
The role of big data in the fight against COVID-19.
We’ve been reporting weekly on CIO sentiment and the IT spending outlook in the face of coronavirus. We’re tracking a couple of developments from analytic database companies that are notable.
Snowflake and Starschema Announce Free Public Data Set
Last week, cloud analytic software company Snowflake announced a free, analytics-ready public COVID-19 data set for the Snowflake Data Exchange. Snowflake claims this is the only comprehensive, free-of-charge data set that is readily available for data modeling and analytics that does not require data cleansing and preparation. It also claims the Johns Hopkins data set that many of us have been visualizing since the early outbreak of coronavirus, is not analytics-ready – see graphic below.
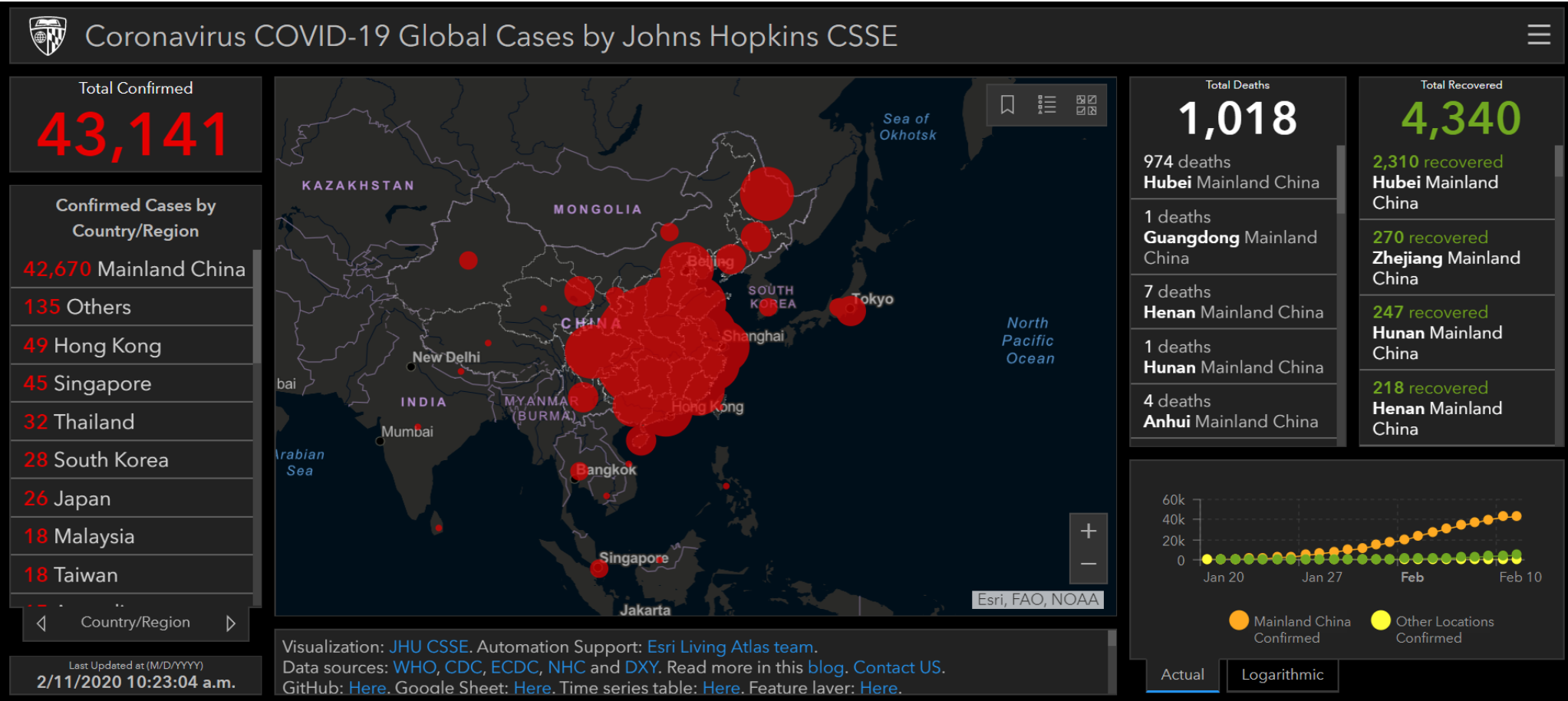
How do Snowflake and Starschema define “Analytics-Ready?” In a blog post, Snowflake summarized Starschema’s position on this by identifying four criteria:
- Stored in the cloud.
- Easy to add additional data sources.
- Low or no maintenance tech – i.e. minimal labor to manage the infrastructure, ideally with high degrees of automation.
- There must be a way to ubiquitously share the data set with anyone who wants it. The hosting data exchange must be cloud-based. It also has to enable the data provider to easily update the data set with additional data sources, so data consumers receive those updates in real time – so sort of cycling back to 1 and 2 above.
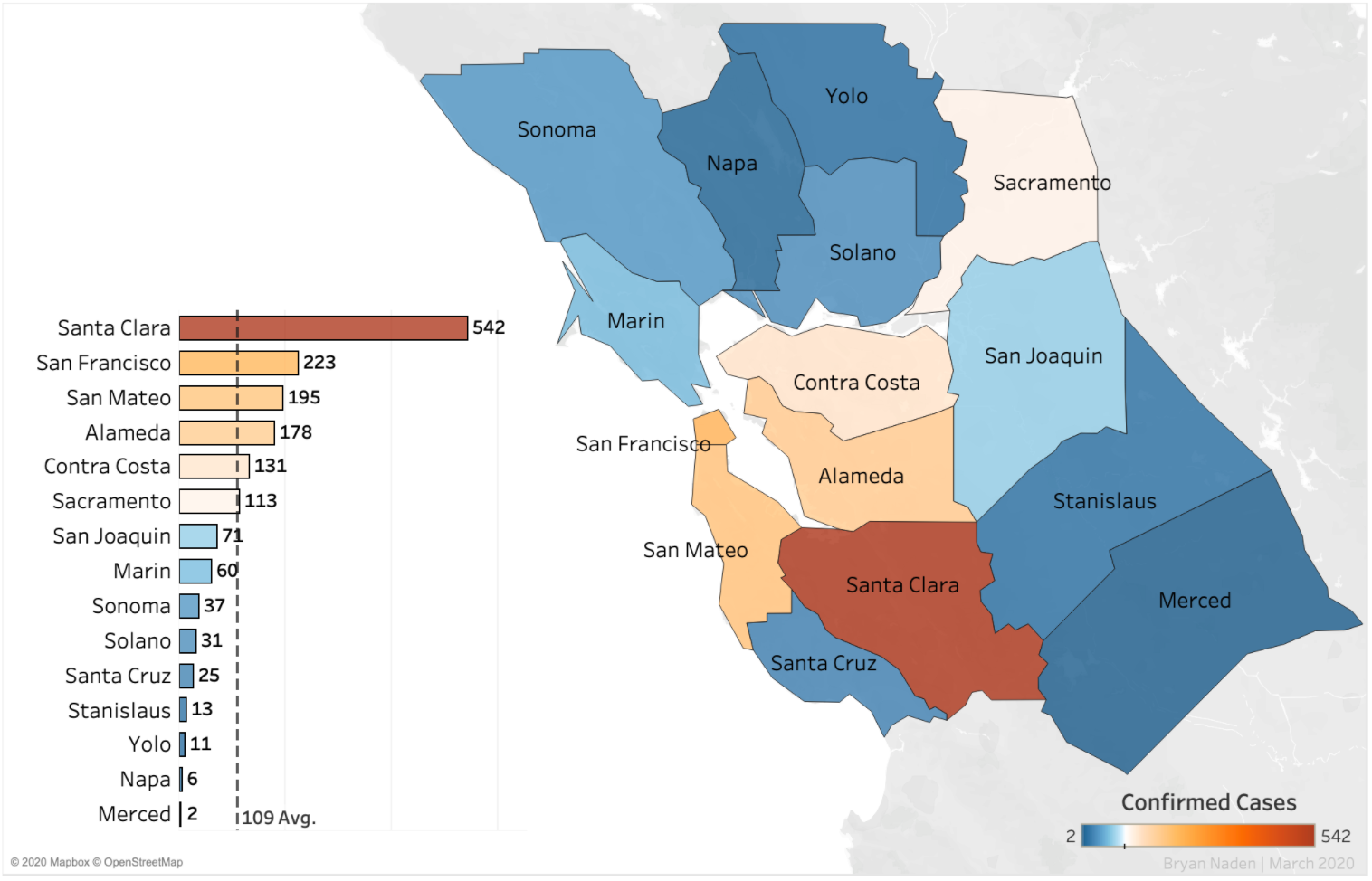
Indeed, the New York Times has a data set on Github that it’s sharing for free with its readers. Here’s how it’s displayed:

Note the caveat in blue text.
Here’s a picture of the Starschema data from the Snowflake data store– beautiful and ostensibly searchable:
New Workloads Emerging in the Cloud
For the past two years we’ve been reporting on a new type of workload that is driving more real time insights for customers. Specifically, we’ve said that while the first generation of cloud workloads were largely about IaaS, compute, object storage and related infrastructure…there’s a new wave that is leveraging troves of data by applying machine intelligence (AI & ML) and using the cloud for massive scale.
We’ve called this the new innovation cocktail. Whereas the industry source of innovation, used to be Moore’s Law, it’s being replaced. Below is a tweet I put out yesterday, imploring author Tom Friedman to move beyond his Moore’s Law narrative and recognize the role of data, machine intelligence and cloud as combinatorial technologies that are the new mainspring of innovation.
I think the team @CNBC is doing a phenomenal job covering #COVID19 & Coronavirus. I appreciate their great weekly guests like @tomfriedman. Tom I want to ask you to re-think your Moore's Law narrative. IMHO the mainspring of innovation is no longer Moore's Law… pic.twitter.com/Z1Fpt2KLzO
— Dave Vellante (@dvellante) March 30, 2020
New Cloud-based Analytic Data Stores
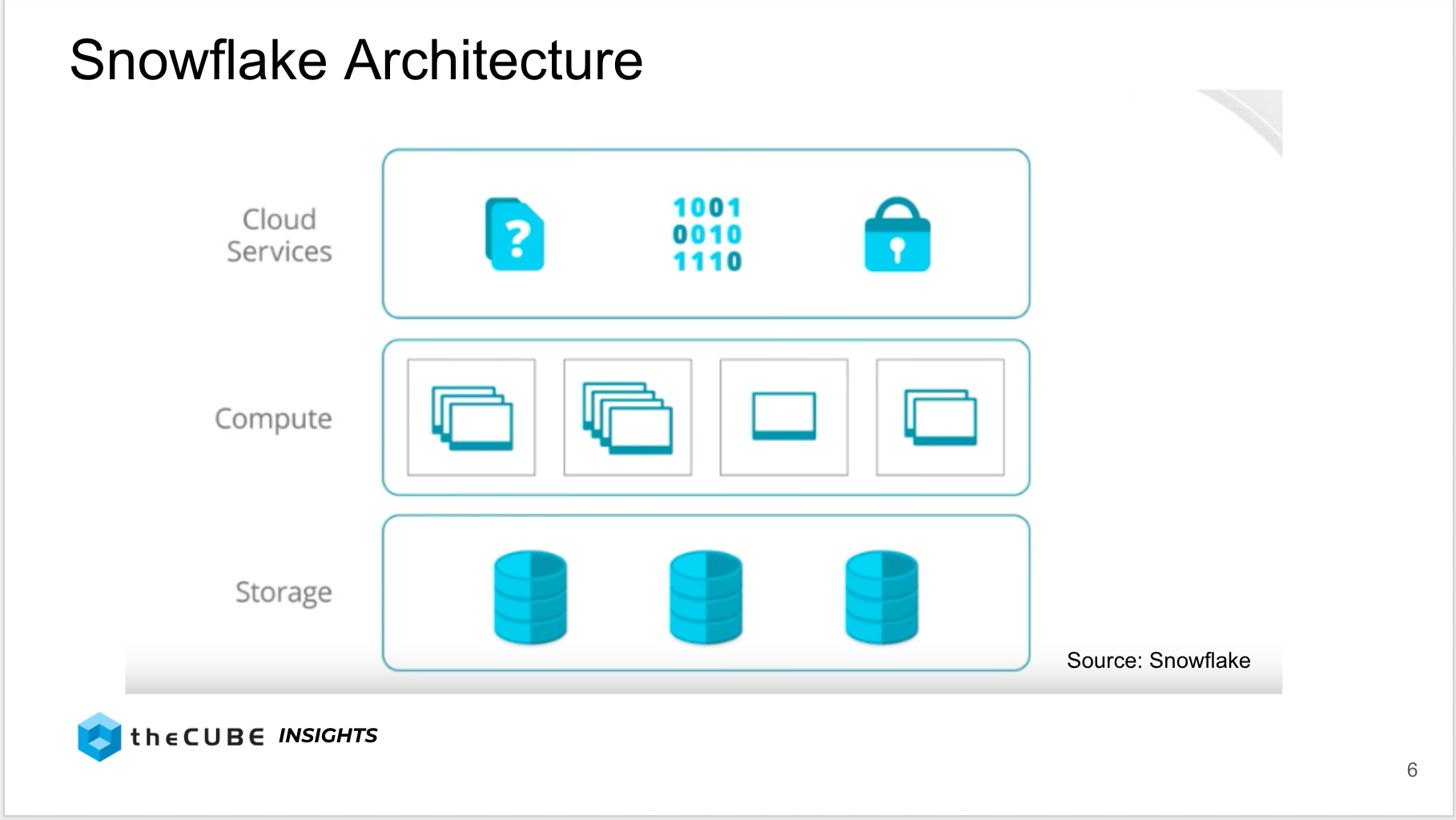
Last summer we reported on this new emerging workload in the cloud and specifically drilled into some of the players with spending momentum based on data from Enterprise Technology Research. In that research we pointed out that Snowflake was one of the first software companies to allow the granular scaling of compute, independent of storage. Rather than having to add infrastructure in chunks, this innovation allowed customers the flexibility to size their infrastructure based on workload needs, not a vendor’s limits – see graphic below:
We’ve also reported on the momentum that not only Snowflake was seeing but AWS’ RedShift as well as other cloud-based analytic databases from vendors like Microsoft. RedShift has followed Snowflake’s lead and at the last re:Invent, AWS announced the capability to scale compute independent of storage. This has been a game-changer for many customers who report not only that the economics are superior but also the capability adds new levels of flexibility and business agility.
What About On-Prem Workloads?
We’ve been following the big data space since its early days. We witnessed the ascendency of the MPP database vendors and the acquisitions of the then-emerging on-prem database companies like Netezza (IBM), Greenplum (EMC), Aster Data (Teradata) and the ParAccel, which was the basis for Amazon’s Redshift.
One of the companies that we’ve tracked closely over the years is Vertica. Of all these MPP columnar stores, Vertica is the one brand that remains in tact as a separate name. Vertica was one of the first to nail the column store architecture and recently, Micro Focus announced it was investing $70-$80M in two areas, security and Vertica. Vertica also recently announced the 10.0 version of its database.
Vertica claims to be the only (or at least the first) company that allows the granular and independent scaling of compute and storage for both cloud and on-prem workloads. Whereas Snowflake for example, which was early to separate compute from storage, would tell you that they are cloud-first, born-in-the-cloud and cloud-only. Typically such companies would poo poo a company taking its on-prem stack and putting it in the cloud.
From Vertica’s perspective it has no choice but to try and make its legacy an advantage. Vertica will claim that not only has it developed its cloud offering using modern code, but also that it is embracing emerging innovations such as in-database ML. As well?, Vertica is extending its capabilities to leverage modern tools like PMML models, Python, TensorFlow, simplifying the experience for customers and adopting cloud licensing and pricing models.
Vertica will also point out that there are a number of workloads that won’t go into the cloud and they are in the best position to capture that work; while at the same time differentiating with a cloud and multi-cloud approach.
Which Model is Right?
In our view, both approaches are viable. From the perspective of a company like Snowflake or AWS with RedShift, there’s no question that their cloud-native, cloud-only approach brings consistency, flexibility and simplicity that you won’t get from a data store developed mid-last decade for on-prem workloads.
At the same time, the reality is that many workloads live on-prem and will stay there for some time due to a variety of reasons (e.g. physics, corporate and government edicts, migration costs, etc.).
In speaking with customers we can boil it down to two simple realities:
- Cloud native analytic databases (e.g. Snowflake) give us a degree of simplicity and flexibility that are compelling, especially for new workloads;
- But the more mature stack of Vertica in terms of its ACID properties and the richness of its support for many use cases, including our on-prem / hybrid workloads make it attractive – especially for Vertica’s existing customers.
Circling Back to COVID-19 & Analytic Databases
One of the nuances of modern analytics is their ability to ingest a variety of data sources, many of which live in the cloud. As it relates to coronavirus forecasts, there’s so much data, much of it conflicting, and the sources of data are often large, varied, messy and dispersed. Modern techniques are being used to ingest, clean, shape, analyze and visualize the results in as near real time as possible.
Here are some of the use cases we’re seeing emerge:
- Forecasting the impact of coronavirus in terms of its presence in granular regions.
- Inferring the relationship between reported and actual cases based on data. from previously affected areas.
- Predicting the expected crush faced by hospitals based on available capacity.
- Predicting the corollary effects of the coronavirus surge from injuries and illness unrelated to coronavirus.
- Predicting the likely unfortunate death rates and the timing.
- Forecasting the financial impacts of the crisis.
- Monitoring the efficacy of real world trials and predicting their mid-term effect.
- Tracking the sentiment of the population as the virus spreads.
- Modeling the effect of life style changes on halting the spread of the virus.
And many others.
The key point is ten years ago this type of analysis would not be possible, at least in terms of its depth, speed, accuracy and ability to iterate as new data points come to light. Today we are operating in near-real-time and the combination of data, data science tools, analytic databases and cloud make this possible.
A New Era – Call it Cloud 2.0 or Digital Transformation for Real
The coronavirus crisis will bring permanent change to certain aspects of industry. As an example, retail was already getting disrupted and COVID-19 will only accelerate that trend. Airlines are learning how to deal with massive swings in demand and may face significant consolidation as travel restrictions elongate. Industries affected by supply chain disruptions may choose to sub-optimize efficiency in favor of business resiliency.
In our view, emerging analytics database architectures such as Snowflake’s are going to continue to gain momentum. The new workload types that we described earlier and have been reporting on for two years are real. They are a fundamental component of digital transformation. Why? because digital is all about putting data at the core and these new data stores are critical to enabling that transformation.
At the same time, we continue to look for companies that can support on-prem analogs to these workloads. In our view, Vertica is a leader in this regard, more so than some of the other mid-2000 MPP columnar store players. Suppliers that can meet this demand will continue to be in a position to compete. But they must simplify their cloud experiences and not let the cloud native databases run away with the prize.
Here’s a video analysis we did in conjunction with the Vertica Big Data Conference that contains further analysis of these trends.


