
Contributing Analyst:
Dave Vellante
Premise:
The key driving force in the analytic data pipeline in Systems of Intelligence is shrinking the time between capturing data and making a decision. The prior research note introduced the concept of stream processing to capture data in near real-time as an alternative to traditional databases.
This research notes takes the next step in helping IT leaders and architects evaluate the trade-offs between the two approaches when analyzing data one event at a time. At the highest level, databases can generally make more accurate decisions while stream processors can make much faster decisions.
Introduction
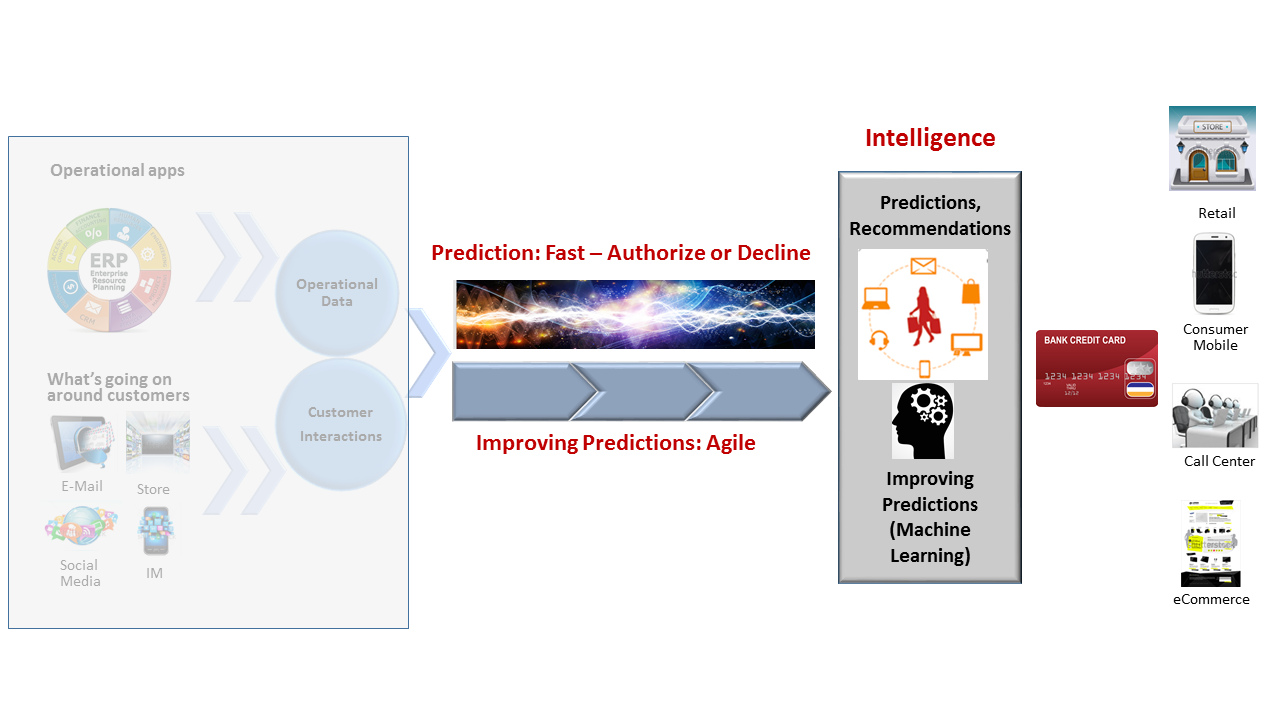
Comparing DBMS’s and stream processors risks being a rather abstract exercise. In order to make it a bit more concrete, we’re going to use the example of fraud detection/prevention. First, we’ll compare just the essence and trade-offs of the two approaches at a level accessible to IT leaders. Then we’ll drop down a level and peer under the covers just enough to give architects a glimpse at how things work and the trade-offs of the two approaches.
To keep things simple in this research note, we are going to look at each approach in isolation. In some of the leading-edge products in both categories there is functionality that shows a bit of overlap. In a future note we’ll explain what this overlap looks like. In addition, we’ll look at how products from the two categories might work together or even how one approach might eventually subsume the other one.
Source: Wikibon 2015
Real-time analytic data pipeline with DBMS’s
Fraud Detection
What happens: When a credit card charge request comes in the database looks up and evaluates information about the customer, including what they’ve done in the past. Running alongside the database is a program which indicates the likelihood that this transaction is fraudulent (the tech terminology is model scoring). If the answer is yes, the transaction will shut off the card so it can’t make any further charges.
When using a DBMS, however, the performance overhead will generally make it a bit too slow to prevent the fraudulent transaction. It’ll only be able to detect fraud a bit after the fact.
Pluses
- Richer fraud model – The database can look up relevant information separate from the charge request that helps make a more accurate picture of whether the transaction is fraudulent.
- Richer history – Every purchase is captured as a transaction. That makes it possible to check if the previous charge took place within the last hour and that it came from within a 25 mile radius, for example. Charges very far apart within a short time-frame are more likely to be fraudulent.
Minuses
- Performance overhead – Databases pay for their rich functionality relative to stream processors with a stiff performance penalty. One stream processing vendor, admittedly biased, estimates DBMS’s are 100-1,000x slower.
- Detection instead of prevention – That performance penalty means that if there’s just enough computing horsepower for a stream processor to flag a fraudulent charge, a database on the same hardware won’t be fast enough to prevent the charge. It would more likely be able to shut off the credit card after the transaction.
Real-time analytic data pipeline with stream processors
Fraud Prevention
What happens: Charge requests just stream in with raw performance without getting stored first. The same scoring program that runs next to the database assigns a likelihood that the charge request is fraudulent. The stream processor then either sends a message to stop the merchant from authorizing the purchase or it does nothing. Most modern stream processors at least add the charge request to a log so that it’s permanently stored and another program can do downstream processing later.
Pluses
- Performance overhead – The opposite of the database’s shortcoming is the super low overhead of the stream processor.
- Prevention instead of detection – Just like serving an online ad, the stream processor might have only several tens of milliseconds to make a decision to fit within the SLA of the merchant’s payment processing device. With the much faster performance, the charge can be denied in real-time.
Minuses
- Less fidelity in the fraud model – Nothing is keeping track of all the other information beyond the current charge request. That includes information like recent charges or other profile data that could inform the current decision.
- Less history – The stream processor could look up historical charges, including recent ones, in an external database. But that would erase its primary advantage: performance. It could cache some of this information locally, but it would risk containing out-of-date or incorrect data. Without a DBMS, it can’t use transactions to make sure new charges don’t step on existing data, like a running total of monthly charges and whether the current transaction will exceed that limit.
Summary
In terms of budgeting for trade-offs listed in the previous research note, using a DBMS offers more accurate predictions because of access to a richer profile. It also better leverages existing skills and technology infrastructure. But this comes at the expense of the speed of prediction.
Stream processors offer faster analysis and that stops more fraudulent transactions. Although the count of blocked transactions may be higher, however, there is less accuracy. Some more sophisticated ones may slip through because the information surrounding each charge isn’t as rich.
Action Item:
Both IT leaders and architects need to participate in the decision process using the budget that evaluates trade-offs. To help evaluate the trade-offs between speed and accuracy, organizations can often use historical or training data.


