
Executive Summary
Unstructured data is growing significantly faster than structured data. As a result, enterprise expenditure on filers is growing, and IT executives know that action is required to ensure that this expenditure does not grow out of control. At the same time, Big Data management techniques and analytics have shown that historical data is valuable. Even security footage video has the potential to be analyzed with techniques such as facial recognition to help identify past security breaches and protect future losses.
Wikibon has concluded that a step-by-step process is required to:
- Bring Some Structure to Unstructured Data
- Data should be actively classified, system metadata added automatically, and user metadata added at the time of creation.
- Provide a De-duplicated Global File System as a Basis for Future Analysis
- This system should avoid replication of data.
- It should ensure that data can be analyzed either in place or by easy extraction via the metadata.
- Integrate the Data into Modern Big Data Extraction and Analysis Processes
- The details of this step are beyond the scope of this work. However, the choice of IT infrastructure should allow data to be migrated easily into a Hadoop data lake, for instance, or be analyzed in place where possible to minimize data movement.
The mark of success of an unstructured data management project for IT is that:
- The unstructured data is under control;
- We know what types of unstructured data we have, and what the growth rates are;
- We have consolidated and removed most redundancy in our unstructured data;
- We have good protection processes in place;
- We have good techniques for compliance, pre- and post-classification;
- We can get at that data pretty easily;
- We can manage the risk adequately;
- We have plans to add structure and add application functionality to identify and derive business value.
Wikibon has analyzed the potential IT value of an unstructured data project in Figures 1 & 2 below. The potential value for the Wikibon standard company ($40 million dollar budget and $2.5 billion in revenue) is a NPV of $1.7 million, with about a two year break-even. The true business value, however, is in projects that can derive value from the data and reduce the risks of non-compliance.
Introduction To Wikibon Unstructured Data Study
Wikibon interviewed senior IT executives to investigate the sources of pain points with unstructured data and the alternatives for addressing these issues. In addition, Wikibon reviewed its previous research on unstructured data as well as a number of published surveys. This research took place in early 2014.
Data Growth Projections
IDC’s The Digital Universe study projects that the total amount of data created and copied annually was 4.4 zettabytes (1010, or 4.4 billion 1TB disk drives) at the end of 2013 and will grow by a factor of 10 by 2020. Research by G. Decad, R. Fontana and S. Hetzler at the IBM Almaden Research Center suggests that these starting figures and growth rates are high, based on analysis of the yearly manufacture of NAND flash, hard disk and tape media.
However, the overall consensus of the senior executives Wikibon spoke with is enterprise data is growing fast, and while structured data growth is essentially under control, enterprise unstructured data is growing faster from a smaller base (~30%) with little control. Typically, unstructured data was spread across multiple distributed filers, personal and mobile devices, backup files, tapes and thumb-sticks.
Although they are concerned about unstructured data growth, the IT executives interviewed believed that with good IT practice, unstructured data could be brought under control with approaches similar to those that previously worked with structured data. As one of the interviewees succinctly said:
““The value of data is ultimately defined by what you can do with it. Our unstructured data is not categorized with useful metadata to apply to some business process. So, right now we consider our unstructured data as unimportant. But we just throw storage at it because we don’t know what to do with it yet and are afraid to throw it away. But ultimately, we expect it to over-run us. We will need to apply rigor and policies about compliance, retention, security, tiering, governance – just like we did when structured data began to overwhelm us.”
Definition And Types Of Unstructured Data
The Wikibon definition of unstructured data file is:
- A file with little or no metadata, and little or no classification data
Unstructured data is the collection of many different types of unstructured files in many formats on many media types in many locations. In our discussion with Wikibon members we discussed many types of unstructured data, including:
- Videos (interactive training, Telepresence, Youtube, largest by capacity).
- Office suite data:
- Excel files,
- PPT files, design and test *Data living in Excel files,
- Email (unstructured (especially in .pst files, but is potentially classifiable as structured).
- Image files.
- Equipment “calling home” raw data.
- Home directories.
- Personal data & pictures.
- File shares.
- Access DBs.
- Security data –process for comprehensive threat analysis.
- Files for eDiscovery.
- Web data.
- Retail customer data.
- Log files.
- Etc.
Adding Structure To Unstructured Data
Given that this data is spread across the enterprise in many filers and formats, the starting point is to pick the fast growing types of data with potential for future business value and establish a storage policy framework similar to how structured data is handled today;
- Actively classify/categorize data at the point of ingestion:
- This is often easier said than done, as many data creation tools (e.g., those in Microsoft’s Office Suite) do not have a mechanism for making it easy or unavoidable to add classification data (e.g. name of project, security classification, department, etc.)
- Focus on adding automatic metadata at the time of creation where possible.
- Focus on moving away from individual filers each with their own name-space, and move towards consolidating files and creating global name spaces.
- Leverage metadata embedded in other solutions (e.g., Unified Communications, eDiscovery, content management, email archiving, etc.)
- Automate as much as possible the managing of unstructured data storage to reduce operational cost.
- Create a long-term strategy for adding the new structured or semi-structured data into corporate “data lakes”, using open source techniques such as Hadoop.
- Ensure that there is good feed back from Big Data analysts and data scientists into improvements in data classification and metadata creation.
Potential Strategies With Video Data
The IDC Digital Universe Study estimates that out of the total 4.4 zetabytes in 2013, 33% is consumed by surveillance. Most of surveillance data is in video format. The current use of video tapes is constrained by the human time required to review tapes. If the time and date are known, it is possible to go back and review. However, this does not protect in real time from a known “bad guy” entering a building, or in reviewing tapes to find if newly identified “bad guys” had visited earlier. The people cost for doing this would be prohibitive.
An increasing number of algorithms will encode elements in the video, from faces to physical characteristics (e.g., height, weight, hair color, etc.). The algorithms are developing rapidly. By extensively tagging the data with metadata about the people and things “recognized” in the video, video can become a living record that can be interrogated and analyzed to protect organizations from internal and external threats. Sharing the data between enterprise and government would increase the potential value exponentially.
Business Case For Migrating Unstructured Data
Figure 1 illustrates the business case for migrating unstructured data. The first column shows the typical costs of IT infrastructure and IT management of unstructured data. The analysis assumes that data is growing about 30%/year. The scope of the project is assumed to be the implementation of a scale-out NAS system (e.g., EMC Isilon) to replace the current departmental filer sprawl. In addition, there is a small-scale project to add automatic metadata, and put in systems that will allow users to add metadata at time of creation.
such a project will create savings across the board in all components of cost.
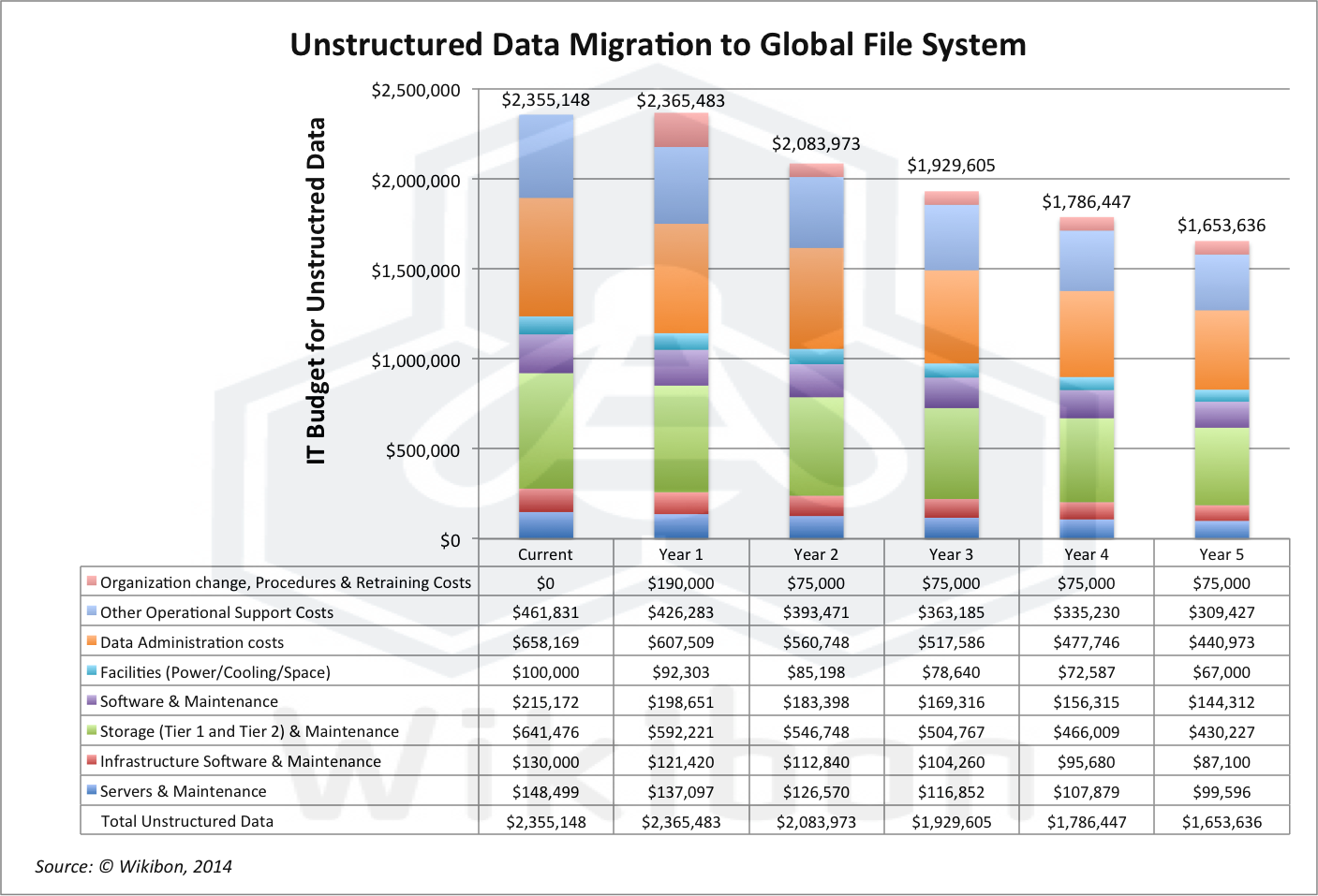
Figure 2 shows the business case for implementing a global file system with simple metadata constructs. The assumption is that currently IT will spend about $11.8 million over five years to manage this data. The analysis shows that implementing a global file system will reduce that total expenditure to about $9.8 million. The net present value of the investment is $1.7 million, with a break-even of 27 months and a IRR of 47%. This is a safe but not spectacular saving. However, the real reason for implementing this system is for risk-reduction from non-compliance and being able to use future Big Data projects to analyze and extract value from the current unstructured data.

Action Item: Unstructured data represents both a liability and opportunity for enterprises and IT leaders. CIOs should set a long-term goal to add structure and the ability to extract value from each type of unstructured data. This is a long journey. The first steps are to understand the growth of different components of unstructured data, to consolidate and eliminate redundancy, and to protect these enterprise data assets. A pragmatic plan can then be put into place to identify which components of unstructured data have high growth and high cost, and focus on determining the best way of adding structure and functionality to derive value from these components.


