
Premise
The technology industry has marched to the cadence of Moore’s Law since the mid 1980’s. It has been the fundamental driver of innovation in the tech business for decades. A question often posed in the Wikibon community is: “After fifty years of IT innovation, is it over?” Two data points people often cite regarding this key question include: 1) “Moore’s law seems to be running our of steam”; and 2) “IT budgets appear to be in perpetual decline.”
The premise of this research is that IT innovation is strong and getting stronger, but not due to microprocessor performance in and of itself. Rather the combinatorial effects of emerging technologies is re-shaping the exponential innovation curve. At the heart of these innovations is data. Specifically, technology disruptions are leading to a vast increase in the data available to applications in real or near-real time. We believe this will lead to the creation of “Systems of Intelligence,” (SoI), a major new category of application, which represents a highly disruptive force that will dramatically lower enterprise costs and increase value to stakeholders.
An implication of this premise is that systems infrastructure must evolve to support this new wave of application innovation and traditional so-called “commodity hardware” (AKA Intel x86 systems), in their current form, won’t be able to adequately support this new wave.
Introduction
The major disruptions discussed in this research and throughout the technology industry, include Mobile, Cloud, Social Media, Flash, Open Source, Convergence, Hyper-convergence, Moore’s Law, Big Data, Mega-datacenters, Micro and Nano Sensors, and the Internet of Things (IoT). These disruptions in turn lead and in fact feed what we believe will culminate in Systems of Intelligence, explained in detail within this research note.
Mobile
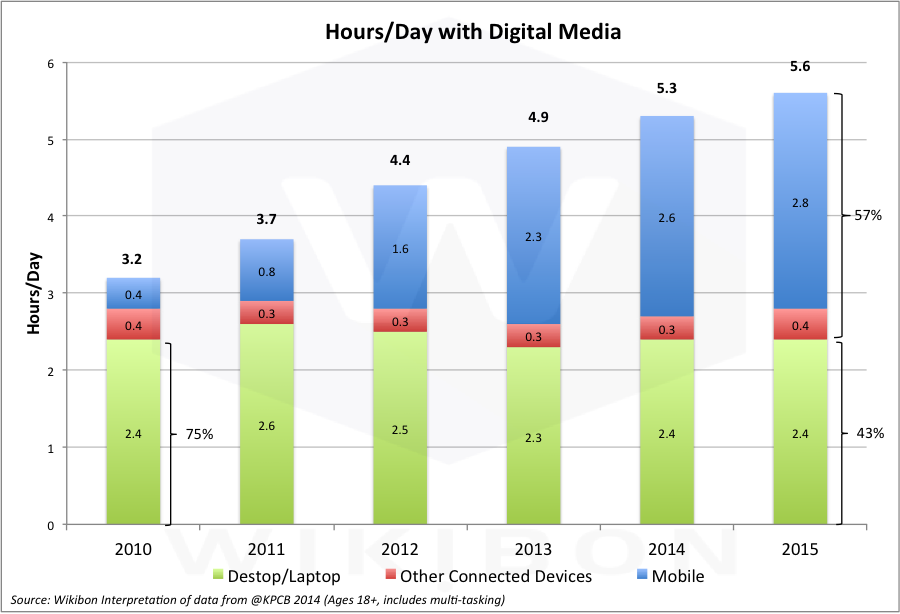
Source: Wikibon Analysis in 2015 of Data from @KPCB
Figure 1 shows the extent to which mobile is dominating access to data. Several key points are relevant, including:
- The hours/day used for PCs has declined from 75% in 2010 to 43% in the first half of 2015.
- Mobile computing allows users access to data and people anytime and anywhere and changes the fundamental flow of data.
- Google has begin penalizing web sites and pages not built to be mobile friendly.
- The web form factor is changing from landscape to portrait, and new navigation standards for mobile have already been set.
Moreover, the implications for microprocessor designs are significant. Namely:
- Mobile technology almost exclusively uses ARM processor chips, originally designed to conserve power.
- ARM chips are less than 20% the cost of traditional Intel microprocessors, and the speed of the latest iPhones and Android smartphones is almost the same as the PC-based Intel chips.
- The ratio of ARM chips to Intel chips sold is 10:1, and the spread is increasing in favor of ARM. Desktop PCs still have the edge on multi-programming and top-of-the-line gaming. However, the number of PC applications available is less than 10% of those offered on iOS and Android phones.
- Notably, desktop applications cost on average 10X more than smartphone apps. Even the mainstay of PCs, Microsoft Office, now runs quite well on iOS and Android. The Intel/Microsoft stranglehold on personal computing is fading fast into history.
- As the CEO of Microsoft, Satya Nadella, has declared, the future IT world is Mobile First, Cloud First.
Managing the Data Tsunami: Mobile – Bottom Line:
Mobile & Cloud First will be the design endpoint for both IT management and personal information. Mobile will mandate cloud access (discussed below) and new data management architectures. The technologies in consumer mobile will define the technologies used in enterprise devices and computing.
The Internet of Things
The ARM processor ecosystem also dominates the sensor marketplace which has major implications for the Internet of Things (IoT). Kurt Peterson is the father of MEMS (Micro-Electromechanical Systems), which allowed the miniaturization of different types of sensors. All mobile devices have a plethora of these tiny sensors, measuring everything from the amount of light (for cameras), distance, position, acceleration, pressure, temperature and many more. These sensors send huge amounts of data from mobile devices to the Internet, indicating the location of people and sending signals about what they are doing. Wearables such as Fitbit and the Apple watch show how small the sensors have become. The sensors will become even smaller and cheaper with the advent of nanosensor technologies.
Source: © Wikibon 2013
These sensor technologies will feed future IoT devices sitting everywhere, from security cameras to fridges to frigates to windmills to sensors injected into our bloodstreams. Gigantic amounts of data will accrue from these sensors. A key take-away is that sensor technology will be derived almost exclusively from consumer technology.
The design of IoT systems will be a combination of edge computing and cloud computing. The amount of raw sensor data is far too great to be transmitted directly to clouds. Mobile IoT devices (e.g., planes) have constraints in bandwidth. Many static IoT locations (e.g., wind-turbines, oil-rigs) have severe geographic connection challenges. As a results, the will be significant edge converged appliances running software such as time-series databases to reduce the data transmitted, and allow applications to run locally against the data. This in turn will allow high-value selective datastreams from sensors groups and other events to be transmitted to the cloud, and create a major opportunity for real-time analysis. The data volumes from IoT will be far far greater than mobile.
Managing the Data Tsunami: IoT – Bottom Line:
Specifically, the amount of data created from IoT and the drive to real-time or in-time analytics will explode. As customers combine transaction and analytical systems, infrastructure performance requirements will escalate dramatically. The market is seeing use cases beyond early ad-serving adopters into logistics, supply chain, medical, retail, consumer and other examples.
New system requirements will include multi-threading technology, in-memory database designs where high-speed analytics will need the fastest engine possible. This means customers will enable customers to deliver more value while deploying fewer resources.
From Public Cloud to Hybrid Cloud
The movement from PCs to mobile has also driven many early cloud investments. The mobility of these devices means that applications, application updates, the internet, email, messages, backup data, search data in the cloud and other services need to be accessed any place, any time – the cloud accessed though mobile data or WiFi is an essential component of mobile computing. In many emerging counties the familiar PC and landline era has been bypassed completely by mobile and cloud.
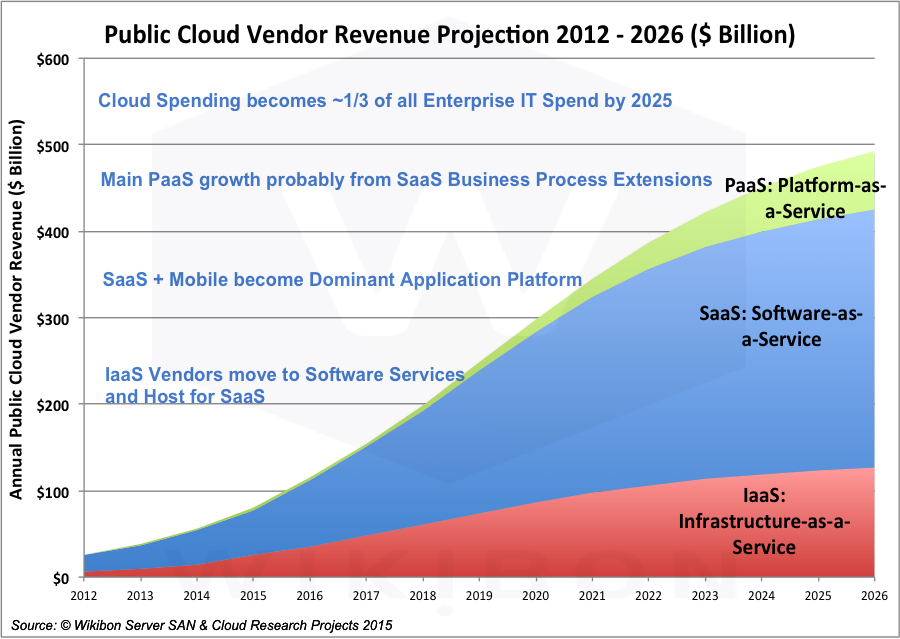
Source: © Wikibon 2015
There are three main types of cloud computing shown in Figure 3:
- Software-as-a-Service Clouds (SaaS), driven by advertising or on a usage basis.
- Intrastructure-as-a-Service (IaaS), driven by a usage model rather than a purchase model.
- Platform-as-a-Service (PaaS), driving an end-to-end design of applications through a set of micro-services rather than infrastructure components.
SaaS – Software-as-a-Service Cloud – Mobile accelerated the explosion of social computing through SaaS applications such as Facebook, Instagram, Twitter, LinkedIn and many others. At the same time some enterprise business processes could be easily outsourced to SaaS, including Payroll, sales and marketing support (e.g., SalesForce.com), IT Services (e.g., ServiceNow), HR (e.g., Workday), etc. Notably, Microsoft is moving large amounts of its Office portfolio to a SaaS model with Office 365.
ISVs (Independent Software Companies) have found SaaS applications are much cheaper to develop and maintain than traditional software distribution methods, and quicker to update functionally. There are less moving parts to manage when the infrastructure is fixed. The subscription model is easier to sell, (although harder to initially finance). IT creates a stable platform on which to develop, as the infrastructure and middleware components are also well defined.
Figure 3 shows the SaaS market is projected by Wikibon to grow six-fold from about $50 Billion in 2015 to about $300 Billion in 2026. It is currently a highly diverse market with a long tail of small vendors. It is expected to continue to be so.
IaaS – Infrastructure-as-a-Service Cloud – IaaS public clouds provide shared infrastructure services for compute, storage and networking. These services are provided as both short-term and longer-term rental basis. many SaaS vendors use IaaS vendors such as AWS and Microsoft Azure, especially because of the wide range of software services available to rent, and the ability to lower initial capital costs.
Figure 3 shows the SaaS market is projected by Wikibon to grow five-fold from a base of about $25 billion in 2015 to about $125 billion in 2026. IaaS vendors such as AWS, Microsoft Azure, Google and IBM will be looking to include their own software on the IaaS base, in particular middleware and database software.
Source: © Wikibon 2015
PaaS – Platform-as-a-Service Cloud – driven by a different application development and operations model (Dev/Ops). PaaS is an end-to-end design for applications through a set of micro-services rather than infrastructure components.
This public cloud segment is emerging as two separate components.
- The first is an extension to the IaaS model, where micro-services replace infrastructure components, which then manage and utilize the IaaS infrastructure. An example is Pivotal Cloud Foundry.
- The second is extension to the SaaS model, where the same application infrastructure is extended to give the ability to develop derivative applications. An example is force.com extension of Salesforce.
The PaaS cloud is nascent. It is built on the IaaS and SaaS clouds, and is expected to gain traction after the further establishment of IaaS and SaaS clouds. Figure 3 shows the PaaS market is projected by Wikibon to grow sixty-fold from a base of about $2.3 billion in 2015 to about $68 billion in 2026.
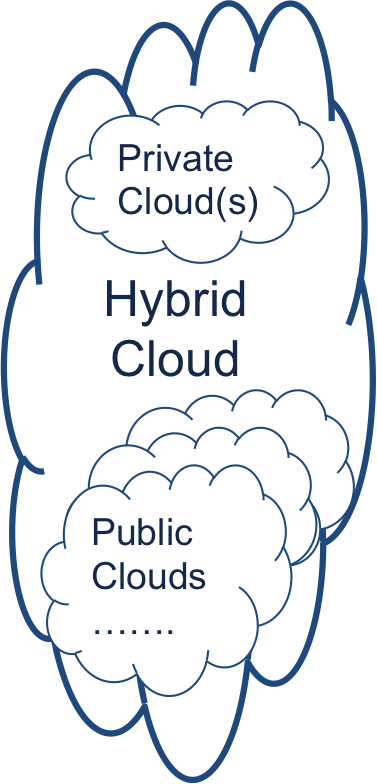
Figure 4 shows that public clouds in total will grow to be about 30% of all IT expenditure over the next decade. SaaS will be two thirds of this market. SaaS is, and is expected to continue to be, a highly fragmented market. Wikibon expects private clouds and edge clouds to approach the same levels of efficiency as public clouds.
Figure 4 shows the migration of many public clouds and private clouds into hybrid clouds. This means that enterprises will take resources from many clouds, and will own the challenge of managing the data-flows and workflows between many public and private clouds.
Managing the Data Tsunami: From Public Cloud to Hybrid Cloud – Bottom Line:
Public Clouds will grow to be 30% of IT expenditure over the next decade. SaaS applications will be two-thirds of this spend, from many different sources. Enterprise IT will own the challenge of managing the data-flows and workflows between many public, private and edge clouds.
The adoption of cloud will put increased pressure on IT organizations to compete with the economics of the public cloud. In order to do so, they will have to achieve massive volume (unlikely) or significant differentiation and value-add with on-premises infrastructure. Building Systems of Intelligence will provide that differentiation and necessitate that IT organizations focus on bridging legacy “Systems of Record” applications with data-intensive SoI workloads. A new systems infrastructure will emerge to support these workloads.
Flash and Data Sharing
Traditional magnetic disks (HDDs) hold ever increasing amounts of data. Current capacity drives hold up to 8 TB/Drive. However, the ability to access data on HDDs has stalled. The IOs per second from a capacity drive is limited to about 100. Storage arrays have done their best to mitigate the problems of HDDs by providing caching services, and create as much IO as possible that is sequential IO. Sequential data is handled better by magnetic HDDs, especially if data is striped over many HDDs.
The results of these constraints are limits on the amount of data available to applications, which limits to the design of applications to using just cache friendly data with small working sets.
Another result of the limited data access capabilities of HDDs is that data cannot be shared. As a result, many copies of data are taken, on average about 10-15 copies within an IT installation. These copies take a long time to complete. Figure 5 shows a typical data flow through a data center, which can often take weeks to accomplish. The result is 10-15 physical incomplete copies of the original data made over a period of weeks.

Source: © Wikibon 2015
Flash storage is about 10 times the price of capacity HDD storage. However, flash has 1,000 times the data access rate of HDDs. This leads to a huge advantage for flash. The same data can be stored once on flash, and many different applications can access that data. Figure 6 shows the impact that sharing data from a single physical copy has on reducing cycle times. The result is dramatic – Instead of weeks with incomplete data, more complete copies can be made of all data in minutes.
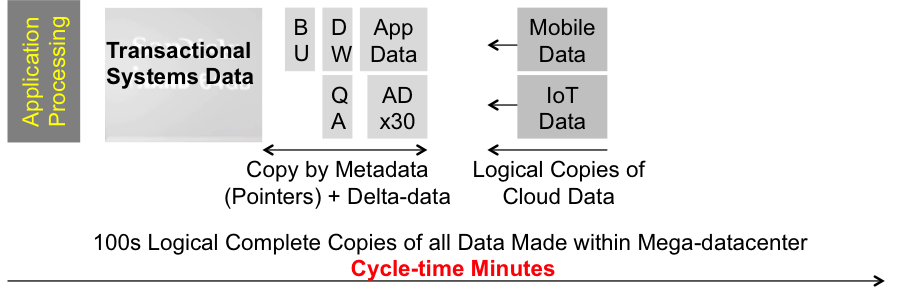
Source: © Wikibon 2015
Flash and data sharing reduces the cost of flash storage to lower than HDD storage, and provides the foundation for faster time to value and Systems of Intelligence.
Managing the Data Tsunami: Flash and Data Sharing – Bottom Line:
Implementing Flash and Data Sharing will shorten the data cycle and time to value from weeks to minutes. The performance of flash is a prerequisite to enable applications to access and process streaming data and operational data together in Systems of Intelligence. The I/O pendulum is swinging back toward the processor as in-memory databases and flash storage will create huge increases in system bandwidth requirements. New systems design will emerge that incorporates semiconductor-based designs throughout the systems hierarchy.
Moore’s Law and Amdahl’s Law
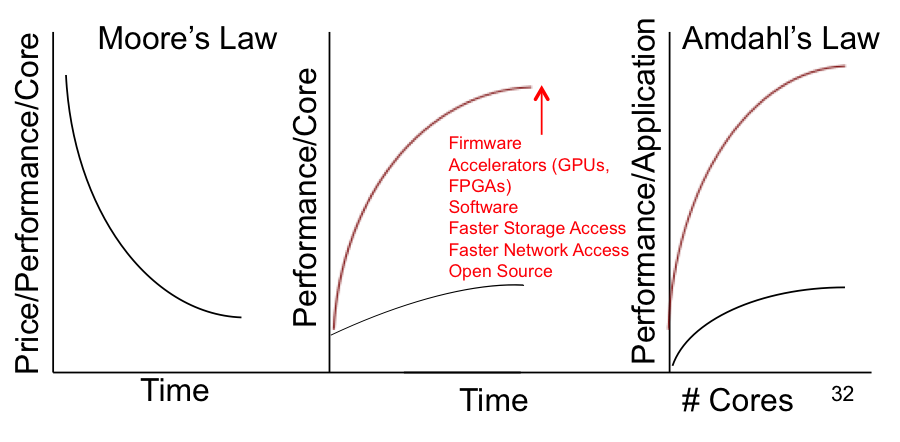
Source: © Wikibon 2015
The left-hand part of Figure 7 shows Moore’s Law following the price performance curve per core. However, this is not the whole story. The performance of a core has stabilized at between 3 and 4 GHz/core. The price performance has been achieved by adding more cores to an Intel x86 chip.
Amdahl’s Law is shown in the right-hand side of Figure 7. When you add cores to an application, the additional amount of performance is limited, depending on the type of system. The number of cores that can be added before the performance gain turns negative is between 8 and 32. Most enterprise data applications are closer to 8 than 32. The black lower line is what is available for application performance. The red line is what is available if the performance of a single core can be significantly improved.
In our view, Intel’s current approach will not support intensive data applications such as Systems of Intelligence because of the performance limitations of the core. The middle section of Figure 7 shows that the only way to improve the performance of the core is to improve the architecture. One design is using coherent data between accelerators such as GPUs, faster access to storage and faster access to other nodes in a cluster. Software and firmware to support these extensions needs to be provided. Although Intel has recently acquired Altera (FPGA maker) to help compete in this area, Wikibon believes it will be many years before this can be brought to market.
An alternative approach is to use Linux processors designed using coherent data architectures different places such as the OpenPOWER foundation. One of the most important OpenPOWER innovations is the use of CAPI, which allows this coherent access to common coherent memory from accelerators, storage and networking. Contributors IBM, Nvidea and Mellanox. Early results from Redis and other open source software indicates a 20x performance gain potential, at one third the total cost.
Systems of Intelligence will need all the compute power possible to allow processing of the maximum amount of data. At the moment, Wikibon believes that the OpenPower foundation design is currently the best architecture for Systems of Intelligence (with IBM mainframes being another alternative for existing mainframe shops). While the adoption IBM Power and other non-x86 architectures clearly waned in the past decade, new workloads have emerged that are requiring organizations to re-think systems design. We believe that while x86 will continue to dominate traditional workloads, a potential tipping point in systems design will be reached due to SoI. We believe close attention needs to be paid to the degree to which organizations can leverage new systems design to create SoI and new sources of business value.
Managing the Data Tsunami: Moore’s Law and Amdahl’s Law – Bottom Line:
Systems of Intelligence require the ability to process many times the data from both operational and streaming sources. The current limitations of Intel processors need major extensions. The OpenPOWER foundation is currently the best architecture for data centric high performance computing.
Software Design for Systems of Intelligence
Todays systems are focused on separate operational and data warehouse systems, as shown in Figure 4 above. The data extracted from the operational system to feed the data warehouse. Reports and analytics performed are then used by analysts and line of business executives to run the organization.
Figure 7 shows the time value of enterprise data. The traditional data warehouse empowers the few analysts and managers to steer the enterprise ship by its wake. This model does not encourage sharing data and insights. It rather encourages executives to hoard data and insights, and optimize when to share it.
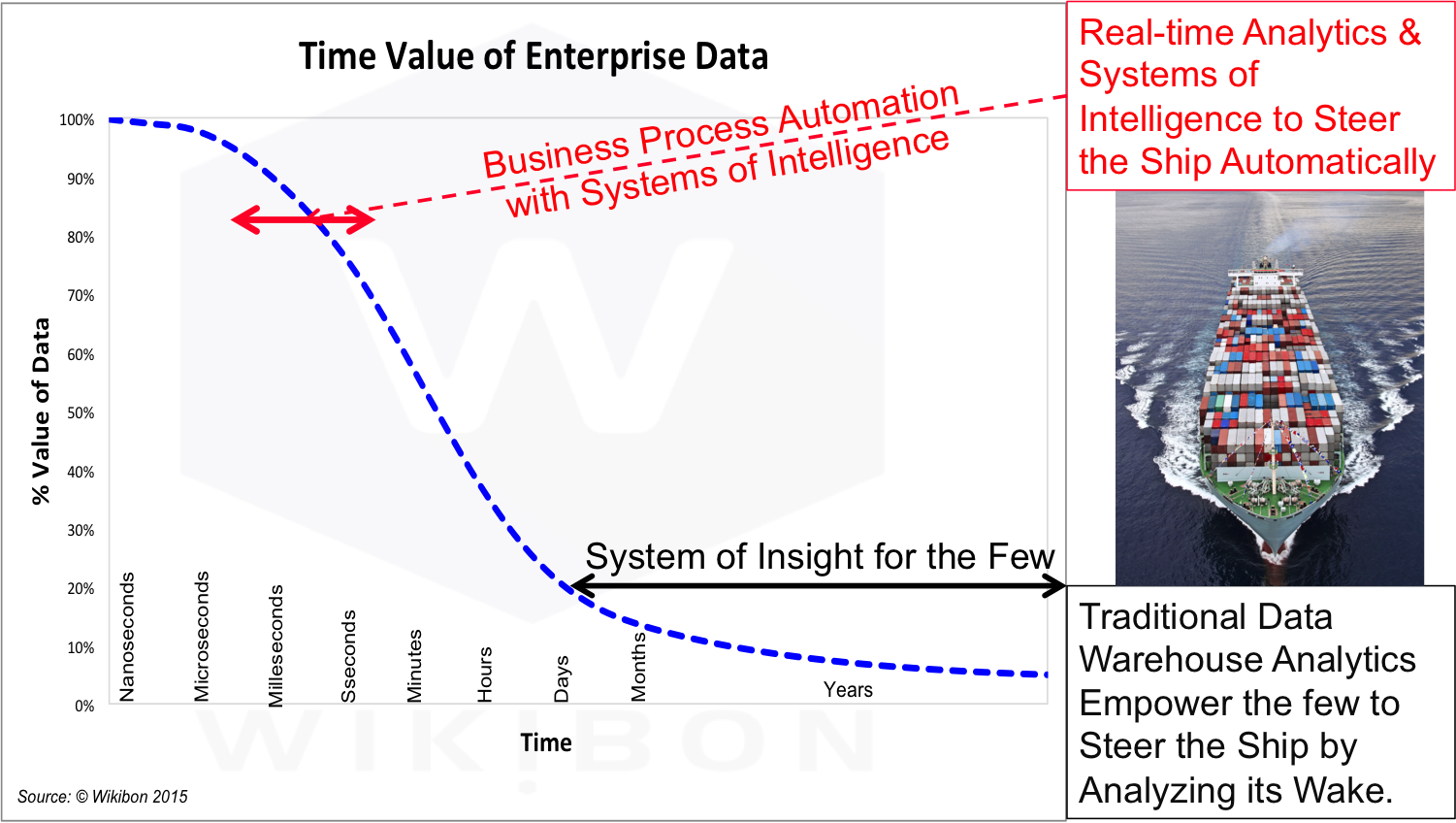
Source: © Wikibon 2015
The Software design for systems of intelligence is is to combine operational systems data with streaming data to allow implementation of real-time or near-real time algorithms that will automate the optimum decision. The algorithm is designed and maintained with the help of big data systems operating in batch mode.
The key to success is to be able to access as much data as possible to drive the best algorithm. The faster the data access (low-latency flash storage), the more data is shared (no data movement required), the faster the processor (the greater the data processed) the better the decision making capability of the SoI. It is important that the algorithm operates very fast, in milliseconds, so that operational user productivity of employees and customers (and the customer experience) is not impacted.
One core component of SoI design is the capabilities of the database. Functionality such as being able to take highly performant views by row (for transaction processing) and column (for analytics). IBM’s DB2 system is one example of a database that will take advantage of OpenPOWER technology and allow both operational and analytics to be done simultaneously.
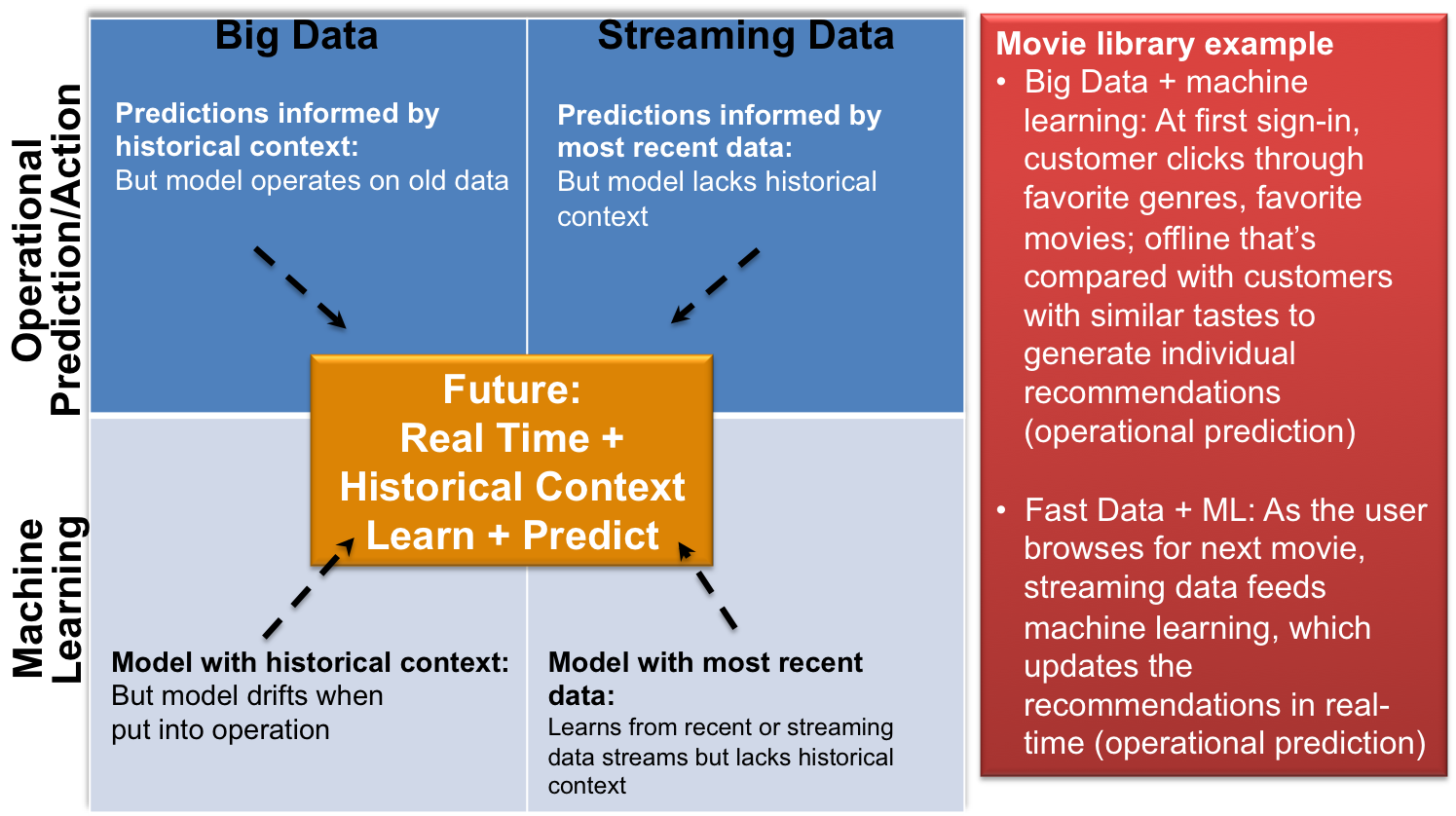
Source: © Wikibon 2015
Figure 8 shows an example of the journey to Systems of Intelligence. Streaming data and machine learning are required to be processed extremely fast, using databases designed to achieve success.
Managing the Data Tsunami: Software design for SoI – Bottom Line:
Systems of Intelligence require the ability to process many times the data from both operational and streaming sources. The current limitations of Intel processors need major extensions. The OpenPOWER foundation is currently the best architecture for data centric high performance computing.
IT Disruptions are Consumer Led
The major disruptions are Mobile, Cloud, Social Media, Flash, Open Source, Convergence, Hyper-convergence, Moore’s Law, Big Data, MeSensors and the Internet of Things (IoT). These in turn lead to the greatest disruption, Systems of Intelligence.
Most of the disruptions started as consumer led. Intel drove Moore’s Law, and the Intel/Microsoft duopoly in PCs led to x86 and Windows volume, which led to the same technologies being used in commodity data center servers. The PCs funded volume hard disk drives, which led to the same technologies being used in commodity data center storage. Steve Jobs funded the start of Flash in the consumer iPod Nano, and flash has taken over storage in smartphones, video cameras, thumb drives, etc. Over 85% of flash is consumer led. Mobile is built on flash and ARM processors, which now dominate mobile, wearables and increasingly access to Internet data. Google search was a consumer-led cloud, digital Big Data application run in Mega-datacenters. Facebook, LinkedIn, and other cloud applications led to convergence and hyper-converged technologies, which are reaching into enterprise computing. Open Source software, starting with Linux, is driving most consumer and enterprise clouds. Moore’s law is reaching performance limits. The x86 architecture, without the protection of consumer PCs and mobile, is under potential threat from ARM processors and processor innovation from the OpenPOWER foundation. The sensor MEMS revolution funded by mobile has lead to the Internet of Things (IoT), and ever increasing amounts of big data and computing at the edge (close to the sensors) and in the clouds in mega-datacenters.
This tsunami of information, sensors and computing is driving artificial intelligence (AI) and Systems of Intelligence.
Managing the Data Tsunami: IT Disruptions are Consumer-led – Bottom Line:
The key take-away for enterprise executives is that almost all enterprise technologies will be directly derived from consumer technologies. Executives should be wary of investment in technologies that are not strongly connected to consumer technologies.
Systems of Intelligence
The initial application by Google to driving consumer cars has arrived, and shown that autonomous cars are safer than cars driven by humans. Systems of Intelligence will take the streaming tsunami of real-time information and combine extracts from this data with operation systems in real-time. This will lead to smarter autonomous systems that will bypass human operators. This in turn will lead to creating a major disruption by dramatically lowing enterprise costs, and increasing the opportunity for radically different ways of providing value to stakeholders.
The migration to Systems of Intelligence will occur by focussing on one business process at a time, and focussing on algorithms that will enable automation and new ways of adding business value.
Action Item
The ability to implement systems of Intelligence will depend on ensuring that all the technology prerequisites are in place, especially fast processors, flash storage and highly functional databases. Strong management leadership is also a prerequisite. The key is to focus the end result on proven algorithms implemented as part of operational systems.


