
Contributing Analyst:
Dave Vellante
Premise:
For thirty years mainstream analytic data pipelines took information from OLTP applications and created reports that informed organizations about what happened in the past. This process was accomplished periodically (e.g. weekly or monthly at the end of close, etc.). The tooling to support these processes essentially focused on offline ETL and business intelligence. Increasingly, organizations must deal with data flows that come in, not in batches, but continuously. As a result, developers must reconsider how they process and analyze that data. Specifically, because continuously streaming data is becoming mainstream and decisions must be made as close to real-time as possible, customers need to adopt new data management and analysis technology.
This research note will review the trade-offs between extending current DBMS technology and subsuming it with “streaming first” technology.
Systems of Record: Thirty Years of Batch Processing and Business Intelligence
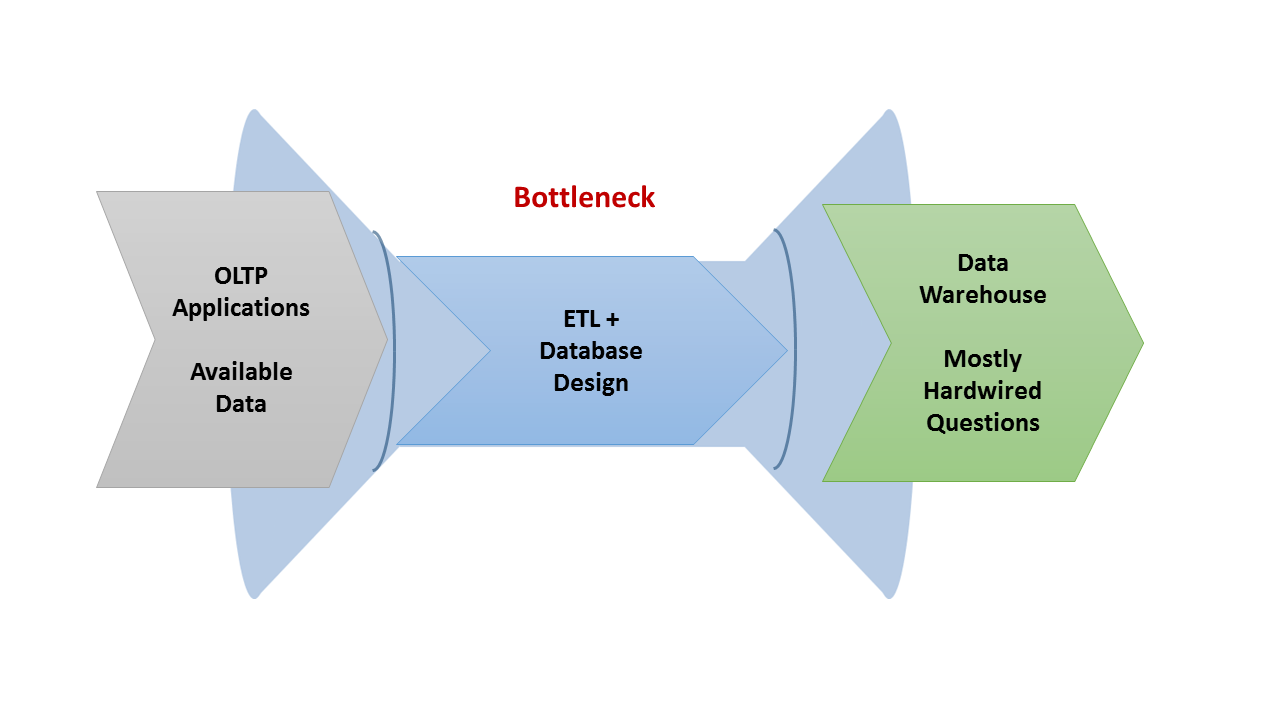
The historical process of data management is characterized by the following six factors:
- Applications were designed to capture data from transactions and then convert that information into a separate database optimized for scanning and summarizing;
- The data flow was “lumpy” and came in batches, based on the how frequently reports were run which then drove how frequently the extracts had to occur;
- This model restricted the degree of self-service access to business intelligence. The IT organization delivered the extracts and built BI models for the data warehouse but everything was cumbersome to change and respond to new requirements;
- Data warehouses proliferated. Users became accustomed to these cumbersome limits and tried to “cut the line,” cajoling IT to provide one-off extracts and dumping them into their own data warehouses;
- This created an infrastructure that was fragmented, hard to manage, and difficult to present in a global view;
- Agility was a function of the slowest process which tended to be bottlenecked within IT.
Source: Wikibon 2015
The Imperative for a New Data Management and Analysis Model
Zoomdata, one of the emerging, nexgen BI vendors explains in very plain terms how near real-time streaming data can often grow out of the existing application landscape. Lots of data that organizations capture, perform ETL, and analyze in batch mode starts out as streams. Retail point-of-sale data, telco call detail records for billing and network management, and systems and application management are all examples of data that flows continuously. They were batched up so they could be moved from one system to the next or be combined for analysis.
Now it’s possible to perform ETL and analyze all that data while it’s flowing “in motion” because of several new technologies.
- Elastically scalable stream processors such as Kafka and AWS Kinesis Firehose can keep up with the volume and with resilience.
- Streaming analysis products such as Spark Streaming, Flink, Data Torrent, Hortonworks Dataflow, Google Cloud Platform Dataflow, IBM Infosphere Streams, and others can perform advanced analytics. The analytics typically includes machine learning at scale, where only more expensive DBMS’s such as Oracle and Teradata could deliver similar capabilities.
- New operational databases (NewSQL, NoSQL) can combine high velocity streaming transactions with some native analytics and the ability to integrate with more advanced techniques such as machine learning.
- Finally, new BI tools such as Zoomdata and high performance databases such as MemSQL, VoltDB, and Splice Machine can serve live dashboards and often OLAP cubes on the streaming data.
Evaluating Two Approaches To Leveraging Near Real-Time Data
Becoming a “data-driven” organization that can build Systems of Intelligence ultimately requires a new approach to building applications. This is where developers and architects have to evaluate one of two paths forward from which to choose.
A main challenge and opportunity that mainstream organizations have is replicating the process that the Web giants have undertaken to deal with data in near real-time. A debate in Global 2000 development circles boils down to the following paradox:
- Do you extend your existing database infrastructure or
- Switch to a new approach that can potentially subsume the old model as part of a new data management strategy.
The tradeoffs are clear but non-trivial. In particular, extending the old model leverages existing assets and skills. However it may not accommodate the full extent of the desired business outcomes with current technology. Following the latter path is more risky because of the need for new skillsets and less mature technology.
Wikibon practitioners should focus on the following formula for their first applications to inform the business case and make the decision:
Budgeting for trade-offs
- Accuracy of predictions
- Speed of analysis/prediction (latency)
- Speed of changing the analytic model (agility)
- TCO / operational complexity (single vs. multi-product/vendor infrastructure)
- Development complexity (same as TCO but for development frameworks)
- Existing infrastructure (technology and skills)
The result of this analysis will help evaluate the costs and risk levels. The key in our view is to get started and gain valuable experience, working toward a continuous delivery model.
Part 2
The next part in the series will explore the two major choices for building Systems of Intelligence: extending existing database infrastructure or building on the new model with the use of standalone streaming analysis products.
Action Item:
Creating a data-driven organization requires new thinking by developers. Moving toward a real-time model is an imperative for most organizations. However, regardless of which approach that’s chosen, IT must start getting the source operational applications ready to “publish” their data continuously rather than in batches. That often means adding infrastructure capacity to support real-time movement of data into a stream processor. The next step is to start creating a “shadow” ETL pipeline. Unlike the existing ETL pipeline, this new one does some of the basic transformations continuously and in near real-time.


