
Premise. In the big data domain, businesses are trying to solve complex problems with complex and novel technology — and often failing. Simplifying the packaging of big data technologies will streamline big data pilots and accelerate big data time-to-value.
(This is Part 2 of a two-part series on emerging approaches to establishing big data capabilities and accelerate big data time-to-value by streamlining toolset complexity. This report contrasts two different approaches to managing big data toolset complexity: a bespoke mix-and-match approach; and an integrated appliance approach.)
Too many businesses are struggling to realize the promise of big data technology, and a culprit is complexity. Methods, skills, intellectual property rules, software, and hardware are all evolving rapidly in response to increasing problem specialization. The open source movement is rushing to fill holes in toolkits, but fixes often appear focused on improving the productivity of individual tools and not aligned with an holistic vision of how to improve toolkits overall. As a VP of analytics at a large financial services firm told us,
“I don’t have time for big data technology science projects. I just need someone to show me how all these big data tools fit together.” VP Analytics, US-based financial services company
As a result of complexity challenges, our research shows that big data pilot projects often are abandoned. Partly, this stems from the choice of problem to solve: Few companies have the needs nor resources of a Yahoo, Google, or Facebook driving their big data pilot-to-production efforts. But even when outcomes are well chosen, complexity typically sinks big data pilots because teams:
- Wrongly believe that ease-of-procurement predicts success. Open source software has reset many development-related practices, including software procurement. However, simpler procurement does not necessarily lead to simpler everything else, especially in big data domains.
- Evaluate piece parts, not integrated wholes. The goal of any project should be to achieve a business outcome, not mainly a deeper understanding of a set of tools. Outcome-oriented criteria for evaluating options must be developed and employed.
- Discount the value of packaging. “Solution” has been a marketing buzzword for at least three decades, but packaging itself is a source of real returns in complex, fast changing ecosystems, like big data.
Ease-of-Procurement Is a Poor Predictor of Big Data Success
Freemium, open source software models are compelling: download a distribution, stand it up on commodity hardware and try it, and decide whether or not to buy it. For circumscribed project spaces run by teams with deep experience, the simple try/buy approach to sourcing can predict overall pilot-to-production costs and success. For example, the success of Linux is directly attributable to the facts that (1) it’s a very well defined operating system being purchased by (2) a group of administrators with deep expertise in how it works and how it can be applied to solve specific types of problems.
However, when projects feature a lot of moving parts and steep learning curves, ease-of-procuring commodity technologies is a poor predictor of either ongoing costs or success rates (see Figure 1). Our research shows that single-managed entities (SMEs), comprised of out-of-the box, pre-packaged configurations of hardware, software, and services can streamline pilots and accelerate time-to-value (see Figure 2). Why? Because SMEs grant project teams the opportunity to focus on the business problem to solve and minimize the uncertainties associated with underlying technology (see Figure 3). Normally associated with converged infrastructure, emerging SMEs for big data cost more up-front, which invokes complex procurement processes, but are showing signs of improving success rates from pilot to production.
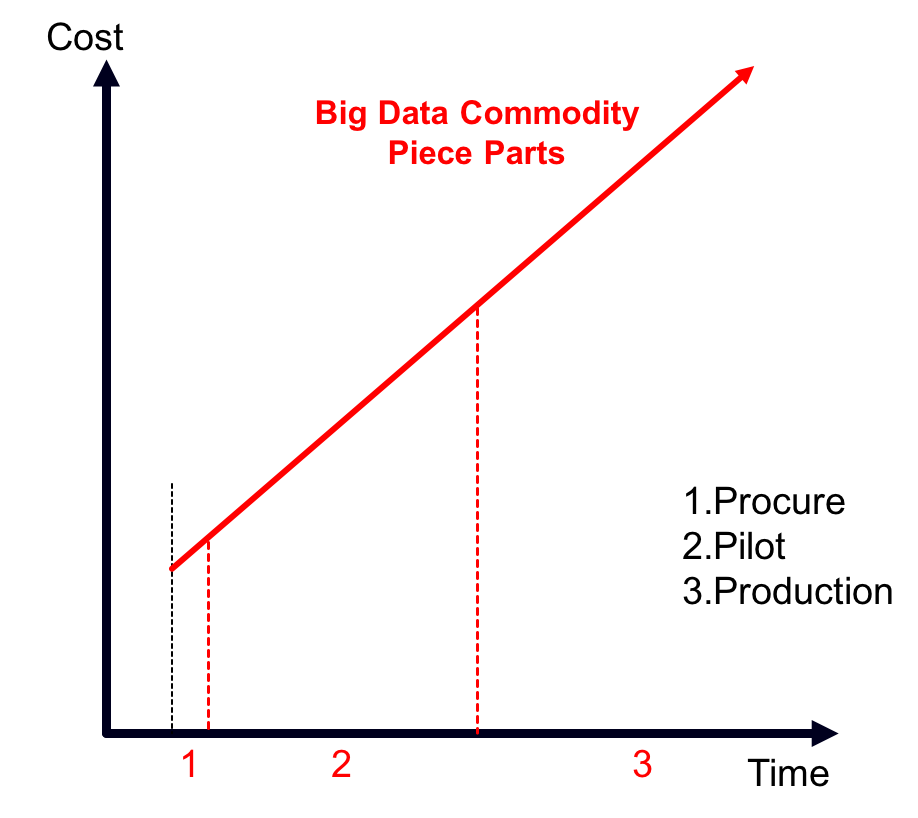
Figure 1: Big Data Piece Parts Approach Facilitates Procurement
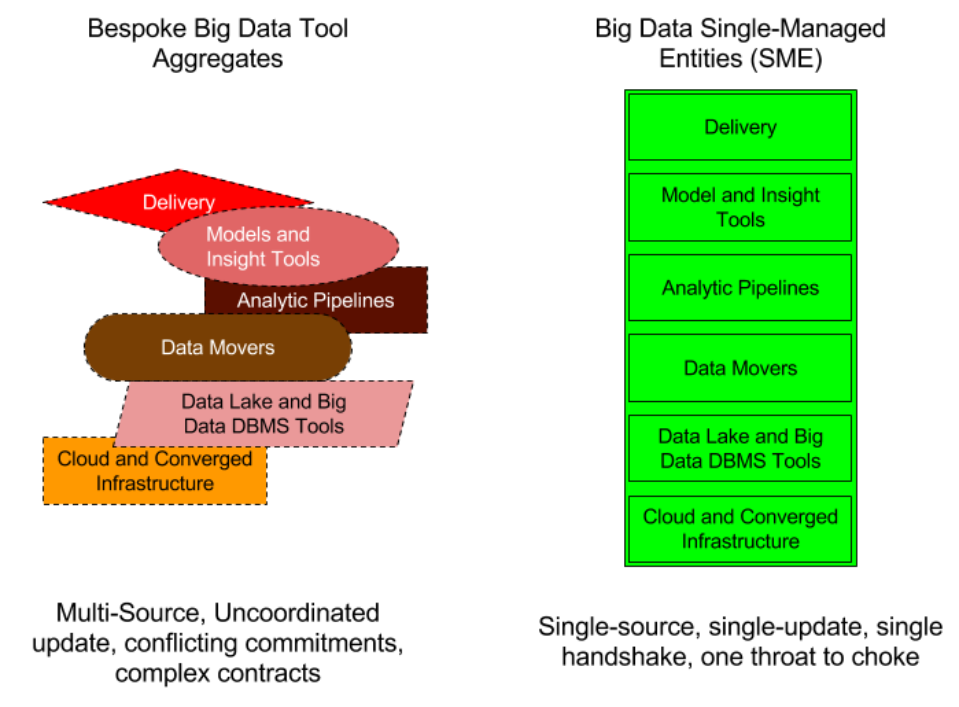 Figure 2: Single Managed Entities (SMEs) Simplify Options
Figure 2: Single Managed Entities (SMEs) Simplify Options
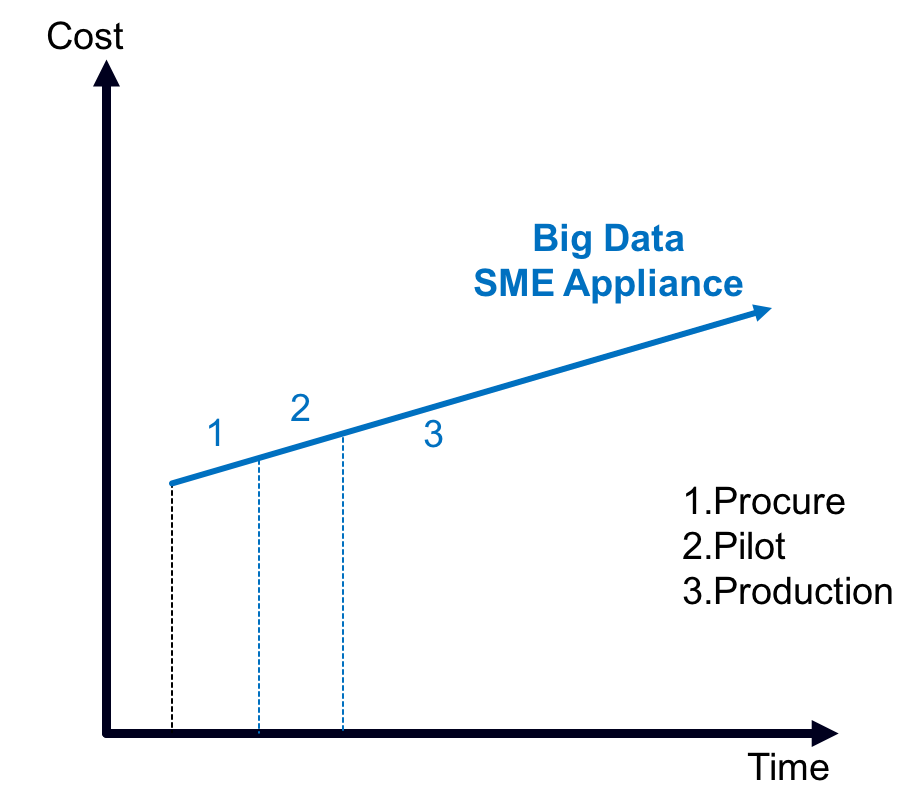 Figure 3: SMEs shift timelines “left” and flatten longer-term costs
Figure 3: SMEs shift timelines “left” and flatten longer-term costs
Evaluate Big Data Outcomes, Not Technology Selections
Big data use cases are multiplying as success in one domain leads to experimentation in another. What started out as an effort to understand visitor click patterns at Yahoo has turned into highly innovative big data systems for fraud detection, deep security, and improving operations. Choosing the right tools will always be important, but our extensive conversations with big data leaders, on theCUBE and elsewhere, highlight 12 criteria that should be used to evaluate big data technology packaging options, which are:
Acquisition of Technology
- Price. Out of pocket expenses are always an issue in technology selection. Cheaper is always better, other things being equal.
- Procurement process. Options with higher up-front costs trigger more complex procurement processes, which (usually by design) slow decision making. Faster and streamlined is better.
Configure and Run Pilot
- Implementation and configuration costs. Setting up big data infrastructure can be a complex task by itself. Even when piece parts appear cheap, the effort to set up clusters, allocate resources, and test configurations can take weeks or months — all before any real effort to determine a project’s potential is undertaken. Cheaper and simpler is better.
- Time to discover and integrate data sources. From the outside, big data projects can look like wild goose chases, as data scientists and others search for data sources that get them closer to understanding and answers. Finding sources, however, isn’t enough; integrating data — testing, mapping, translating, reformatting, contracting for, etc. — can require far more effort and be much more time consuming. Faster and more certainty about sources is better.
- Pilot cost. Ideally, pilots are quick to set up, simple to execute, lead to unambiguous answers, and easily translate into production. Our research shows that big data pilots are especially problematic, prone to failure, and likely to be abandoned. Why? Because many big data pilots combine new hardware, software, skills, methods, and problem domains. For most companies, a big data pilot can actually turn into 5 or more separate pilots, each considering different classes of technology, integration, visualization, business outcome, etc., capabilities, any of which can fail and bring the effort to a halt. Faster and cheaper to a more certain answer is better.
Roll Out to Adoption
- Time to production. The goal of any pilot is to test likely returns on representative technologies and practices. However, many big data projects feature so much newness that successful pilots can turn into protracted rollouts. One contributing factor: New and specialty vendors can “discover” new business practices after pilots are complete, which can lead to new rounds of complex negotiations, procurements, and resource allocations. Faster is better.
- Time to value. Of course, promoting pilots into production ends much of the complex engineering work, but the effort to acculturate people to the new system and the practices it embodies can be equally — or more — complex and involve greater risks. This is especially true in big data programs that involve new data sharing, collaboration, and empirical management habits. Whenever possible, familiar is better than novel. Faster is better.
Maintain and Enhance System Value
- Technology exploitation options. The big data ecosystem is evolving rapidly. Methods are being refined, practices learned, and outcomes discovered daily. The open source projects and technology companies creating and delivering big data tools are both pushing the state-of-the-art — and learning it from successful clients. While few big data technology choices are guaranteed dead ends today, ensuring access to the most productive streams of big data innovation should be a management concern. More options with more concrete prices and returns is better.
- Automation options. New methods, practices, and tools means new operations processes must be identified and adopted — typically before automation tools can be successfully introduced. Tools for automating cluster administration are good and improving, as are tools for administering many core big data system software components, but tools for automating pipelines, model development, asset delivery, and application technologies are immature. Automation investments will follow adoption numbers. This is one domain where betting right early sets you up for years to come. More complete automation is better, which can also be achieved by reducing the number of moving parts.
- Use case options. While keeping technology and automation options open is good, ensuring that today’s big data investments can support not only today’s solutions, but also tomorrow’s even better, more valuable business outcomes is far more important. Our research shows that big data projects often are so complex that IT and business pros become obsessed with solving the immediate problem, often creating new technology and data silos along the way. However, the scope of potential applications of big data technology is expanding rapidly. Efforts to scale big data solutions must not succeed at the expense of pruning future big data application options. More options with more concrete prices and returns is better.
Operationalize Solution
- Scaling constraints. Our research shows that a successful big data project can spawn significant integration work across application portfolios. The data feedback loops that tie together application domains and are crucial to machine learning and other promising big data technology types can themselves engender significant additional capacity requirements. Knowing how hardware, system software, and networking architecture choices will impact future integration is crucial to intelligent big data system designs. Comprehensively identified scaling constraints is essential; fewer — and comprehensively identified — scaling constraints is better.
- Longer-term operations costs. Where do you want your big data talent focused? On infrastructure administration? Or problem solving? A team of 6 data scientists can easily cost $1.3 million – 1.6 million per year. If they are spending their days mucking about in hardware and system software, then that combination of components becomes very expensive very quickly, regardless of whether or not it was “free” when it was procured. Cheaper is better.
An Example: Comparing Oracle’s Big Data Appliance with Commodity Hadoop
Oracle has been at the vanguard of single-managed entity packaging since at least 2010. Using experience gained in the database appliance and other SME domains, the company has been refining its packaging of an SME for big data, which it calls the “Big Data Appliance” (BDA). Today’s Big Data Appliance smartly brings together cluster hardware and big data software components into an SME that dramatically simplifies big data infrastructure (without compromising performance), facilitates integration of data sources from within Oracle (including NoSQL sources), leverages SQL-based tools (without forcing dramatic data transformations), and bundles Cloudera’s Hadoop Enterprise Edition distro — all under a single, aggressive price (as measured per terabyte, relative to commodity, on-premise Hadoop clusters). Additionally, as an SME, it is administered as a unit, not as a collection of piece parts.
So how does the Oracle BDA compare to a “vanilla” combination of Hadoop and cluster piece parts? Very favorably (see Figure 4). Our analysis shows that integrated innovation wins on most criteria, with significant advantages for some of the most important criteria, like pilot costs, time-to-value, use case options, and longer term operational costs.
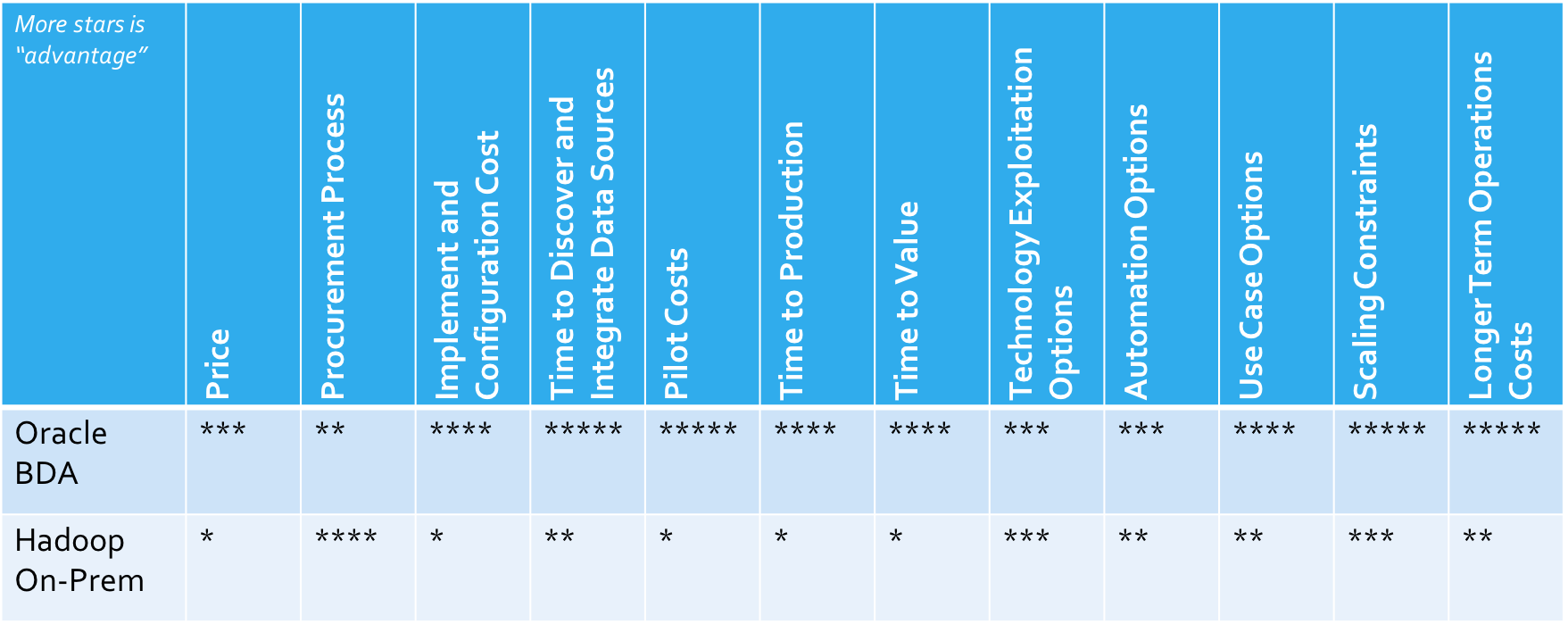 Figure 4: Comparison of “Roll-your-Own” Versus an Integrated Appliance
Figure 4: Comparison of “Roll-your-Own” Versus an Integrated Appliance


