
With George Gilbert
Over the past several months we’ve produced a number of in-depth analyses laying out our mental model for the future of data platforms. There are two core themes: 1) Data from people, places, things, and activities in the real world drives applications, not people typing into a UI; and 2) Informing and automating decisions means all data must be accessible. That drives a change from data locked in application silos to application logic being embedded in a platform that manages an end-to-end representation of an enterprise in its data.
This week’s Snowflake Summit further confirmed our expectations with a strong top line message of “All Data / All Workloads” and a technical foundation that supports an expanded number of ways to access data. Squinting through the messaging and firehose of product announcements, we believe Snowflake’s core differentiation is its emerging ability to be a complete platform for data applications. Just about all competitors either analyze data or manage data. But no one vendor truly does both. To be precise, managing data doesn’t mean running pipelines or serving analytic queries or AI/ML models. It means managing operational data so that analytics can inform or automate operational activities captured in transactions. With data as the application foundation, the platform needs robust governance.
In this week’s Breaking Analysis, we try to connect the dots between Snowflake’s high level messaging and its technical foundation to better understand the core value it brings to customers and partners. As well, we’ll explore the ETR data with some initial input from the Databricks Data + AI Summit to assess the position and prospects of these two leaders along with the key public cloud players.
A Tale of Converging Use Cases
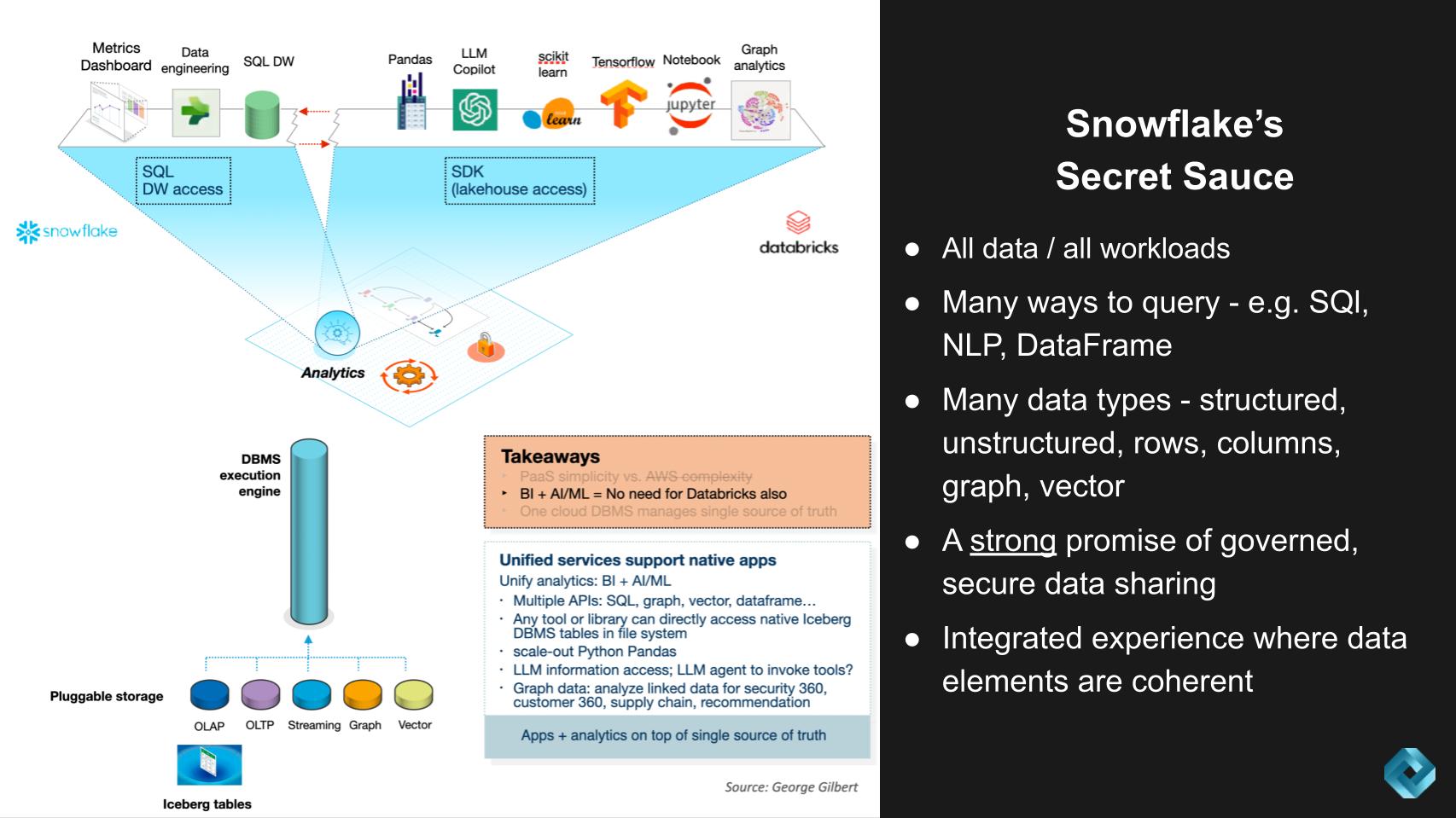
We’ve shown versions of the above slide in previous research posts but we’ve updated it. The figure above talks to the traditional strengths of Snowflake coming at the problem from a database management perspective and Databricks from a data science machine learning angle…and they’re both now trying to expand their opportunities into each others’ domain.
Snowflake’s Secret Sauce
- All data, all workloads rather than developing with many different analytic and operational databases
- Access methods that work across storage formats: SQL, python dataframe, graph analytics*, vector search*, natural language search via LLM Copilot*, notebook*, AI/ML libraries (pre-LLM), LLM data engineering pipelines for complex content (documents)*
- Storage formats accessible through different access methods: OLAP column store, OLTP row store*, graph*, vector embeddings*
- Unified governance model
Snowflake’s Potential Exposure
- High compute overhead and price of a powerful, general purpose data platform makes 20-30% of workloads that are data engineering pipelines vulnerable to lower-cost, external engines. Our research shows 5Tran, dbt, and other partners are seeing customers try to trim Snowflake budgets by moving their pipelines to AWS EMR (Spark), Databricks, Starburst, etc. The real question is what’s the true cost and benefit of moving everything into Snowflake versus keeping some of the data engineering off platform. A more complete economic analysis is necessary to address this question.
- Transition to LLMs enables AI/ML toolchain market reset. Snowflake is betting primarily on NVIDIA’s tools. No one has a track record in this market yet.
Databricks’ Secret Sauce
- Mature and integrated tool chain for supervised machine learning (pre-LLM).
- Intense investment (development and acquisition) and focus on supporting LLM training, fine-tuning, and inference.
- Ability to harness the energy of the data engineering community for pipelines that are too expensive to run in a data warehouse designed for interactive workloads
- Accumulation of huge amounts of customer data in data lakes that include raw ingest, normalized tables, as well as final data products for consumption.
- A strategy to provide coherent governance of heterogeneous data assets beyond the data lake.
Databricks’ Potential Exposure
- Development tools (in this case AI/ML/LLM) and data engineering pipelines as businesses have never been as large as managing data or building applications.
- Support for business intelligence workloads in Photon SQL is immature relative to Snowflake.
Snowflake High Level Narrative
In thinking about Snowflake and what we’ve been talking about and learned at this Summit, our view is the high level narrative is strong…the technical foundation is differentiable but sometimes it’s challenging to connect the two layers together.
We asked Frank Slootman on theCUBE this week to describe the narrative in his words:
Well, the narrative for Snowflake as a data cloud is, it’s a multi-layered cake. We obviously have infrastructure elastic consumed by the drink. We have live data in extraordinary amounts. We have the complete workload enablement layer, the programmability platform, which is Snowpark, the marketplace, and then the transactional model. People can monetize data and applications. So the strategy is, we enable data engineers big time, that’s sort of our… I call ’em our homies. (laughs). Those are the people that we’re super close to historically, because we’re a database company from way back. But we now have completely embraced the functional layer that lives above the data layer. You have data engineers and software engineers, and we now said, “look, software engineers and data engineers, we address both these audiences.” It is a big vision, but we think in the cloud you have to have this.
In an on-premise environment, it’s very, very different. You can really stratify these things, but in the cloud it’s like, wait a second. All of a sudden it’s like, who manages security and governance here? Well, it’s not you, it’s them. So in other words, unless we step into that void and say, “No, no, no, we own it.” If you’re in Snowflake, you’re safe, you’re compliant, all these things. That’s a really important thing, because if we’re not doing it, who’s going to do it? So there’s a lot of discomfort around, where do software engineers live, where do data engineers live? How do they interact? We want to really usurp that space, if you will.
Slootman’s point about who owns security and governance is an important one. The cloud uses a shared responsibility model. Multiple clouds means many shared responsibility models. And for many customers this is a complicated situation. Like Apple with the iPhone, Slootman is saying, “if you’re in Snowflake, we’ve got you covered.”
This is the big promise and the hard part of what Snowflake does. Everything is integrated into a single, unified platform. This is a really important point, and one of the differentiators that sometimes isn’t appreciated, including the potential cost tradeoffs cited above. So this is where we want to drill in today.
Snowflake is not a Data Warehouse, it’s a Comprehensive Data Flow Execution Engine
We believe there’s a movement away from a world where people drive applications through mobile or web UIs. Instead, data from the interaction of people, places, and things will drive applications. That transition means the application platform has to be built around capturing data and informing or automating transactions based on analytics. So rather than raw cloud infrastructure, developers have to build applications on a data platform. As with all application platforms, there is a trade-off between integrated simplicity and the power of choice.
Snowflake was initially recognized as a SQL data warehouse. But it was always designed to be a more general purpose engine that could support many access methods and manage many data types. The objective was to push out the trade-off between simplicity and choice.
SQL was just the original access method. Subsequently, it integrated DataFrames, a more flexible interface which Python programmers frequently use to query, explore, and cleanse data. Notably, with the surge in Python programmers not only for data science but also for data engineering, this gave an expanding user group the same backend data management capabilities that were previously only accessible to SQL programmers.
Once DataFrames were supported, the same data science and engineering community that grew up on Spark and the open source ecosystem could access the data platform.
LLMs require new toolchains beyond the traditional DataFrame-based ones for supervised AI/ML. Databricks is building and buying technology, including Mosaic. Snowflake is betting that it can close the gap it had in supervised AI/ML tools by partnering with NVIDIA for its Enterprise AI stack. NVIDIA has been investing as long as anyone in tools for training, fine-tuning, and running LLMs. So Snowflake is going to offer NVIDIA’s tools within its new Container Service. Developers can access LLMs via Snowpark or Streamlit or a Hex notebook, among other interfaces.
Neeva’s technology will be instrumental in introducing natural language search capabilities. Initially, Neeva was focused on consumer search but Snowflake will apply Neeva technology to enterprise use cases by translating natural language into SQL queries. That will expand the audience of people who can directly access data. In addition, with the technology acquired from Applica that is part of the Document AI functionality, complex documents can have their own pipelines so their contents can be accessible from any of the query access methods.
On Data Storage and Management
Having one engine manage many data types is simpler than using a dozen separate operational databases from AWS and several more analytic databases. Snowflake spans across structured, semi-structured, and unstructured data. Snowflake’s “pluggable storage” capability allows data to be stored in column format for analytics and, with Unistore, in rows for transaction data. Snowflake announced Unistore at its conference last year and promised that its shipment is getting closer.
The flexibility to manage different data types continues to expand. Not only will Snowflake support vector data for similarity search and embedding in AI/ML models, but third-party vector databases such as Pinecone demonstrated plugging-in through its Container Services. Graph data has been esoteric to many, but it’s becoming more important for applications that need to capture all the rich connections in data.
Snowflake’s vision of an integrated data platform for applications may have its best showcase with the supply chain ISV Blue Yonder. It is rehosting its suite of legacy applications on Relational.ai’s graph database. The graph database can manage the supply chain data model and application logic while Snowflake manages the operational and analytic data. By managing Blue Yonder’s data in Snowflake, customers can integrate their supply chain data with the rest of their enterprise data estate.
[Listen to George Gilbert explain the differences between Snowflake and AWS].
Spending Data Shows Snowflake & Databricks Converging
Let’s dig a little bit more into the ETR data, and see what it tells us.
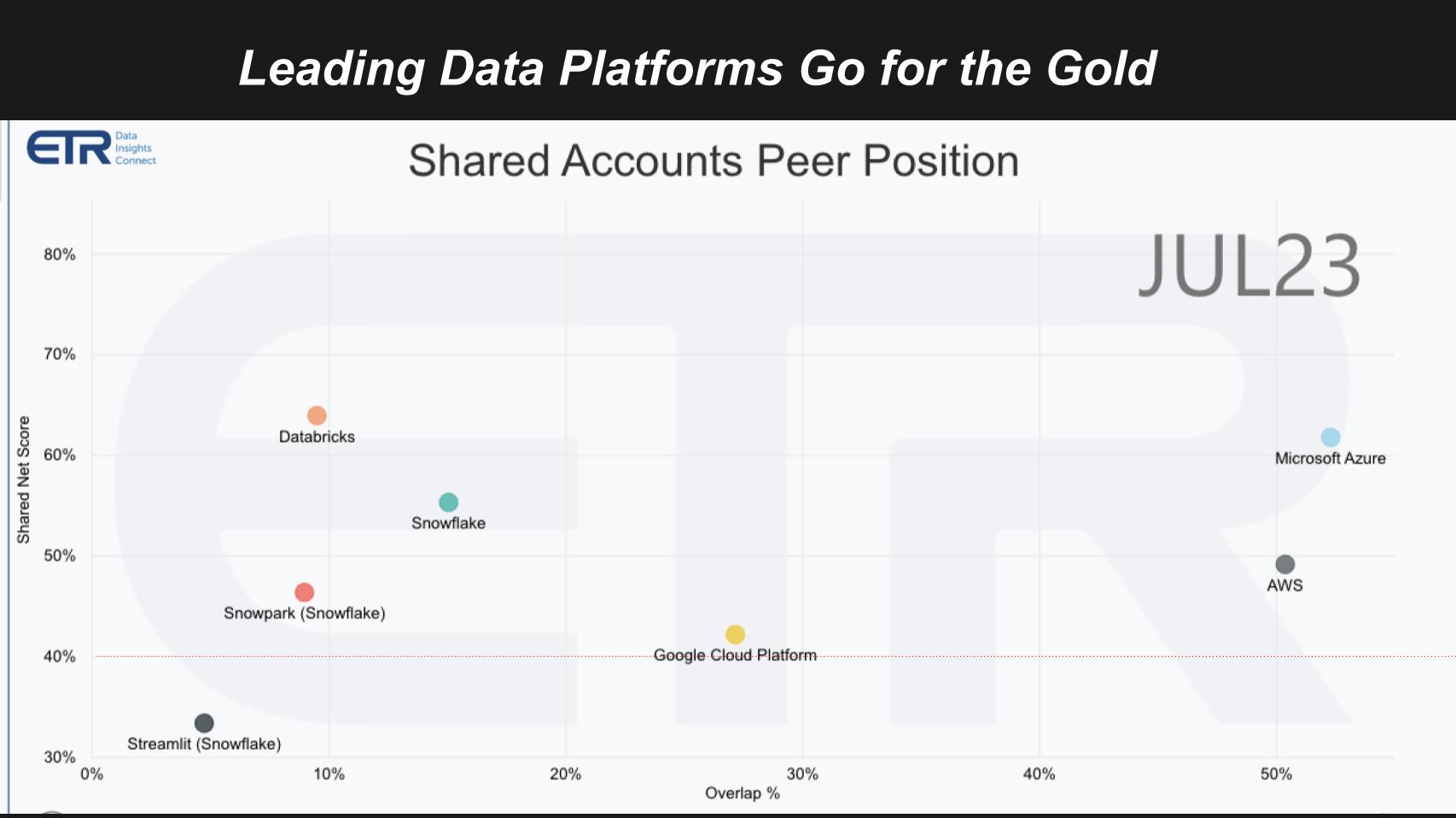
The slide above shows Net Score on the vertical axis. Net score is a measure of spending momentum. The horizontal axis it’s a measure of presence in the dataset. Here we plot several companies that we think are vying for the future of the new data stack. The red dotted line is an indicator of a highly elevated spending momentum,
The big three cloud players not only lead in cloud infrastructure, they also lead in analytics, database and ML/AI. Microsoft Azure in the upper right, AWS is prominent and GCP is right on the 40% line with a more than respectable presence.
Then you see we plotted Snowflake and Databricks, the two players vying to be the net great data platform. ETR recently added Streamlit and this survey has added Snowpark, Snowflake’s application platform.
A New Data Stack Began to Emerge Last Decade
Stepping back for a moment. Mid last decade we saw the emergence of what we thought was a new data stack comprising AWS infrastructure in the cloud,Snowflake for the modern cloud data warehouse and Databricks for machine learning. We thought that was going to form a new triumvirate – and it did.
But both of these companies saw massive opportunities, capitalized and now they’ve become much more competitive. Nonetheless, in the field, customers continue to buy both. Specifically, the ETR data shows a meaningful overlap in the two account bases:
- Nearly 40% of Snowflake accounts also run Databricks
- About 46% of Databricks accounts run Snowflake
We believe that this dynamic will continue for some time as Snowflake is immature in data science and Databricks is immature in data management. As such customers will continue to rely on both platforms, at least in the near to mid term.
The Big Three Cloud Players will Double Dip in Infrastructure and Partner Data Platforms
Let’s come back to Microsoft on the above chart. Their data platform in Azure was always very fragmented. And this is the first time with Fabric and Synapse as the core engine, that they at least standardized on the table format.
But they standardized on Delta Tables because a large portion (~ 40% overlap) of VMs running on Azure were Databricks, meaning the data on Azure was under Databricks’ heavy influence. So Microsoft is trying to take back control. Our view is Microsoft’s posture is “Use our analytic engines and we’ll partner with Databricks, and between the two of us we’ll try to get everyone into Delta Tables…then we’ll compete on the basis of our analytic engines and their quality.”
So that’s their play, but neither of them has a core engine that is wholly integrated with multiple query options and multiple data types that Snowflake has in terms of handling all these different workloads.
AWS, as we heard from George’s clip, has a different approach. While they support many query types and data formats their products are bespoke. But they serve developers well and AWS partners extensively with Snowflake. Snowflake bundles in the AWS compute and storage costs so AWS gets paid when customers consume Snowflake.
Google has a very strong play with BigQuery and there’s a good reason to use it, but they’re not as partner friendly as AWS and Microsoft when it comes to Snowflake and Databricks platforms. Google wants everybody into their platform around BigQuery and appears less willing to partner with these firms it sees as competitive.
Room for Two New Modern Data Platforms Doubling Down on GenAI
You have this mindshare battle going on between Snowflake and Databricks. And AI is the next wave. So let’s put this into context with the graphic below.
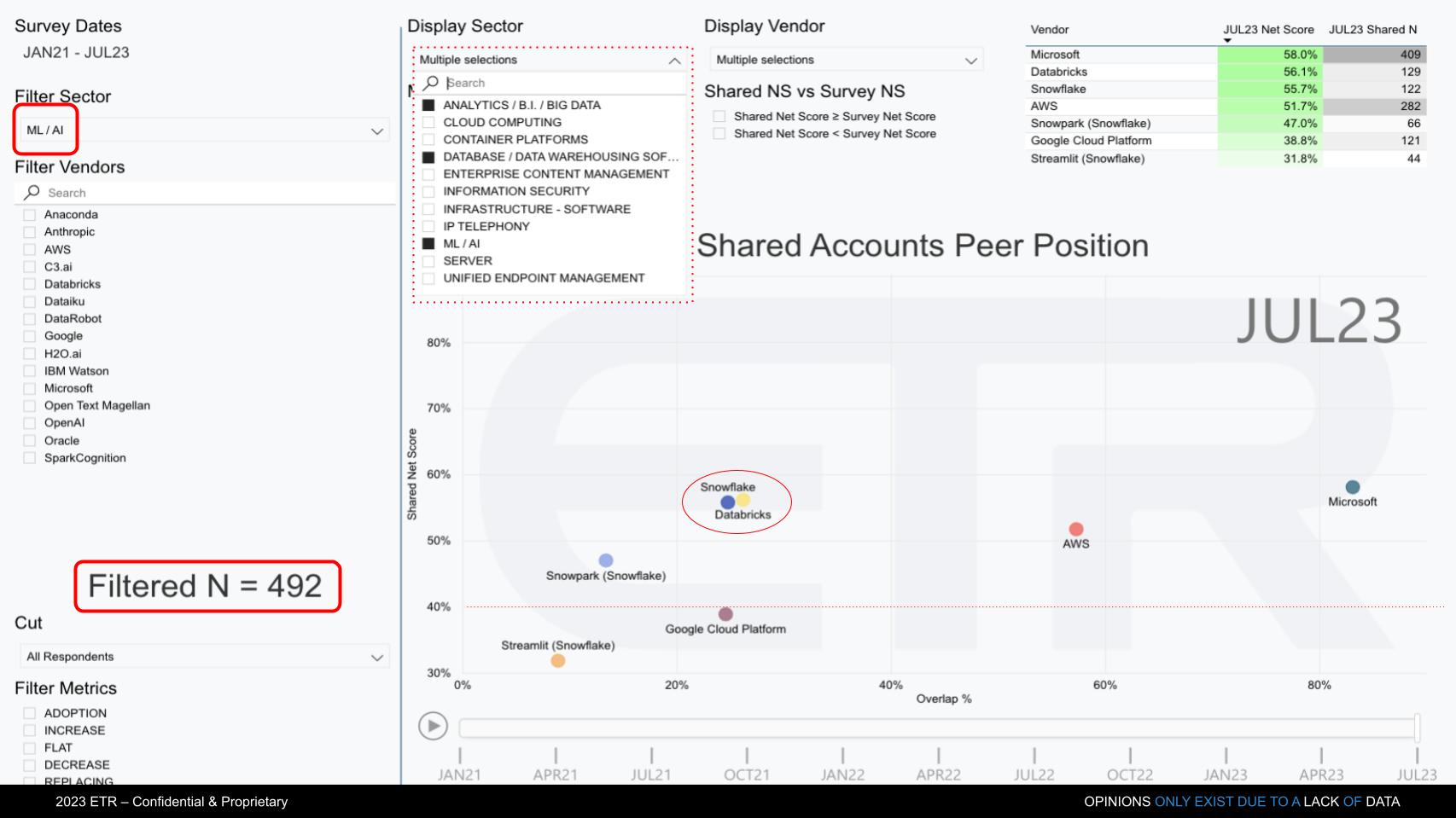
Because the big topic, and the battle right now is around AI, we created a unique view of the ETR data. The chart above cuts the ETR database by those customers who are leading AI ML accounts.
On the upper left, we’re filtering on ML/AI accounts, and the filtered N = 492. And we plot the positions of those same firms. We’re keying on the survey data for their product portfolios within analytics, database and AI.
Nw Microsoft, as you can see, plays a leading role here and leapfrogged everybody with its OpenAI deal. Amazon’s got a really good AI story with SageMaker, very good actually. And we know Databricks is really strong in the ML/AI space, but Snowflake has been making moves there and heavily emphasized AI at its Summit. We saw two prominent examples in the Neeva acquisition, and the NVIDIA announcements this week. Snowflake is containerizing the Nvidia stack within Snowpark Container Services and in our view is trying to leapfrog its way past Databricks.
It’s notable to see Snowflake and Databricks right on top of each other on this chart. So on the one hand you’d say, well that’s surprising. Snowflake’s presence in ML/AI accounts is strong, even though you’d think Databricks’ would be stronger. But first of all, there are a lot more Snowflake accounts and the reality is, there’s a large overlap between Snowflake and Databricks as we described above.
Snowflake: Expanding Its Data Universe through Pivotal Partnerships and New Services
Ok let’s close with a quick summary.

In an impressive series of announcements, Snowflake has demonstrated its rapid evolution in the data management and analytics industry. By partnering with industry innovators and leaders,, developing novel frameworks, and fostering an emerging developer ecosystem, we believe Snowflake is solidifying its place at the forefront of the next data revolution.
The collaboration with NVIDIA encapsulating the latter’s entire stack within Snowflake’s Snowpark Container Services is seen as a major breakthrough. This amalgamation, as indicated by NVIDIA’s Jensen Huang, supercharges Snowflake, intensifying its capabilities, and extending its reach into advanced analytics and AI applications.
Further, the launch of the Iceberg open tables showcased Snowflake’s commitment to performance and accessibility. By negating performance disparities between data in Snowflake or Iceberg tables, Snowflake reaffirmed its commitment to providing a seamless user experience across diverse data types.
The unveiling of a native application framework – essentially an ‘app store’ for enterprises – was another significant stride. With 25 companies participating and more expected to join, this development paves the way for a more collaborative and expansive enterprise software ecosystem.
The introduction of Snowpark container services simplifies the process of data import and app development within Snowflake. Companies like Blue Yonder will leverage this service, marking the advent of a new era of integrated, containerized applications within the Snowflake platform to attack supply chain problems. This is just one of many possible examples of emerging data workloads that will leverage the Snowflake platform.
In addition to these major announcements, Snowflake has rolled out a range of somewhat boring but important enhancements for developers. These include autosync with Git repositories, logging and tracing APIs, and a new open-source command-line interface. While these improvements may appear trivial, they underscore Snowflake’s commitment to simplifying the developer experience and enhancing productivity.
We believe the trajectory of Snowflake signifies an evolution in the future of data applications. The firm’s dedication to expanding its capabilities and promoting an inclusive, dynamic ecosystem is reshaping the landscape of data management and analytics. As analysts, we will continue to closely observe Snowflake’s journey in defining the next generation of data-driven applications.
As well we’re closely watching the ascendency of Databricks and its differing approach. This includes the perception and perhaps reality that in certain situations customers may find it more cost effective to do some data engineering tasks outside of Snowflake and not have to incur AWS infrastructure costs indirectly.
In our view the massive total available market will support multiple players and the data suggests that both Snowflake and Databricks will participate in earnest for the foreseeable future.
Keep in Touch
Many thanks to Alex Myerson and Ken Shifman on production, podcasts and media workflows for Breaking Analysis. Special thanks to Kristen Martin and Cheryl Knight who help us keep our community informed and get the word out. And to Rob Hof, our EiC at SiliconANGLE.
Remember we publish each week on Wikibon and SiliconANGLE. These episodes are all available as podcasts wherever you listen.
Email david.vellante@siliconangle.com | DM @dvellante on Twitter | Comment on our LinkedIn posts.
Also, check out this ETR Tutorial we created, which explains the spending methodology in more detail.
Watch the full video analysis:
Image: vegefox.com
Note: ETR is a separate company from Wikibon and SiliconANGLE. If you would like to cite or republish any of the company’s data, or inquire about its services, please contact ETR at legal@etr.ai.
All statements made regarding companies or securities are strictly beliefs, points of view and opinions held by SiliconANGLE Media, Enterprise Technology Research, other guests on theCUBE and guest writers. Such statements are not recommendations by these individuals to buy, sell or hold any security. The content presented does not constitute investment advice and should not be used as the basis for any investment decision. You and only you are responsible for your investment decisions.
Disclosure: Many of the companies cited in Breaking Analysis are sponsors of theCUBE and/or clients of Wikibon. None of these firms or other companies have any editorial control over or advanced viewing of what’s published in Breaking Analysis.


