
Introduction
Low-latency and hyperscale computing are reshaping the fundamental design of databases and systems. As a result, the shape of the IT industry is being radically altered.
Wikibon projects the following principles for the deployment of flash, magnetic media, hyperscale computing and redesigned cloud-based enterprise applications:
- All active data will reside in flash and DRAM;
- The most active data will reside in the servers;
- Passive data will exist on magnetic media, disk and tape;
- The metadata about the passive data will reside in flash;
- Data haulage will be minimized, especially over distance;
- Data affinity (where the joining of data will optimize value) will determine the optimum location of data, and therefore of data processing;
- The hyperscale software-driven computing model will dominate consumer, federal government and over time enterprise IT spend;
- Rapid (by historical standards) migration to this new IT order will be accelerated by increased IT spend to unlock significant business value generated by innovative total enterprise applications;
- These new applications will exploit the new capabilities and extend the reach and range of new enterprise applications, not just decrease the cost of existing applications;
- The earlier adopters of new mainly cloud-based total enterprise applications will reap significant gains in productivity and competitiveness. These gains in the range of 10%-30% total enterprise productivity will in many cases be disruptive to a specific marketplace and result in significant market share for early adopters. The enterprises that initially succeed are likely to be mid-sized organizations that can decide quickly and migrate rapidly to the new environment.
Behind these principles is the consumerization of enterprise IT. The fundamental drive for flash is from mobile consumer products, and enterprise computing in support of consumers or enterprises rides on the coattails. Enterprise IT vendor innovation is and will continue to be primarily focused on and around hyperscale technologies built from largely consumer components. The greatest increase in enterprise vendor market value is likely to accrue to developers of new total enterprise application portfolios adapted to fit a business, rather than demand business change to fit the application.
This research is designed to help senior IT executives connect the dots between the different IT trends currently occurring, and assist in the development of optimal IT strategies. It will also inform very senior executives of software companies of the business potential of creating total enterprise applications with lower costs and much higher business value.
Case Study: The Changing Cost Of Database Systems
The case study is designed to illustrate the potential for rapid decline in the cost of IT computing for current applications. The fundamental technologies that drive this change are already tested and in place, although not yet in widespread deployment. This case study shows the dramatic reduction in database system cost determined by the increasing introduction of low-latency technology on existing applications. The next two sections will look at the reduction in costs from hyperscale and open-source technologies, and potential business benefits that accrue from the deployment of such technologies in enterprise applications.
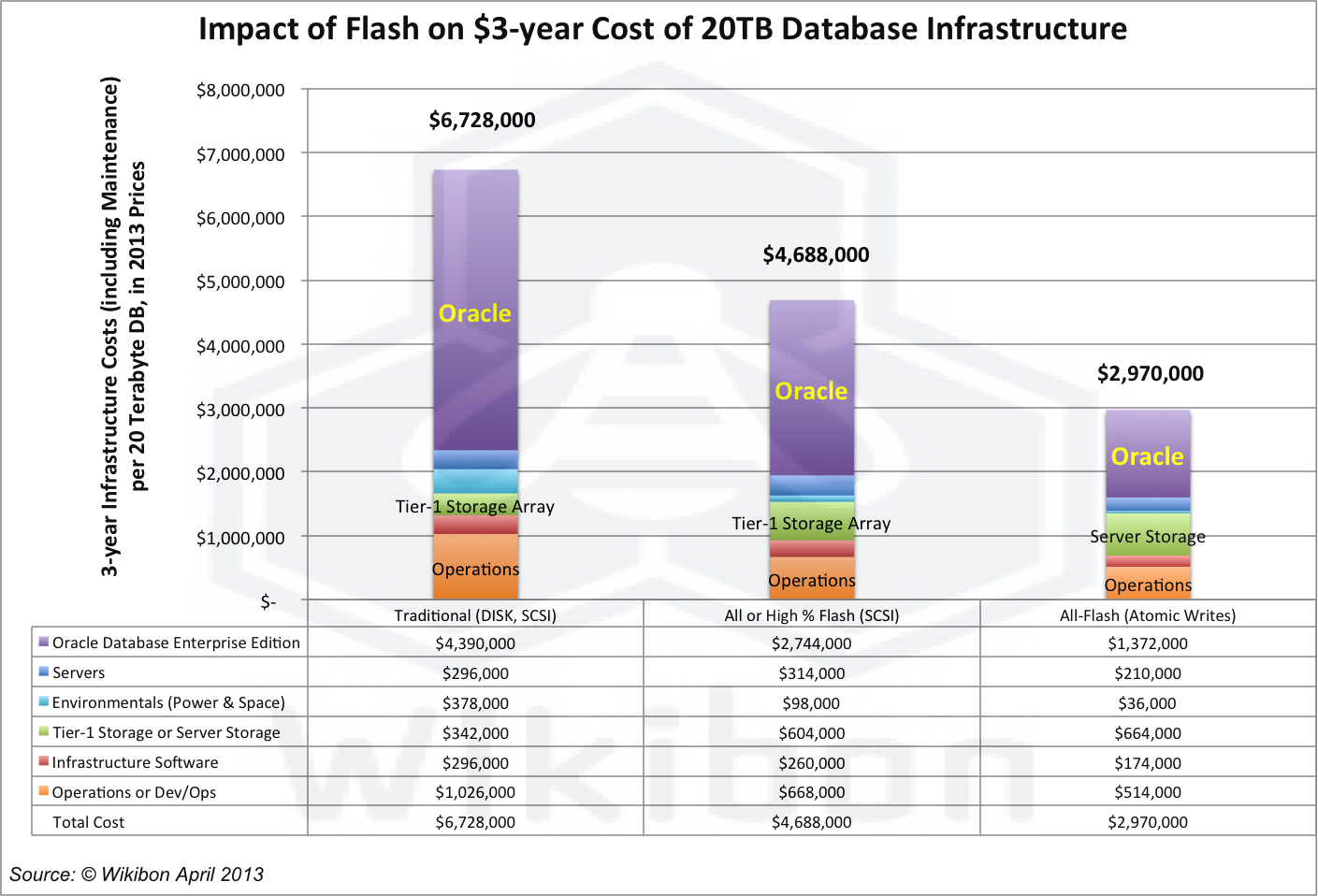
Source: Wikibon 2013, based on Table 1 and Table 2 in Virtualization of Oracle Evolves to Best Practice for Production Systems with the addition of Space, Power & Operational Costs.
Figure 1 takes the current infrastructure deployment cost of a tier-1 20-terabyte database (Column 1), and compares it to the costs of infrastructures optimized for low-latency and low-variance IO. Stage 1 (middle column of Figure 1) uses a configuration with very high percentages of flash storage using traditional SCSI IO protocols. Stage 2 (column three in Figure 1) introduces the impact of using server-based PCIe flash cards, which are implemented as an extension of processor main memory (DRAM).
Column 1, (Traditional, Disk, SCSI)
The cost of a traditional database infrastructure using Tier-1 storage using SCSI disk with little or no flash. The line items are a rearrangement of the detailed assumptions in Table 2 of a detailed study of Oracle best practice, with the additional of environmental and operational costs. This column represents the total 3-year infrastructure cost (including maintenance) of supporting a 20-terabyte database. Database licenses are the largest single component. The average IO response time is in the 5-10 millisecond range, and the variance usually greater than 1,000. There is tremendous intellectual property build up around optimizing mechanical rust.
Column 2, (All or High % Flash, SCSI)
The details in this section can be skipped. The bottom line is spending money on faster and more consistent IO results in less servers, far fewer Oracle licenses and reduced cost. The average response time is 1-2 milliseconds, improving the response time in column one by a factor of 3-10 times, and variance (in an all-flash array) by up to 2,000 times.
- Details about Cost: The cost of database infrastructure with Tier-1 storage with at least 20% tiered flash, or an all-flash array with 100% flash. At this time (April 2013) there are no Tier-1 all-flash storage arrays in production, as defined by Wikibon, although Wikibon expects the functionality of all-flash arrays to improve to tier-1 functionality and availability by early 2014. The storage protocol is still SCSI. The mean IO response time is less than 2 milliseconds. The key impacts of additional spend on flash storage and optimized servers is to reduce the IO response time and variance. Key components of the database can be pinned, and a tiered storage system is assumed. The write IO time for log files is usually a critical throughput metric. The impact of improving IO response times is to reduce CPU IO wait time, and this in turn reduces system overhead and improves CPU utilization. The net effect is to reduce the number of cores required by about 37%. The detailed analysis of the reasons is given in the “Optimizing For CPU IO Wait Time” and “The Cost Impact Of Optimizing Database Infrastructure” sections of the report referenced above.
- Details about Caching:Caching techniques with small amounts of cache are efficient at improving some workloads. Large amounts of cache are not suitable for database IO. Although caches improve read response times and gross performance issues, they do not achieve much for a well-balanced database system that cannot be achieved with storage controllers with additional DRAM. In general caching techniques only improve IO reads, and radically increase IO variance. Consistent low-latency write performance usually has the greatest impact on the overall locking rate that can be sustained.
Column 3 (Server Flash, Atomic writes)
The details in this section can be skipped. The bottom line is that atomic writes can place a 64 byte block of data in persistent storage in 100 nanoseconds in a single write. This is 10,000 times faster than traditional SCSI writes. For existing database systems this enables at least a doubling of throughput, and a doubling of flash endurance as data is only written once.
- Details about Server Flash Storage: The flash storage in the server is on a PCIe card, and flash controller on the card connected directly to the server bus. The flash storage is treated as an extension of main DRAM memory. A new file system replace the traditional SCSI writes with atomic writes directly to the PCIe flash controller. A virtual mapping architecture and software in the server allows tight communication between the server and the storage, and allows a sparse matrix of non-contiguous virtual elements in memory to be mapped to a sequential log file in the PCIe flash card. The atomic write is the same line width as the server bus architecture (64 bytes in Intel’s x86 current implementation) and can be increased. APIs from the file system allow different types of atomic write. The acknowledgement of a 64-byte block atomic write is given as soon as the data is written to capacitance protected DRAM (or MRAM) in the PCIe flash controller, about 100 nanosecond. Only a single write to flash is required, which doubles the flash endurance. Early benchmarks of database systems using this technique show throughput improvements of about twice. For an additional deep dive on flash storage technologies, see Note 3 in footnotes.
The Business Impact Of Improved User Response-Time
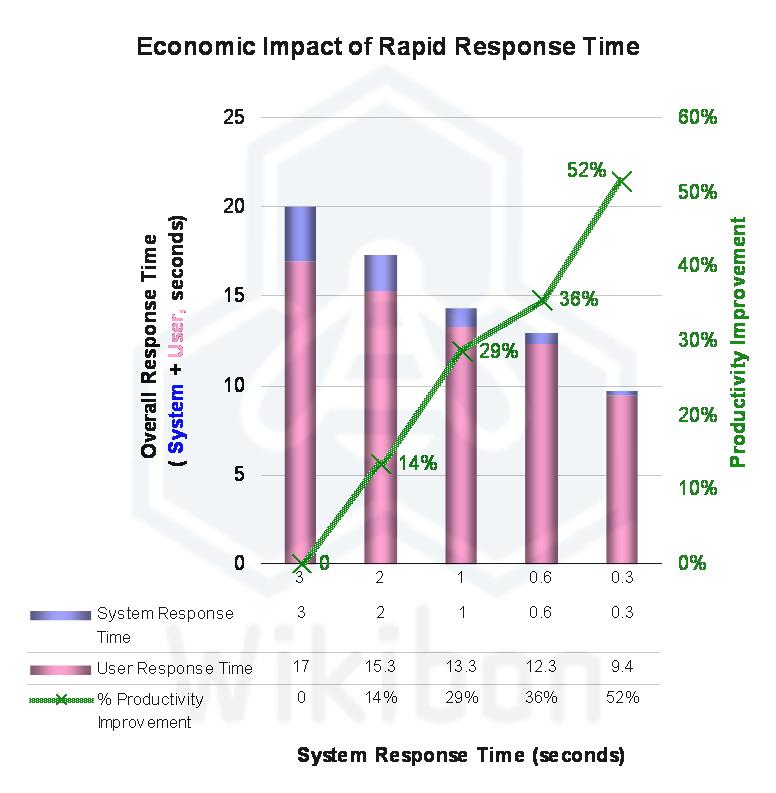
Source: Wikibon 2011|Case Study: The Hunting of the RARC, based on data from Figure 3 in a seminal paper Economic Value of Rapid Response Time, Walter J. Doherty and Ahrvind J. Thadani, IBM’s Thomas J. Watson Research Center (1982).
One impact of improving user response times as a result of improving IO response times is to improve user productivity. Wikibon re-presented some IBM research, which showed that improving user on-line response time had an overall improvement in productivity of the user. By reducing transaction response time from 3 seconds to 0.3 seconds, the productivity of a user was improved by 58%. Earlier survey research by Barometrix showed the amount of time spend actively using IT varied significantly by industry, but overall was in the range of 5-20%. Typical IT application response times are in the range 1-3 seconds.
The range of overall business improvement in productivity from increasing end-user response times is therefore between 1% and 12%. The business case for implementing improved end-user response times and reducing the overall cost of database systems is overwhelming, but not the whole story. The use of low-latency computing to change the design of systems is addressed in the next section.
The Business Impact Of Radical Redesign Of Enterprise Applications
The impact of the huge difference in speed between processors and current storage leads to the design principles behind today’s enterprise systems. Designers always keep the number of database calls low in transactional system of record. If this exceeds 100 database calls per transaction, there are significant implications in the cost of operations and the cost of application maintenance for such systems. Performance can go to hell in a hand-basket. As a result, the ease-of-use of many applications is less than perfect with significant training costs.
The limit on application design goes much further. One database of record would be the simplest way of designing an enterprise-wide system. However, if SAP had tried to implement such a design for a large organization (or even a small one, as will be seen later), that database would never scale. The locking rate on the database would be far beyond what the traditional IO systems could support. Even the fastest sustained traditional IO in SANs of just below 1 millisecond would not allow a significant reduction in the number of databases required. There have been recent investments in NoSQL databases, that reduce the database adherence to the ACID properties. This can be effective in increasing throughput when data integrity is not paramount (e.g., in research systems), but if data integrity is required the complexity of providing it is given back to the programmer.
The result of this persistent storage performance problem is that enterprise applications have had to be designed by creating many loosely connected system modules (See Note 1 in footnotes for an SAP example of modularization) held together by many loosely connected databases of record. As consultants implementing enterprise systems such as SAP will attest, it is extremely complex to take a typical enterprise-wide application and implement it in a real organization. Often the package will have to be modified to fit the organization, and many times the organization will have to be reorganized in order to accommodate the package. This is illustrated in Figure 3.
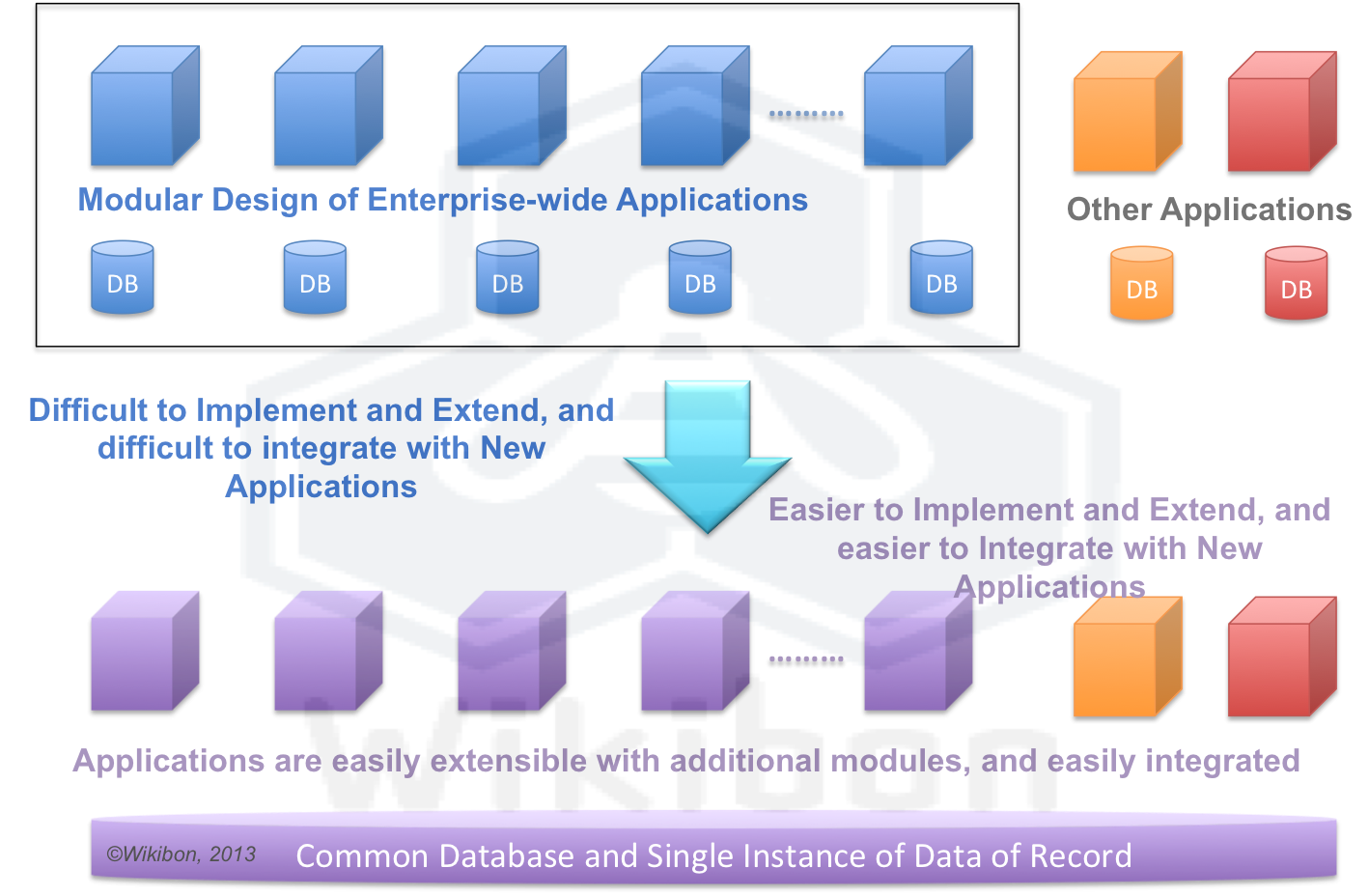
Source: Wikibon 2011, Case Study: The Hunting of the RARC, Fit the Sixth
Figure 3 illustrates that improving the time to protect data from 1 millisecond to 100 nanoseconds, a 10,000 times improvement, can lead to a radical design simplifications (see Note 2 for discussion on the impact on other NVM technologies). The number of databases can be drastically reduced, reducing the overall system complexity. Modules can be process extensions, and can be independent of database considerations.
The case study referred to in Figure 3 was Revere, a 200 person electrical distributer in Chicago. Their core application was the Epicor Eclypse ERP system, which was designed round a single set of tightly integrated databases. Revere found as they implemented more modules, the effect was to slow the database to a crawl. IT responded by limiting the use of functionality during business hours to only core functions such as the call center (taking new orders) and warehouse activities. This became a major irritant and a major cause of inefficiency to other parts of the organization. Revere IT then put the whole Eclypse database onto a PCIe Flash card, with a mirrored copy on another server and PCIe flash card. The impact was dramatic – response time improved dramatically, and all the advanced function for all the other parts of the company were able to be turned on again, and operated in real time against the common database.
Revere was able to increase revenue by 20% over the next twelve months with no increase in headcount. Revere attributed at least 50% of the improvement to lower response times and the availability of the full functionality of the Eclypse package to the whole company. The resulting productivity increase was a major contributor to enabling Revere to increase business. Without any productivity gain, the company would have had to hire about 40 people to take care of the growth. The savings in people costs went straight to the bottom line, and were many times the total IT budget.
The benefits at Revere were achieved with the use of rapid IO using traditional SCSI protocols. For large organizations and larger applications, atomic writes would also be required to allow the locking rates to be processed. Many large enterprise and government projects trying to integrate multiple systems have ended in incredible resources being applied, but nothing being achieved. Simplifying the system design would allow a much better chance for success.
THe last question to be addressed is how modern applications be developed and deployed, and the role of hyperscale and cloud computing, which will be addressed in the next section.
Case Study: The Impact Of Hyperscale & Cloud On Database Systems
The largest internet service providers such as Amazon, Apple, Facebook, Google, Microsoft, Yahoo and Zynga use hyperscale systems in very large data centers. These systems are defined to fit a relatively small number of systems or system components. Most use ODMs to build these systems to their specification. The internet providers tend to spend on people to save on equipment and software, and to tailor open-source software and commodity hardware and software to the needs of the applications. The core of their business is the quality and value of their applications.
In contrast, enterprise data centers support many applications, and tend to spend on equipment and software to save on people costs. That spending includes outsourcing facilities and operations to large data centers, and increasingly outsourcing to cloud service providers. These cloud providers are using much lower costs, using open-source software where possible, and are spreading the costs over many customers by running a multi-tennant environment across multiple locations.
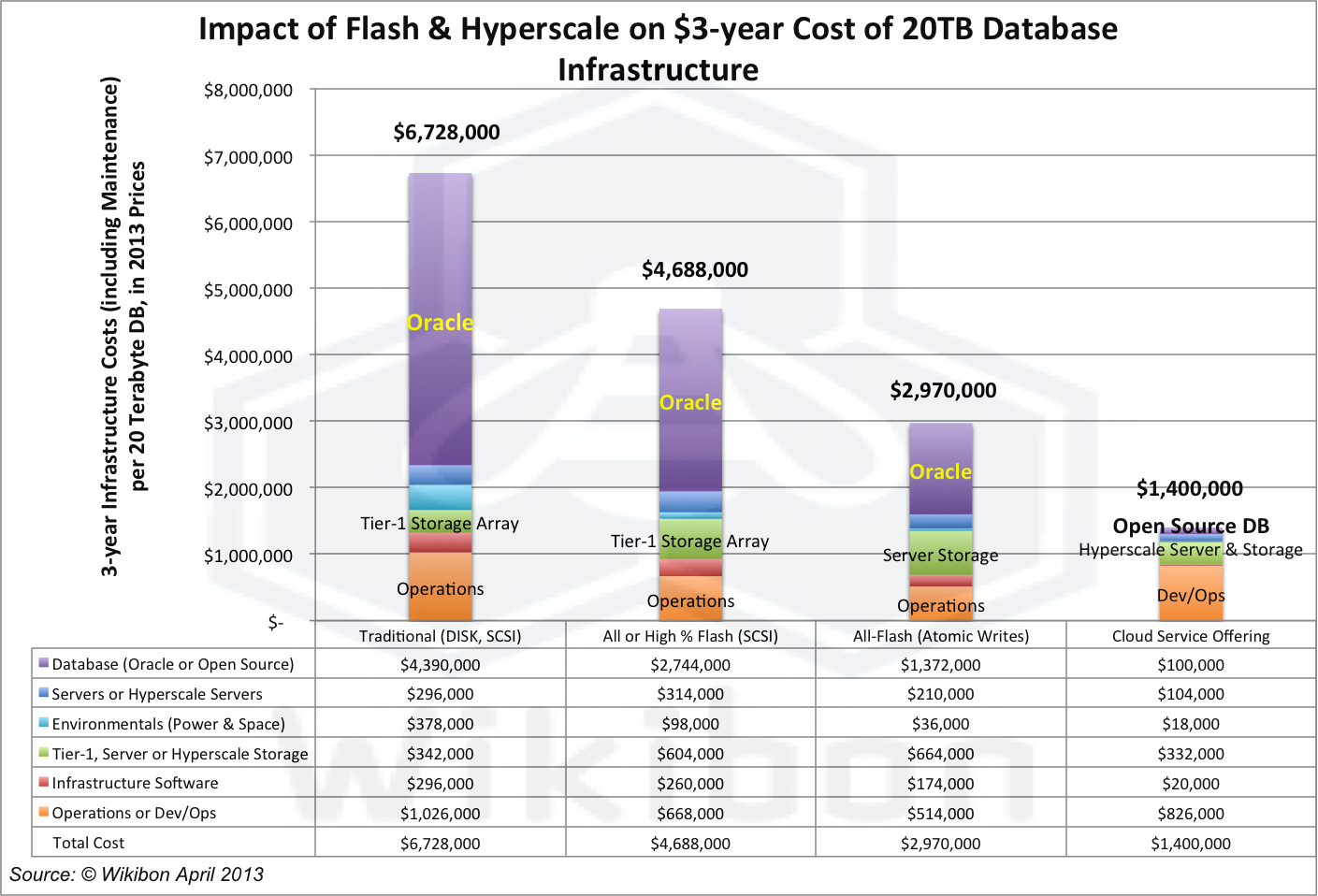
Source: Wikibon 2013]]
Figure 4 introduces an additional column to illustrate the impact of hyperscale and cloud computing on how the new designs of enterprise applications are implemented, and the cost implications. Hyperscale computing is currently being deployed by large IT service providers, and are usually centered round a specific application. At the moment many of the applications are consumer (e.g., Zynga), but an increasing number of industry vertical specific. The detail for Column 4 in Figure 4 shows that the database costs have dropped to zero, but the cost of people in Dev/Ops is much higher as additional functions such as extremely secure multi-tenancy are developed and maintained. The advantages of this environment for both developers and users is one where additional function can be developed and implemented more quickly, the costs of deployment are minimized, and the security and compliance can be externally audited.
Case Study: ServiceNow A simple case study would be a SaaS company like ServiceNow, which fundamentally provides a system of record for IT. They have found a niche in providing integrated operational systems such as service desk, change control, incident and problem management and charge-back/show-back. Most organizations have implemented a host of separate point systems and tools that provide a solution to a single component. These tools use different databases and different terminology, and are extremely difficult to integrated. By providing a framework approach round a single database, and allowing easy extensions to be made to fit a specific customer within a multi-tennant infrastructure, ServiceNow has been able to offer a single IT integrated IT work-flow and management system round a single set of integrated MySQL databases. ServiceNow As a result ServiceNow has grown dramatically as organizations have embraced an “IT-as-a-service” model compared to the DMV-like “wait-in-line” model. ServiceNow is helping CIOs focus on work-flow rather than the details of database and data storage, and growing very fast as a world-wide organization.
The disruption from SaaS cloud service companies such as ServiceNow is blending the development of ISV development and Infrastructure management to provide a new and much more productive model of business management to organizations, and replacing legacy ISV point products with an enterprise-wide work-flow enabler. Wikibon believes that companies like ServiceNow will emerge to take on not just 3-6% of IT part of the organization, but the largest work-flows of organization. SAP is a large successful ERP ISV dependent on expensive software and hardware infrastructure, and difficult to implement and maintain. The opportunity is for new ISV vendors to create ServiceNow-like solutions for specific verticals, and focus on developing the ability to deliver, manage and change flexible work-flow systems for their customers. The key is going away from the modular design shown in the footnotes towards a single tightly integrated set of databases which support the work-flows relevant to specific organizations. The race is on between the ability of legacy ISVs to adapt and new ventures to subsume.
Either way, there is potential for significantly improved productivity for enterprises, and greatly enhanced returns on investment for IT spend, and the probability that IT budgets will grow to take advantage of the disruptive forces and potential for improvement.
Frequent Objections
Three objections often heard show a profound misunderstanding of computing systems in general and storage systems in particular:
- Flash – that’s only for Wall Street traders and other fringe applications – it’s a small segment of the market – (every disk vendor);
- Disk drives will continue to rule; there is insufficient capital to builds flash fabs – (CEO of RAID storage system manufacturer);
- Flash technology is going to hit the wall after the next generation – (every disk vendor, and proponents of other non-volative storage such as MRAM and RRAM).
- Flash storage on a server cannot be protected – (every disk vendor who believes that data on SANs is 100% protected)
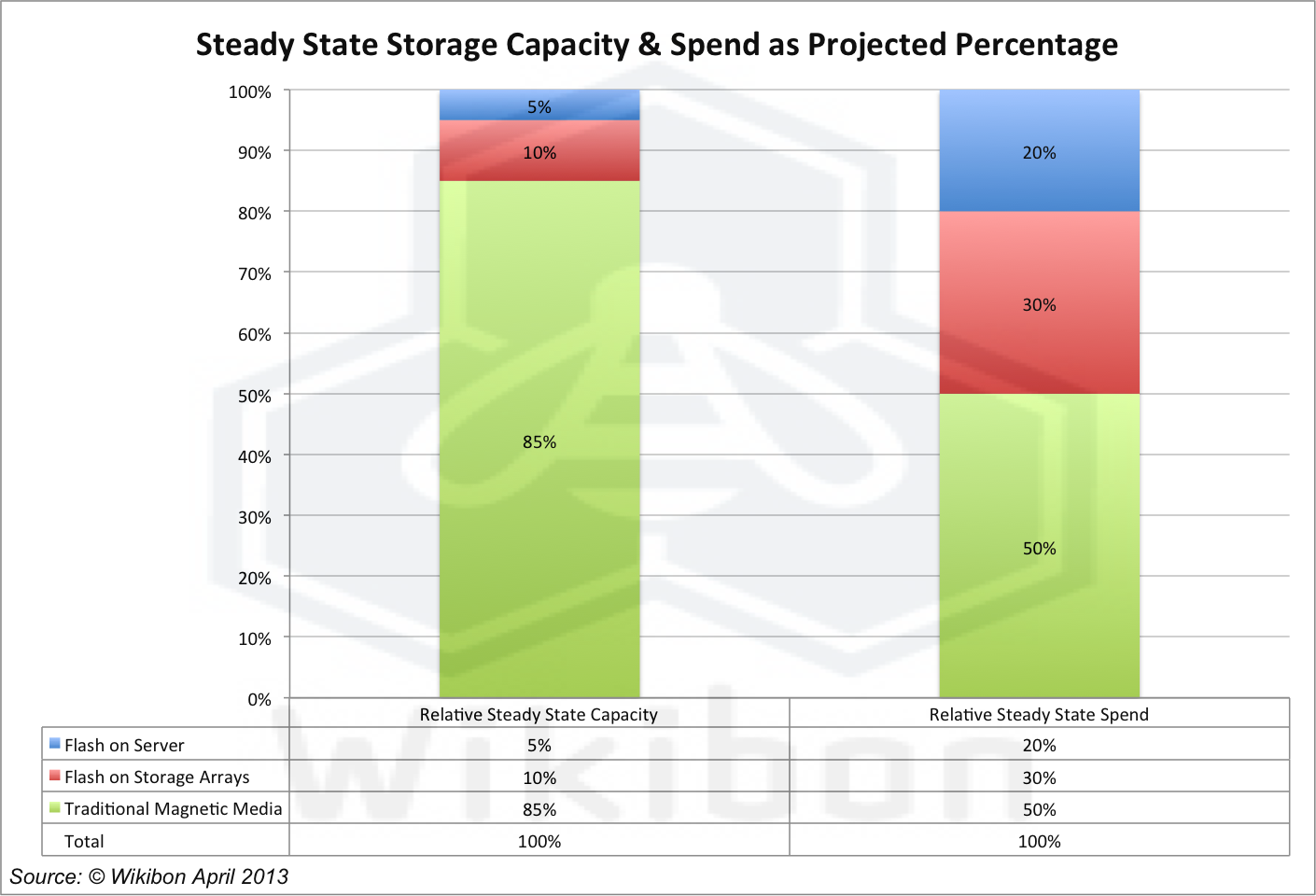
Source: Wikibon 2013
The ten principles of deployment of flash, disk and tape above make it clear that the most cost effective way of storing passive data is on magnetic media such as disk “Tubs” or tape libraries. Figure 5 shows a likely “steady state” capacity and spend for flash on server, flash only storage arrays and magnetic media. These technologies are being driven by the consumer markets, and adapted for enterprise use. There are huge investments being deployed to improve these technologies for consumer devices; history is on the side of continuous improvement to the existing flash and magnetic media technologies, rather than the introduction of new memory technologies such as RRAM or optical. The percentages in Figure 3 are supported by investment availability for consumer and enterprise demand.
Also clear is the potential for redesigning systems to simplify IT will impact every government and enterprise organization. Low-latency persistent storage is a tool to release this capability for all organizations.
Server vendors are perfectly capable of providing very high availability of persistent storage on servers, as are SAN and storage vendors. All should acknowledge there can never be 100% data availability or zero RPO.
Please feel free to contribute additional objections with or without rebuttals to this section!
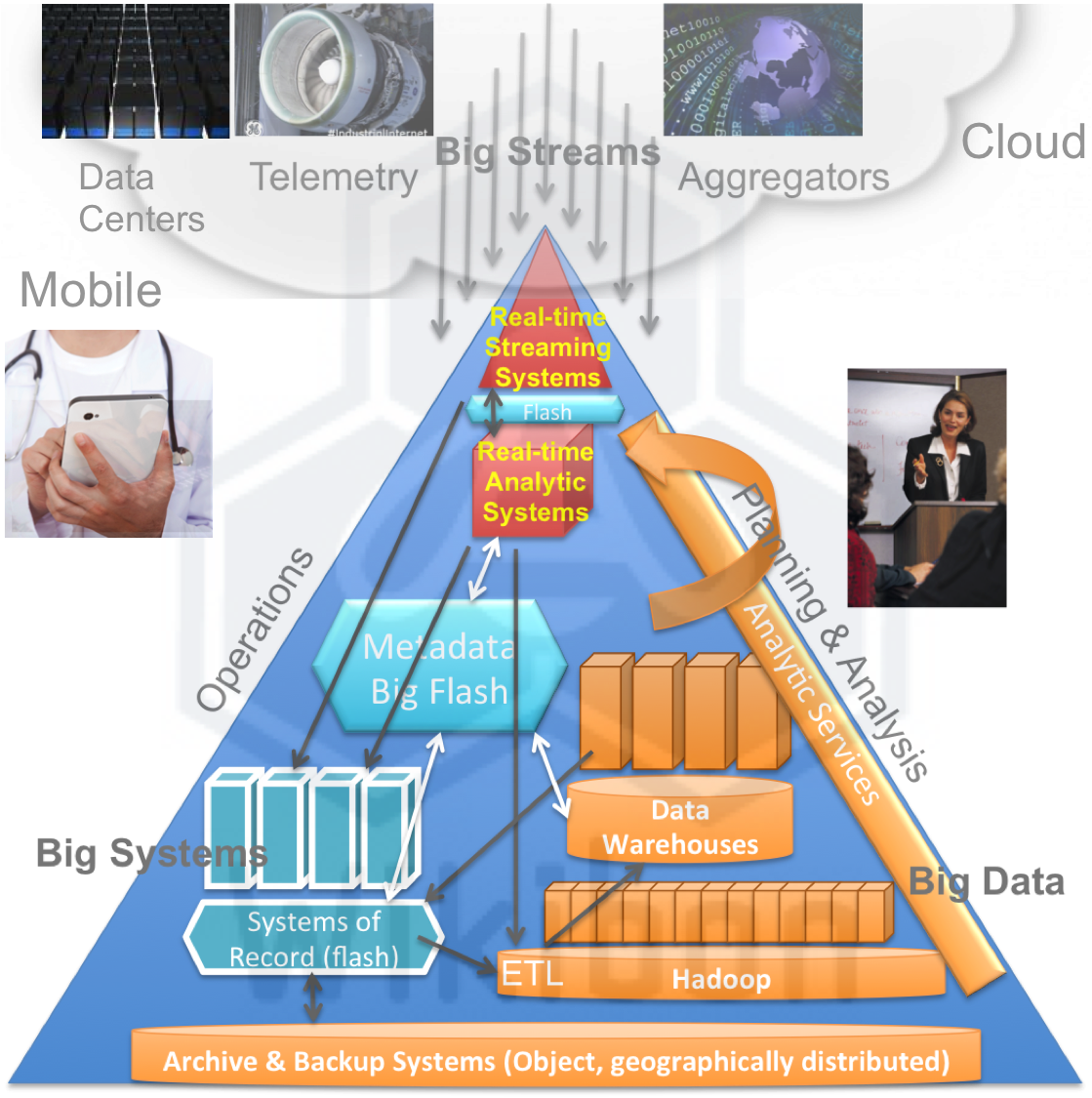
Big Streams, Big Systems, Big Data & Cloud Computing
Figure 6 below shows a topology of enterprise systems, and the interaction between them. The left hand side of the triangle represents the operational systems of record, and the right hand the planning and analytical control systems. At the bottom are the backup and archive recovery systems. There are three different types of system at each corner:
- Big Streams: These sensor systems deal with the large amount of data coming in in real time from customers, partners, suppliers, supply chains, weather, competition, political, environmental, web access, security, video, the universe of things, etc. It deploys realtime transactional and analytical systems to make near-realtime recommendations or updates on (say) the price of goods and services, or take action (say) when a global cyber-security exposure is detected. The Big Streams system will then pass data through to the systems of record, and the planning and analytical systems, as well as update the metadata. Big Streams databases for example will make significant use of flash technologies, such as Aerospike does today.
- Big Systems: These systems of record take input from customers, suppliers, partners, etc., and process the changes. In contrast to today, Big Systems will have flatter series of tightly integrated databases in the server that will allow much higher levels of performance. Instead of the modular structure dictating the work-flow, the database will offer support for any work-flow that makes business sense for the organization. Data will flow from the Big Systems to the ETL systems (such as Hadoop) and data warehouse system, as well as to the metadata and backup and archive systems.
- Big Data: These systems will allow data to organized and analyzed, with much tighter integration between the data warehouse and the systems of record. Where up to the minute information is required, the system of record will be used, and where data is required by accounting period, the data warehouse will be the main source of reports. Integrated into the flow will be systems of provenance and immutability to ensure the integrity of analytical and planning systems.
- Backup & Archive: Backup, recovery and archive systems are likely to be object based and geographically spread using techniques such as erasure coding. The main system of storage will be magnetic “data-tubs”, with very high storage capacity and low access capability. The metadata about this data will be stored in flash, allowing multiple views of the backup and archive data to a single copy. This allows much less data to be stored and shared for multiple purposes. Again, the usual systems of provenance and immutability will be in force.
- Metadata & Big Flash: With a growing disparity between the accessibility of data on magnetic media compared with flash, metadata and metadata management become of crucial importance. Metadata repositories will need to be held in flash to allow systems to understand information about the data and minimize the number of detailed data records retrieved. Metadata management at the file level has improved immeasurably recently with technologies like IBM’s GPFS. These will need to be extended much further to allow system wide integration.
The advent of data streams from the web, data aggregators and the universe of things could mean that the cost of hauling data to an enterprise site will escalate, as well as the elapsed time to receive the data. A simple remedy is to move the enterprise systems to very large data centers that will center round specific verticals. These data centers are likely to house cloud providers, data aggregators, and the systems of many competing enterprises. Also avaiable in these mega data centers will be multiple data carriers that will ensure reasonable data haulage costs where necessary, and well has hyper-fast connection to alternate sites. The fundamental principle is that data haulage costs (amount of data x distance) should be minimized. The cost and elapsed time to “back-haul” data by throwing a cable between two systems within a mega data center is by far the lowest cost, and will allow a rich ecosystem of support cloud systems to develop. A model for such an approach is the SuperNAP colocation facilities in Las Vegas, Nevada, where (for example) a large number of the film industry have their processing, and where an ecosystem of cloud providers supply (for example) editing and CGI services.
The cloud service providers with a limited number of applications and a focus on reducing equipment cost will be early adopters and exploiters of hyperscale computing. This is also very likely to be incubation grounds for the emergence of new enterprise-wide applications that will allow flexible work-flows (such as the ServiceNow example above). The effect of using open-source databases and infrastructure were illustrated above. A new ERP system better suited to the (say) film industry, and built on low-latency principle above would allow much greater flexibility to meet the differing work-flow requirements in the industry, as well being much easier to adapt to future changes. Although in theory SAP or Oracle could develop these systems, history suggests that this is unlikely to happen.
In summary, data will flow from storage arrays to the servers, servers will flow from enterprise data centers to mega colocation facilities, applications will flow from enterprise systems in the colocation facility to cloud services in the colocation facility, data will flow from enterprises and many other sources to data aggregators within the mega colocation facilities, which in turn will flow back to the enterprises and drive their systems. All in the flash of an eye!
Source: Wikibon 2013
Conclusions And Recommendations
The key conclusions are:
- Current applications and application designs are severely constrained by IO;
- Low-latency IO reduces the constraints, and enable significant savings in database license requirements and other infrastructure costs;
- Very low-latency IO enables the redesign and integration of enterprise-wide applications, and simplifying the database architecture;
- Hyperscale and Cloud computing, together with very-low latency IO, allow new cloud ISVs the opportunity to offer integrated applications that can be moulded to ever-changing work-flow requirements of the enterprise rather than require the organization to adapt to the package.
- Computing will gravitate to very large data centers, housing both enterprise data centers, cloud providers and data aggregators that are relevant to an industry. These data centers will support multiple data carriers, and provide ultra-high bandwidth to secondary sites. This move will be driven by the high cost of hauling big data, and the benefits of quicker elapsed to to process big data.
Wikibon believes this is a profound change in IT and the potential value IT can bring to organizations. Wikibon expects this trend to start with mid-sized companies, who will move faster to ensure competitive advantage. Overall, Wikibon expects that IT spend will increase as a result of this trend, because of the very high returns of 20% or higher productivity improvements for most organizations. All organizations should have a strategy for moving towards this environment, and for taking advantage of new application opportunities. CIOs should be engaging senior executives in the likelihood that IT budgets will and should increase over the next decade, as application on much high functionality and adaptability become available.
Action Item: CIOs and CTOs should look closely at their application portfolio, and identify:
- Applications (particularly databases) that can benefit from database or other software cost reduction today with low-latency IO
- Applications that are under IO constraint where end-user response time can be improved or throughput enhanced with low-latency IO
- Applications where databases can be merged and simplified to improve functionality
- Applications (particularly from emerging cloud ISVs) that show promise in replacing legacy enterprise wide frameworks and applications that are constraining abilities to redefine work-flows
CIOs should start to inform CXO’s and board members of the potential increase in IT value coming from applications exploiting low-latency, hyperscale and cloud services, and the necessity of increasing IT spend to exploit a once-in-a-career opportunity to enable competitive advantage.
Footnotes:
Note 1: Example of Modular Construction of an Enterprise Application:
- SAP FI Module- FI stands for Financial Accounting
- SAP CO Module- CO stands for Controlling
- SAP PS Module – and PS is Project Systems
- SAP HR Module – HR stands for Human Resources
- SAP PM Module – where Plant Maintenance is the PM
- SAP MM Module – MM is Materials Management –
- SAP QM Module – QM stands for Quality Management
- SAP PP Module – PP is Production Planning
- SAP SD Module – SD is Sales and Distribution
- SAP BW Module – where BW stands for Business (Data) Warehouse
- SAP EC Module – where EC stands for Enterprise Controlling
- SAP TR Module – where TR stands for Treasury
- SAP IM Module – where IM stands for Investment Management
- SAP – IS where IS stands for Industries specific solution
- SAP – Basis
- SAP – ABAP
- SAP – Cross Application Components
- SAP – CRM where CRM stands for Customer Relationship Management
- SAP – SCM where SCM stands for Supply Chain Management
- SAP – PLM where PLM stands for Product LifeCycle Management
- SAP – SRM where SRM stands for Supplier Relationship Management
- SAP – CS where CS stands for Customer Service
- SAP – SEM where SEM stands for STRATEGIC ENTERPRISE MANAGEMENT
- SAP – RE where RE stands for Real Estate
Source: SAPtraininghub.com
Note 2: The very low elapsed time for writing out to the flash controller and receiving an acknowledgement puts in question the future of other non-volatile memory (NVM) contenders, such as MRAM, PCM and RRAM other than for niche usage. Unless a new NVM technology is adopted in consumer products in volume, the continued investment in flash technologies driven by consumer demand will make volume adoption of an NVM alternative very unlikely, and make their adoption in enterprise computing economically impossible. Wikibon believes that flash will be the only NVM technology of importance for enterprise computing at least the next five years, and probably longer.
Note 3: Technical Deep Dive! In the early days of computing, all data was held on magnetic drums. These had a single head per track, and rotated at 17,500rpm. There were 25 sectors per track. By optimizing the placing of instructions and output data on the tracks, a maximum processor speed of 400KHz, and a practical speed 100KHz. Memory access was in line with processor speed. It took it 1 microsecond to process and 1 microsecond to write to persistent storage. Today the processor speeds are in GHz (>1,000 times faster), and the magnetic media write times in milliseconds (~1,000 times slower); a net increase in difference of 1 million times (10 6). This difference has been offset by reading and writing large blocks, increasing the multi-programming levels of OS and file systems, increasing the number of cores, increasing the IP invested into the IO storage controllers and, most importantly of all, increasing the functionality and complexity of the database systems to protect data, primarily from Oracle, IBM and Microsoft.
The has been recently a move to address this disparity with All-Data-in-Memory databases, which have used DRAM protected by battery backup to provide persistent memory. This is a very expensive solution with expensive databases, that does not scale well. Data in DRAM in combination with Data in flash memory is in general a more scaleable and lower-cost solution.
With atomic writes, the difference is reduced by 10,000 times, from a best of 1 milliseconds to 100 nanoseconds for a line write of 64 bytes. The flash technology is silicon based and not constrained by mechanical limitations. The reduction in speed between the technologies should not increase again. This will lead to significant reduction in complexity in IO engineering, and an radical increase in the size and complexity potential of the applications , rather than the database.



{kind=link}