

Artificial intelligence (AI) workloads are consuming ever greater shares of IT infrastructure resources. Increasingly, solution providers are building platforms that process growing AI workloads more scalably, rapidly, and efficiently. They are also using a new generation of AI-driven tooling to optimize these AI-ready platforms individually as well as manage, monitor, scale, secure, and control the end-to-end IT and application infrastructures in which they’re deployed.
AIOps Is Reshaping IT Infrastructure
Artificial intelligence (AI) workloads are consuming ever greater shares of IT infrastructure resources. AI is also taking up residence as an embedded component for managing, monitoring, scaling, securing, and controlling IT infrastructure.
AI-optimized application infrastructure is one of today’s hottest trends in the IT business. More vendors are introducing IT platforms that accelerate and automate AI workloads through pre-built combinations of storage, compute, and interconnect resources.
AI is an unfamiliar discipline to many longtime IT professionals and many AI hardware and software stacks are complicated to tune and maintain. These challenges have spurred many IT professionals to seek out stable, validated, preconfigured, and pretuned stacks that are optimized for specific AI workloads, including data ingestion, preparation, modeling, training, and inferencing.
AI-infused scaling, acceleration, automation, and management features are fast becoming a core competitive differentiator. Increasingly, this emerging IT management paradigm goes by the name “AIOps,” which refers to two aspects of AI’s relationship to cloud infrastructures and operations:
- AI-ready computing platforms: AI is a growing workload that infrastructure and operations are being readied to support. More vendors are launching compute, storage, hyperconverged, and other platforms that are purpose-built for high-performance, high-volume, fast training, inferencing, and other AI workloads. At a hardware level, AI-ready storage/compute integration is becoming a core requirement for many enterprise customers.
- AI-driven infrastructure optimization tools: AI is a tool for making infrastructure and operations more continuously self-healing, self-managing, self-securing, self-repairing, and self-optimizing. These tools may be embedded in AI-workload-optimized platforms or be available through stand-alone tools for managing many platforms. In this regard, AI’s growing role in management of IT, data, applications, services, and other cloud infrastructure stems from its ability to automate and accelerate many tasks more scalably, predictably, rapidly, and efficiently than manual methods alone. Without AI’s ability to perform continuous log analysis, anomaly detection, predictive maintenance, root cause diagnostics, closed-loop issue remediation, and other critical functions, managing complex multi-clouds may become infeasible or cost-prohibitive for many organizations.
With these trends in mind, enterprise IT professionals should:
- Identify the workloads to be processed in your AI DevOps pipeline across your distributed computing infrastructure: AI encompasses a wide range of workloads that involve building, training, deploying, evaluating, and refining data-driven algorithms in production applications. For any AI practice, one may define an end-to-end DevOps workflow involving teams of data scientists and others collaborating at every stage in readying applications and models for production deployment. These workloads may be understood as fitting into through DevOps phases: preparation, modeling, and operationalization, as well as the core end-application AI workload of inferencing from live data in production environments.
- Ensure that your computing environments are ready to process AI workloads scalably and efficiently: In the past year, Wikibon has seen a growing range of storage, compute, and hyperconverged infrastructure solution providers roll out AI-ready offerings. Solution providers are competing with full hardware stacks that are optimized for specific AI workload throughput, concurrency, scale, data types, and machine-learning algorithms. Before long, no enterprise data lake will be complete without pre-optimized platforms for one or more of the core AI workloads: data ingest and preparation, data modeling and training, and data deployment and operationalization.
- Benchmark your end-to-end AI environments ability to optimize specific workloads against relevant metrics: No computing platform should be considered “AI-optimized” unless it’s been benchmarked running specific AI workloads—such as training and inferencing–and been certified as offering acceptable performance on the relevant metrics. In the past year, the AI industry has moved rapidly to develop open, transparent, and vendor-agnostic frameworks for benchmarking for evaluating the comparative performance of different hardware/software stacks in the running of diverse workloads.
Identify your AI workloads across the DevOps pipeline
AI encompasses a wide range of workloads that involve building, training, deploying, evaluating, and refining data-driven algorithms in production applications.
For any AI practice, one may define an end-to-end DevOps workflow involving teams of data scientists and others collaborating at every stage in readying applications and models for production deployment.
Table 1 provides a handy guide for developers to pinpoint the specific AI workloads that can be processed through purpose-built and optimized platforms. These workloads may be understood as fitting into through DevOps phases: preparation, modeling, and operationalization, as illustrated in Figure 1. Please note that the core workloads of production AI—which are the culmination and end-result of these DevOps processes—are outside the scope of these pipeline view, though they are very much germane to the optimization of platforms for AI applications.
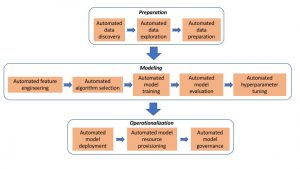
Figure 1: DevOps Phases and Process in the AI Pipeline
| PHASE | PROCESS | DISCUSSION |
| Preparation | Data discovery
|
These workloads support discovery, acquisition, and ingestion of the data needed to build and train AI models. |
| Data exploration | These workloads support building visualizations of relationships of interest within the source data. | |
| Data preprocessing | These workloads support building training data set through encoding of categorical variables, imputing missing variables, and executing other necessary programmatic data transformations, corrections, augmentations, and annotations. | |
| Modeling | Feature engineering | These workloads support generating and evaluating alternative feature representations that describe predictive variables to be included in the resulting AI models. |
| Algorithm selection | These workloads support identifying the statistical algorithms best suited to the learning challenge, such as making predictions, inferring abstractions, and recognizing objects in the data. | |
| Model training | These workloads support processing an AI model against a training-data test or validation set to determine whether it performs a designated task (e.g., predicting some future event, classifying some entity, or detecting some anomalous incident) with sufficient accuracy. | |
| Model evaluation | These workloads support generating learning curves, partial dependence plots, and other metrics that illustrate comparative performance in accuracy, efficiency, and other trade-offs among key machine learning metrics. | |
| Hyperparameter tuning | These workloads support identifying the optimal number of hidden layers, learning rate (adjustments made to backpropagated weights at each iteration); regularization (adjustments that help models avoid overfitting), and other hyperparameters necessary for top model performance. | |
| Operationalization | Model deployment
|
These workloads support deployment of AI models for execution into private, public or hybrid multi-cloud platforms, as well as into containerized and virtualized environments. |
| Model resource provisioning | These workloads support scaling up or down the provisioning of CPU, memory, storage, and other resources, based on changing AI application requirements, resource availabilities, and priorities. | |
| Model governance | These workloads support keeping track of which model version is currently deployed; ensuring that a sufficiently predictive model in always in live production status; and retraining using fresh data prior to redeployment. |
Table 1: AI Workloads Throughout the DevOps Flow
Ensure that computing platforms are ready for your AI workloads
In the past year, Wikibon has seen a growing range of storage, compute, and hyperconverged infrastructure solution providers roll out AI-ready offerings. Solution providers are competing with full hardware stacks that are optimized for specific AI workload throughput, concurrency, scale, data types, and machine-learning algorithms. Before long, no enterprise data lake will be complete without pre-optimized platforms for one or more of the core AI workloads: data ingest and preparation, data modeling and training, and data deployment and operationalization.
At a high architectural level, we can characterize the comprehensiveness of an end-to-end computing environment’s AI readiness along the criteria presented in Table 2.
| CRITERIA | DISCUSSION |
| AI deployment scenarios | What are the specific deployment scenarios (e.g., on-premise/private cloud, as-a-service/public cloud, hybrid cloud, multi-cloud, edge/IoT cloud) within which AI workloads are scaled, accelerated, and otherwise optimized? |
| AI workload support | What are the specific deep learning, machine learning, low-latency real-time analytics, natural language processing, in-database analytics, image classification, and other AI workloads being scaled, accelerated, and being optimized? |
| AI accelerator enablement | What is the range of GPUs, FPGAs, CPUs, TPUs, ASICs, and other chipsets being used to accelerate and scale workloads? |
| AI-optimized hardware componentry | What are the specific hardware platform components (storage, compute, memory, interconnect, hyperconverged, high-performance computing, etc.) that have been configured and accelerated to optimize the processing of AI workloads? |
| AI-optimization software tooling | What are the specific software components (data ingestion, enterprise data hubs, data science workbenches, cluster management tools, containerized microservices, etc) that support scalable, high-performance, efficient processing of AI workloads? |
Table 2: Criteria of Computing Platform AI-Readiness
What’s noteworthy about today’s AI workload-ready computing solutions is that many incorporate:
- Hyperconverged infrastructure to support flexible scaling of compute, storage, memory, and interconnect in the same environment;
- Multi-accelerator AI hardware architectures, often combining Intel CPUs, NVIDIA GPUs, FPGAs, and other optimized chipsets in environments where AI is a substantial workload within broader application platforms;
- Memory-based architectures with ultra-high memory bandwidth, storage class memory, and direct-attached Non-Volatile Memory Express (NVMe) drives to minimize latency and speed data transfers;
- Petabyte-scale all-flash enterprise storage over distributed, virtualized architectures;
- Embedded AI to drive optimized, automated, and dynamic data storage and workload management across distributed fabrics within 24×7 DevOps environments;
- Bundled machine learning, deep learning, real-time analytics, in-database analytics, model training, data preparation, and other software in support of a wide range of AI workloads;
- Agile deployment support for AI workloads and data in and across private, public, hybrid, and multiclouds, leveraging virtualization and containerization fabrics
The full architectural stack of an AI-ready computing platform is illustrated in Figure 2.
 Figure 2: Architectural Stack of AI-Ready Computing Platform
Figure 2: Architectural Stack of AI-Ready Computing Platform
Please note that possession these and other AI-ready capabilities does not signify, in and of itself, platform is truly “optimized” for machine learning, deep learning, and the like. That, as will be discussed later in this report, can only be determined through valid benchmarking exercises that evaluate a given platform’s ability to process specific AI workloads according to relevant metrics.
What follows are profiles of several vendors of storage platforms that have been purpose-built for speedy, scalable, efficient processing of various AI workloads.
Dell EMC
Dell EMC AI-ready solutions span its storage, infrastructure, and hyperconverged solution portfolios. Table 3 presents an overview of these solutions.
| SOLUTIONS | FEATURES |
| AI workload-specific hardware/software solutions |
|
| AI-ready storage | • Dell PowerMax is a storage solution optimized for real-time AI, IoT, and mobile workloads;
• Incorporates a memory-based architecture for extreme low-latency performance over NVMe-over-Fabrics and storage class memory; • Embeds a real-time ML engine that uses predictive analytics and pattern recognition to power automated data-placement optimization across Dell EMC’s VMAX3 and VMAX all-flash portfolio based on historical and real-time analytics |
| AI-ready infrastructure appliances |
|
| AI-ready hyperconverged infrastructure appliances |
|
Table 3: Dell EMC AI-Ready Solutions
HPE
HPE’s principal AI-ready solution is 3PAR, which supports the capabilities presented in Table 4.
| SOLUTION CATEGORIES | DISCUSSION |
| Predictive storage optimization | HPE is building an automated, deeply intelligent, and self-improving storage product line. HPE is extending InfoSight coverage to the HPE 3PAR StoreServ all-flash storage product line. This enables HPE storage to grow continuously smarter and more reliable. In real-time, the solution observes, learns, predicts, prevents, pinpoints root causes, automates issue resolution, and enforces intelligent case automation to drive higher levels of storage availability. HPE InfoSight is cloud-based predictive analytics platform for enterprise storage, which it gained through its acquisition almost 18 months ago of Nimble Storage. |
| Automated storage management | HPE 3PAR is a DevOps and container-friendly storage platform in which users can run both mainstream and containerized applications on the same enterprise-grade infrastructure. HPE is launching new toolsets to automate and manage HPE 3PAR for the cloud, DevOps, virtualization and container environments. In addition to existing integration with Docker and Mesosphere DC/OS, HPE 3PAR now works with Kubernetes and Red Hat OpenShift to offer automation and integration with the leading container platforms. |
| Self-service storage management | HPE is launching a new plug-in for VMware vRealize Orchestrator, which provides self-service storage automation through pre-built workflows to quickly deploy, and streamline storage management. |
| Storage management DevOps | HPE is launching new pre-built blueprints for configuration management tools available for HPE 3PAR users—including Chef, Puppet and Ansible–as well as language software development kits in Ruby and Python. These enable DevOps professionals to automate storage functions in native programming languages for faster application delivery. |
Table 4: HPE’s AI-Ready Storage Solution
AI workload optimization is a key theme in other aspects of HPE’s product and partnering strategies:
- HPE Apollo 6500 Gen10 System delivers a 3x faster deep learning model training than previous generations
- HPE has extended its AI partner ecosystem through areseller agreement with WekaIO to deliver optimized storage performance in AI environments.
- HPE is bringing InfoSight to its Edgeline systems to drive optimized data placement across edge devices.
IBM
IBM provides AI-ready platforms throughout its solution portfolio. These range from an AI reference architecture to fully built-out AI-ready compute/storage platforms, AI-accelerating all-flash storage solutions, and an AI-driven enterprise storage management tool.
Table 5 presents IBM’s AI-ready solutions:
| SOLUTION | FEATURES |
| IBM Reference Architecture for AI Infrastructure | • Reference architecture facilitates AI platform proofs of concept that can grow into scalable, multitenant production systems;
• Includes GPU servers for fast model training and optimization, storage resource connectors that simplify and maintain ongoing connections to multiple data sources, multitenancy features to support shared access to compute clusters by multiple data scientists, frameworks, and applications; • Designed to maximize utilization of shared AI server and GPU resources while supporting elastic, resilient, and distributed training in which GPUs are dynamically assigned to models and can be added and removed without the need to stop training. |
| IBM POWER9 Systems for Enteprise | • Incorporates the faster, more scalable POWER9 CPU core and chip architecture for next-generation workloads, especially AI;
• Greater performance per core, memory per socket, memory bandwidth per socket, and I/O bandwidth than Xeon SP CPU • Can scale up to 16 sockets and provides ultra-high memory bandwidth for CPU-GPU interconnect to enable considerably faster training times; • Includes an OpenCAPI interface for coherent, high bandwidth communication to NICs, FPGA accelerators, and storage controllers • Built-in PowerVM, so every E950/E980 workload is virtualized with accelerated secure mobility • Cloud PowerVC Manager included for resource optimization and private cloud portal • Cloud Management Console (CMC) entitlement for consolidated monitoring over multiple locations • Consistent enterprise-wide multi-cloud management with VMware vRealize Suite integration • Create new Power cloud-native solutions with IBM Cloud Private suite of DevOps tools and app store • Dynamic resource management across multiple Power cloud servers with Enterprise Pools |
| IBM PowerAI Enterprise | • Computing platform that combines popular open source deep learning frameworks, AI development tools, and accelerated IBM Power Systems servers;
• Implements the IBM Reference Architecture for AI Infrastructure • Incorporates POWER9 processors, AI accelerators (PCIe, OpenCAPI, NVIDIA NVLink, persistent memory); AI solutions (PowerAI, Power AI Vision, third-party GPU DBs, open-source DBs, in-memory analytics), operating systems (AIX, I, Linux), PowerVM, PowerVC, Power SC, PowerHA, KVM, OpenStack_ • Provides a complete, optimized, and validated environment for data science as a service, enabling organizations to bring new applied AI applications from development into production; • Includes DL frameworks with all required dependencies and files, precompiled and ready to deploy; • Provides large model support that facilitates the use of system memory with little to no performance impact, yielding significantly larger and more accurate deep learning models; • Supports multiple users and lines of business with multi-tenancy, end-to-end security, including role-based access controls; • Enables centralized management and monitoring of the infrastructure and workflows. |
| IBM FlashSystem 9100 Multi-Cloud Solutions | • All-flash enterprise storage solution that leverages AI to provide a unified view of predictive insights into all-flash storage virtualized across multi-clouds;
• Provides insights into storage performance, capacity, trends, issues, and diagnostics; • Analyzes storage patterns, predicts and prevents issues, and generates alerts; • Includes best practices blueprints for Data Reuse, Protection, Efficiency, Business Continuity, Private Cloud Flexibility, and Data Protection; • Runs on IBM FlashSystem 9100, which provides an all-flash NVMe-accelerated array over InfiniBand, with 2.5-inch IBM FlashCore devices, up to 32 PB usable capacity in a full rack, guaranteed consistent latency of 350 microseconds, and 100 million IOPS per four-way cluster; • Includes the full IBM Spectrum storage management software suite |
| IBM Spectrum Computing | • Solution portfolio that uses intelligent workload and policy-driven resource management to optimize computing clusters across the data center, on premises and in the cloud
• Spectrum Storage provides enables data storage, access, and management on a range of platforms and deployment models, including on-premises, hybrid, private, and public clouds. • Spectrum Scale optimizes big data analytics and clustered applications with high-performance, scalable storage that enables global collaboration, simplifies workflows, and lowers costs with cloud tiering • Spectrum Symphony supports a low-latency, high throughput software-defined infrastructure for running compute- and data-intensive distributed applications on a scalable, shared grid • Spectrum Conductor enables sharing of compute and storage clusters and accelerated deployment of distributed and containerized workloads, including Spark and AI in multitenant environments, both on-premises and in the cloud • Spectrum Conductor Deep Learning Impact enables rapid deployment of end-to-end AI DevOps pipelines; supports distributed data ingest, transformation, modeling, training, hyperparameter optimization, and visualization |
| IBM Storage Insights | • Software tool supports proactive storage management in through AI-driven predictive analytics, trending analysis, capacity planning, and SLA-based best practice insights;
• Includes Spectrum Storage software for array management, data reuse, modern data protection, disaster recovery, and containerization; • Analyzes storage performance data and provides proactive alerting of storage issues; • Enables 24×7 support on storage by displaying open/closed ticket status, enhanced ticket response times, and remote management and code loads. |
Table 5: IBM’s AI-Ready Solutions
NetApp
NetApp has recently released NetApp ONTAP AI, which is a new a new validated computing platform for integrated edge-to-core AI pipelines. It incorporates NVIDIA DGX-1 GPU-equipped supercomputers; NetApp AFF A800 cloud-connected, ultra-low-latency, all-flash, NVMe storage array; Cisco Nexus 3232C 100Gbe switches; NVIDIA GPU Cloud Deep Learning Stack software; Trident dynamic storage provisioner software; and NetApp ONTAP 9 common data management services layer software.
NetApp has configured several versions of the ONTAP AI stack for specific workload profiles, based on such requirements as data throughput, processing capacity, high availability. It has published benchmarks for the stacks’ ability to process specific image-classification training and inferencing workloads. Within the stack, DGX server incorporates 8 Nvidia Tesla V100 GPUs, configured in a hybrid cube-mesh topology and using Nvidia’s NVLink network transport as high-bandwidth, low-latency fabric. The solution’s reference design has four DGX servers to one AFF A800, although customers can start with a 1-1 ratio and nondisruptively scale as needed. DGX-1 servers support multimode clustering via Remote Direct Memory Access-capable fabrics. The NetApp FAS A800 system supports 30 TB NVMe SSDs with multistream write capabilities, scaling to 2 PB of raw capacity in a 2U shelf. The system scales from 364 TB in two nodes to 24 nodes and 74 PB.
NetApp AI ONTAP is based on ONTAP 9.4, which handles enterprise data management, protection and replication. By leveraging the NetApp Data Fabric, ONTAP AI enables enterprises to create a data pipeline that spans from the edge to the core to the cloud. This pipeline integrates diverse, dynamic, and distributed data sources. It gives users scalable control, access, management, protection, and performance they need to provide the right data at the right time at the right location to their AI applications. It removes performance bottlenecks and enables secure, nondisruptive access to data from multiple sources and data formats. The platform automatically moves cold data off to other devices and supports hybrid cloud data tiering, including supporting backup support to Google Cloud Platform and Microsoft Azure. ONTAP will automatically move inactive data to a lower-cost storage tier to save money and automatically bring data back when the user needs it.
PureStorage
Pure Storage provides AIRI, which is an integrated hardware/software platform for distributed training and other compute- and storage-intensive AI workloads.
AIRI is purpose-built for a wide range of AI pipeline workloads, ranging from upfront data ingest and preparation all the way through modeling, training, and operationalization. It incorporates:
- A half-rack of Pure Storage’s FlashBlade storage technology,
- 4 NVIDIA DGX-1 supercomputers that run the latest Tesla V100 GPUs
- Interconnection of storage and compute through Arista 100GbE switches that incorporate NVIDIA’s GPUDirect RDMA technology for high-speed high-volume data exchange on distributed training and other AI workloads;
- NVIDIA’s GPU Cloud deep learning software stack, a container-based environment for TensorFlow and other AI modeling frameworks; and
- Pure Storage’s AIRI Scaling Toolkit.
The product can initially be configured with a single DGX-1 system, which delivers 1 petaflop of performance, but it can be easily scaled to four, quadrupling the performance. A Pure Storage array can hold up to 15 52 TB blades for a total capacity of over 750 TB.
Benchmark whether your AI platform is optimized to handle your specific workloads
No computing platform should be consider “AI-optimized” unless it’s been benchmarked running specific AI workloads—such as training and inferencing–and been certified as offering acceptable performance on the relevant metrics.
As the AI arena shifts toward workload-optimized architectures, there’s a growing need for standard benchmarking frameworks to help practitioners assess which target hardware/software stacks are best suited for training, inferencing, and other workloads. In the past year, the AI industry has moved rapidly to develop open, transparent, and vendor-agnostic frameworks for benchmarking for evaluating the comparative performance of different hardware/software stacks in the running of diverse workloads. As illustrated in Figure 3, determining whether an AI-ready platform is optimized evolves measuring whether it is able to process specific AI workloads on specific AI computing configurations according to relevant metrics, which may be in the DevOps tasks (e.g, training time and cost) and/or in the end application tasks (e.g, inferencing accuracy).
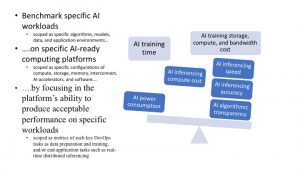
Figure 3: Benchmarking AI-Ready Platforms to Assess Workload Optimization
Here the most important of these initiatives, as judged by the degree of industry participation, the breadth of their missions, the range of target hardware/software environments they’re including in their scope, and their progress in putting together useful frameworks for benchmarking today’s top AI challenges.
MLPerf
The MLPerf open-source benchmark group recently announced the launch of a standard suite for benchmarking the performance of Machine Learning (ML) software frameworks, hardware accelerators and cloud platforms. The group — which includes Google, Baidu, Intel, AMD and other commercial vendors, as well as research universities such as Harvard and Stanford — is attempting to create an ML performance-comparison tool that is open, fair, reliable, comprehensive, flexible and affordable. Available on GitHub and currently in preliminary release 0.5, MLPerf provides reference implementations for some bounded use cases that predominate in today’s AI deployments:
- Image classification:Resnet-50 v1 applied to Imagenet.
- Object detection:Mask R-CNN applied to COCO.
- Speech recognition:DeepSpeech2 applied to Librispeech.
- Machine translation:Transformer applied to WMT English-German.
- Recommendation engine: Neural Collaborative Filtering applied to MovieLens 20 Million (ml-20m).
- Sentiment analysis:Seq-CNN applied to IMDB dataset.
- Reinforcement learning:Mini-go applied to predicting pro game moves.
The first MLPerf release focuses on ML-training benchmarks applicable to jobs. Currently, each MLPerf reference implementation addressing a particular AI use cases provides the following:
- Documentation on the dataset, model and machine setup, as well as a user guide.
- Code that implements the model in at least one ML/DL framework and a dockerfile for running the benchmark in a container;
- Scripts that download the referenced dataset, train the model and measure its performance against a prespecified target value (aka “quality”).
The MLPerf group has published a repository of reference implementations for the benchmark. Reference implementations are valid as starting points for benchmark implementations but are not fully optimized and are not intended to be used for performance measurements on target production AI systems.
Currently, MLPerf published benchmarks have been tested on the following reference implementation:
- 16 CPU chips and one Nvidia P100 Volta graphics processing unit;
- Ubuntu 16.04, including docker with Nvidia support;
- 600 gigabytes of disk (though many benchmarks require less disk); and
- Either CPython 2 or CPython 3, depending on benchmark.
The MLPerf group plans to release each benchmark — or a specific problem using specific AI models — in two modes:
- Closed:In this mode, a benchmark — such as sentiment analysis via Seq-CNN applied to IMDB dataset — will specify a model and data set to be used and will restrict hyperparameters, batch size, learning rate and other implementation details.
- Open:In this mode, that same benchmark will have fewer implementation restrictions so that users can experiment with benchmarking newer algorithms, models, software configurations and other AI approaches.
DAWNBench
Established in 2017, DAWNBench supports benchmarking of end-to-end Deep Learning (DL) training and inferencing. Developed by MLPerf member Stanford University, DAWNBench provides a reference set of common DL workloads for quantifying training time, training cost, inference latency and inference cost across different optimization strategies, model architectures, software frameworks, clouds and hardware.
DAWNBench currently supports cross-algorithm benchmarking of image classification and question answering tasks. The group recently announced the winners of its first benchmarking contest, evaluating AI implementations’ performance on such tasks as object recognition and natural-language-understanding comprehension. Most of the entries to this DAWNBench were open-sourced, which means that the underlying code is readily available for examination, validation, and reuse by others on other AI challenges.
On the DAWNBench challenge, teams and individuals from universities, government departments, and industry competed to design the best algorithms, with Stanford’s researchers acting as adjudicators. Each entry had to meet basic accuracy standards and was judged on such metrics as training time and cost. For example, one of the DAWNBench object-recognition challenge required training of AI algorithms to accurately identify items in a CIFAR-10 picture database. A non-profit group won with a submission that used an innovative DL training technique known as “super convergence” which had previously been invented by the US Naval Research Laboratory. This works by slowly increasing the flow of data used to train an algorithm, and, in this competition, was able to optimize an algorithm to sort the CIFAR data set with the required accuracy in less than three minutes, as compared with more than half-hour in the next best submission.
ReQuEST
ReQuEST (Reproducible Quality-Efficient Systems Tournaments) is an industry/academia consortium that has some membership overlap with ML Perf. ReQuEST has developed an open framework for benchmarking full AI software/hardware stacks. To this end, the consortium has developed a standard tournament framework, workflow model, open repository of validated workflows, artifact evaluation methodology, and a real-time scoreboard of submissions for benchmarking of end-to-end AI software/hardware stacks.
The consortium has designed its framework to be hardware agnostic, so that it can benchmark a full range of AI systems ranging from cloud instances, servers, and clusters, down to mobile devices and IoT endpoints. The framework is designed to be agnostic to AI-optimized processors, such as GPUs, TPUs, DSPs, FPGAs, and neuromorphic chips, as well as across diverse AI, Deep Learning, and Machine Learning software frameworks.
ReQuEST’s framework supports comparative evaluation of heterogeneous AI stacks’ execution of inferencing and training workloads. The framework is designed to facilitate evaluation of trade-offs among diverse metrics of AI full-stack performance, such as predictive accuracy, execution time, power efficiency, software footprint, and cost. To this end, it provides a format for sharing of complete AI software/hardware development workflows, which spans such AI pipeline tasks as model development, compilation, training, deployment, and operationalization. Each submitted AI pipeline workflow to be benchmarked specifies the toolchains, frameworks, engines, models, libraries, code, metrics, and target platforms associated with a given full-stack AI implementation.
This approach allows other researchers to validate results, reuse workflows and run them on different hardware and software platforms with different or new AI models, data sets, libraries, compilers and tools. In ReQuEST competitions, the submissions arranged on the extent of their Pareto-efficient co-design of the whole software/hardware stack to continuously optimize submitted algorithms in terms of the relevant metrics. All benchmarking results and winning software/hardware stacks will be visualized on a public interactive dashboard and grouped according to such categories as whether they refer to embedded components or entire stand-alone server configurations. The winning artifacts are discoverable via ACM Digital Library, thereby enabling AI researchers to reproduce, reuse, improve and compare them under the common benchmarking framework.
For AI benchmarking, the ReQuEST consortium has initiated a competition to support comparative evaluation of Deep Learning implementations of the ImageNet image classification challenge. Results from this competition will help the consortium to validate its framework’s applicability across heterogeneous hardware platforms, DL frameworks, libraries, models and inputs. Lessons learned in this competition will be used to evolve the benchmarking framework so that it can be used for benchmarking other AI application domains in the future.
ReQuest is also developing equivalent benchmarking frameworks for other applications domains, including vision, robotics, quantum computing, and scientific computing. Going forward, the consortium plans to evolve its AI framework to support benchmarking microkernels, convolution layers, compilers, and other functional software and hardware subsystems of AI stacks.
It may take two to three years for MLPerf, DAWNBench, ReQuEST, and other industry initiatives to converge into a common architecture for benchmarking AI applications within complex cloud and edge Architectures. Here is a separate discussion of AI-benchmarking initiatives that are focused on mobile-, IoT-, and edge computing platforms.
Action Item
Enterprise IT professionals should adopt the new generation of hyperconverged, storage, and other infrastructure offerings that can scale hardware resources needed for training, inferencing, and other core AI workloads. IT professionals should pay special attention to benchmarking the AI-accelerator hardware technologies—such as GPUs, FPGAs, ASICs, and other AI-optimized chipsets—that are embedded in their infrastructure. Likewise, the new generation of AI-optimized IT intrastructure should incorporate memory-based architectures with ultra-high memory bandwidth, storage class memory, and direct-attached NVMe drives to minimize latency and speed data transfers between nodes in distributed, containerized, and virtualized AI computing environments. All of these hardware-focused AI platform investments should also incorporate integrated machine learning, deep learning, real-time analytics, in-database analytics, model training, data preparation, and other software in support of the DevOps requirements of AI application development teams.

