
[This is Part II of a series of research focused on the technologies and architectures within the new cloud-native stack. Part I is available here – “Technology Considerations for the New Cloud-native Stack“]
Premise: Cloud-native applications continue to evolve to address new business opportunities, and the need to understand these new architectures is becoming a more critical requirement for IT organizations and digital product teams. As Wikibon highlighted in our Digital Business Platform research, new applications must be able to have programmatic interaction with applications and users, as well as be driven by continuous data-feedback-loops that will help different parts of the business interact with the marketplace.
Many cloud-native applications are beginning to follow the architectural guidance provided by 12 factor applications and cloud-native application architectures. These architectures help shape the best practices for several key areas:
- Defining the scope of a service. The emerging trend is moving away from large “monolithic” applications, which are difficult to update and test in a rapid manner, and moving towards building applications that are made up of smaller building blocks (often called “microservices”) which can be created, tested and deployed more quickly and independently.
- Defining the interaction between services. As applications evolving into a set of smaller services, the scope of each service is bound to specific functions that can be reached via an independent, programmable API (internal or external facing). This independence of services allows multiple applications or 3rd-party services to reuse or replace individual components without impacting other applications.
- Defining the usage of data and location of data sources. Unlike monolithic applications, microservices-based applications take a much different approach to data storage, data persistence and on-going data analysis. This shift impacts not only storage systems, but also also database architectures and replication patterns.
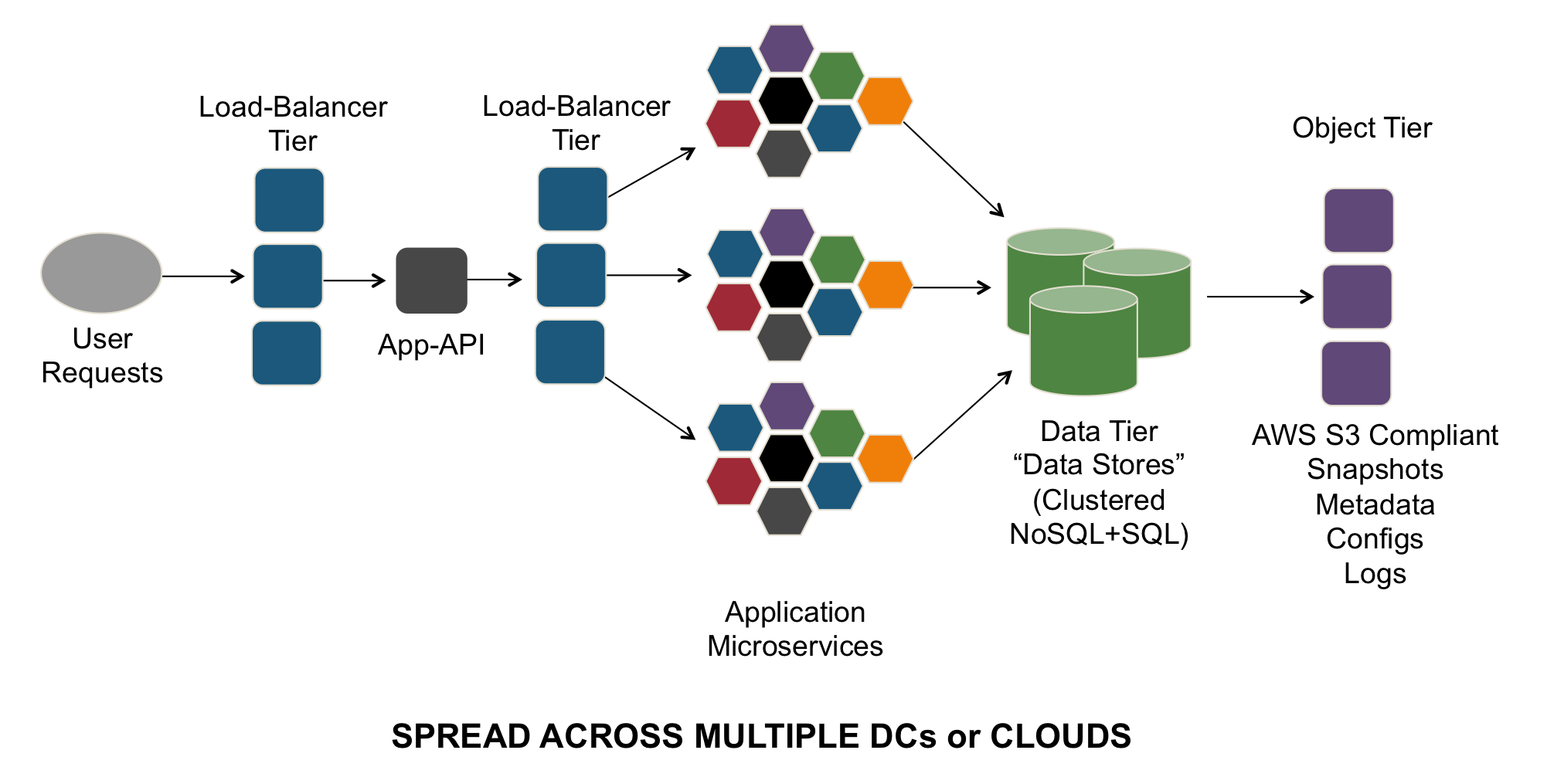
Defining the Scope of a Services
The simplest way to think about the differences between a monolithic application and a microservices-based application is to think about two common occurrences that every business person has experienced. Monolithic applications are the ones that are associated with the email from the IT organization that says, “Application <X> will be unavailable from <TimeA> to <TimeB> due to the need for maintenance.” These maintenance windows are typically planned weeks or months in advance, and require the entire system to be tested and updated to deliver new functionality or fix critical bugs. While this approach worked well for mission-critical systems that were optimized for availability, it is lacking for environments that require frequent changes and updates to support new capabilities that align to business needs.
Microservices-based applications are the ones that send a notification on your phone that notifies you that it’s time to update a mobile app, an occurrence which might happen every couple weeks. The update can be done at any time of day, typically only takes a few seconds, and is done at the user’s discretion. These types of updates only impact small portions of the services which make up the application, and they can be done quickly and independently of other elements within the application. This type of modularity allows applications to quickly respond to a security update, or add a new integration with a popular 3rd-party API service.
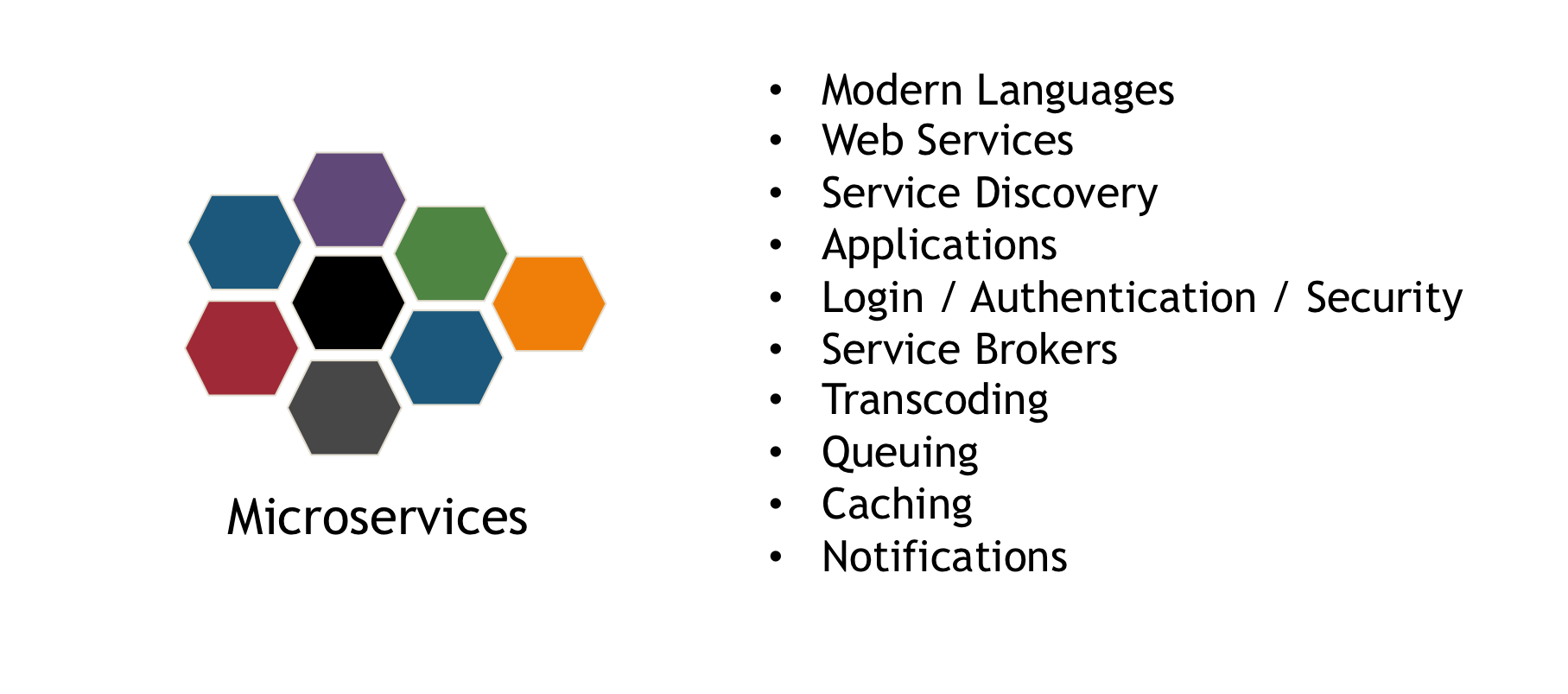
At the core of any microservices-based application is the idea that each service is bounded in context (does a specific function) and is independently available through a programmatic interface. This allows the service to be modified, tested and updated without impacting the broader set of services that are delivered to an end-user or other application. For example, a retailer could modify/improve the recommendation service on their website without impacting the inventory displayed for a specific line of clothing. A new widget to share a purchase via Facebook, Pinterest or Twitter can be added without impacting any other aspect of the shopping experience for a user. In the past, these types of changes may have required that the entire user-experience be disrupted until all new changes could be created, tested and deployed in a single quarterly or biannual update.
Defining the Interaction between Services
In the past, monolithic applications often created large, isolated islands of capabilities. Over time, those capabilities could be made available to other applications or services, but they often required complex gateways to integrate even the most basic services. As discussed in Wikibon’s Digital Business Platform, cloud-native applications are built around the core concept of data-feedback-loops that not only improve the end-user experience, but also deliver valuable insight back to the business. These data-feedback-loops are reshaping how cloud-native architectures are being designed. In the example below, adapted from a popular media service, the services are built according to how quickly they will impact the end-user experience. In “Real-Time”, the user expects instant access to a set of content choices. In “Near-Time”, the services are designed to manage 1000s of scalable transactions and store frequently accessed information. In “Offline”, the on-going interactions within the services are collected, aggregated and analyzed in batches for broader trends to help optimize the service or deliver a more personalized experience to the end-users.
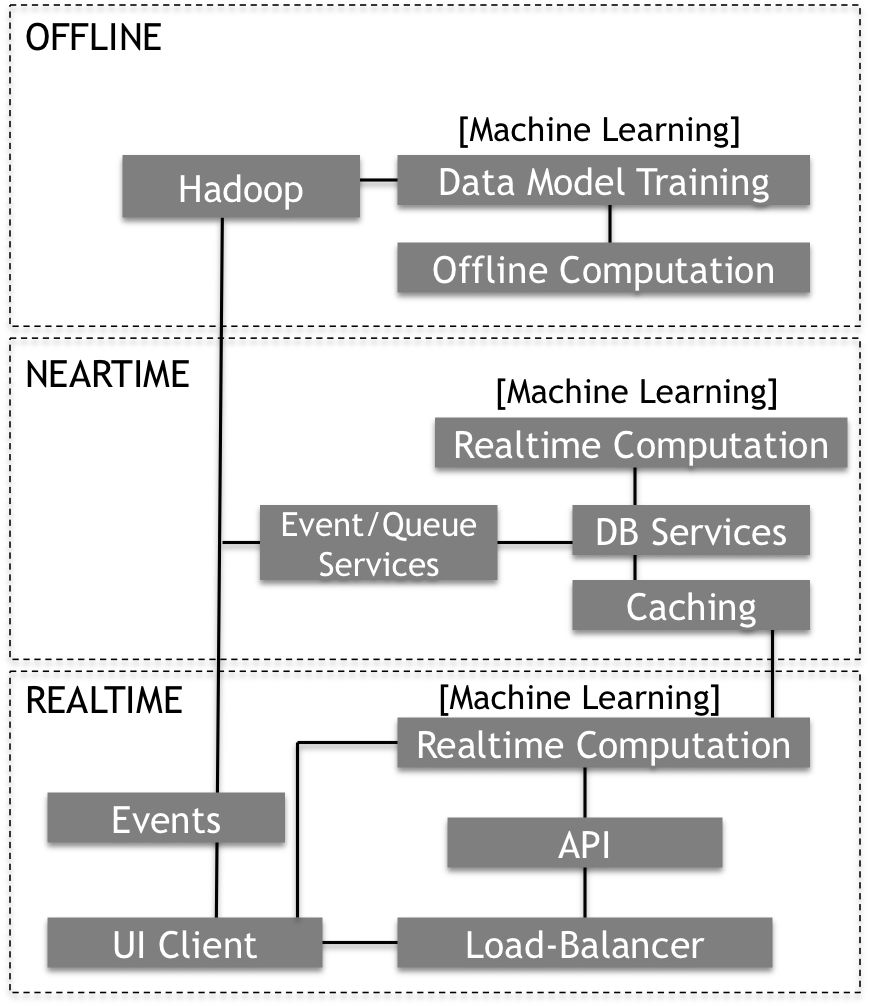
Each of these domains are architected and optimized for the pace and scale needed within an aspect of the end-user experience. They have each been designed using microservices architectures that deliver specific, independent, programmatic services. But each domain operates differently based on the needs of the business for that specific function, and each is interconnected in ways that data-based insight can be shared to improve the overall service experience.
Defining the usage of Data and Location of Data Sources
In comparing application architecture models, one of the biggest differences between monolithic and microservices-based distributed applications is how data is utilized and where data/state is maintained. Monolithic applications are primarily stateful, with application data stored centrally in large SQL databases, backed by large shared storage systems (e.g. Storage Arrays, or SAN). Monitoring and logging data about the application is typically maintained outside the system, and is used by IT operations teams for maintenance and troubleshooting.
Microservices-based applications are being designed around stateless principles, with state and data maintained outside of many services. But this does not mean that data is less critical to these applications, in fact the data elements are more actively involved in the on-going lifecycle of the applications and how they evolve to impact end-user experiences. The common sources and location of data within microservices architectures is listed below:
- Database Tier – NoSQL and SQL databases, evolving to incorporate in-memory databases for real-time interactions (putting as much data in RAM as possible into the physical servers to hold larger datasets) (e.g. MySQL, Cassandra, Greenplum, SAP HANA, etc.) While these databases are clustered (locally and geographically), they are often employing eventually-consistent replication models to manage scalability.
- Caching Tier – As geolocation and proximity to data becomes more critical, especially on mobile devices, high-performance caching tiers are put in place to server frequently used data to applications (e.g. Memcached, CDN Services)
- Logging Tier – Unlike monolithic applications which were monitored for performance or availability, modern applications use logging to understand the context of user-interactions and behaviors. Modern DevOps teams are attempting to log everything in an effort to improve the digital product and improve user-to-business interactions.
- Persistent Storage Tier – In some architectures, scalable-out persistent storage is required for databases or large datasets. These requirements are evolving from legacy SAN architectures to modern, software-defined storage architectures, often partner of converged (CI) or hyper-converged (HCI) infrastructure systems (e.g. Nutanix, Simplivity, EMC ScaleIO, etc.)
- Hadoop/Spark Tier – For big data architectures, many applications integrate with Hadoop or Spark to handle large-scale Batch, Search, and Analytics processes. These offline activities are intended to identify larger trends within data sets, in order to help refine the digital product experience. This tier is often called a “Data Lake”.
- Object Tier – For all types of unstructured data, the Object Storage Tier is used to store Configuration Files, Images, Dataset Snapshots, and create backups for various systems. Object tiers are simpler to integrate that legacy, clustered file-systems, and they have scalability architectures which allow global presence of replicated data.
Action Item: The architecture of modern applications are quickly evolving to address new challenges from mobile and analytics-driven applications. Developers, Architects and IT organizations must begin to understand the evolving architectures and best-practices for cloud-native applications if they want to be success in their business’ digital transformation.


