

Premise
Machine learning (ML) and AI have seized the collective imagination of enterprises everywhere as the most transformational technology in generations. These technologies are the focus of intensive experimentation, following similar experimentation with on-prem Hadoop-based big data projects. But if mainstream enterprises are going to leverage AI and ML widely over the next several years, they are going to have to pick their way carefully through an obstacle course. There just aren’t enough skilled data scientists to work at all levels of the ML and AI food chain.
On-premises, Hadoop-based, big data investments were going to cure cancer, taste like chocolate, and cost a dollar. But a majority of Hadoop projects at mainstream enterprises struggled to make it past the pilot phase. Why? Because of a lack of two classes of skills. First, Hadoop is comprised of many complex, open source projects that aren’t built to work together seamlessly; mainstream enterprises didn’t have the skills in-house to manage the tool composites that characterized typical Hadoop initiatives. Second, most enterprises lack a pool of qualified data scientists. Moreover, the tools intended to facilitate the construction and operationalization of complex big data models offered limited capabilities.
The same set of issues are emerging in the AI and ML world. Addressing this skills shortage requires that CIOs and LOB executives review their ML and AI projects from the perspective of leverage. Mainstream enterprises have to limit the type of work they can undertake, for now:
- Leave new algorithm development to tech companies and the research community. At the most sophisticated level, scientists and researchers create and train new algorithms using general-purpose, but low-level, frameworks or engines (see the “deep data science” level in figure 1).
- Build applications based on mature AI/ML patterns. Enterprises with sophisticated talent pools of data scientists or statisticians can build applications that are based on relatively well-known design patterns such as fraud prevention or recommenders (see the “developer ready” level in figure 1).
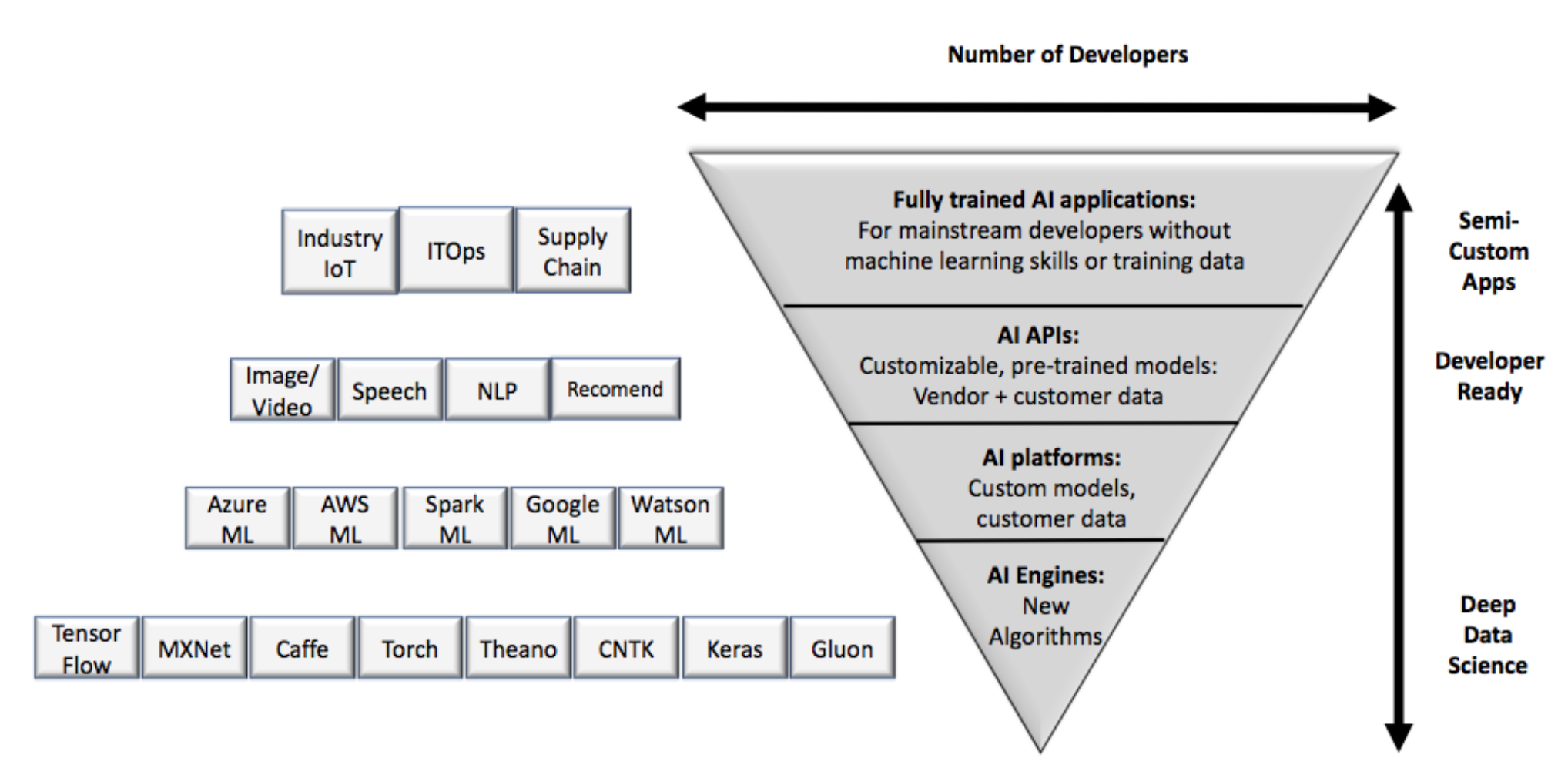
Leave New Algorithm Development To Tech Companies And The Research Community.
Both tech vendors with a focus on AI/ML as well as the research community can push the state of the art in two ways. First, they can apply existing technologies to the novel, previously intractable problems, such as diagnosing diseases via radiology images. Second, at the extreme end, tech vendors and researchers can create new paradigms for AI/ML. Perhaps the most prominent example is the reinforcement learning that drove the simulations that let Alpha Go Zero teach itself to beat a previous version of itself, which had already beaten the world’s best player.
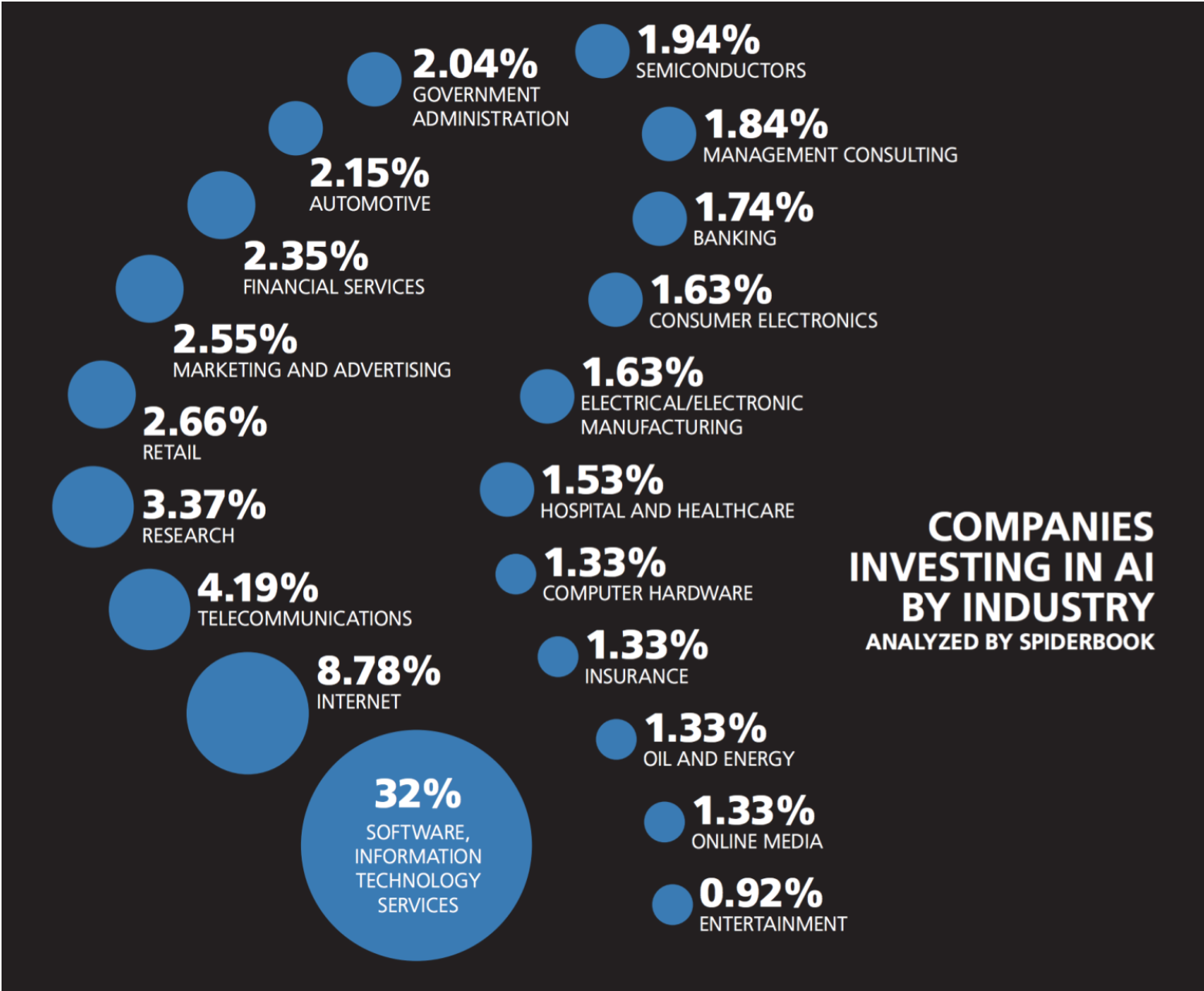
There are only an estimated 10,000 AI/ML researchers at this level. Universities and technology-centric firms do most of the development here because they can attract more of this talent. Firms can pay more and offer immense data sets and compute power for experimentation. Most of all these firms can offer an internal community of world-class talent. Salaries at vendors for those with advanced degrees can start at $350,000-$500,00 per year, plus equity. Based on a web crawl and an analysis of jobs, projects, and other activity, Spiderbook estimates that almost 45% of all companies investing in AI/ML come from software, IT services, internet, and research organizations (see figure 2). No one has figured out how to democratize access to these technologies yet.
Build Applications Based On Mature AI/ML Patterns.
Prototypical AI/ML applications that have a high and measurable ROI include fraud prevention and personalization engines, such as next best action or recommendations. Microsoft and IBM have extensive template libraries to help customers get started. Templates remove the need for customers to figure out what algorithms to select. The templates also help prioritize what input data is required. Developer tooling here is improving. Microsoft introduced an Azure Machine Learning Experimentation service and Model Management service which collectively augment the design and deployment stages of the ML lifecycle, both of which have been relatively dark arts. These new services leverage Microsoft’s historical strength in developer tools and bring them into “data ops,” the data science equivalent of devops. IBM has deep and highly strategic industry solutions for IoT, building on its long history of working closely with large customers.
While templates exist for these types of models, they require varying levels of customization. Enterprises don’t all have input data sets that are identical. So there is a need for additional feature selection and engineering, training data with labels, and model evaluation. While Microsoft and many others are building out the tooling, managing the design-time and runtime data science pipelines is still immature. Most enterprises will need to draw on thin pools of data science expertise. Data scientists have to be in the loop for both design-time and run-time pipelines. At design-time, they have to prep and label data and evaluate model fitness. At run-time, they have to continually evaluate live model performance and continually retrain the models using data feedback loops. In IBM’s case, the industry solutions are templates that require joint development in order to bring together customer domain expertise and IBM’s knowledge of IoT and ML technology.
Wikibon believes the skills base for ML talent outside the tech community is somewhat thin. Based on the same Spiderbook web crawl that identified AI/ML vertical activity in figure 2, the number of companies and the maturity of their investments is quite small (see figure 3). Another way of assessing the talent pool is to look at the number of developers trained on Python and R. Based on that count, there are 1.5-3M data scientists and data engineers compared with 8M developers trained on the previous, mainstream analytic software, SAS. Wikibon believes these numbers are misleading in terms of how many engineers can manage the entire ML model design process. Our research indicates a large majority of this population does data wrangling and preparation. O’Reilly’s 2016 salary survey indicates the median base salary across these skills is $106K in the U.S.

Action Item
In order for mainstream CIOs to avoid having their AI/ML pilots bog down – or unnecessarily fail outright – CIOs and line of business (LOB) executives need to inventory their in-house skills and establish concrete strategies for acquiring those skills or transferring AI/ML knowledge into their organizations in some other, non-labor form.


