
Plan for a sequence of ever more sophisticated big data capabilities
Leading enterprises are starting to deploy Systems of Intelligence that, when mature, will bring together Data Lakes, machine learning, Systems of Engagement, Systems of Record, and systems that tune themselves against business objectives. For the past few years, the efforts have progressed with fits and starts. Enterprises have been experimenting with machine learning in Data Lakes, consumer loyalty programs within Systems of Engagement, and custom-built fraud detection applications. However, our Wikibon big data communities are beginning to talk about deployment patterns that build on each other, including (see Figure 1):
- Mastering Data Lakes pattern. Most big data pros are trying to use big data technology to create repositories with production-ready predictive models based on machine learning not of population segments but individuals. Successful practitioners are manually integrating disparate tools for data prep, modeling, and visualization and starting to simplify their execution engines with Spark.
- Designing Intelligent Systems of Engagement pattern. Applications with an engaging user experience grow in value if developers can integrate predictive models to anticipate, influence, and ultimately personalize each interaction. That requires deep integration of models between outward-facing consumer applications and live Systems of Record running operations.
- Evaluating Intelligent Self-Tuning Systems pattern. Many applications, like fraud detection, have new forms of suspicious activity show up and practitioners need machine learning to track automatically the new patterns without having data scientists always in the loop. Lots of new new computer science is required, but it is beginning to show up in technologies such as Spark and — in key cases — customers are participating as design partners.
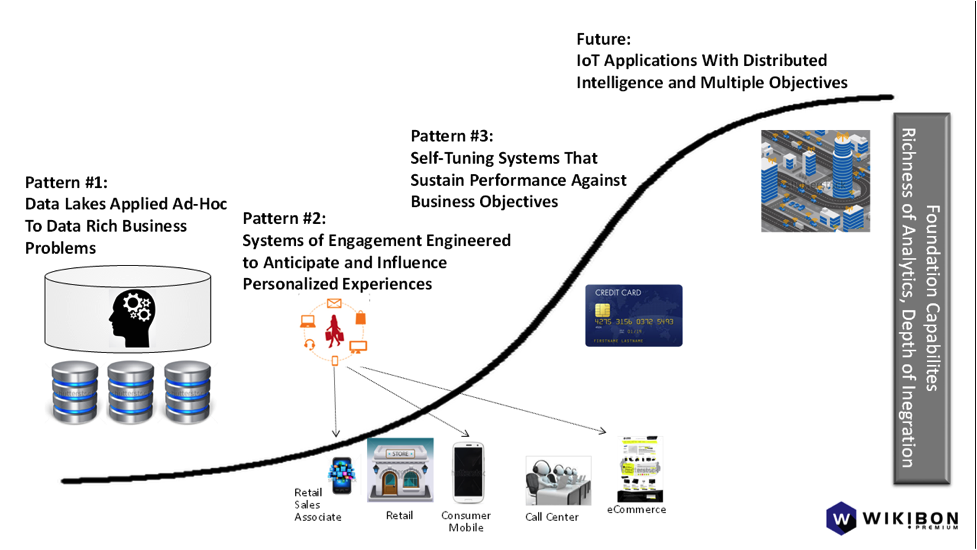
Pattern 1: Data lakes applied ad-hoc to data-rich business problems
About 75% of enterprises in the Wikibon community with a big data initiative are working with data lakes to apply data they previously couldn’t collect to find answers to questions they didn’t know they had. We estimate that 80% percent of these enterprises have at least one good experience applying the data lake pattern to a previously intractable application infrastructure management, cyber security, recommendation engines, or other data-rich business problem. However, too often success is hit or miss because of the challenge of working with dozens or hundreds of new data sources with discordant data prep and analysis tools and the challenge of administering the mix and match choice of analytic engines in Hadoop. To get the most out of data lakes, customers are trying to create models not of segments of populations, but of individual customers and precise prescriptions for improvements in internal operations.
The Wikibon community is starting to cobble together tooling for data preparation, modeling, and visualizing entire data sets, not just sampled data. Since these tools come from multiple vendors, customers are integrating them manually with custom workflows. In addition, the Wikibon community is increasingly deploying Spark for an increasing portion of their pipelines to simplify analysis and administration because it can perform the tasks of several specialized engines with one, much simpler runtime. Deploying the predictive models that come out of this analysis process to production applications is still a manual process for this application pattern.
Pattern 2: Systems of Engagement engineered to anticipate and influence personalized experiences
About 20% of organizations with a big data initiative are working to enhance Systems of Engagement (SoE) by adding capability that makes it possible to manage individual consumer experiences across multiple channels in in real-time . For example, an SoE at a telco might correlate a high number of recently dropped calls with churn among their most profitable customers. To keep its best customers, the telco might prioritize call connections in real-time for high-value customer in cell zones that are suffering high congestion, or throttle internet bandwidth for less valuable customers.
The production-ready analytic models required to coordinate interactions between consumers and a vendor’s operational applications typically don’t exist for the data lake pattern. Companies mastering this pattern are beginning to automate integration of data preparation, analysis, and production application workflows. This is challenging work that requires tooling for continuously benchmarking the quality of data lake models, thereby increasing the accuracy of parameters that are deployed directly into production applications. In the case of our telco example, they are deploying micro-app templates for customer lifecycle value, likelihood of churn, and network congestion to help automate workflows and deploy the right data to the right app at the right time.
Pattern 3: Self-tuning systems that sustain performance against business objectives
About 5% of organizations with a big data initiative are applying big data technologies to big data applications themselves, effectively employing big data techniques to tune the predictive models at the heart of Pattern 2. The goal is to sustain quality by minimizing drift as new data points show up. But data scientists have to get out of the loop of day-to-day model maintenance, though they still have to perform major model upgrades. In addition, the models themselves also have to coordinate multiple Systems of Record while a consumer is interacting live online. For example, a fraud prevention application needs a real-time view of activity across channels and products when evaluating a consumer’s online credit card authorization request.
After the data science process creates initial, baseline models about what constitutes abnormal behavior suggesting fraud, for example, the machine learning process must go online. This is extremely delicate and computationally expensive. The process works in conjunction with live, operational models. For example, when a model makes a decision about a credit authorization, a parallel process has to decide if adjusting the models with new data points will improve its accuracy. This capability already exists for some class of models in Spark. Finally, architects must embed the models so that they can coordinate with multiple, disparate Systems of Record. Flagging fraud in real-time might require feeding models with dozens or even hundreds of real-time database look ups across systems managing different products and channels. Self-tuning systems not only tune their models, but they “dial in” the level of accuracy of predictions relative to calculation speed so that the consumer experience remains interactive.
Action Item
The Wikibon community has only seen vendors deliver customizable templates that qualify as micro-apps for processes such as customer churn or product recommendation. Weaving these processes into broader Systems of Intelligence means building them into ever more sophisticated patterns. The key capabilities will ultimately boil down to two: 1) operationalizing the process of improving machine learning models, and 2) integrating them more deeply into Systems of Record. Ultimately, these must be self-tuning systems. As part of that process, companies should be able to choose a range of goals and trade-offs. For example, in fraud detection, by relaxing the required speed of response and taking a few more milliseconds to look up more details related to transactions, the application can return fewer denials that are “false positives”.
Table 1:
| Maturity | Capabilities | Technology challenges | Skills/operations challenges | Data movement latency | Transition challenges |
| Pattern 1:
Data Lakes |
Data Lakes begin as a repository for exploring data for unknown questions. They need to yield answers to repeatable questions. | They need to support “fine-grained” predictive modeling based on machine learning. | Manual workflow processes need to integrate disparate tools for “data wrangling”, getting past sampling, and benchmarking models’ accuracy. Hadoop also comes with high administrative complexity. | Batch data movement processes typical of data warehouses predominate. | Those models have to be deployed into production applications for ultimate success. Adopting Spark can simplify some of the complexity. |
| Pattern 2:
Intelligent Systems of Engagement |
Systems of Engagement need to be upgraded so they can anticipate and influence each interaction. | These systems need multiple predictive models with real-time integration between the consumer-facing apps and the Systems of Record that run operations. | Model deployment from Data Lakes to live systems has to rely on automated tools. | The data science process for producing models works in batch but the predictive models work in near real-time. | The ability to “dial-in” the trade-off between run-time precision by the models versus system response time requires finesse. |
| Pattern 3: Intelligent, self-tuning systems | Self-tuning systems must be able to drive multiple Systems of Record while continually calibrating how well they answer users and drive operations. | Predictive models from a live machine learning process have to coordinate the operation of many Systems of Record while maintaining performance SLAs. | Data scientists need to get their machine learning algorithms to the point where they can benchmark and tune themselves while operating in production applications. | Both the machine learning process and the output of the predictive models work in near real-time. | Future systems will need to cooperate with intelligent, distributed ecosystems of connected devices. |


