
Premise: While legacy IT infrastructure will remain in place, and needs to be updated and maintained for years to come, an increasing number of CIOs are now focusing more of their attention on new types of applications that will help differentiate how the business competes in the digital era. These new types of applications are being built using architectures that value data collection, closed system feedback loops, and data-driven decision making to improve customer experiences.
Wikibon refers to these architectures as the “Digital Business Platform“. At the core of these architectures is a focus on collecting and analyzing information about digital interactions, in the context of customer actions. The Digital Business Platform framework enables companies to have a real-time view of how customers are interacting with their digital products, and share this information within the company to improve their products and create better experiences for their customers and partners.
In the past, businesses would deploy large systems to process transactions and maintain information about multiple aspects of their business. These ERP, CRM, HRM (and many other) systems managed back-office functions that improved the efficiency of the business, with analysis often being done in weekly or monthly batches, often through data warehousing.
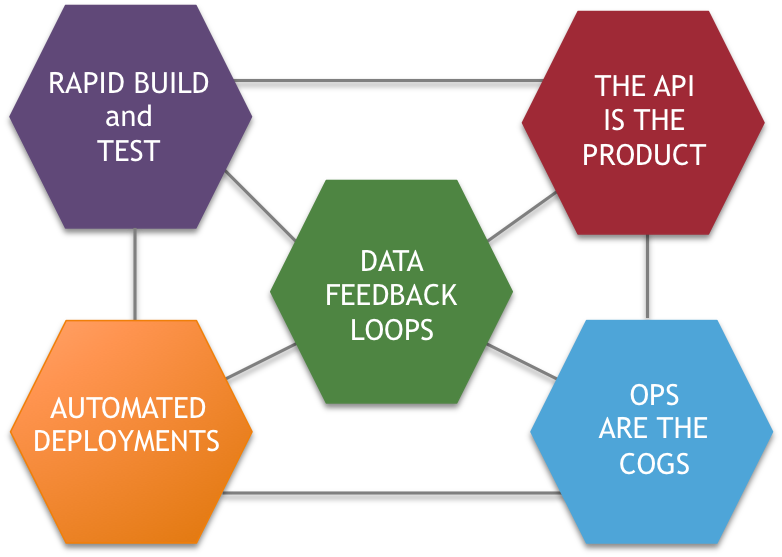
But the needs of every business are rapidly evolving, especially as the costs of computing are coming down and customers expectations are being significantly shaped by mobile devices and the collection of data at the edge of networks. These transformative shifts mean that more data-rich experiences can be created for customers, and more data about those experiences can be collected, analyzed and acted upon. Wikibon calls this a “Data Feedback Loop“, which allows the business to quickly test, validate and responded to interactions in the market.
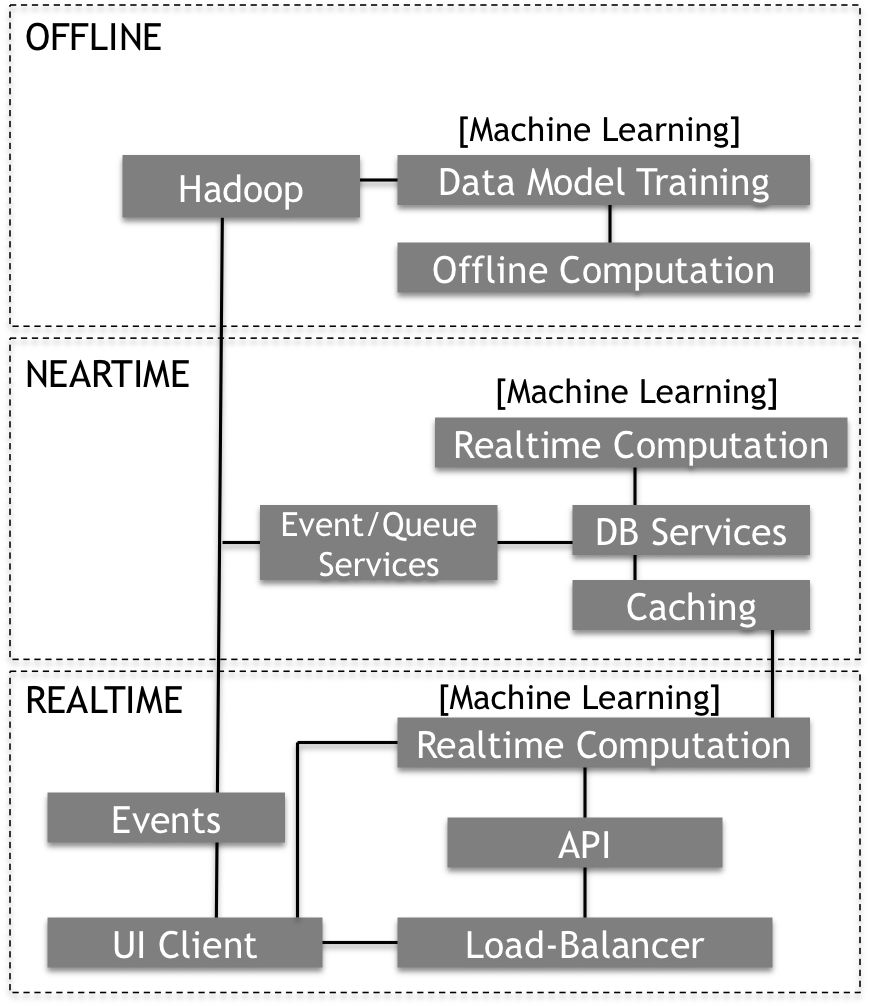
An example of this type of architecture can be seen below.
- The RealTime tier is focused on immediate Customer UX interactions. It is serving front-end web content (or mobile content) with a mix of static content and user-specific content.
- The NearTime tier takes contextual data from customer interacts and determines how to adjust the experience based on the contextual activities of the user. This may include recommendations, personalized offerings, or content that is specific to their location or modality (web vs. mobile). This tier is driving decisions based on data collected from the Realtime tier and combining it with data from the Offline tier. This data will be used in the day-to-day interactions of the business to meet near-term goals and make proactive and reactive adjustments to the marketplace.
- The Offline tier is focused on historical trends and analysis, as well as creating models of user or device behaviors for 1000s of users or interactions. This data will be used strategically by the business to look at on-going trends, as well as ways to make the overall business more efficient.
The Evolution of Cloud-native Applications, Data and Storage
In the past, stateful applications were built using a three-tier architecture of web, middleware and database, popularized by the LAMP (Linux, Apache, MySQL, PHP) stack. These monolithic architectures were difficult to update and scale, and they were typically built on hardware-centric infrastructure (e.g. VLANs, SAN) that was also complicated to update and scale. As such, new Cloud-native application and infrastructure architectures are beginning to emerge to provide businesses with greater agility. These new architectures are being built using software-defined infrastructure, distributed application principles and microservices. This allows for smaller portions of applications to worked on independently, and updated without impacting the broader set of services.
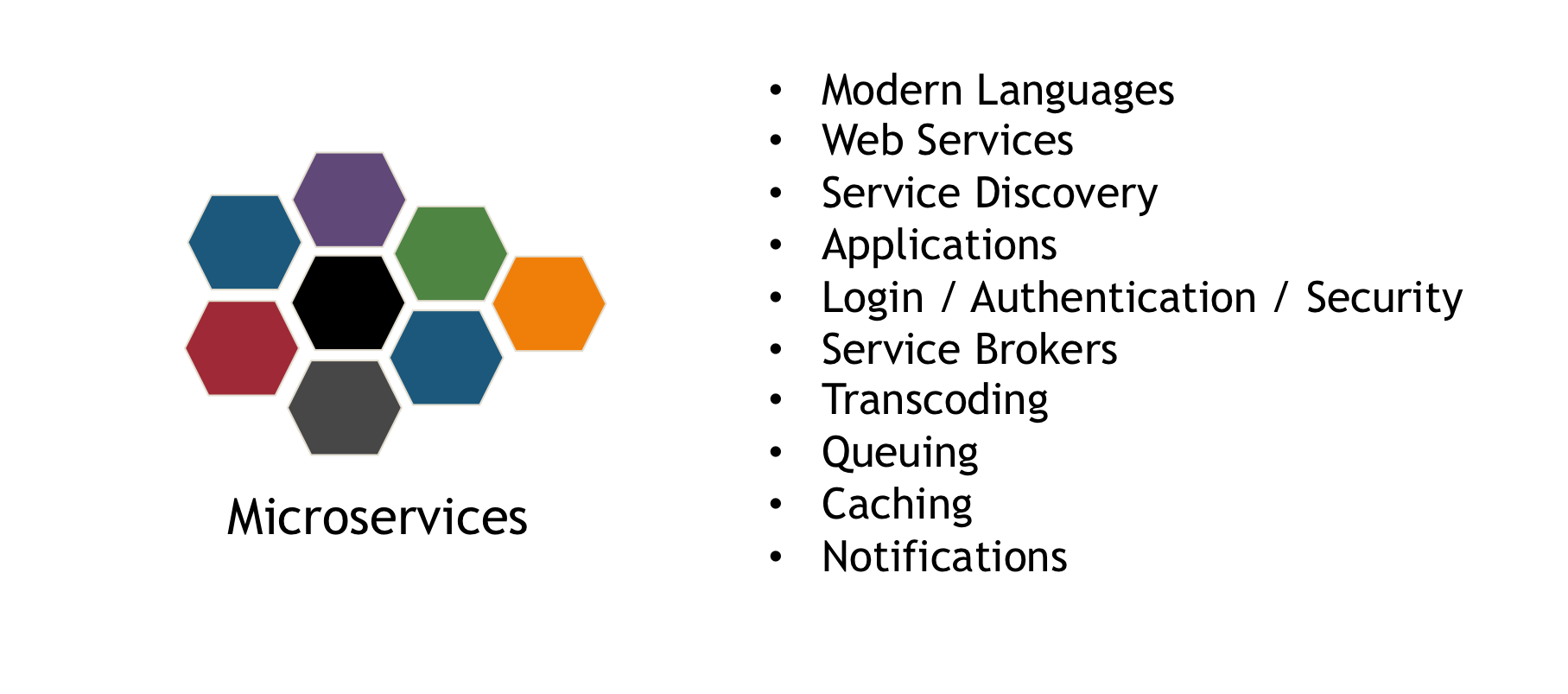
With traditional (monolithic) applications, developer and operations teams are constrained in their ability to publish new updates because of all of the interdependencies within the application components. Microservices is the evolving application model that separate elements of applications into discrete functions, allowing them to be developed, maintained and updated independently of other functions of the applications.
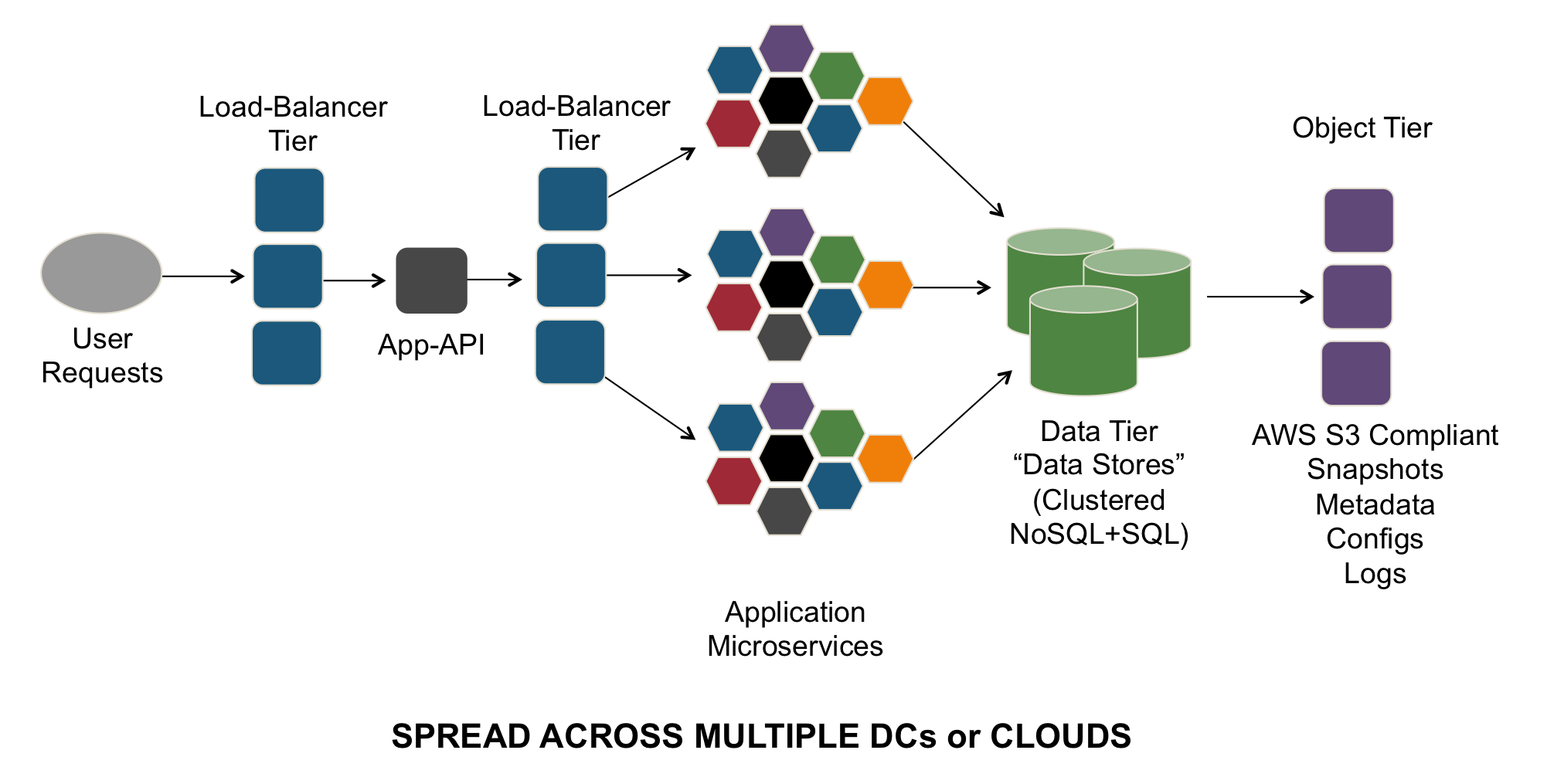
These new application architectures are collecting more data about the application-usage and user-interaction. The data tends to get segmented into various tiers, depending on the location of the user and the need for responsiveness of the application.
- Caching Tier – This could be a CDN, or a localized cache (eg. Memcached) for initial user interaction. It is often pulled static data (e.g. images from an object storage, static HTML, etc.) and frequently accessed data.
- Database Tier – More applications are moving towards a model that attempts put as much data in RAM as possible into the host and makes huge datasets locally available. NoSQL/SQL databases are clustered and replicated (locally and geographically).
- Logging Tier – At every tier within an application, developers and operators are now attempting to log everything. Not only is this used for troubleshooting application problems, but the contextual data is being used in the Data Feedback Loops to better understand how to deliver a better user-experience, identify usage trends or streamline the interaction with the application.
- Analytics Tier – Hadoop, Spark, Machine Learning, AI, Batch; Search; “Data Lake” – All of these concepts and technologies are being applied to the data collected from an application in order to understand usage trends and align strategy plans.
- Object Tier – As more content is being created by the applications, by the users and by cross-system interactions (Images, Videos, Backups), it is more frequently being stored in Object Storage repositories instead of SAN or File-System repositories, as they are simpler to manage and scale, and they make it simpler for applications to only need a globally available URL to reach this content.
Public or Private Cloud Deployments
While the on-demand nature of public cloud deployments can be appealing to developers, the reality of Internet network latency, physical data locality, security and compliance guidelines often become a bottleneck for operations teams that must maintain applications in production. These limitations lead many companies to consider a Private Cloud or Hybrid Cloud option for deploying Cloud-native applications.
While many open source projects (Hadoop, Kubernetes, OpenStack, etc.), can emulate the services delivered by public cloud providers, a number of commercial vendors also offer solutions which can emulate public cloud services and deliver additional capabilities required by Enterprise companies. These commercial offerings simplify deployments and validate 3rd-party integrations, which is a critical aspect to deliver flexible options for application teams. These offerings also allow IT organizations to deploy consistent environments on Private Cloud or Public Cloud infrastructure, simplify operations for applications running in either environment.
Action Item: With increasing demand from CIOs to help digitize their business, IT organizations can expect to see more requests for them to build and operate an environment that supports Cloud-native applications. It is important to understand that these Cloud-native applications use different design patterns than previous applications, and the expectations for data and data management are rapidly changing. It organizations should begin to study the design patterns of Cloud-native applications, as well as evaluate commercial offerings that will help simplify the infrastructure and operations of these environments.


