return to shared everything scale up architectures?
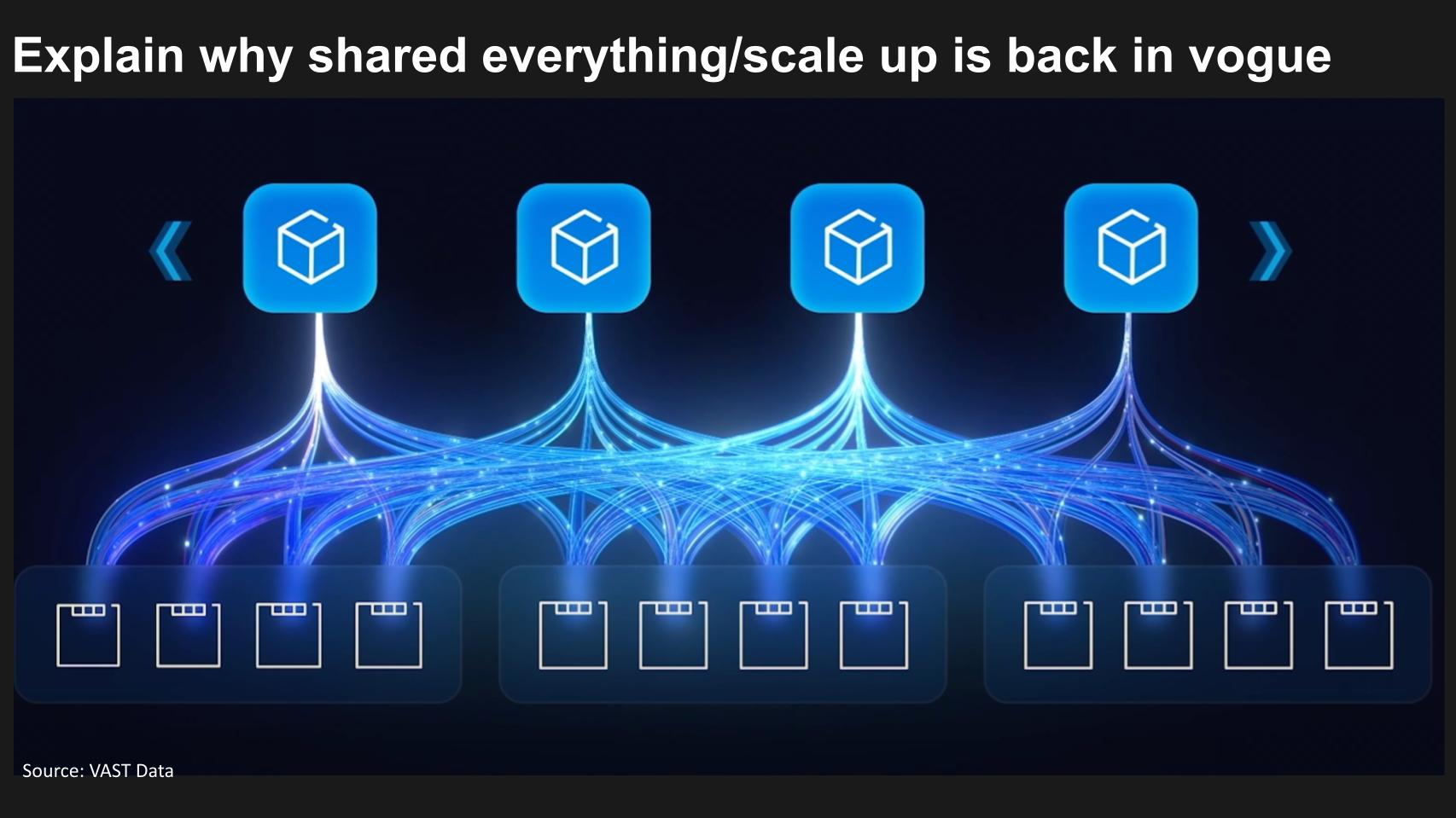
This chart from a VAST presentation depicts many nodes with shared memory – those little squares inside the big squares – with access from all these connections in a high speed network. The cubes represent compute. The compute has access to all the data in the pooled memory/storage tier, which is being continually enriched by AI and some metadata IP which we’ll talk about later.
Q. Renen and Jeff, explain your perspective on why we need scale up shared everything to accommodate exascale data apps in the future. And why is this suddenly possible now?
Renen Hallak
It’s possible because of fast networks and because of new types of media that is both persistent and fast and accessible through those fast networks. None of these things could have been done at this level before we started, and that’s another reason why we didn’t see them before. Why do we need them? It’s because of the scale limitations that we’re reaching. It’s a short blanket in the shared-nothing space. You can do larger nodes, and then you risk longer recovery times when a node fails. They can take months, in which case, you can’t have another node fail without losing access to information, or you can have smaller nodes and a lot more of them, but then from another direction, you’re risking failure.
Because you have more nodes, statistically they’re going to fail more often. From a performance perspective also, as you add more nodes into one of these shared-nothing clusters, you see a lot more chatter. Chatter grows quadratically, and so you start to exhibit diminishing returns in performance. All of that limits the scale and resilience and performance of these shared-nothing architectures. What we did when we disaggregated, we broke that trade-off. We broke it in a way that you can increase capacity and performance independently but also such that you can increase performance and resilience up to infinity, again, so long as the underlying network supports it.
Jeff Denworth
The network is what allows for disaggregation or the decoupling of persistent memory from CPUs, but the second thing that had to happen is some invention, and what we had to build was a data structure that lived in that persistent memory that allowed for all the CPUs to access common parts of the namespace at any given time without talking to each other. So it’s basically a very metadata-rich transactional object that lives at the storage layer that all the CPUs can see and talk to in real time while also preserving atomic consistency, and so once you’ve done that, you can think of this architecture not as a kind of like a classic MPP system that most of the shared-nothing market kind of uses as a term to describe what they’re doing but rather more as a data center-scale SMP system, where you just have cores and one global volume that all the cores can talk to in a coherent manner. So it’s basically like a data center-scale computer that we’ve built.
Note: The VAST network is either Infiniband or Ethernet. VAST shared that most of its customers use Ethernet.
Q. The first reaction one might have is, we’ve had tens if not hundreds of billions of investment in the scale-out data center architecture. Is it that you’re drafting off the essentially rapid replacement of big chunks of that data center infrastructure for the LLM build out with this new super fast network that you’re running on because it’s being installed so rapidly at the hyperscalers and elsewhere?
Renen Hallak
LLMs are the first piece of this new wave. It’s going to span way beyond language models and text, but yes, there is a new data center being built in these new clouds, in enterprises in a way that didn’t exist before, and this new data center, its architecture perfectly matches our software architecture in the way that it looks. You have GPU servers on one side. You have DPUs in them in order to enable the infrastructure layer to be very close to the application in a secure manner, and then you have a fast network and SSDs in enclosures on the other end, and that’s the entire data center. You don’t need anything beyond that in these modern locations, and we come in and provide that software infrastructure stack that leverages the most out of this new architecture.
[Renen Hallak explains the new wave, starting with LLMs but going further].
Turning Strings into Things
Let’s come back to this funny phrase we use – turning strings into things.
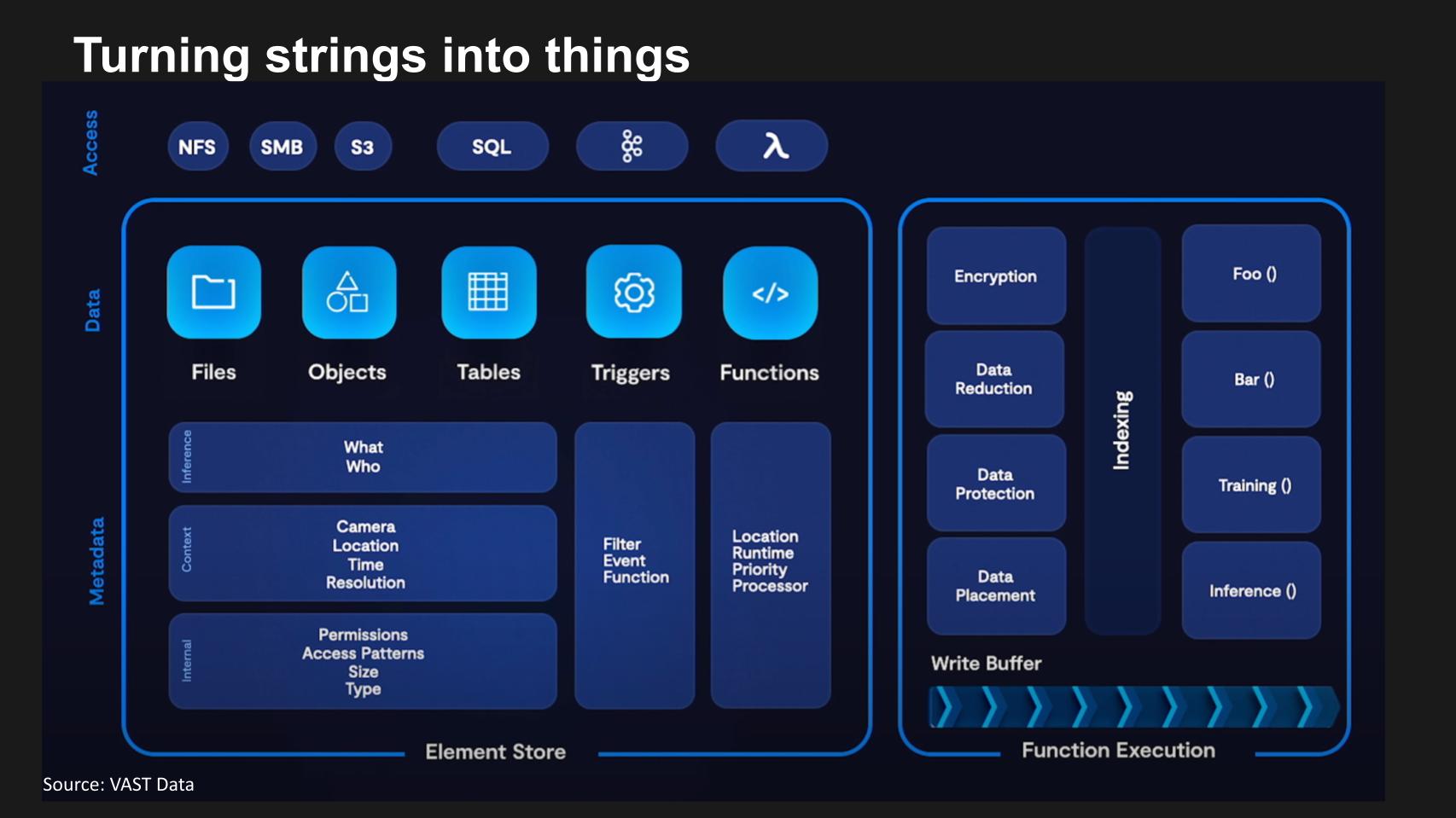
In our previous episodes we’ve explored the idea of Uber for all. We’ve had Uber on the program to explain how in 2015 they went through a major software initiative to, among other things, create essentially a semantic layer that brought together transaction and analytic data and turned things that databases understand (e.g. ASCII code, objects, files, etc.) into things that are a digital representation of the real world (riders, drivers, locations, ETAs, destinations, prices, etc.).
In this example above we have the data up top in NFS or S3 or structured SQL in the form of files, objects and tables- which we can discuss later…but our inference is that the metadata at the bottom level gets enriched by triggers and functions that apply AI and other logic over time and this is how your turn strings into things.
Q. Is our understanding correct and can you please elaborate on how you do this?
Renen Hallak
I think it is. The way our system is built, it’s all data based. What do we mean by that? Data flows into the system, and then you run functions on that data, and those functions are very different than what used to be run on strings. These are inference functions on GPUs. They’re training functions on GPUs. They enable you to understand what is within these things and then to ask intelligent questions on it because it’s not just metadata that gets accumulated right next to the raw information. It’s also queryable. All of this is new, and it brings, again, computers closer to the natural world rather than what was happening over the last two decades where we needed to adapt to the strings. Now computers are starting to understand our universe in a way that they couldn’t before, and as you say, it will be actionable.
Jeff Denworth
But action is a byproduct of being able to make intelligent decisions. Well, I should say, you know, it should be a byproduct of that, and so this is why this architecture that we’ve built is really important, because what it allows for is the strings to be ingested in real time. As I mentioned, we built a distributed transactional architecture that, you know, typically you’ve never seen before because of the crosstalk problems associated with shared-nothing systems, but at the same time, if I can take that data and then query it and correlate it against all of the other data that I have in my system already, then what happens is I have real-time observability and real-time insight to flows that are running through the system in ways that you’ve never had before. Typically you’d have, like, an event bus that’s capturing things and you’d have some other system that’s used for analytics, and we’re bringing this all together so that, you know, regardless of the data type, we can essentially start to kind of process and correlate data in real time.
Q. There seems to be a need to unify all the metadata or the intelligence about the data, but can you elaborate on your roadmap for building the database functionality over time that’s going to do what Jeff was talking about, which is observe changes streaming in and at the same time query historical context and then take action. What might that look like? As you’ve said, you built out the storage capabilities over time, and now you’re building out the system and application level functionality. Tell us what your vision for that looks like.
Renen Hallak
In this new era, the database starts as metadata. In fact, you can think of the old data platforms as having only metadata because they didn’t have the unstructured piece. They didn’t have those things in them, but the first phase is, of course, to be able to query that metadata using standard query language, which is what we came out with earlier this year. What the big advantage, of course, of building a new database on top of this new architecture is that you inherit that breaking of trade-offs between performance and scale and resilience. You can have a global database that is also consistent. You can have it extremely fast without needing to manage it, without needing a DBA to set views and indexes, and so what you get is the advantages of the architecture.
As we go up the stack and add more and more functionality, we will be able to displace not just data warehouses but also transactional databases, and in fact, we find a trade-off there between row-based and column-based traditional databases. You don’t need that when the underlying media is 100% random access. You don’t need ETL functions in between to maintain multiple copies of the same information because you want to access it using different patterns. You can just, again, give different viewpoints or mount points into the same underlying data and allow a much simpler environment than was possible before.
Addressing Historical Tradeoffs Between Latency and Throughput

Let’s talk more about how data management connects to new data center architectures. Above we show a graphic implying that shared persistent memory eliminates historical trade-offs. We’ve touched a little bit upon that, but let’s go deeper.
Using shared persistent memory instead of slow storage for writes in combination with a single tier of, let’s say, all flash storage, brings super low latency for transactional writes and really high throughput for analytical reads. So this ostensibly eliminates the many-decades-long trade-off between latency and throughput.
Q. Please comment and add some color to how you address that tradeoff. And we see companies like Snowflake which, as you know, is claiming to add unstructured data, just as Oracle did many years ago. But there is a cost challenge. So when you talk about the scale issue, can you address any cost comparisons when you’re at that 20X scale that you mentioned?
Jeff Denworth
So to start, in terms of the data flow, as data flows into the system, it hits a very, very low latency tier of persistent memory, and then as what we call the write buffer fills up, we take that data and then we migrate it down into an extremely small columnar object. If you’re building a system in 2023, it doesn’t make sense to accommodate for spinning media, and if you have an all-flash data store, the next consideration is, well, why would you do things like classic data lakes and data warehouses have been built around for streaming. With flash, you get high throughput with random access, and so we built a very, very small columnar object. It’s about 4,000 times smaller than, let’s say, an Iceberg row group, and that’s what gets laid down into SSDs that is then designed for extremely fine-grained selective query acceleration. And so you have both, and about 2% of the system is that write buffer.
The remaining 98% of the system is that columnar-optimized random-access media, and then when I put the two together, you can just run queries against it and you don’t really care. So if some of the data that you’re querying is still in the buffer, of course, you’re reading on a row basis, but it’s the fastest possible persistent memory that you’re reading from, and so in this regard, even though it’s not a data layout that’s optimized for how you would think queries naturally should happen, it turns out that we can still respond to those data requests extremely fast time thanks to persistent memory.
Now, to the the point I think you were getting to, George, around cost, we started with the idea that we could basically bring an end to the hard drive era, and every decision that we make from an architecture perspective presumes that we have random-access media as the basis for how we build infrastructure, but cost is a big problem, and then flash still carries a premium over hard drive-based systems, and that’s why most data lakes today still optimize for hard drives. But people weren’t really thinking about all that could be done from an efficiency perspective to actually reconcile the cost of flash such that you can now use it for all of your data, and so there’s a variety of different things that we do to bring a supernatural level of efficiency to flash infrastructure.
One of those is basically a new approach to compression which allows us to look globally across all the blocks in the system but compress at a level of granularity that goes down to just two bytes, and so it’s the best possible way to find patterns within data on a global basis and is designed to be insensitive to noise within data so that we’d always find the best possible reductions. Typically our customers see about 4:1 data reduction, which turns out is greater than the delta between flash and hard drives in the marketplace today. So it’s completely counterintuitive, but the only way to build a storage system today that is cheaper than a hard drive-based data store is to use flash because the way that you can manipulate data allows you to find a lot more patterns and reduce data down in ways that would just not be sensible to do with spinning media.
Implications for the Sixth Data Platform
Let’s wrap up with some thoughts on what we’ve learned today and what it means for the emergence of the next great data platform.

We see VAST Data as a canary in the coal mine, and what we mean by that is this new approach to data center architectures shines a light on the limitations of today’s data platform. So of course, the big question over time is does this approach represent the sixth data platform or is it a piece of the value chain?
And the second part of that question is, how are the existing data platforms going to respond? We think a determining factor is going to be the degree to which companies like VAST can evolve their ecosystem of ISVs to build out the stack. Of course, the starting point, as we heard earlier, is really a full-blown analytic DBMS. As well, existing players must figure out how to unify data and metadata, leverage AI to turn strings into things and address the limitations of shared nothing architectures at scale.
We’ll close with some final thoughts including how VAST sees accommodating existing tools to take raw data and turn it into refined data products. And as well, tools to address the pipelines, the observability, the quality rules and how they expect or intend to accommodate that sort of migration over time?
Renen Hallak
I think in the same way that we have done it today. We support standard protocols, we support standard formats, and we support multi-protocols and multi-formats. For example, if you look back to our storage days, you’re able to write something via a file interface and then read it through an object. That allows you to continue working in the same way that you did but to move into the new world of cloud-native applications. The same is true at the database layer. Us providing the standard formats and protocols allows you to start using the VAST platform without needing to change your application, but over time, enables you to do things that you couldn’t do before. Back to Dave’s question about does it start with a DBMS, I think the last wave of data platforms did because it was focused on structured data.
I think the next wave of data platforms, I like to use the analogy of the operating system. It’s no longer just a data analytics machine. It’s a platform that provides that infrastructure layer on top of new hardware and makes it easy for non-skilled enterprises and cloud providers to take advantage of these new AI abilities, and that’s what we see in the future, and that’s what we’re trying to drive in the future.
Jeff Denworth
I think we generally think that solving old problems isn’t that fun, and so if you think about what’s happening now, people are trying to bring AI to their data, and there’s a very specific stack of companies that are starting to emerge. And you talked a little bit about our funding. We went and did some analysis of the companies that have increased their valuation by over 100% this year, of real-size companies, so companies that are valued over $5 billion, and it’s a very, very select number of organizations. At the compute layer, it’s NVIDIA. At the cloud layer, it’s a new emerging cloud player called CoreWeave which is hosting a lot of the biggest large language model training. In inference applications, it’s us, it’s Anthropic, and it’s OpenAI, and that’s it. So something is definitely happening, and we’re trying to make sure that we can not only satisfy all these new model builders but also take these same capabilities to the enterprise so that they can all benefit.
This was an enlightening research exercise for us to better understand a new perspective on the shared-nothing architecture, which we’ve grown over two decades to take for granted. Once you revisit that assumption, when you can think about scale up is back instead of scale out, then everything you build on top of that can be rethought. Thanks to VAST for participating and helping us question those assumptions. It was particularly interesting to see the idea that we need to unify files, objects, and tables as one unified namespace; and that there’s no real difference between data and metadata. It all kind of blurs as you turn these strings into things, and the one thing we keep focusing on is that ultimately, when you turn strings into things, there is a semantic layer that has to represent these things richly and the relationships between them. That’s what’s going to allow us to separate compute from data where you can have composable applications talking to a shared infrastructure.
It seems VAST is on the forefront of building towards that vision and as always we’ll be tracking the journey to the sixth data platform.
[Watch and listen to the final thoughts from today’s Breaking Analysis participants].
Keep in Touch
Thanks to Alex Myerson and Ken Shifman on production and handling our podcasts and media workflows for Breaking Analysis. Special thanks to Kristen Martin and Cheryl Knight who help us keep our community informed and get the word out. And to Rob Hof, our EiC at SiliconANGLE.
Remember we publish each week on Wikibon and SiliconANGLE. These episodes are all available as podcasts wherever you listen.
Email david.vellante@siliconangle.com | DM @dvellante on Twitter | Comment on our LinkedIn posts.
Also, check out this ETR Tutorial we created, which explains the spending methodology in more detail.
Watch the full video analysis:
Note: ETR is a partner of theCUBE Research and SiliconANGLE. If you would like to cite or republish any of the company’s data, or inquire about its services, please contact ETR at legal@etr.ai.
All statements made regarding companies or securities are strictly beliefs, points of view and opinions held by SiliconANGLE Media, Enterprise Technology Research, other guests on theCUBE and guest writers. Such statements are not recommendations by these individuals to buy, sell or hold any security. The content presented does not constitute investment advice and should not be used as the basis for any investment decision. You and only you are responsible for your investment decisions.
Disclosure: Many of the companies cited in Breaking Analysis are sponsors of theCUBE and/or clients of Wikibon. None of these firms or other companies have any editorial control over or advanced viewing of what’s published in Breaking Analysis.