
ABSTRACT: The future of intelligent data platforms is being reshaped by the growing adoption of composable architectures and cutting-edge execution engines. This research delves into transitioning from traditional, monolithic data systems to flexible, scalable, and high-performance modular data platforms. Key technologies like the Theseus execution engine, which utilizes GPU-accelerated hardware, are highlighted for reducing energy consumption while drastically enhancing query performance. Emphasizing the critical role of open standards and interoperability, the article explains how organizations can build custom data platforms that integrate best-of-breed components from various vendors. The benefits of composable data platforms, such as cost efficiency, innovation, and freedom from vendor lock-in, are explored alongside the challenges of managing complexity, ensuring consistent performance, and maintaining security. As AI and big data analytics converge, this analysis anticipates the future landscape of data platforms, where advanced composability and execution engine technologies will empower businesses to stay competitive in an increasingly data-centric world.
As our theCUBE research conversation surrounding the next generation of intelligent data platforms evolves, two critical concepts emerge as pivotal to the future of data management: execution engines and composable data platforms. These concepts not only define the technical architecture of modern data systems but also shape the strategic decisions that organizations must make to remain competitive. This section delves deeper into these ideas, exploring their implications, challenges, and the potential they hold for transforming how businesses manage, analyze, and leverage data.
The Role of Execution Engines in Modern Data Platforms
Execution engines are the workhorses of data platforms, responsible for processing and querying data efficiently across various environments. In traditional, monolithic data architectures, the execution engine was tightly coupled with the compute and data storage layer, limiting flexibility and scalability. However, the rise of cloud computing, big data, and AI-driven analytics has necessitated rethinking this approach.
Modern execution engines like Voltron Data’s Theseus are designed to be modular and decoupled from the underlying compute and storage systems. This decoupling allows for greater flexibility, enabling the same data to be processed by multiple engines optimized for different tasks. For instance, a single dataset could be processed using a high-performance engine like Theseus for real-time analytics, while a more general-purpose engine might query the same data through Apache Spark for batch processing.
Theseus: A Case Study in Composability
Theseus, developed by Voltron Data, exemplifies the next generation of execution engines. It is designed to run on GPU-accelerated hardware, significantly reducing the power consumption associated with large-scale data analytics. This energy efficiency is particularly important in the context of AI and machine learning, where the computational demands are growing exponentially.
The modular design of Theseus allows it to be integrated into existing data platforms with minimal disruption. Organizations do not need to overhaul their entire data infrastructure to benefit from the performance enhancements offered by Theseus. Instead, they can plug the engine into their current systems, leveraging its capabilities to reduce costs, improve query performance, and decrease the environmental footprint of their data operations.
Theseus’s ability to process data with significantly lower power requirements, up to 95% less energy compared to traditional approaches, positions it as a potential key player in the future of sustainable data platforms. As data centers face increasing pressure to reduce energy consumption, execution engines like Theseus offer a path forward, combining high performance with eco-friendly operation.
Composable Data Platforms: Building Blocks for the Future
Composable data platforms represent a paradigm shift in how organizations design and deploy data systems. Unlike traditional monolithic architectures, where all components are tightly integrated, composable platforms allow each layer of the stack—storage, compute, execution, metadata, governance, and API—to be independently selected, deployed, and scaled. This modularity allows organizations to tailor their data platforms to specific use cases, optimizing performance, cost, and scalability.
The Foundation of Composability: Open Standards and Interoperability
At the heart of composable data platforms is the adoption of open standards, which ensure interoperability between different components. Apache Arrow, for example, has emerged as a critical standard for in-memory data representation, enabling seamless data exchange between compute, execution, and storage engines. Similarly, open table formats like Iceberg and Delta Lake provide a common framework for managing data across multiple platforms.
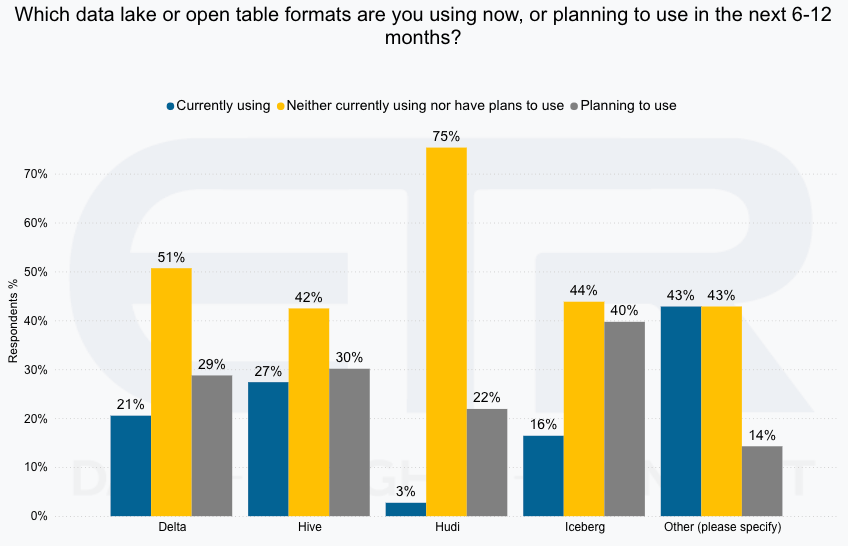
source: Databricks & Snowflake Shared Customers Survey July ’24 – ETR.ai
Adopting open standards is essential for realizing the full potential of composable data platforms. By standardizing how data is stored, accessed, and processed, these platforms enable organizations to mix and match components from different vendors, creating a best-of-breed solution that meets their unique needs. This approach reduces the risk of vendor lock-in and fosters innovation by allowing new technologies to be easily integrated into existing systems.
Composable Architectures in Practice
The practical implementation of composable data platforms can be seen in how organizations increasingly adopt multi-engine strategies. Instead of relying on a single, all-purpose data platform, they use specialized engines optimized for specific tasks. For example, a company might use one DBMS for lightweight, in-memory analytics while leveraging others for high-performance, GPU-accelerated processing. Using a common data format, these different engines can operate on the same datasets without requiring data movement or transformation.
Another critical aspect of composable data platforms is integrating with diverse data sources, including on-premise systems, cloud-based data lakes, and hybrid environments. This flexibility is crucial as organizations operate increasingly complex and heterogeneous IT landscapes. Composable platforms allow data to be stored in its optimal location, whether for cost efficiency, performance, or regulatory compliance, while still being accessible to the most appropriate execution engine for each task.
Advantages of Composable Data Platforms
The benefits of composable data platforms are numerous:
- Flexibility: Organizations can choose the best tools for specific tasks, whether for real-time analytics, batch processing, or machine learning.
- Scalability: Components can be independently scaled to meet demand, ensuring that resources are used efficiently.
- Cost Optimization: Organizations can reduce overall infrastructure costs by selecting the most cost-effective tools for each task.
- Innovation: The modular nature of composable platforms allows organizations to adopt new technologies, quickly driving innovation and competitive advantage.
- Reduced Vendor Lock-in: Open standards and interoperability reduce the risk of being tied to a single vendor, giving organizations more control over their data strategy.
Challenges and Considerations
While the advantages of composable data platforms are clear, their implementation is not without challenges. One of the primary obstacles is the complexity of managing a modular architecture. Organizations must have the expertise to integrate and maintain multiple components, each with its own set of dependencies and configurations. This can increase the operational overhead and require more sophisticated data governance and monitoring tools. But as we covered in the AnalystANGLE video and see in the ETR data, organizations already have multiple cloud-based and on-premises data platforms that they are managing.
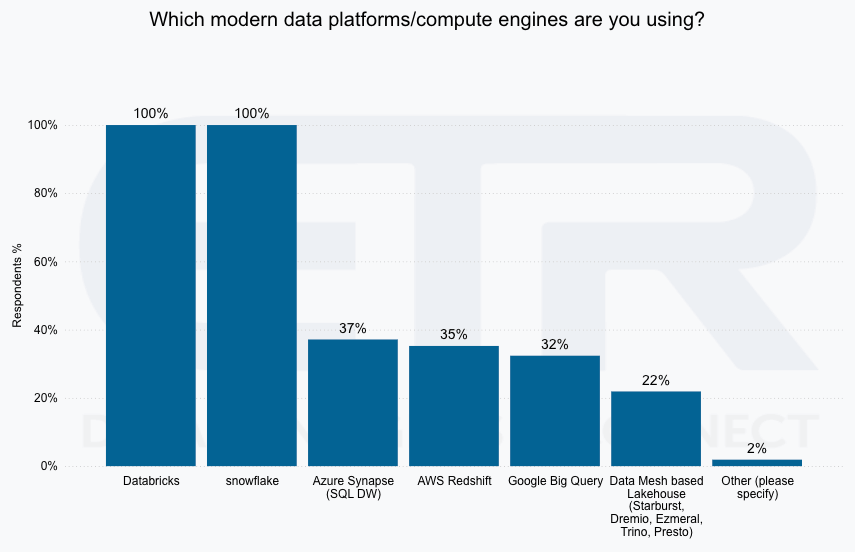
source: Cloud-based data platforms by shared Databricks and Snowflake customers, Databricks & Snowflake Shared Customers Survey July ’24 – ETR.ai
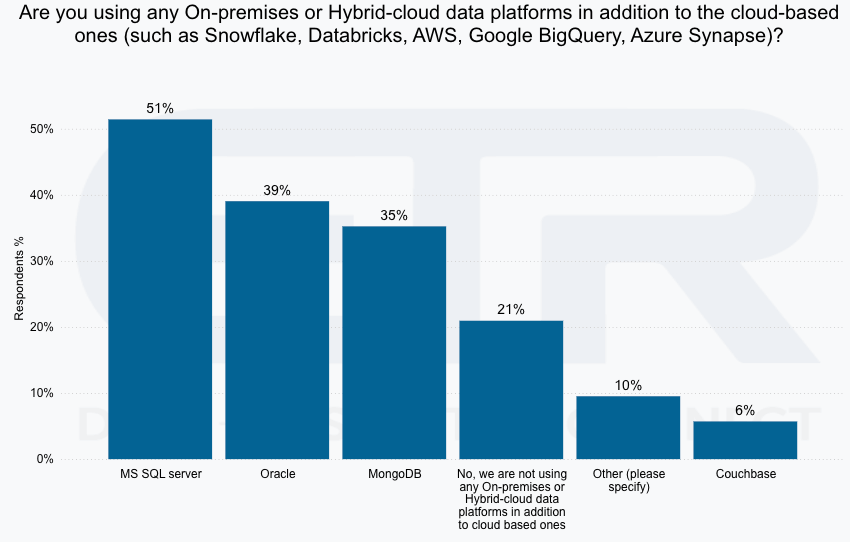
source: On-premises based data platforms by shared Databricks and Snowflake customers, Databricks & Snowflake Shared Customers Survey July ’24 – ETR.ai
Another challenge is ensuring performance consistency across different components. While composability allows for optimization, it also introduces the potential for bottlenecks if components are not properly aligned. For instance, a high-performance execution engine like Theseus might be constrained by slow storage or network infrastructure, negating some of its benefits.
Finally, security and compliance are critical considerations. As data moves across different systems and environments, ensuring it remains secure and compliant with regulations is paramount. Organizations must implement robust security measures, such as encryption and access controls, and ensure that all components adhere to the same standards.
Our Perspective
We believe the future of the next intelligent data platform lies in the continued evolution of composability and the development of more advanced execution engines. As technologies like AI and machine learning become increasingly central to business operations, the demand for high-performance, flexible data platforms will only grow. Execution engines can offer significant performance improvements and energy efficiency and will play a crucial role in meeting these demands.
Looking ahead, we can expect to see further advancements in integrating AI capabilities with data platforms. The convergence of AI and data analytics will drive the development of new compute and execution engines optimized for real-time decision-making, predictive analytics, and automated data management. These engines must handle increasingly complex workloads while maintaining composable platforms’ flexibility and scalability.
Moreover, adopting open standards will continue to expand, further enhancing the interoperability of different components within a composable architecture. As more organizations embrace this approach, the ecosystem of tools and technologies supporting composable data platforms will grow, offering even more options for customization and optimization.


