
Introduction
The workloads within enterprise performance computing include large scale mission critical applications with high performance requirements. These applications require high performance to get the job done, high availability to enable the platform to “take a lickin’ an’ keep on ticking'”, and have a reasonable cost. The platforms for these workloads require an architecture that will deliver these characteristics.
Enterprise performance architecture can be thought of as a three-legged stool with each of the three legs contributing to balance:
- High Availability – to detect and recover from server, storage and software problems with the minimum loss of data (RPO) and minimum recovery time (RTO)
- High Performance – requiring:
- Clustered high performance processors with large memories;
- High performance persistent¹ storage;
- High performance network performance with very low consistent latency and high bandwidth.
- Reasonable Cost – reasonable cost to acquire and maintain.
In addition, these systems needed to have simple programming structures based on an available ecosystem of enterprise software.
Until now, architectures could usually only deliver two of the three requirements and there are some workloads that can run well in these environments. For instance, big data systems such as Hadoop can run cost effectively on a distributed node system (see section below for a full discussion), if the code can be decomposed to run efficiently on distributed nodes. However, in this architecture the network is the bottleneck for general high performance, and the challenges of set-up and restart make high availability very difficult to achieve within reasonable cost constraints. Mainframes can deliver high availability and high performance, but with high cost. Wikibon believes that Flash as Memory Extension will allow all the criteria to be met, and will become the enterprise performance platform of choice.
Premise: Wikibon believes that Flash as Memory Extension, or FaME, can provide high performance, high availability and reasonable cost, and will become the dominant architecture for performance enterprise computing.
This research analyzes the different system architectures available now for enterprise computing, and discusses the advantages and disadvantages of each. The four architectures are:
- 2-Node Architecture with PCIe Flash
- Distributed Node Architecture
- Data-in-Memory Architecture
- All-flash Array Architecture
Wikibon has researched in detail the comparison between these architecture and the FaME architecture. We conclude that for the majority of enterprise performance applications, the FaME architecture will be the most performant, the lowest cost for developing applications, the lowest cost to maintain and manage, and be enterprise reliable. With FaME systems appearing in 2015, Wikibon believes that CIOs should ensure that FaME architected systems are installed early, and should be asking their brightest and most creative staff to use FaME to implement advanced application functionality, such as implementing automated decision support within an operational system. These techniques will be vital to IT to guide the organization to avoid being disrupted, and to be competitive in the second machine age.
Current Enterprise Performance Architectures
Two Node Architecture
The two node high performance architecture is illustrated in Figure 2. The blue square represents processors, the plain yellow DRAM memory, and the stippled yellow PCIe flash. The second node is used as a failover node for the first, and the data is replicated in the second node using, for example, RAID 1. This architecture is used extensively in hyperscale computing, to run databases such as MySQL that need the low consistent latency. Fusion-io was an early supplier of PCIe flash cards for this architecture, before being acquired by SanDisk.
The two node architecture has been extended to include atomic write APIs within NVMe, which can half the IO required for database applications and double the throughput. These extensions are available on all the distributions of MySQL, including MarieDB, Oracle, Percona and Red Hat.
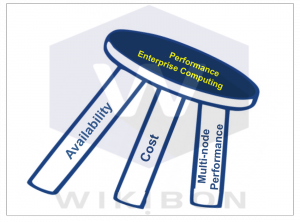 Figure 3 shows a three legged stool assessment of the two node architecture. The availability is good, with recovery and restart times being excellent. Single node performance is excellent, but resources such as the number of processors, the amount of DRAM and the amount of data are constrained. These constraints limit the use of two node architectures for enterprise performance applications. The cost is reasonable. One area where this architecture is used extensively is in financial modeling systems, where the operating systems and applications are often finely tuned to shave milliseconds of processing time.
Figure 3 shows a three legged stool assessment of the two node architecture. The availability is good, with recovery and restart times being excellent. Single node performance is excellent, but resources such as the number of processors, the amount of DRAM and the amount of data are constrained. These constraints limit the use of two node architectures for enterprise performance applications. The cost is reasonable. One area where this architecture is used extensively is in financial modeling systems, where the operating systems and applications are often finely tuned to shave milliseconds of processing time.
In summary, this architecture works well for small enterprise application systems. Wikibon looked at the business benefits of such a system for a small enterprise and found that the business return was very significant, improving overall productivity by 10%. However, this architecture does not scale to enterprise applications with larger amounts of data, so it needs scalable clustering to become relevant as a general purpose high performance enterprise architecture.
Distributed Node Architecture
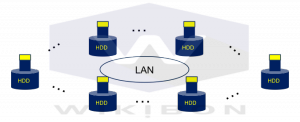 Figure 4 illustrates this scale-out distributed architecture. The data is spread across multiple nodes, and the application code is sent to the data partitions. The servers, storage and LAN network can be and usually are low cost commodity components.
Figure 4 illustrates this scale-out distributed architecture. The data is spread across multiple nodes, and the application code is sent to the data partitions. The servers, storage and LAN network can be and usually are low cost commodity components.
Within each node, there is good latency for persistent reads and writes. The lowest cost storage at a node is still magnetic disk, but flash drives (SSD) can be used as well. The node processor:storage ratio is usually fixed across the system.
This architecture is good for problems that decompose to run independently on each node, and is widely used as a platform for big data applications. The Hadoop software ecosystem provides good support for operating systems, systems management, middleware, databases (SQL, NoSQL & key value), and applications.
 The distributed node architecture often runs large-scale single applications, and is best suited for long-running jobs in batch mode. It is used extensively by Google and Yahoo. It is very difficult to run real-time transactional or real-time decision support applications. In practice, most problems cannot be completely parallelized and are constrained for a significant proportion of time by the performance of a single node. System performance being ultimately constrained by the speed of a single processor was first described by Gene Amdahl, and is known as “Amdahl’s law”.
The distributed node architecture often runs large-scale single applications, and is best suited for long-running jobs in batch mode. It is used extensively by Google and Yahoo. It is very difficult to run real-time transactional or real-time decision support applications. In practice, most problems cannot be completely parallelized and are constrained for a significant proportion of time by the performance of a single node. System performance being ultimately constrained by the speed of a single processor was first described by Gene Amdahl, and is known as “Amdahl’s law”.
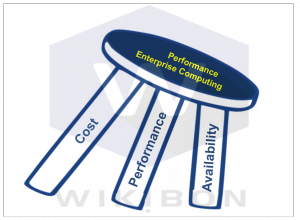
Figure 5 summarizes a three legged stool assessment of the distributed node architecture. The distributed node architecture is a low-cost solution for some large-scale batch problems, but is not relevant as a general performance enterprise architecture. The network is the key bottleneck for performance and availability.
Data-in-Memory Architecture
Data-in-memory architecture has developed strongly in the last few years. The master copy of the data is held in DRAM memory across multiple processor nodes. DRAM is non-persistent memory. Sometimes the DRAM is protected by capacitance or batteries, and usually by additional copies spread across different servers. Figure 8 illustrates the architecture. A high-speed message passing interface (MPI) network connects the clustered servers. The data for loading into the DRAM is held on traditional disk storage, either magnetic or solid-state. The load time and restore times for the data in memory are significant.
The data is distributed across the DRAM in multiple server nodes. The message passing between the nodes usually uses the MPI protocol, the interface used by the application programmer. This gives low latency for reads and writes within a node, but much longer between nodes. The larger the number of nodes, the greater the internode communication and latency impact. The increase in overhead is non-linear so specialized high performance servers with very large DRAM are usually used to minimize the number of nodes and the internode communication overhead.
In general, data-in-memory supports applications with small data sets. It has been successfully used in data analytic applications, where a relatively small cube of data is ETLed and loaded into DRAM. There are a number of data-in-memory databases such as SAP HANA which utilize this approach.
Source: © Wikibon 2015
As is shown in Figure 9, availability is the achilles heel of data-in-memory systems. Since DRAM is non-persistent, ways have to be found to recover and reload the data if there is a power failure to the servers. Writing out data to persistent storage can slow down the application. Reloading large datasets into memory can take hours or even days to achieve. The data-in-memory architecture provides very good performance over a small number of nodes, can tackle applications with small datasets, and is tolerant of longer recovery times.
As will be discussed in the next section, FaME architectures can be used to run data-in-memory databases, and help reduce load and recovery times very significantly.
All-flash Array Architecture

Source: © Wikibon 2015. The yellow blocks are DRAM, the blue block are processors and the blue disk drives are solid state drives (SSD).
This architecture is illustrated in Figure 6. It
supports very large data sets, with the master copy held in the array. The all-flash array gives predictable latency for reads and writes, in the range of about 1 ms end-to-end, including protocol and switching overheads. The all-flash array can have excellent storage services.
There is good support for clustered servers from multiple ecosystems (e.g., Linux, Microsoft Windows, Oracle, etc.). Servers can be different, and all servers can access all persistent data with equal performance. Data can be “shared” between applications with space efficient snapshots. Data costs can be reduced with data reduction techniques such as de-duplication and compression, although at some cost to latency.
 This traditional architecture is optimal for persistent storage on magnetic disks, since the protocol and switching overheads are dwarfed by the disk drive latencies. The upgrade to flash drives reduces the latency and latency variance significantly. The flash is so fast that the network and protocols are now the major inhibitor of performance, both for latency and latency variance (or jitter). As the two-node solution earlier shows, the utilization of the compute nodes can be improved by a factor of at least two times if this latency is reduced. The only way to achieve that performance is to place persistent storage much closer to the processors.
This traditional architecture is optimal for persistent storage on magnetic disks, since the protocol and switching overheads are dwarfed by the disk drive latencies. The upgrade to flash drives reduces the latency and latency variance significantly. The flash is so fast that the network and protocols are now the major inhibitor of performance, both for latency and latency variance (or jitter). As the two-node solution earlier shows, the utilization of the compute nodes can be improved by a factor of at least two times if this latency is reduced. The only way to achieve that performance is to place persistent storage much closer to the processors.
Figure 7 shows a three legged stool assessment of the all-flash array architecture. The architecture is highly available, with a mature ecosystem. They key performance bottleneck is the network.
Wikibon has constantly pointed out that magnetic drives have been a constraint on enterprise performance computing. In research titled “The Potential Value of Low-latency Flash“, Wikibon shows that the all-flash array is significantly lower cost that either magnetic disk only or magnetic disks with 20% flash. The future of storage in enterprise performance computing is flash and only flash.
The comfortable latency that can be achieved with the all-flash array is between 1 and 1.5 milliseconds. This is much faster than the 5 to 7.5 millisecond response time you can get from highly tuned traditional arrays with flash tiers.
When you try to try to reduce the latency further in traditional networked all-flash arrays, the major stumbling blocks are the network and switch overheads. The minimum sustainable latency for networked all-flash arrays is about 500 microseconds, and the latency variance starts to climb. The FaME architecture discussed in detail in the next section will show how putting the flash closer to the servers and using bus switches and protocols can bring the IO access time down by a factor of up to 1,000 times, and bring the system into balance.
Flash as Extension of Memory Architectures (FaME)
 By bringing the flash physically close to the processors, using processor bus latency, using bus switches, and using bus protocols, the latency can be taken down much much further, from milliseconds through microseconds to the high nanoseconds.
By bringing the flash physically close to the processors, using processor bus latency, using bus switches, and using bus protocols, the latency can be taken down much much further, from milliseconds through microseconds to the high nanoseconds.
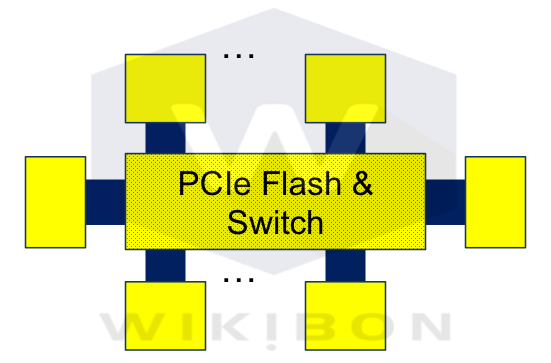
Figure 10 shows the flash as memory extension (FaME) architecture. At the center of the system are the PCIe flash cards and the switching mechanism. The logical switch for PCIe flash is a PCIe switch, but other solutions could be viable (flash memory bus “DIMMs” with memory bus switching may be another alternative). The dotted lines show that there could be many more than 6 processors. The switch will determine the number of processors within the system, with 20-40 processors being an initial range supported by available technologies. If the system is designed to maximize performance, the processors would be as fast as possible with fewer cores, and the DRAM size as large as possible. Smaller lower cost configurations are also possible. The nodes do not need to be identical, but too great a difference in relative speed would make it difficult for the lower speed processors to access data (true for all clusters).
All the servers can access all the data, and the latency is very low (PCIe speed) and consistent. The architecture supports large datasets on specialized flash modules with controllers built for this architecture. The PCIe architecture supports up to 32 point-to-point lanes, which together with the parallel switching can theoretically deliver bandwidths of up to 1 terabyte/minute for loading or de-staging data to DRAM.
The FaME architecture allows easy migration of applications to this platform, especially database applications. For example, the ability to coalesce many smaller volumes required for traditional storage management into a single volume makes storage management much easier. Flash storage services, in particular space efficient snapshots, will enable data sharing between applications or versions of data, and reduce flash costs. A FaME snapshot capability would also enable backup and recovery mechanisms to work optimally for ultra-fast flash storage, and provide low RPO capabilities.
The FaME architecture is balanced, and will allow multi-programming. Applications written for other architectures will be able to run on FaME, and take advantage of the ultra fast storage. For example:
- Applications written and deployed on a two-node architecture will be able to run on FaME with similar performance, and can be extended to run with multiple nodes.
- Hadoop applications can take advantage of much faster shared storage and flexible scheduling to significantly reduce elapsed time for completion, and minimize tear-down and data-loading times for new jobs.
- IO constrained applications running on an all-flash storage array will complete faster on FaME with lower processor time (reduced CPU wait time).
- Data-in-memory applications can load, reload, recover or restart many times faster that traditional configurations, because parallel loading and unloading of data can be done 100s of times faster.
The FaME architecture will also allow coexistence of operational transactional systems and real-time analytics, and enable automated decision making based on analytics within the operational systems. The architecture is potentially extensible to atomic write APIs within NVMe, which can half the IO required for database applications and double the throughput.
Initially, the flash and flash switching components will be more expensive than all-flash array storage. However, the positive impact on processors performance will make the total solution very competitive. This will bring performance, availability and cost into balance, as shown in Figure 1 in the introduction. Wikibon believes that volume of these switches will grow very strongly, and the cost of the FaME architecture will drop accordingly. Wikibon expects that over time solutions with slower processors, slower switches and slower flash with greater data reduction and data sharing will emerge as lower entry points for FaME solutions. The Wikibon research titled “The Rise of Server SAN” forecasts the impact the FaME architecture will have over the next decade.
Conclusions
The FaME architecture has the potential to give a 2X or greater boost to the throughput and elapsed times of enterprise performance systems. The flexibility of the architecture, the use of traditional x86 servers, and the ability to utilize system resources much better than traditional clustering solutions means that FaME will have the lowest costs of management. Wikibon expects that a majority of FaME systems will be delivered as converged systems, and will use a Server SAN model for software services.
The most important benefit of the FaME architecture is the ease with which advanced applications can access and process 1,000s of times more data in business real time. Wikibon expects that this architecture will be the reference model for enterprise ISVs, as they expand the role of integrated processing, big data and cognitive systems in what MIT’s Erik Brynjolfsson and Andrew McAfee are calling “The Second Machine Age”.
Action item:
Wikibon believes that CIOs should ensure that FaME architected systems are installed early, and should be asking their brightest and most creative staff to use FaME to implement advanced application functionality, such as implementing automated decision support within an operation system. These techniques will be vital to IT to guide the organization to avoid being disrupted, and to be competitive in the second machine age.
Footnotes:
Note ¹ Persistent Storage
Persistent storage is storage that is not affected by loss of power. Magnetic storage drives, first tape and then disk, have been the persistent storage option for over 50 years. Storage array processors starting in the 1990s were able to mask the magnetic disk storage performance and bandwidth limitations with many innovations, but have run out of capability in high performance storage. Flash storage is persistent, and has replaced disk for high performance disk, and will start to replace disk for most capacity storage from 2016 onwards. In addition, flash storage is radically changing the design of systems, databases and applications.
Note ² References
Wikibon Posting on Revere Electric: Case Study: The Hunting of the RARC
Wikibon Posting on: The Potential Value of Low-latency Flash
Wikibon Posting on Server SAN: The Rise of Server SAN
Wikibon Posting on All-flash Arrays: The Evolution of All-Flash Arrays
Flash and Hyperscale Changing Database and System Architecture Forever
theCUBE Keynote Presentation by Andrew McAfee at MIT IDE Keynote in London April 2015
theCUBE Interview with Erik Brynjolfsson & Andrew McAfee at MIT IDE in London April 2015


