
Premise
Even the most sophisticated customers are grappling with Hadoop’s operational complexity because of the number of moving pieces (see figure 1). Prospective customers as well as those who are still in proof-of-concept or pilot need to understand that there are no easy solutions.
Hadoop’s unprecedented pace of innovation comes precisely because it is an ecosystem, not a single product. Total cost of ownership (TCO) and manageability have to change in order for “big data” production applications to go mainstream. And if the Hadoop ecosystem doesn’t fix the problem, there are alternatives competing for attention.
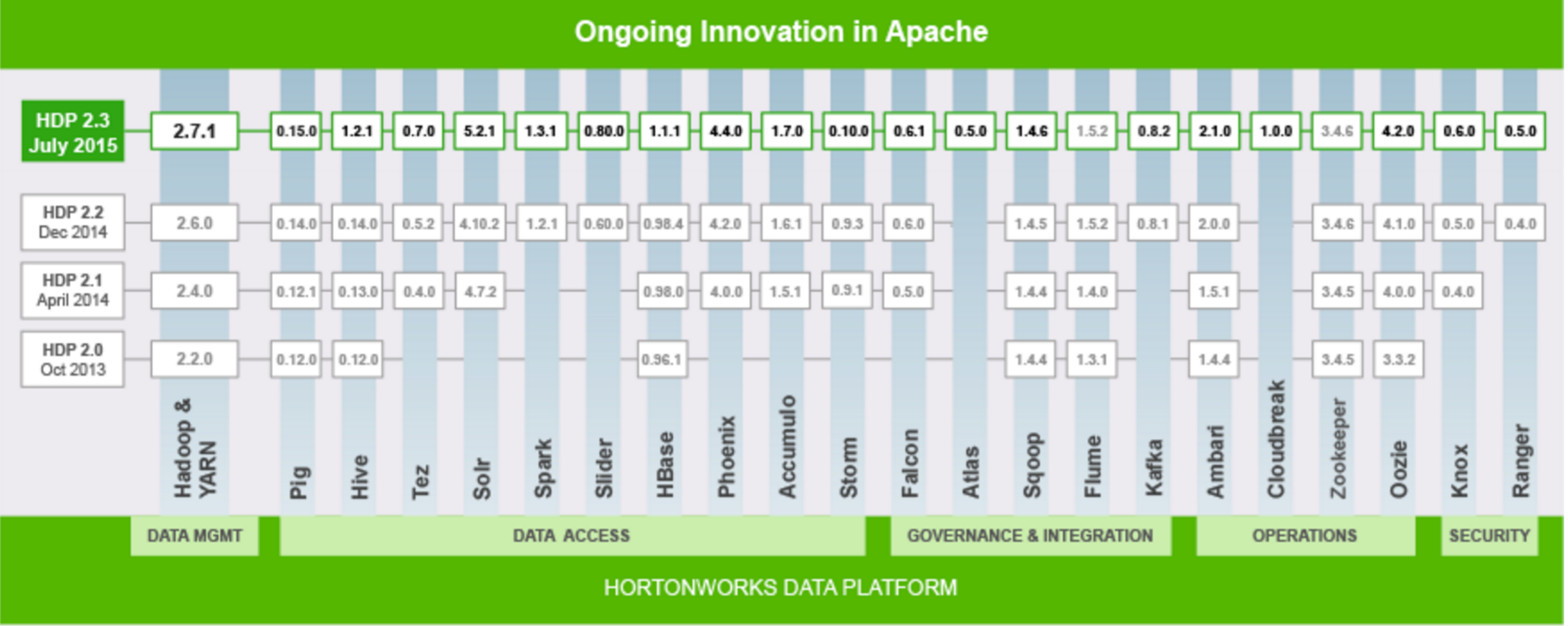
Source: Hortonworks, Wikibon 2015
Right now the customers with the skills to run Hadoop on-premises are Internet-centric companies and traditional leading-edge enterprise IT customers such as banks, telco’s, and large retailers. Solving the TCO and manageability problem won’t be easy. This research note outlines the trade-offs of several key alternatives:
- running Hadoop-as-a-service,
- using Spark as the computing core of Hadoop, or
- building on the native services of the major cloud vendors such as AWS (Kinesis Firehose, DynamoDB, Redshift, etc.), Azure, or Google Cloud Platform while integrating specialized 3rd party services such as Redis.
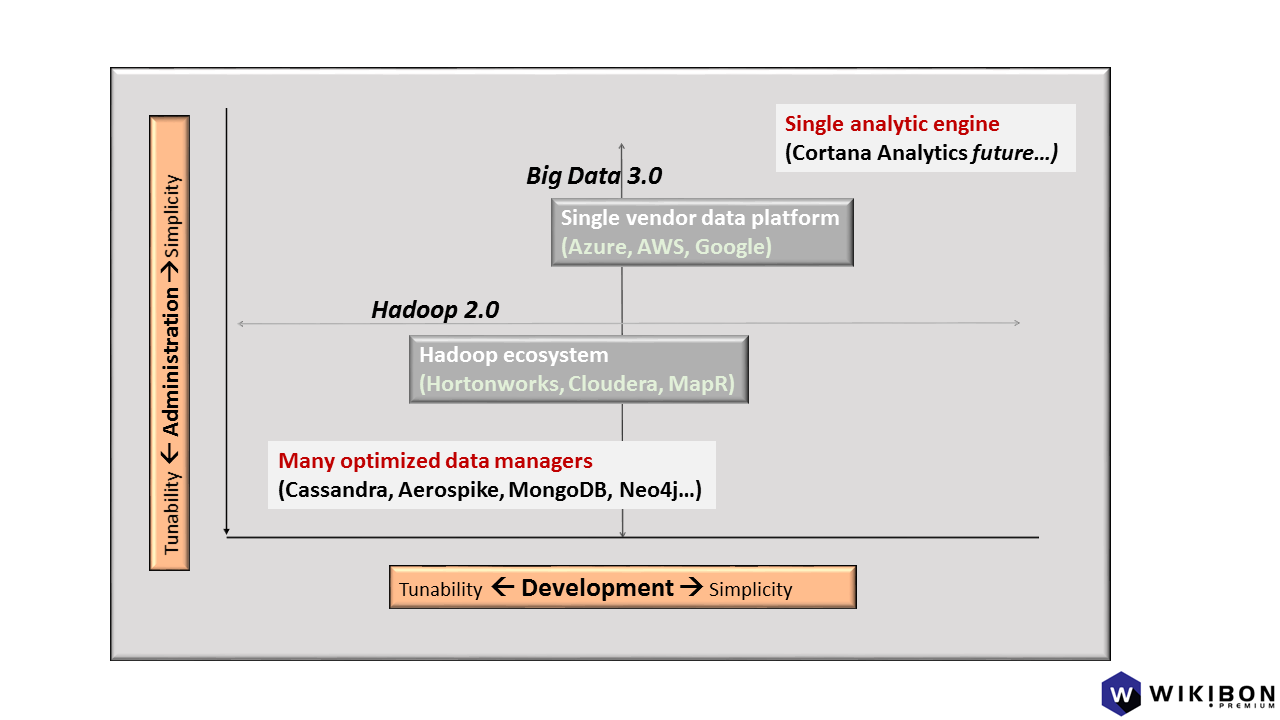
Source: Wikibon 2015
Manageability needs a definition in order to show how easily TCO can grow out of control.
Timothy Chou, the former head of Oracle Online, has published several books on managing cloud applications. The management categories are the same whether delivering a service or running an application on-premises even if the techniques and technologies are different: change management, availability, performance, and security.
- Change management: Getting the entire hardware and software stack to work correctly and not touching it helps ensure error-free availability. But managing change is necessary because anything related to security, performance, or availability requires some sort of change.
- Availability: Applications have to be able to withstand failure, including from changes and reconfigurations.
- Performance: Admins need to be able to measure and analyze how well an application is working and make changes to tune or fix problems.
- Security: Admins have to be able to identify users and control who can access what resources.
Today, management is fractured. Just about every service has its own management tool or console to help customers operate things. It’s only a slight exaggeration to show Chou’s management categories in a table with all the layers in the application and infrastructure stack. Just monitoring performance for a range of applications shows how many different consoles are involved in this one cell in the table.
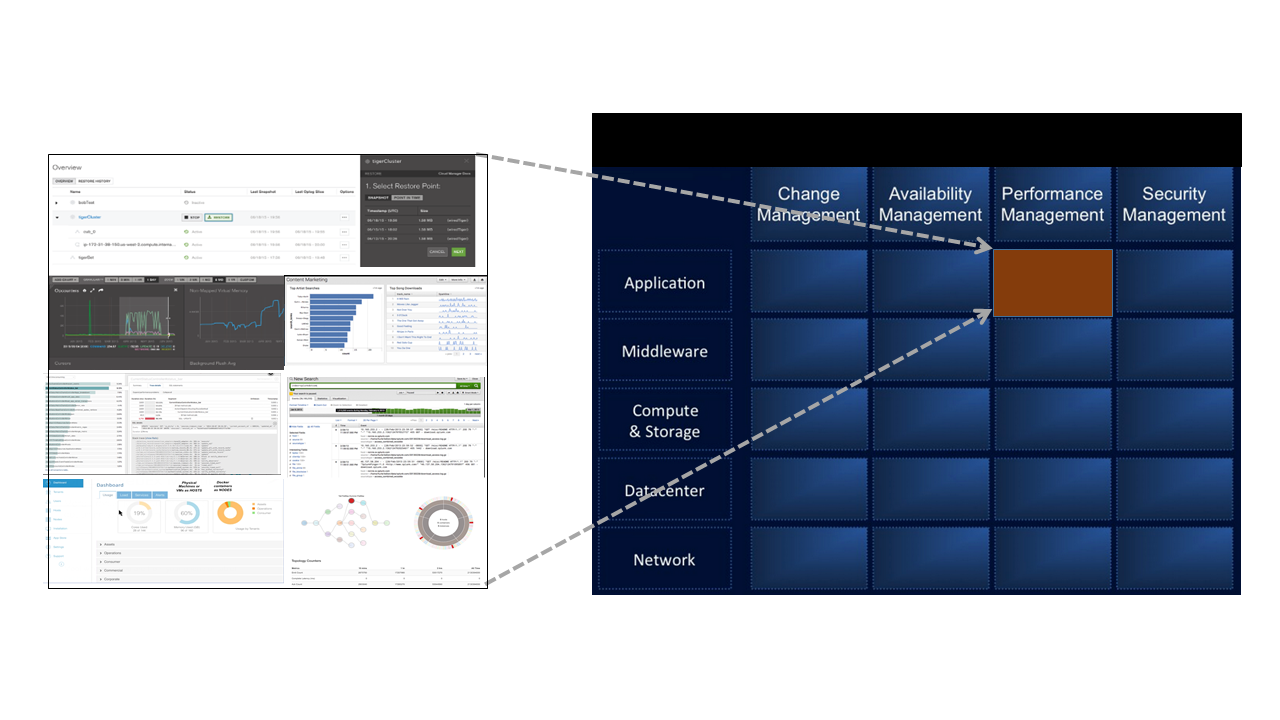
Source: Wikibon 2015
In a perfect world, a single suite of devops tools would build and manage the big data applications and their infrastructure. Once upon a time, telco’s actually lived in a world like this and their Network Operations Centers looked like this.
Running Hadoop as a managed service simplifies some, but not all, of the management problems.
Attitudes about running Hadoop in the cloud are evolving more rapidly than running client-server applications, which are far more deeply rooted in on-premises infrastructure and operations. Wikibon has heard from many parts of the big data ecosystem that it has typically taken two years to get from proof-of-concept to production of at least one application.
Part of the problem is that Hadoop is so unlike the client-server applications that have dominated IT for decades. The problem is deeper than just scale-out versus scale-up architectures.
Virtualizing servers don’t solve the problem. Traditionally, they have sliced up existing client-server clusters that have thinner blade servers connected to SANs with network traffic that travels primarily between clients and servers. Stealing spare cycles from servers on isolated clusters still leaves virtual servers in isolated clusters, not a big elastic pool of infrastructure. Elastic pools tend to have fat servers on one network with JBOD storage and network traffic that moves primarily between servers.
AWS’s Elastic MapReduce (EMR) delivers Hadoop as a managed service but it is apparently somewhat hampered by AWS’s traditional separation of compute and storage resources. While that helped keep costs low, it has tended to make EMR jobs tougher to manage. They are slower to start and trickier to work with when trying to run workloads that are a mix of interactive and batch processing.
Hadoop-as-a-service vendor Altiscale, one of the most prominent Hadoop-as-a-service vendors, purpose-built their hardware and software infrastructure with trade-offs optimized for Hadoop workloads. They know how their stack interoperates all the way down to the metal. That makes it possible for them to tune all the hundreds of “knobs” that would otherwise make operating Hadoop so labor intensive. Of course, customers have to get their data to the data centers that host Altiscale and they don’t have the rich ecosystem of complementary tools on AWS.
Spark, whether managed by Hadoop or standing on its own, carries management complexity even while it greatly simplifies application development.
It’s easy to assume that by developing on Spark customers can get away from the 20+ products that comprise a Hadoop distribution.
- But Spark doesn’t manage data. It needs a database or a file system. So customers often choose Cassandra for that role.
- It also needs a way to ingest data. Kafka is quickly becoming the de facto standard for all big data applications.
- Then some service has to make sure a majority of the other services are live and talking to each other. That means Zookeeper has to keep tabs on everything.
- And there’s still no management console.
So getting up and running with a Spark cluster takes no less than 12 servers: 3 for each of the services. Again, even though Spark is a single, unified processing engine, it requires at least four different services. And that’s where the management complexity comes back into play. Each service has its own way of failing; its own way of managing access; its own attack surface; and its own admin model.
Native cloud services on AWS, Azure, and Google Cloud Platform can dramatically simplify management, but at the cost of choice, open source portability
AWS has its own homegrown, increasingly integrated set of big data services. There’s Kenisis Firehose for dealing with high velocity streaming data, DynamoDB for operational processing, Redshift SQL MPP, a machine learning service, and the Data Pipeline to orchestrate everything.
All the cloud providers will provide ever more powerful devops tools to simplify development and operations of applications on their platforms. But as soon as customers want the ability to plug in specialized 3rd party functionality, that tooling will likely break down. The overhead of opening up these future tools is far more difficult than building them knowing in advance just what services they’ll be managing.
Wikibon interviewed Google’s Melody Meckfessel, senior director of development tools on just these challenges at Facebook’s @Scale conference earlier this fall. Listening to her, it’s clear there’s a lot of work to be done to accommodate a multi-vendor future.
Action Item
Customers building their outward facing Web and mobile applications on public clouds while trying to build Hadoop applications on-premises should evaluate vendors offering it as-a-service. Hadoop already comes with significant administrative complexity by virtue of its multi-product design. On top of that, operating elastic applications couldn’t be more different from the client-server systems IT has operated for decades.


