
ERP and other, traditional enterprise applications record-keeping systems comprised of historical data. But ERP and newer, predictive machine learning apps can exist symbiotically, extending the useful lifespan of ERP apps and simplifying the implementation and operation of machine learning apps.
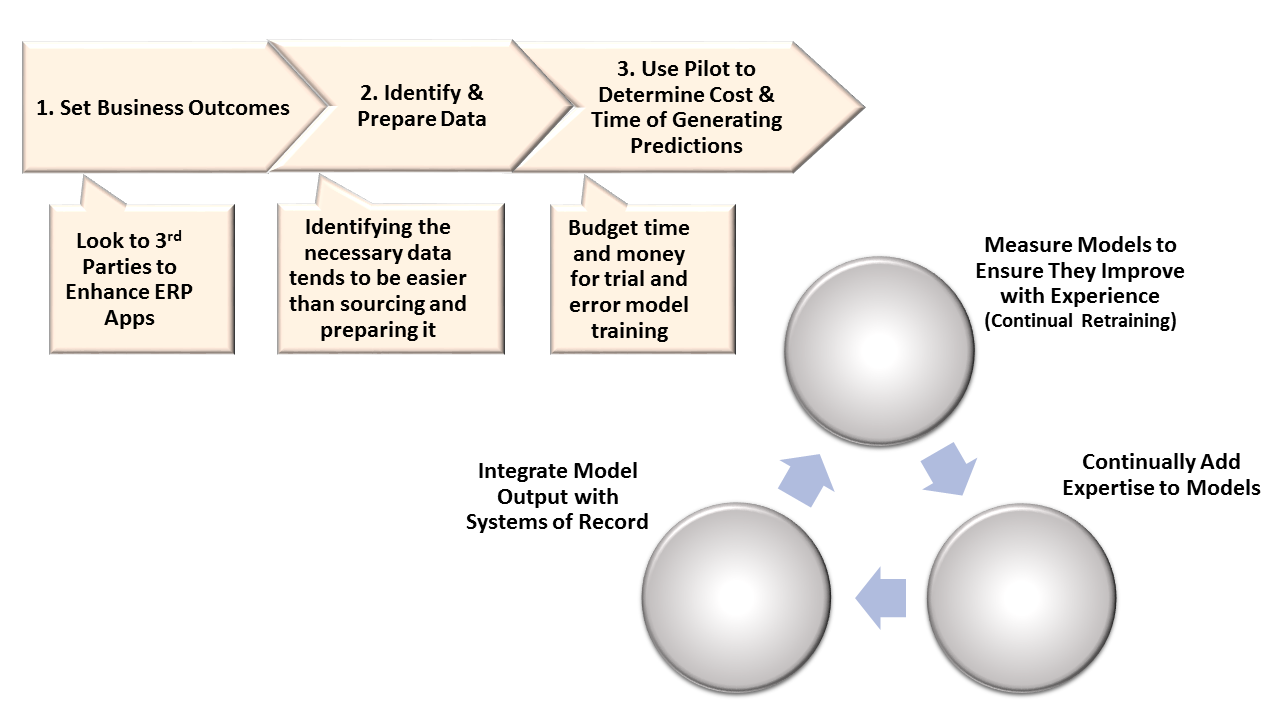
ERP vendors are not expeditiously adding machine learning capabilities to their packages. However, users can apply Wikibon’s recipe for machine learning applications to ERP environments to generate significant business returns from machine learning apps (see Figure 1). For example, a retail customer of machine learning vendor Blue Yonder, following the basic steps of the recipe, was able to reduce stock-outs by 80% and improve gross margins up to 10% by:
- Looking to 3rd-party ISV’s to enhance ERP apps. Machine learning apps can generate significant returns, but it all starts with properly choosing the desired business outcomes based on strategic trade-offs such as growth vs. profitability. The fastest way to add this capability is to buy from an ISV like Blue Yonder rather than waiting for traditional vendors to add pervasive machine learning functionality.
- Identifying the necessary data tends to be easier than sourcing and preparing it. One of the advantages of buying a machine learning application (instead of building) is that the application makes clear exactly what data it needs, such as all the internal and external factors driving customer demand at different prices for each grocery item (See Figure 4). Making sure that data is consumable by Blue Yonder is part of the pilot process.
- Budgeting time and money for trial and error model training. Training the model the first time requires some understanding of what drives its prescriptions. Grocers also have to decide how much time and effort they can spend collecting historical data. More history equals better predictions of price elasticity. They also have to budget substantial time and money for working on the initial model training.
Look to 3rd-Party ISV’s To Enhance ERP apps.
Blue Yonder has built a specialized application that leverages data in ERP and other systems of record to prescribe pricing and replenishment plans for grocers based on machine learning. Forty percent of grocers’ revenue comes from perishable products. Availability of these items, especially “long-tail” items, is critical to attracting shoppers. At the same time, overstocking and markdowns can easily erase already thin margins.
The first step in the recipe is to choose desired outcomes. Most businesses — and almost all ERP app teams — have limited experience with machine learning. Therefore, they have limited experience scoping the characteristics of the outcomes and translating those characteristics into machine learning application attributes. The example grocer’s senior management team worked closely with Blue Yonder’s sales and support specialists to scope strategic options. They evaluated a spectrum of trade-offs, such as minimizing stock-outs that drive away customers versus minimizing write-offs from perishable items that diminish margins. At a higher level, these choices translate into balancing sales growth vs. profitability vs. working capital requirements to support inventory.
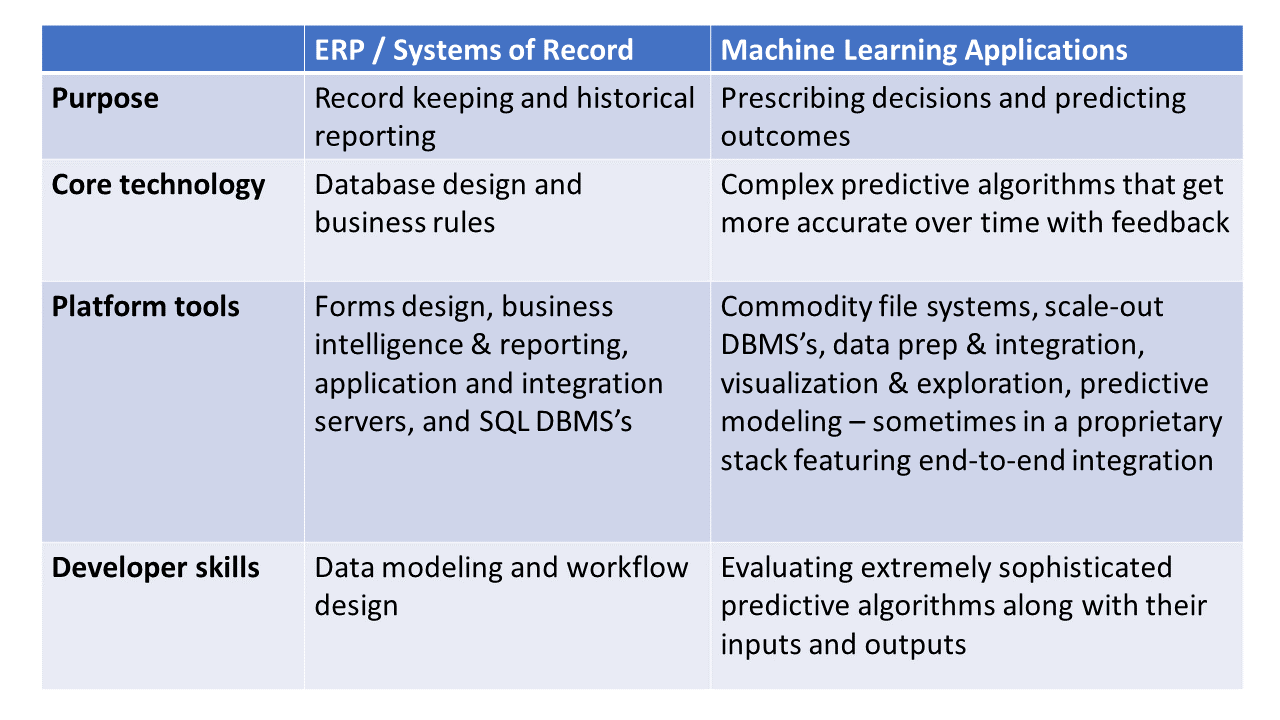
Why have ERP vendors have been slow to exploit machine learning? Partly because under the covers, machine learning and ERP applications utilize entirely different technology (See Figure 1). Blue Yonder embeds and hides a lot of data science “magic” In its application for grocers. Blue Yonder has several dozen PhD’s in R&D who developed a machine learning algorithm optimized for grocers. The model employs roughly 50 variables to make pricing and replenishment prescriptions within the machine learning application. To keep the application from buckling under complexity, this single algorithm models all types of groceries, including produce, deli, and dry goods. The algorithm also works to isolate the difference between correlation vs. causation factors. The expertise required to design these machine learning algorithms is so scarce that it makes sense for most grocers to buy a package such as Blue Yonder rather than try to build their own application.
Identifying the necessary data tends to be easier than sourcing and preparing it.
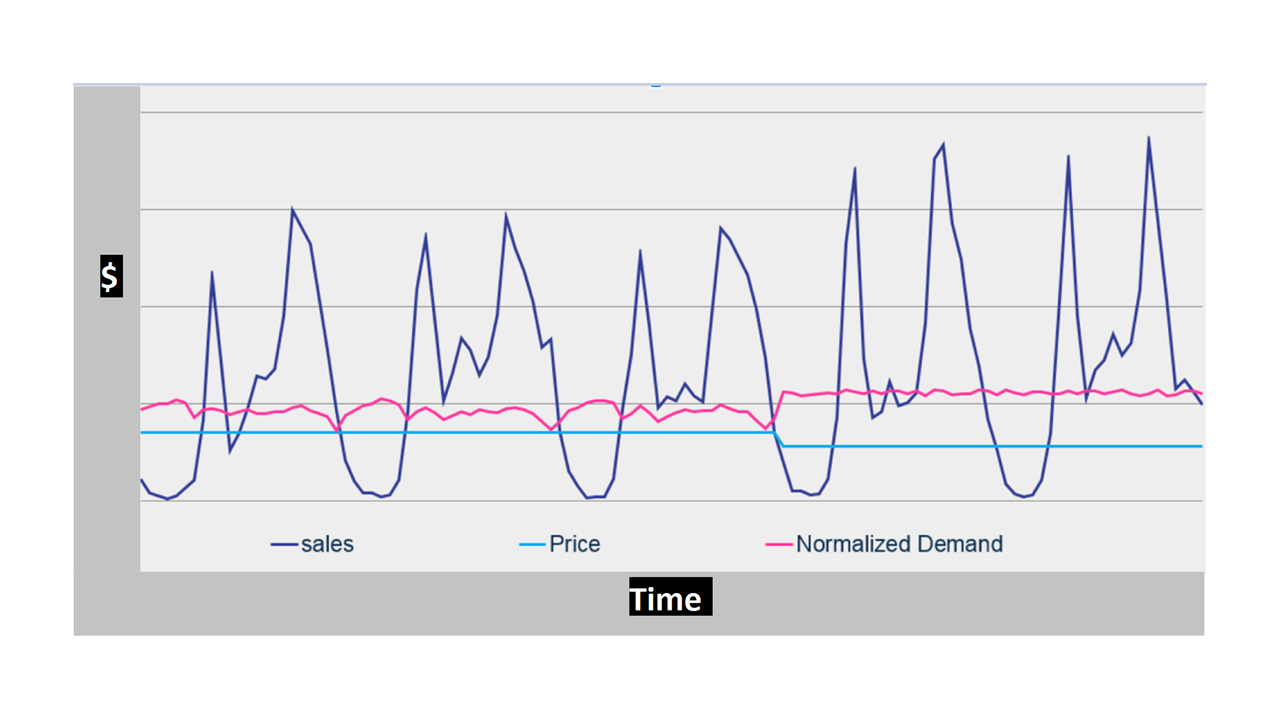
Packaged machine learning applications greatly simplify the process of identifying the data required to make predictions of business outcomes. With custom applications, developers, data engineers, and data scientists have to build most of the machine learning pipeline just to verify that they have the right data and enough of it to validate the model and its predictions. With Blue Yonder, grocery stores out of the box get the ability to create a prediction of how much of each item (at the SKU level) will sell at each store for each day over a forecast horizon that can stretch to 21 days (See Figure 2).
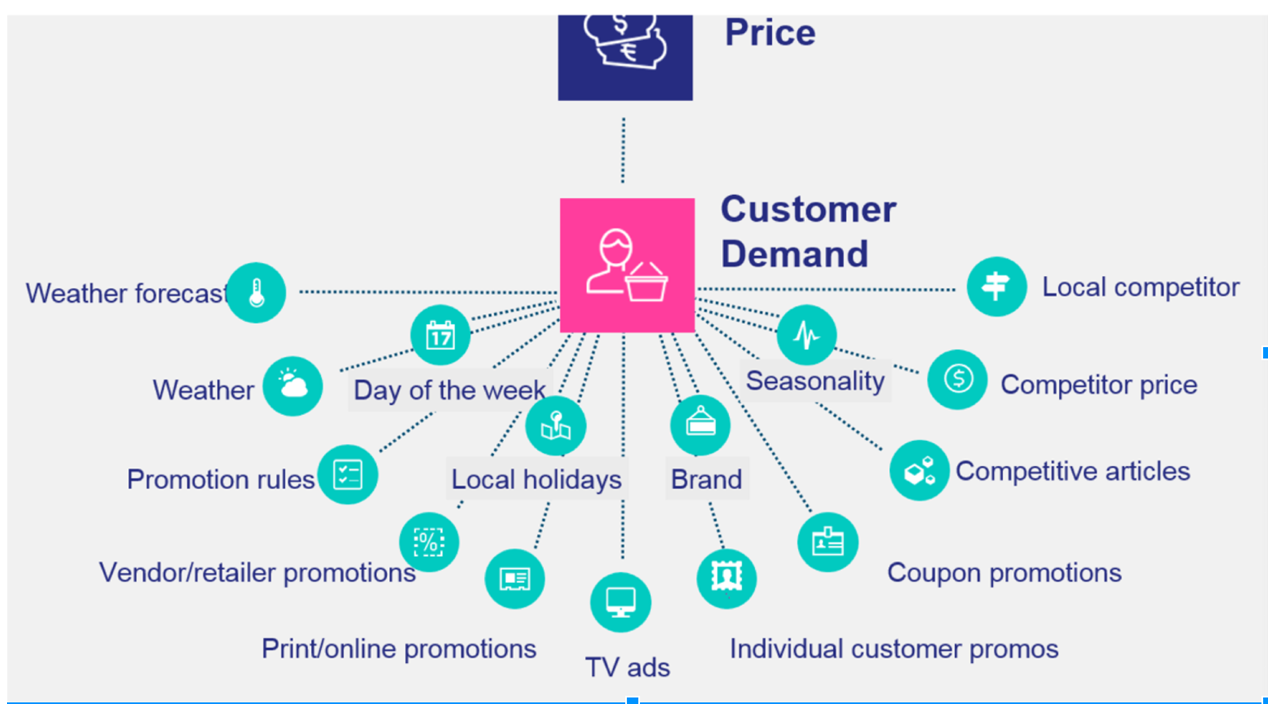
The factors driving these predictions largely come from ERP and other systems of record, including retail specific data such as pricing, promotion, and stock levels; master data such as product families and pricing; supplier-related data such as minimum order quantities, lead time for delivery; and other external contextual data such as seasonality, weather, and similarity to other products (See Figure 3). Blue Yonder, like other machine learning applications that delivers precise predictions needs clean data. And as with any project to integrate multiple applications, the pilot process will likely consume a lot of time uncovering inconsistencies in data sourced from different applications and then scrubbing the data. Typically, customers will need some sort of UI in order to simplify the process of importing the data in order to get interactive feedback about errors.
Budget time and money for trial and error model training.
When fully operational, the machine learning application returns an output file ready for one step importing into an ERP application. The output file from Blue Yonder indicates to the ERP system how much of each product to buy and stock for each store every day.
Budgeting the time and expense of the training process is inexact but there are some rules of thumb. Training is far more compute intensive than prediction. A $10bn grocer with 500 stores, 20,000 products, and a 21 day forecast horizon requires 200M predictions within each nightly 6 hour batch window (500 x 20,000 x 21). On AWS, that means just the nightly batch prediction run costs $20K in addition to basic compute charges (200M predictions x $0.10 per 1,000 predictions). Model training runs typically involve much larger data sets because they have to take history into account, as much as three years with Blue Yonder. What’s more, training runs are far more compute intensive than prediction runs because of the need to continuously iterate on the model until the optimal mix of driving factors are found. Blue Yonder helps simplify this trial and error process. Machine learning models are typically notorious for being black boxes in terms of understanding how they get to their predictions. Blue Yonder’s algorithm “explains” how much each of as many as 50 variables contributed to each prediction. Customers can leverage this transparency by reducing the required number of trial runs. Understanding what’s driving predictions also has great value in the change management process of getting operations staff to accept the application’s recommendations.
Action Item
Data science is a scarce resource, not only among mainstream enterprises but within traditional application vendors as well. But customers don’t have to wait for traditional vendors to extend their applications with the new technology. Nor do customers have to take on the risk of custom development. Customers should look for a growing number of packaged industry- and function-specific machine learning applications to enhance their traditional applications with functionality that delivers much more strategic business outcomes.


