

The big data market remains volatile, driven by rapid advances in hardware and software technology, use cases, market structure, and skills. While the array of big data technology is remarkable, getting the most out of big data technology still requires getting the most out of the companies that supply it.
With George Gilbert, Peter Burris, and Ralph Finos
As part of Wikibon’s big data 2018 market forecast and modeling effort, we interviewed an expansive number of vendors and users regarding trends, learnings, and practices. We published our 2018 Big Data Analytics Trends and Forecast and 2018 Big Data and Analytics Market Share reports using these interviews and others, including hundreds of theCUBE interviews we’ve produced. These reports highlighted the key trends we believe will influence the direction of the big data and analytics market over the next ten years (see Figure 1).
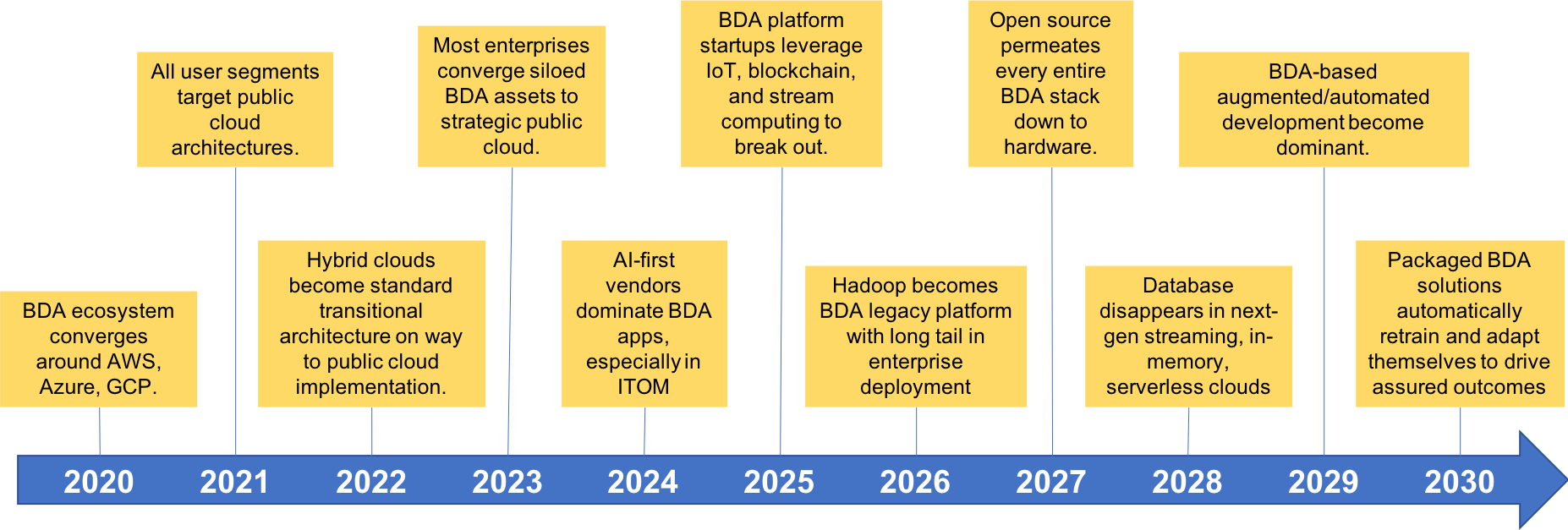 Figure 1. Wikibon’s Key Big Data and Analytics Trends, 2020-2030
Figure 1. Wikibon’s Key Big Data and Analytics Trends, 2020-2030
In this report, we provide vendor profiles we developed during the research. Following are profiles on:
| Actian | Hortonworks | ParallelM |
| Attunity | IBM | Qubole |
| AWS | Iguazio | SAP |
| BMC | Informatica | SAS |
| Cloudera | Intel | Snowflake |
| Confluent | MapR | Splice Machine |
| data Artisans | MemSQL | Splunk |
| Datameer | Micro Focus | Syncsoft |
| Dremio | Microsoft Azure | Teradata |
| FogHorn | MongoDB | Transwarp |
| Oracle | Zoomdata |
Actian. Actian is a well-established vendor of enterprise application databases, analytic databases, and application infrastructure solutions. Headquartered in Palo Alto, California, the privately held firm assembled its product portfolio from technologies that it acquired with Ingres, ParAccel, Versant, and Pervasive.
Actian’s diversified solution portfolio now includes an OLTP RDBMS, an in-memory SQL analytic database, a NoSQL object database, and an embedded key-value database. It also includes offerings for visual design, orchestration, and execution of data integrations in on-premises, hybrid clouds, B2B, app-to-app, and IoT/edge interoperability scenarios. Its offerings address hybrid data challenges, including on-premise and cloud deployments, structured and unstructured data, transactional and analytic applications, real-time and low-latency updates, historical archiving, and edge-based deployment.
Going forward, Actian’s roadmap priorities include offering analytic and machine-learning technologies optimized in-database, mobile device, and IoT edge device deployments, as well as integration solutions for cross-domain data hubs. It has no plans to provide analytic apps, data science pipeline tools, or stream computing solutions.
Attunity. Attunity is an established provider of application infrastructure and stream processing solutions for enterprise deployment. The company targets large enterprises with its solution portfolio, which are primarily for on-premises deployment, but also work in Azure and AWS public clouds.
Attunity’s flagship offering is Attunity Replicate. This data integration solution—geared to enterprise data warehousing and data lake scenarios–moves structured or unstructured data between heterogeneous source and target systems while preserving transactional consistency. The solution, which leverages change data capture (CDC) technology and requires no footprint on source systems, can move data to and from application or analytic databases in near-real-time or in batch mode. It can also move data in near real time to stream processing platforms such as AWS Kinesis, MapR Streams, Azure Event Hubs, and Kafka. The Attunity Compose product provides ETL to make sure that structured data is prepared for consumption in the target systems.
Attunity has close partnerships in the public cloud (Microsoft, AWS), Hadoop distributions (Hortonworks, Cloudera, MapR), professional services (Accenture, Cognizant), and stream computing (Confluent). Its roadmap calls for it to enhance the multi-step data-preparation capabilities of its CDC technology, including greater application of rich workflow, metadata, profiling, ACID transactionality, and machine learning in this process.
AWS. Amazon delivered the first AWS services, Amazon S3 object storage and Amazon EC2 VMs, in 2006. As with Azure and Google Cloud Platform later, AWS’s services originated from what Amazon the parent used to build its own services. Today there are well over 100 first-party AWS services with a revenue run-rate of over $20bn. AWS’s operating profit is greater than what Amazon earns on all its $178bn in revenue. Enterprise spending on different types of cloud computing will top $750bn globally by 2026.
The evolution of AWS’s services has been very rapid. The original Amazon EC2 compute service now has dozens of instance types from general purpose to compute-optimized, memory-optimized, GPU-accelerated, and FPGA-accelerated. AWS has moved aggressively to add the very latest GPUs to support ML and AI workloads. The EC2 P3 instances offer the latest NVIDIA Tesla V100 GPUs with up to 8 GPUs per node. AWS claims this high density is 1.8x-2x better in price/performance and 6x better absolute performance than GPU instances from any of the other cloud vendors.
AWS has also moved to progressively higher abstraction layers for core compute services. AWS has had Docker container support for several years but added Kubernetes orchestration last year in recognition of Google’s having established Kubernetes as a standard. Several years ago AWS moved compute up one more layer with serverless compute services that execute as event handlers in AWS Lambda. More and more services are accessible via Lambda calls, including databases. AWS has offered its own version of Hadoop, Amazon EMR, with S3 serving as the data lake. AWS has targeted EMR at the devops audience and it features programmatic access to large data volumes. For more conventional SQL-based access, there is the Amazon Redshift data warehouse, which recently added support for separately elastic S3 storage with the Amazon Redshift Spectrum feature. Somewhere in between EMR and Redshift Spectrum is Amazon Athena, which is a serverless query service accessing data in S3 based on Presto. Presto originated at Facebook, which built it as a successor to Hive for SQL access to data with schema-on-read. AWS launched its Machine Learning service in early 2015 and at re:Invent 2016 launched pre-trained models for text to speech with Amazon Polly, image classification and recognition with Amazon Rekognition, and conversational bots with Amazon Lex (in preview). At the same time, AWS also launched Deep Learning AMIs, which are EC2 instances pre-installed with a variety of deep learning frameworks. At re:Invent 2017, AWS introduced SageMaker, a fully-managed service that enables data scientists and developers to build, train, and deploy machine learning models. It builds on the earlier efforts to further simplify the AI and machine learning process.
Looking forward, we expect AWS to continue a focus on enterprise cloud experience, migrating data and workloads, and integrating services to simplify building and operating workloads. For example, while customers can deploy and manage their own streaming data solution with Apache Kafka for hybrid or cloud-only continuous data processing, they can also use AWS’s Kinesis as a fully managed service. Another design pattern, which is fast becoming a leading-edge technique, is to integrate different services and workloads with a stream processing hub which acts as a near real-time single source of truth. The growth of edge-based intelligence with the rise of IoT has created an impression among many that the cloud computing wave will crest before its vendors recoup their massive capital expenditures on data centers. While most run-time inferencing and some model training will happen at the edge, the supervised training and redesign of models will likely take place in the cloud. That edge vs. cloud division of labor will increasingly be data-intensive on the edge and compute-intensive in the cloud. As with Azure and GCP, expect to see more services that take advantage of the cloud vendors’ global infrastructure. AWS introduced Global Tables for Amazon DynamoDB, which enables multi-region, multi-master tables for fast local performance for globally distributed apps. We also expect AWS to continue to open up to customer workloads more of the machine learning for IT operations and application performance that it uses internally for its own services. These operational services should continue to improve the TCO of cloud workloads relative to on-prem equivalents.
BMC. BMC is a long-time incumbent in enterprise system and workload management. Among other functions, its Control-M offering allows enterprises to instrument complex, data-rich applications with workload and delivery automation across the lifecycle, reducing the need for expensive automation retrofits. The tool provides a single point of control for enterprises to reliably automate batch and streaming jobs in data management pipelines. It enables secure scheduling, instant status visibility, and automated recovery on file transfer operations. It supports automated ingestion, enrichment, modeling, analysis, and other machine learning pipeline functions.
Control-M enables rapid application changes and deployment cycles in data management with through a “Jobs-as-Code“ DevOps capability. It exposes a REST-based API for coding job flows in JSON and committing them to a DevOps source repository. It includes a workbench for building test workflows and passing jobs-as-code as reusable assets so that developers can build and test them in modern application pipelines. The Application Integrator tool enables any application that can be accessed via API or CLI to be integrated with data management workflows in Control- M.
The solution provides integrated control over these functions running in mainframe/host environments; Spark, Pig, Hive, Hadoop and other big-data platforms; AWS and Azure public clouds; and hybrid clouds. BMC has partnerships and certified integrations with Cloudera, Hortonworks, and MapR. BMC’s Control-M roadmap is focused on both supporting new big data tools and deeper integration with leading public clouds.
Cloudera. Cloudera is an established provider of a modern platform for analytic databases, real-time operational databases, data engineering and data science solutions for machine learning and big data analytics. Based in Palo Alto CA, it is one of the principal vendors in the early commercialization of Hadoop, but it has diversified well beyond that core market over the past several years as it expands its solution footprint in enterprise customers worldwide.
Cloudera’s flagship enterprise solution offering is Cloudera Enterprise Data Hub. This solution is an integrated offering that includes Cloudera Enterprise, which is its core platform components with enterprise-grade management, security, and governance tooling, and premium enterprise support. In addition, it includes Cloudera Analytic DB (to support BI, SQL query, exploratory, ad-hoc, and batch workloads, via Impala, Hive, and the Navigator Optimizer), Cloudera Operational DB (which includes Kudu, Spark Structured Streaming, and HBase in support of online real-time, low latency, and hybrid transactional analytic applications), Cloudera Data Science & Engineering, and Cloudera Shared Data Experience. The latter is a cross-product multi-cloud abstraction layer that incorporates the Cloudera Navigator for data cataloguing, Cloudera Security for role-based cluster security, Cloudera Director for self-service cluster provisioning and scaling, Cloudera Governance for shared governance, lineage, and auditing, and Cloudera Manager for workload management.
In recent years, Cloudera has aggressively moved into the data-science pipeline tooling segment. It offers Cloudera Data Science Workbench, which supports collaborative, self-service development, training, and deployment of machine learning models in the enterprise. Going forward, Cloudera plans to provide all of its solutions as managed platform-as-a-service cloud offerings. It currently is introducing a managed data-preparation service, Cloudera Altus, which supports data ingest and ETL workloads in Microsoft Azure and AWS. Other priorities in its roadmap are to expand self-service cloud access to all of its solutions, support a wider range of public and private cloud deployments, and provide deeply integrated support for both Kafka and Spark Streaming as real-time streaming options throughout its portfolio. It will continue to offer industry solutions alongside technology alliance and channel partners, with a core focus on security, financial services, IoT, healthcare, and genomics use cases.
Confluent. Confluent provides a streaming platform based on Apache Kafka®. It was founded in 2014 to provide a distribution of Apache Kafka, which the core team created while at LinkedIn. The team designed Kafka to address the increasingly complicated data flow within enterprises. The trend toward real-time stream processing as an enterprise’s core backbone goes well beyond the growth of big data and analytic applications and platforms and the skyrocketing adoption of mobile, embedded, IoT, edge, microservices, and serverless computing. Confluent’s ultimate opportunity is to become the real-time single source of truth in the enterprise. Many used to see Hadoop serving that purpose. But it never was able to live up to that promise: aside from complexity, the data lake at the core of Hadoop is a reservoir of historical data that feeds batch processing. Actionable insights are perishable so data from as many sources as possible should pass through a single hub to as many targets as possible. And this continuous processing should work in near real-time. In this respect, continuous processing is becoming a peer processing model to batch and request-response.
Kafka is a fast, scalable, and distributed platform for continuous processing. It reinvents the old message queue category with a distributed commit log, a publish-and-subscribe topology centered on an elastically scalable hub, and provides durability where the user chooses the extent of the history to store. The increasingly sophisticated stream processing is building on this foundation.
Confluent’s solution, like many hybrid open source products, builds on the Apache Kafka distribution. In addition to the core open-source Kafka, the Confluent Enterprise solution offers tools for working with Kafka at scale, including monitoring, replication, data balancing, etc. under a subscription license. The Confluent Cloud offering provides Kafka as a Service on AWS.
As a streaming platform, Apache Kafka provides low-latency, high-throughput, fault-tolerant publish and subscribe pipelines and is able to process streams of events. Kafka provides reliable, millisecond responses to support both customer-facing applications and connecting downstream systems with real-time data. Kafka’s Streams API and KSQL language will continue to get more powerful for continuous processing in business applications and ETL pipelines. However, we don’t expect Kafka to extend to AI and ML model training. Rather, we expect Confluent to leave the data science to Spark, Flink and others. Kafka is more likely to be positioned as a core component of a pipeline where already trained models can be deployed for inferencing. Kafka’s stream processor doesn’t require its own cluster, so it offers many more deployment options than Spark, for example. It can be embedded as a library in just about any devops pipeline.
New programming paradigms are slow to emerge because of the weight of legacy systems and skills. But`streaming workloads as part of continuous processing applications are emerging as a new programming model that will take its place next to the traditional batch and request/response models over the next decade. Confluent Platform is one of the core contenders for that role in enterprise computing.
data Artisans. data Artisans provides a stream processing platform. It is the principal vendor commercializing Apache Flink, an open-source codebase that originated in 2009 by the company founders and became an Apache project in 2014, around the same time that data Artisans was founded.
data Artisans’ dA Platform manages streaming and batch processing using a common programming model The platform, which is delivered as licensed software, runs natively on any Kubernetes based platform. It supports forking of live streaming Flink apps and replaying of streams using historical data, thereby guaranteeing strong data consistency. Developers build stateful streaming apps for deployment to Flink, with the platform able to process millions of events per second and save up to terabytes of live state. The platform supports metrics, logging, and operationalization of live data streams. The platform manages the lifecycle of Flink apps in production. Developers can take snapshots of running apps, start new code from those snapshots, guaranteeing consistency, and integrate with DevOps tools from third parties.
Going forward, data Artisans stands to benefit from the trend toward real-time stream computing as the core backbone of most BDA solutions, platforms, and apps, which is due to the skyrocketing adoption of mobile, embedded, IoT, edge, microservices, and serverless computing. To avoid having its growth prospects limited, it will need to add the following features, among others: robust governance of streaming data and AI to accelerate the handling of non-standard data types in real-time pipelines.
Datameer. Datameer is an emerging provider of analytic data infrastructure. It provides a platform which allows organizations to create business-led data pipelines that feed analytics-ready data to business teams. The Datameer platform provides facilities for data profiling, cleansing, preparation, and exploring data, and then taking the resulting pipelines and operationalizing it to deliver curated data to the customer’s visualization, discovery and data science tools.
Datameer’s solution offers a business analyst-friendly interface with an interactive spreadsheet-like metaphor for defining data manipulation, transformation and preparation functions, and a visual exploration metaphor to discover analytically interesting aspects of the data. It allows users to chain together several worksheets with transformations to create a programmatic pipelines that work on full datasets, not just an interactive samples. The pipelines can then be productionalized to execute jobs at scale and keep analytic datasets fresh. Once final analytic data sets are created, results can be exported to Hive and Presto as data marts, or existing BI tools such as Tableau, PowerBI or Qlik for further discovery and visualization.
Datameer’s customers primarily deploy it on-premises. Approximately 10% of Datameer customers use the platform in the cloud on AWS or Microsoft Azure, but the company expects this segment to grow significantly moving forward. On AWS, the platform has separated compute from storage enabling a elastic, on-demand architecture. It integrates with native AWS services including EMR, S3, and Redshift and other cloud data warehouses like Snowflake.
The solution ingests data from more than 70 structured and unstructured data sources, including cloud file systems, data lakes, transaction processing systems, enterprise data warehouses, and master data management systems. Advanced enrichment and organization features help customers to prepare data for more advanced time series, graph, segmentation, behavior and data science analytics. The platform provides deep facilities for securing and governing data including role-based security, masking, encryption, and data lineage.
Datameer’s roadmap calls for three major initiatives: (a) further integration with public cloud providers to become a cloud-first architecture, (b) deepening cataloging, security and governance capabilities, including integration with data catalog and governance solution providers, and (c) providing a scalable, unconstrained, open query engine for any 3rd party BI and visualization tools to work with analytic data managed by Datameer.
Dremio. Dremio is a startup provider of analytic applications for data discovery, enrichment, visualization, and exploration. Dremio illustrates the important theme of big data solutions unbundling the RDBMS. It is trying to reinvent 1) the role of the system catalog, 2) thea federated query optimizer, and 3) some parts of the storage engine. Its flagship solution supports live access from any BI tool or advanced analytic tool (via SQL, Python, or R) to access data wherever they reside. It hides much of the complexity of where and how data was stored and enables users to discover, curate, and share collaboratively.
Leveraging Apache Arrow, Dremio’s solution organizes data into an efficient, language-independent, in-memory columnar format. It accelerates queries automatically and can run on anywhere from one to more than a thousand nodes in federated data environments. It runs in containers, on dedicated infrastructure, or in the customer’s Hadoop cluster. It provides native integrations to RDBMSs, NoSQL databases, Hadoop distributions, AWS S3, and other data platforms. It can run on dedicated infrastructure or, via YARN, in the customer’s Hadoop cluster. It incorporates a cost-based query planner and supports native pushdown of optimized query semantics for each data source. Users can visualize how their data is queried, transformed, and joined across sources. They can analyze data lineage across all data sources and all data pipelines.
Dremio’s roadmap calls for future releases of its flagship offering to incorporate machine learning, store data to accelerate queries going through its engine, figure out when the data dictionaries of underlying data stores change and update itself automatically, add its own SQL “studio” for simpler creation of queries across dissimilar databases, and get better high-availability capabilities and the ability to run across cloud and on-premises data sources.
FogHorn. FogHorn Systems is a provider of analytic applications, application infrastructure, and stream computing for closed-loop device optimization at the IoT’s edge. It has optimized its solution for industrial use cases in manufacturing (e.g., yield and failure detection); oil and gas production (e.g, detect flare conditions); and smart cities (e.g., building optimization, elevator maintenance, and energy management).
FogHorn’s offering drives real-time advanced analytics in resource-constrained edge devices in industrial settings. Its offering combines cloud computing, high-performance edge gateways, IoT systems integration, real-time stream processing, and onsite big data. It includes a graphical tool for composing the complex event processing that ingests, cleanses, enriches, and aligns data before feeding it into a machine learning model for inferencing.
FogHorn’s solution can retrain ML models based on local results. It provides the option of pushing all retraining data to the cloud and can update tens of thousands of edge devices with a revised model. This approach is suited to use cases in which global context is valuable for retraining and also when deep learning models might be too resource-intensive for local retraining on constrained edge devices.
Google. Google Cloud Platform is Google’s offering to compete with Amazon’s AWS and Microsoft’s Azure. Google traditionally treated enterprise-focused products and services with little priority. Its consumer services had powered almost all of Google’s $110bn in revenue in 2017 and a market capitalization of $750bn. But the company realized its consumer services might pale in size relative to an enterprise-focused cloud platform that could be worth hundreds of billions in annual revenue.
Many of Google’s cloud platform services originated from the infrastructure the company built to run its own consumer services. Deriving the early platform services from Google’s own consumer services meant they tended to be optimal for world-class developers using leading edge programming techniques at global scale. The company recalibrated its approach in the several years under new management of the enterprise business. Now there are many more prosaic cloud platform services that are more familiar to enterprise developers. These services include BigQuery, a data warehouse, Cloud Spanner, a SQL RDBMS that offers full availability and transactional consistency on a global scale, Kubernetes orchestration of containers, Cloud Dataflow, which enables unified process of batch and streaming data, Cloud Dataproc for managed Hadoop and Spark, API management, and increasingly powerful AI tools and services. What distinguishes the current Google Cloud Platform is that these services are all serverless. In other words, GCP hides the underlying infrastructure, whether compute, storage, or network, from developers and administrators. Its competitors still have many of their offerings in virtual machines or containers.
Looking forward, Google is likely to differentiate its cloud platform with ever more accessible machine learning capabilities and with a large professional services group staffed with as many data scientists as Google can hire. On the accessibility front, like Azure and AWS, Google offers pre-trained machine learning models in areas where it can leverage the data from its consumer businesses. These include NLP, speech, image and video processing and recognition, and others. There is a major skills gap between using these pre-trained models and building one from scratch. Cloud AutoML is the first service that starts to simplify this process. Developers with limited ML knowledge take the pre-trained models and upload their own training data to customize the existing models. The addition makes it possible for an apparel maker to enable image searches based on attributes for which Google never trained its models, for example. Google is aggressively hiring data scientists to help less skilled customers apply AI and ML. Other priorities include major investments in integrated performance across the entire machine learning stack from the AI tools and services to the data management and the use of Cloud TPUs (Tensor Processing Units, which are ASICs for AI acceleration.
Hortonworks. Hortonworks is a provider of data platforms that enable companies to extract insights from big data while it is at rest and in motion.
Hortonworks’ original product is the Hortonworks Data Platform (HDP), which is a secure and enterprise-ready open source Apache Hadoop distribution. HDP uses HDFS for scalable and fault-tolerant big data storage and YARN for resource and workload management. HDP delivers a range of data processing engines including SQL, real-time streaming, batch processing and data science among others, to interact simultaneously with shared datasets in private, public, or hybrid big-data multi-clouds environments.
Also central to its product portfolio is Hortonworks Data Flow (HDF) for data-in-motion and real-time streams, powered by Apache NiFi for flow management, supporting Apache Kafka and Storm for stream processing and Hortonworks’ Streaming Analytics Manager (SAM) for Complex Event Processing (CEP), pattern matching and predictive analytics. Furthermore, Hortonworks DataPlane Service (DPS) is fundamental to its management of distributed big-data in multi-cloud and on-premises environments incorporating data at rest and/or in motion. DPS also incorporates a pluggable architecture which provides the foundation for its own and partner services. These extensible services include Data Lifecycle Manager (DLM), a disaster recovery and replication service and soon to be released Data Steward Studio, a data governance service. DPS leverages open source projects Apache Knox, Apache Atlas and Apache Ranger for single sign-on, security and data governance.
Hortonworks is increasingly taking a solution approach in its go-to-market strategy. It provides Hortonworks Solutions as bundled offerings for specific workloads in enterprise data warehouse optimization, cyber security and threat management, internet of things and streaming analytics, data science, and advanced SQL. Hortonworks’ primary vertical industries are banking, insurance, and automotive. Partnerships are a big part of Hortonworks’ go-to-market strategy. It resells IBM Data Science Experience (DSX) as its data science workbench and IBM Big SQL as its own SQL-over-Hadoop offering. IBM, in turn, is reselling Hortonworks Data Platform in lieu of its own deprecated Hadoop offering. Microsoft has OEM’d HDP as the heart of its Azure HDInsight public cloud service. Furthermore, HDP is delivered and sold via the AWS Marketplace, coming out of the box with support for S3 connectivity and a shared Hive metastore. In addition, Hortonworks’ Cloudbreak offering simplifies deployment, provisioning, and scaling of HDP in AWS, Azure, and Google Cloud Platform.
IBM. IBM has been providing data scientists with tools, cloud solutions, and professional services for years. IBM offered a version of Hadoop to support data engineers and data scientists who wanted to work with data sets effectively without limitations on size. Since then IBM created SPSS Analytic Server where data scientists can push the modeling process into Hadoop. IBM also re-engineered introduced Db2 Big SQL to work on a data lake to compete with all the products that were trying to combine the best of data warehouses and data lakes. IBM has been making its Watson AI and ML technology more accessible to developers and data scientists after introducing it as a research project in 2011, when it beat the best Jeopardy contestants. Machine learning capabilities are delivered to data scientists and others in a variety of ways: as consumable cloud services, and as native capability on our Z and on our Power Systems servers.
Today, IBM positions the SPSS Modeler as a tool for visual data science for people who would prefer to create models without code. It is ideal for analytics developers who have been in the industry for decades and might not have formal data science training beyond statistics. By contrast, it targets Watson Studio on public cloud and Data Science Experience (DSX) on-premises to younger developers who have data science training. This audience is typically comfortable working with models and data in Jupyter notebooks using Python, Scala, and R. Watson Studio also features software to allow data scientists to more easily access Watson AI services. For teams who have both types of people, IBM is introducing an integration of SPSS Modeler into Watson Studio/DSX Local.
Iguazio. Iguazio is a startup provider of stream computing, analytic database, and application infrastructure for hybrid big-data multi-clouds. Its go-to-market approach involves partnering with system integrators, value-added resellers, server OEMs, and co-lo operators. Most of Iguazio’s customers are large enterprises that deploy data workloads into the cloud. Iguazio customers are in a wide range of industries, including automotive, healthcare, manufacturing, retailing, cybersecurity, surveillance, government, financial services, and telecommunications.
Iguazio’s solution is a streaming data analytics appliance that is designed for premises-based deployment. The appliance is configured with flash solid state drive, low-latency storage-class memory, a unified data model, an embedded database, and a serverless runtime architecture. It can perform a wide range of data manipulation, machine learning, and analytics functions in real-time streaming environments. It executes stateful event-processing workloads that are accessible through AWS Lambda serverless APIs. Developers can programmatically trigger per-event ETL, ML/AI inferencing, and database manipulation functions that execute on the appliance. The appliance is capable of real-time performance in millions of operations per second with sub-millisecond latency and event-driven analytic processing.
The company’s roadmap calls for continued development of its serverless Nuclio technology, addition of more serverless functions (e.g., Spark, TensorFlow) to its appliance, incorporation of Kubernetes pipeline orchestrations into its architecture, deployment of more appliance functions to IoT/edge nodes, packaging of appliances for more capacity/performance profiles, and enhancement of the product’s multi-tenancy, high-availability, disaster recovery, and data synchronization capabilities.
Informatica. Informatica is a provider of data management solutions for over 7,000 organizations worldwide. The Informatica Intelligent Data Platform™ powers applications and analytics for IT and business users through cloud, on-premises and big data solutions. Hundreds of ISV, SI, and channel partners build on Informatica in the cloud and on-premises.
Informatica’s product line is a natural extension of their original ETL and master data focus. Wikibon has highlighted the emergence of a new generation of data catalog that has to exist in a world of analytic data pipelines comprised of the emerging “unbundled” DBMS. The new data catalog has to manage the metadata about data stored in the many systems that make up the new data pipelines. In Informatica’s take on the category, there are four capabilities. These include analytics, hybrid cloud data management, master data management, and governance and compliance.
Informatica’s data platform supports data engineers, data scientists, data analysts, and data stewards to leverage AI-driven metadata services to uniquely collaborate on common data pipelines, both batch and streaming, within a common business understanding of data. Informatica enables data discovery via AI-driven classification and clustering algorithms. These capabilities enable organizations to deliver enterprise cloud data management for hybrid environments while enabling users within the enterprise to turn any raw data into easily accessible and trusted data assets, in the cloud or on-premises.
Intel. Intel was founded in 1968 and maintains headquarters in Santa Clara, CA. The company currently has $62bn in annual revenues, approximately 100,000 employees, and designs and manufactures leading-edge processors, networking, and storage semiconductors. In analytics and AI, Intel has formidable strength in server processors, and has been making acquisitions to build its AI portfolio across a range of market segments, including MobileEye (machine vision), Movidius (visual processing), Nervana (deep learning), and Altera (FPGAs). Intel’s stated goal is to provide AI solutions in the device, network and data center, and has chalked up major public wins at leading cloud providers like Microsoft, Alibaba, JD.com, and AWS, and is also extremely active optimizing open source AI tools and frameworks for developers. Intel competes in analytics and AI segments with vendors including ARM, Nvidia, IBM, and AMD.
MapR. MapR is an established provider of an enterprise data fabric and converged processing capability marketed as a Converged Data Platform. The solution includes a data science pipeline, stream computing, application infrastructure, analytic database, and an application database.
MapR processes and persists all data—including streams–in a distributed platform that can process and analyze it all at scale and in real time. The core of its portfolio is a scalable converged fabric that executes in-place machine learning and analytics, as well as archiving and protection, on big data from all sources. It can be deployed in a small footprint edition on IoT endpoints, as well as to public, private, and hybrid cloud environments. Supplementing this is MapR’s high-performance NoSQL multi-model database for operational, analytical, streaming, and other workloads.
For integration across its data fabric, MapR provides a global publish-subscribe event streaming platform. Its management console supports administration of the fabric, including tiering of data transparently to users and managing compression and multi-temperature storage policies across the fabric. And its data science refinery enables ML development, real-time exploration, and secure model storage in real-time DevOps environments. Leveraging Zeppelin notebooks, it can run ML models, external modeling and training tools (e.g. H2O.ai), and execute them directly on a MapR node in containerized fashion.
MemSQL. MemSQL is a startup database provider that handles transactions and analytics in one place for real-time applications. It remains one of the premier providers of scale-out “NewSQL” DBMSs to support hybrid transaction and analytical processing. It runs on AWS, Azure, and GCP. It has partnerships in BI (Tableau, Zoomdata, Microstrategy), ETL/streaming (Informatica, Attunity, Confluent), and data collection (OSI software) segments. Its customers are a mix of finance, media, energy, public sector organizations as well as growth companies building greenfield application architectures and other sectors.
MemSQL’s flagship solution, currently in version 6, provides an in-memory SQL DBMS capable of deployment on-premises and in the cloud. It can disarticulate and arrange semi-structured JSON documents into separate columns. It supports real-time ACID transactions in its row store and real-time analytics at low latency in its column store and with very high throughput. It can scale out horizontally to hundreds of nodes, can scan a billion rows per second per core, supports stored procedures, and scales to thousands of concurrent users. It supports full SQL queries against both structured and unstructured data; executes vectorized queries for ultrafast performance; ingests JSON objects as a native unstructured data type, includes stored procedures, and can operate on compressed data. It can persist data in memory or on-disk storage and supports ingest of streaming data directly from Kafka. It can move data to a flash SSD-based column store for large-scale analytics in 10s of terabytes in memory and several petabytes on disk. The solution is delivered as licensed software that customers may deploy in their data center, the cloud of their choice, as a managed service, and on laptops for test and development purposes. It can run in Docker containers for on-premises and cloud environments and supports Spark as a transformation and analytics engine for streaming and batch analytics.
MemSQL’s roadmap focuses on adding support for continuous queries, embedding trained ML models for real-time scoring and training, augmenting its integrated, advanced analytics with user-defined functions and aggregates, and improving support for event-driven architectures and streaming analytics. Additionally, the company is keenly aware of the need to stay ahead of incumbent operational DBMS suppliers like Oracle, Microsoft, and IBM. Each are working to incorporate in-memory capabilities and more sophisticated analytics in their core DBMS engines, but that will take time. Microsoft SQL Server, for example, doesn’t scale out to operate in a cluster. Oracle’s in-memory capabilities only extend to the equivalent of columnar indexes and its ability to scale out is generally very limited with write-intensive workloads. IBM, like Oracle, doesn’t support in-memory transactions. And SAP’s HANA still struggles with transaction performance because it has to transform rows into columns before it does any processing.
Micro Focus. Micro Focus is an enterprise software company focused on helping customers extend existing investments while embracing new technologies in a world of Hybrid IT. Providing customers with a portfolio of enterprise-grade scalable solutions with analytics built-in, Micro Focus delivers products for DevOps, Hybrid IT Management, Security & Data Management and Predictive Analytics.
Based in Newbury, U.K., Micro Focus offers the Vertica Analytics Platform. This platform is available as Vertica Enterprise, a columnar relational DBMS delivered as a software-only solution for on-premises use; Vertica in the Clouds, available as machine images from the AWS, Microsoft Azure and Google Cloud Platform marketplaces; and Vertica for SQL on Hadoop.
In addition, Micro Focus offers IDOL, an AI powered analytics platform that leverages machine learning and deep neural networks to automate and accelerate discovery of trends, patterns and relationships across text, video, image and speech data. Out of the box, it provides access to over 150 data repositories and support for over 1000 data formats, to enable 3600 insights for more effective decisions.
Microsoft Azure. Microsoft previewed “Windows Azure” at their developer conference in 2008. Microsoft wasn’t far behind AWS in launching, but its approach didn’t catch on as fast as AWS’s. Azure was initially a PaaS with a structured framework that enabled application development with that platform’s approach to design. Google also started its Cloud Platform with a structured PaaS, App Engine. Early cloud developers, however, were frequently building test and development workloads of software they would deploy on-prem. As a result, developers favored AWS’s unstructured approach that was closer to IaaS with VM appliance images of well-known on-prem software. As a result of developer preferences, AWS took a large and early lead. Windows Azure also limited itself to Windows-only workloads. When Microsoft changed its approach to “mobile first, cloud first” and eliminated Windows workload exclusivity, Azure accelerated to triple digit growth and hasn’t slowed down. Financial analysts estimate Azure’s revenue run-rate to be over $5bn, part of a $20bn commercial cloud that includes Azure, Office 365, CRM Online, and Enterprise Mobility.
For years, Microsoft has offered Hadoop and Spark as fully managed services in HDInsight, based on a distribution it licensed from Hortonworks. But, like AWS, it also offers more robust but proprietary services accessible via standard APIs. Azure Data Lake supports an HDFS API but can store individual files with sized in Petabytes vs. 5TB in S3 and with very high throughput reads and writes. With a schema-on-read repository, Azure Data Lake Analytics provides compute in the form of U-SQL, which is SQL with extensions for querying semi-structured data, R, Python, and .NET. Azure Stream Analytics is a serverless complex event processor that can target Azure SQL database and SQL data warehouse, the data lake, as well as PowerBI. As part of Microsoft’s cloud-first product strategy, it now builds SQL Server for Azure first, as Azure SQL Database. With each new cloud release, it gets ever closer to elastic scalability as well as functioning better in hybrid deployment scenarios with on-prem SQL Server. Like Google’s Spanner and AWS DynamoDB Global Tables, Microsoft leverages its worldwide infrastructure for its own multi-model, globally consistent and always available database with Cosmos DB. Like MapR’s converged data foundation, the database isn’t open source but it does support many standard APIs. Developers can use it for multiple data types: key value, graph, column family, and JSON. Developers can access it via multiple access methods: SQL, JavaScript, Gremlin, MongoDB, Cassandra, and Azure Table Storage. Azure also has a rapidly-expanding set of tools and services for AI and ML. Like AWS and Google Cloud Platform, it has a set of pre-trained models, called Cognitive Services, which build on data from its consumer Web services. Today there are more than 30 APIs in this service. Azure also has a Bot Framework for the rapidly emerging conversational chat UIs. Azure ML Studio gives data scientists who want to work with pre-built algorithms full lifecycle model design and devops pipeline. For data scientists who want to build their own algorithms, including on the most popular deep learning frameworks, Azure Workbench supports low-level design and deployment. Having fleshed out the design and deployment of cloud-based models, Azure now supports single-click deployment of models for inferencing at the edge with Azure IoT Edge. IoT Edge can run on devices with as little as 128MB of memory, which means it can support far more resource-constrained devices and gateways than most big data software providers.
Looking forward, we expect Azure to continue building out its services with a top-down engineered approach. Microsoft has always made its services build on and integrate with each other so that developers experienced as little impedance as possible. So we expect to see Azure emphasize lower TCO for admins and accessibility for developers. AWS, by contrast, more closely follows the Unix ethos, with many services that are more loosely integrated. Its focus is more on choice.
MongoDB. MongoDB is an established provider of application databases. It provides an open-source, non-relational document database with a scale-out architecture for handling semi-structured and machine data in data lake architectures.
MongoDB optionally provides its database offerings as managed services with elastic scalability, flexible DB schema, certified connectors to Spark and third-party BI tools, access to partners’ machine-learning platforms, and the ability to push data to where users are. It provides a wide range of community-built language drivers as well as a shell for CLI-based interaction and a GUI-based developer tool. In the core database product, it recently introduced the ability to lock down schema, to expose data change notifications for real-time event-driven applications, to guarantee cross-node read/write consistency.
MongoDB offers four versions of its flagship NoSQL database product, all of which share a common API. First, there is a downloadable open-source version of MongoDB. Second, its Atlas version runs as a service in the AWS, Microsoft Azure, and Google Compute Platform public clouds, with MongoDB handling all of the operational back-end responsibilities. Third, its Enterprise Advance version runs in the IBM and Rackspace cloud, and also comes with a commercial enterprise license for on-premises deployment; it includes the vendor’s 24×7 support and DevOps tooling. Fourth, MongoDB Stitch, currently in beta, runs as a service and provides a larger range of back-end application functionality, including a REST-like HTTP API and offers simplified programmatic access to third-party messaging, storage, and other application services provided MongoDB partners.
MongoDB monetizes its products by managing them as a service for enterprises. It has more than 4,900 customers worldwide, has seen 30 million downloads since inception, and has 800,000 developer registrations to its online university. It has professional services relationships with Infosys and Accenture.
Priorities in MongoDB’s roadmap include remaining focused on helping developers manage large data sets, rolling out an on-premises version of Stitch, and supporting replication across instances of MongoDB on two or more public clouds.
Oracle. Oracle introduced the first commercial SQL RDBMS in the 1970s, leveraging research from IBM luminary Ted Codd. It has spent all the decades since continuing to harden the database for mission critical applications, which it started building on its own in the 1990s. Starting in the 2000s as data types and volumes started to grow exponentially, Oracle used the highly profitable maintenance fees from the database’s installed base of customers to broaden its previously homegrown portfolio of enterprise applications. With that strategy, it has built a $200bn market capitalization and $37bn in revenue.
Oracle’s big data product line is based on the need to combine the expressiveness of its SQL implementation, mission critical stability, security, and manageability of its flagship DBMS with the radically lower price of Hadoop-based data management. Oracle customers can continue to use the familiar query capability of the core DBMS to access not just natively stored data but with transparent access to data in HDFS or a NoSQL database managed in Cloudera’s version of Hadoop that Oracle distributes. The integration provides the same security model, one click provisioning, and common console. Advanced analysis comes from the Oracle DBMS’s native implementation of R, spatial data analysis, and graph processing. The combination allows Oracle to maintain the price point of its traditional DBMS while accommodating the new data types and volumes of big data workloads. This big data SQL product can run on commodity hardware, on an appliance on-prem, or on an appliance in the Oracle Cloud.
Looking forward, Oracle is making big claims about its next version of the core DBMS, which it is calling the Autonomous Database. It claims it will make extensive use of machine learning to tune the database, elastically scale both compute and storage independently, and patch itself, all while remaining online. Oracle is also claiming that it will contractually commit to undercutting AWS Redshift by 50% for data warehousing workloads. The functionality sounds compelling, but the reality of the price guarantees will all be in the details. In any case, all these autonomous features should improve the big data offering because the core DBMS is the programmatic portal through which developers and admins get access to big data functionality.
ParallelM. ParallelM is a startup provider of data science pipeline solutions. Its tool provides a backbone for continuous, scalable, and repeatable management of live ML in operations. It provides collaborative tools for operationalization and governance of ML models. It supports full life-cycle visibility into these models’ behavior, performance, validity, health, and lineage tracking in production environments. It stores and tracks ML pipeline events for compliance purposes and can also store the inferences made by deployed models. And it can assign pipeline instances to underlying modeling physical infrastructures and to particular policies.
Qubole. Qubole is startup developer of a cloud-native big data platform that has the goal of enabling as many users as possible with analytics. It has over 200 customers, amounting to tens of thousands of users. Its customers are currently processing an exabyte of data every month.
Qubole delivers self-service analytics and managed Hadoop, MapReduce, Hive, Spark, Presto, Pig, Airflow, and Tensorflow, in addition to being able to plug-in emerging technologies. Its service runs in the AWS, Microsoft, and Oracle public clouds, with a Google Compute Platform cloud partnership in the works for 2018. Qubole also has a new relationship with Snowflake, under which Qubole’s Spark service will be able to read and write directly into Snowflake’s highly popular managed data warehouse service; this will enable joint customers to combine highly sophisticated AI/ML pipelines with the large volume of data that Snowflake databases can manage.
Qubole has designed its service for simplicity of access and management. It accelerates customer time-to-value by enabling business analysts, data engineers, and data scientists to get started with little if any administrator intervention and, through ML-based tooling, hiding much of the administrative complexity. It has engineered its offerings for independent scaling of compute and storage. It uses machine learning to make platform administration autonomous, with policy-driven elasticity and cluster management. It is the autonomous administration that delivers dramatically lower TCO.
SAP. SAP is an established provider of analytic application, data science pipeline, stream computing, application infrastructure, analytic databases, and application databases. It provides diverse solutions for both on-premises and cloud-based deployment, including but not limited to its own cloud PaaS managed service: SAP Cloud Platform.
SAP’s transactional application solutions fall into several line-of-business categories: ERP and digital core, customer engagement and commerce, IoT and digital supply chain, human resources, finance, and procurement and networks. Leveraging its leadership in enterprise applications, SAP has built one of the premier application integration, process, and infrastructure management portfolios. Going back many years, it leveraged its enterprise footprint to establish a strong position in the data warehousing and data mart segment, and now positions its portfolio as a platform for next-generation data lakes. Through strategic acquisitions and organic development, SAP has assembled a comprehensive set of enterprise information management solutions, encompassing information governance, master data management, data quality and integration, content management, and metadata management. In like fashion, SAP has built a substantial portfolio of enterprise business intelligence,v enterprise performance management, and data science pipeline solutions.
As as innovator, SAP was a first mover in the in-memory database arena, having made deep investments over many years to build up its SAP HANA product family, which now deploys in premises and cloud environments and is the foundation for many real-time application, machine learning, and advanced analytics solutions from SAP and its partners. And though it was slow off the starting block SAP has come on strong in big data in the past several years. Three years ago, it launched SAP Vora—which works in private, public, or hybrid clouds–leverages HANA’s structured-data orientation to provide an in-memory, distributed computing engine for OLAP, time-series analysis, and storage of both structured enterprise and unstructured Hadoop data. Two years ago, it launched SAP Cloud Platform Big Data Services, which provides a comprehensive Hadoop/Spark-based managed cloud offering for Hadoop and Spark with automated scaling and elasticity. Last year, it launched SAP Data Hub, which provides a premises-based solution for sharing, pipelining, and orchestrating data analytics in distributed environments, with centralized visibility and governance. Around that time, it also launched SAP Leonardo, its family of solution accelerators for rapidly prototyping big data, artificial intelligence, machine learning, blockchain, digital intelligence, and other microservices for deployment into cloud-native and edge computing environments.
SAS. SAS Institute is an established provider of analytic application, data science pipeline, stream computing, application infrastructure, and analytic databases. It provides these capabilities through enterprise licenses and through its own managed software as a service cloud offerings.
SAS provides power tools for data professionals Its data science, machine learning, statistical analysis, predictive modeling, data mining, data visualization, data application development, data quality, and data governance solutions are the heart of its product portfolio. Going back to the 1970s, it has established a huge worldwide customer base for its SAS/STAT, SAS Analytics Pro, SAS Enterprise Miner, SAS Visual Analytics, and SAS Visual Statistics offerings. Many of these customers use the vendor’s application infrastructure solutions ((Base SAS, SAS AppDev Studio, SAS Enterprise Guide, SAS Information Delivery Portal, SAS Grid Manager, SAS Studio) in their SAS deployments.
SAS has built a common user interface, a framework for sharing information and collaborating, and the ability to plug-in popular open source languages and libraries in addition to SAS’s own. It has a large ecosystem of trained consultants who can help customers build advanced applications that produce high value business outcomes. It has packaged and licensed its products for the new generation of data scientists working on advanced analytics and machine learning challenges for operational deployment. The Viya portfolio includes solutions for self-service, point-and-click access to visual tooling for statistical analysis, exploration, forecasting, optimization, investigation, decision management, event stream processing, data preparation, model management, data mining, machine learning, and natural language processing.
SAS’s solutions are frequently deployed into customer data management and analytics initiatives This drives a fair amount of demand for the SAS Customer Intelligence 360 tool to explore and manage this data and associated analytics. It provides a wide range of industry-specific analytic applications, as well as line-of-business analytic applications in fraud & security intelligence, IoT, personal data protection, risk management, small & midsize business, and supply chain intelligence.
All of SAS Analytics can be accessed through the language of the user’s choice, such as Java, Lua, and Python. SAS provides hooks into open-source methods to incorporate into the user’s data science pipeline. It is in the process of Dockerizing its offerings for containerized portability across platforms. Several customers have licensed SAS Analytics for Containers. Their roadmap calls for more multi-user, multi-container deployments of SAS offerings. They also plan to provide integrate SAS more deeply into pipeline running on and across Spark and Hadoop environments. They are also planning to expand the interpretability of deep learning models built in SAS, through Local Interpretable Model-Agnostic Explanations and other such frameworks. And they plan to expand automation of machine-learning pipelines executing on SAS platforms.
Snowflake. Snowflake is a provider of analytic databases and application infrastructure. It provides a managed, multi-tenant, multi-cluster cloud service for SQL data warehousing and data lake applications.
Snowflake’s service provides highly concurrent ad-hoc and production access to structured and semi-structured data. It manages all on-demand storage, compute, and optimization services for the user, completely separating storage and compute resources for independent scaling. It provides automated configuration, optimization, replication, online recovery, high availability, geographic redundancy, and encryption. It can support multiple elastic compute clusters accessing storage via a globally distributed catalog. Snowflake also enables live, secure sharing of data inside and outside the user’s organization without the need to physically move the data.
Snowflake enables flexible cloud storage with AWS S3 now, and Microsoft Azure soon. The customer doesn’t need a separate account on AWS S3. Through a new partnership with Qubole, Snowflake supports the creation and independent scaling of Spark clusters with secure connections, with Qubole managing the Spark pipeline that pushes analytic SQL queries down to Snowflake. Snowflake’s Snowpipe service enables it to ingest streaming data from Kinesis or Kafka via S3. Users can also explore data in S3. The service is available across multiple regions, and will be available across multiple clouds soon, with cross cloud/region identity federation, replication, and failover via a Global directory.
Splice Machine. Splice Machine is a startup analytic and application database provider. It provides a scale-out, elastic, and ACID-compliant SQL RDBMS that converges operational and analytical apps.
Splice Machine’s platform can be deployed on premises or in the cloud. It incorporates Spark and HBase, and integrates with many big data tools including Kafka and Spark Streaming. It embeds libraries for machine learning and predictive analytics to support both scalable data at rest and data in motion in a lambda architecture. It allows users to plug in other libraries, such as TensorFlow. It incorporates an OLAP engine that runs directly on Spark, while passing OLTP queries directly to HBase. All Spark and HBase CRUD operations are handled transactionally.
Users can pull data in from S3, create clusters on their AWS-based cloud services, and deliver results in Zeppelin notebooks that come with the Splice Machine platform. Developers can interact directly with Splice Machine using not only Java but also using Spark with languages such as Python or Scala. They can share their notebooks with colleagues through Splice Machine and pass around the notebooks offline, so that others can use them on their clusters. They can also switch to a personal mode and operationalize/run a Zeppelin notebook executing every night. The results can be pushed to a prediction table that can be used operationally. Alternatively, the ML pipelines can be directly run against new data in real-time.
Splice Machine’s roadmap calls for automatically storing data records in columnar format (for smaller storage and greater performance), the addition of disaster recovery features, support for active-active and active-passive backups across data centers, support for temporal data, the ability to store machine learning experiments as reusable apps; and deployment on Azure, Heroku, Google Cloud Platform, and Salesforce.com.
Splunk. Splunk was founded in 2003, well before Hadoop spawned much of the interest in big data. It has always focused on extracting business value from machine data, which is growing 50x faster than data about business transactions. Splunk’s approach to big data and machine learning is the antithesis of Hadoop’s approach. Rather than harness the innovation of several dozen semi-independent open source projects, Splunk engineered its pieces to fit together, simplifying the admin and developer burden of working with multiple components. Splunk’s revenues for the most recent twelve months totaled just under $1.2bn and its market capitalization is $14.5bn. With its 3,000-strong field organization, Splunk has solved much of the go-to-market challenge that other big data software companies are facing.
Splunk’s platform products are Splunk Enterprise, Splunk Light, and Splunk Cloud. Splunk also has a growing number of applications, called Premium Solutions, on top of the platform. Today, these are Splunk IT Service Intelligence, Splunk Enterprise Security, and Splunk User Behavior Analytics. The Splunkbase ecosystem has more than 1,500 additional applications, analytics, alerts, dashboards, and visualizations. The Premium Solutions are critical because they generate high fidelity alerts and minimize the typically overwhelming amount of noisy data flowing into advanced analytics platforms. For customers looking to build their own solutions on Splunk Enterprise, Splunk’s free Machine Learning Toolkit provides a guided experience with assistants and examples for building and deploying models. Splunk can make the modeling experience more accessible because the toolkit fits into an existing UI, application, and data storage framework in the core platform.
Looking forward, Splunk can continue to develop more Premium Solutions to address more use cases. Beyond the Premium Solutions, the ML Toolkit can also continue to make ML and advanced analytics more accessible. But Splunk likely won’t provide pre-trained models for the cognitive services that public cloud vendors are supplying. For those services, public cloud vendors have unique access to large volumes of consumer data. The next major set of use cases for Splunk to address center on IoT and business operations. With IoT, Splunk will need to support either edge-based data ingestion that extends to far more devices than its current data forwarding agents or it will need to be an easily accessible target for other edge-based solutions. Since the cloud vendors are increasingly supporting easier interoperability between edge and cloud analytics, we expect Splunk to invest in bringing its technology to the edge rather than leaving that to others.
Syncsort. Syncsort is an established provider of application infrastructure. It focuses on data infrastructure optimization, data availability, data access and integration, and data quality. Its flagship solution delivers mission-critical data from diverse, enterprise-wide data sources, including host-based mainframe systems to next-generation analytic environments. It delivers its products in a cloud-agnostic way so customers can deploy any combination of hybrid multi-cloud combinations.
In 2017, Syncsort made several strategic acquisitions to grow its solution portfolio beyond its traditional focus on data integration from host/mainframe systems to analytic environments and mainframe infrastructure optimization solutions. It acquired Trillium to deepen its data quality capabilities. It launched Data Management Express (DMX) to deepen its change data capture (CDC) into data lake capabilities in its DMX-h data integration software. It introduced new integrated workflow capabilities with DMX-h, with the ability to mix jobs running on different compute frameworks whether it is Hadoop MapReduce or Spark on the same data flow. This dramatically simplifies Hadoop and Spark application development, and allows easy integration of machine learning steps in the same flow. It also publishes data lineage in JSON form and provides REST APIs for customers to incorporate in own metadata environment, deepening integration with Cloudera Navigator and Apache Atlas. It also delivered Trillium Quality for Big Data, which integrates its Trillium data quality capabilities with Intelligent Execution (IX) technology from its DMX-h Big Data integration solution, delivering an agile, efficient and powerful solution that continuously improves the quality of massive data sets stored and processed in data lakes, bringing market leading enterprise data quality capabilities to data lake. It acquired Metron for capacity management, enabling a single view of data workloads across mainframes, IBM iSeries platforms, and multiple clouds. And it acquired Cilasoft, which specializes in compliance and security audit software for the IBM i platform (AS/400, iSeries, System i). Cilasoft moves data securely and publishes it into advanced analytic platforms such as Splunk.
Syncsort’s roadmap calls for extending their predictive maintenance capabilities for workload management; using supervised learning to generate data cleansing rules for execution in Trillium helping data stewards, in addition to their data integration and quality product; and making the full product portfolio cloud-agnostic in AWS, Azure, and GCP; and helping their customers operate in hybrid multi-cloud configurations.
Teradata. Teradata is a leading analytics and data solutions provider. The vendor’s core product is the Teradata Database, an enterprise offering that is optimized for high performance data warehousing and can be deployed on Teradata’s optimized IntelliFlex hardware, in Teradata’s cloud, or in AWS or Microsoft Azure. The same software runs on all the deployment options and is sold as a subscription with portable licensing. Teradata’s IntelliCloud is their premier as-a-service offering. This is a secure managed cloud service built on the Teradata Database and includes onboarding, system administration, monitoring, encryption and daily backups. It provides a managed service of Teradata Database regionally in Europe and the Americas; on AWS and Azure. Teradata also provides a rich set of add-in features, tools, and utilities for the database, including REST APIs, query acceleration, system management, OLAP connection, JSON integration, Python, columnar storage, intelligent memory, row-level security, secure zones, geospatial intelligence, backup and restore, data ingestion, workload management, and load/unload.
Due to be generally available in Q2 2018, Teradata Analytics Platform will converge Teradata‘s platforms, including its Aster analytics portfolio, allowing data scientists to execute a wide variety of advanced techniques to prepare and analyze data in a single workflow, at speed and scale. It will embed machine learning and graph engines, and incorporate TensorFlow and Spark. It currently supports Python, R, SAS, or SQL language access for data analysis. It will allow users to leverage their favorite tools such as Tableau, MicroStrategy, Informatica, Jupyter, RStudio, and KNIME. And it will allow businesses to ingest and analyze data types such as text, spatial, sensor data, CSV, and JSON formats, including support of Avro, an open-source data type that allows programmers to dynamically process schemas.
Transwarp. Transwarp, based in Shanghai, is one of China’s leading enterprise software companies. The founding team released a Chinese Hadoop distribution in 2011 as part of Intel’s Data Center Software Division. Intel made a strategic decision not to build a business that would be in conflict with its downstream enterprise infrastructure software partners and spun out the emerging division. The company raised 600 million Yuan (almost $100M) and has grown to over 300 developers, 85% of whom have advanced degrees. The company has about 1000 customers in more than 10 verticals, including financial services, energy, manufacturing, transportation, telecom, and public sector, etc.
While Transwarp is not a presence in Western markets, it is a leader in China and its product strategy is very much instructive for Western vendors because it addresses many of the limitations of the open source cohort of those peers. Transwarp doesn’t sell much open source software, it sells enterprise software where many of the products support industry standard APIs. In that respect, it is like MapR and Databricks, where both companies have greatly enriched Hadoop and Spark, respectively, but exposed them through industry standard APIs. For example, Transwarp forked Apache Spark to enable Structured Streaming to perform with 1-2 orders of magnitude lower latency than the 1.X version of the open source product. Ironically, Databricks also later developed their own implementation of Spark to deliver similar performance in their own PaaS implementation of Spark.
Unlike most big data vendors, Transwarp has a broad and deep product line that can substitute for most of the infrastructure stack sold by incumbent enterprise software vendors. The product line includes a big data platform that includes Transwarp’s own analytic database, streaming analytics engine, operational database, search engine, data science tools, and management and security products; a hybrid cloud analytic platform that uses docker and Kubernetes to provide multi-tenancy and elasticity while others are either still on YARN or struggling to separate compute from storage. Transwarp’s AI product goes well beyond its Western peers because it’s not just raw tools. It has some of the pre-trained models that make AI accessible to developers. Petro China serves ads to gas station customers by using image recognition to identify the make of a car and OCR to read the license plate. Another AI application that Transwarp itself uses manages the operation of their software as a cloud service. It allows them to scale operations independently of the number of admins. We expect the major public cloud vendors to follow this example in the future. Unravel Data already offers this technology.
Zoomdata. Zoomdata is a startup provider of business intelligence tools designed natively for big data. Zoomdata provides a visual analytics solution that is architected for near-real-time latency and fast interactive query performance against data sets of any size. Zoomdata’s solution is optimized with native connectors for Hadoop, NoSQL, streaming, and cloud data services. It supports interactive visualization and analysis against entire data sets without the need to move them into its own repository. It is built on Spark, executes in-memory in Spark clusters, is designed for embedding into third-party applications, and comes natively architected for cloud and on-premise deployments.
Zoomdata integrates stream and batch processing into a single front-end user experience. It does this by treating all data as a continuous stream, even if the data had been processed as batch in the back-end. It does this by turning a batch into a stream, progressively rendering it in greater detail so that end users don’t have to wait for the full data set to start visualizing. And it supports the following pluggable streaming sources: Kafka, Storm, Spark Streaming, NiFi, SQLstream, Streamsets, Zoomdata Smart Streaming, and Zoomdata Server.
Zoomdata knows how to intelligently leverage the native capabilities in Hadoop-based SQL and NoSQL databases, stream processors, and MPP SQL DBMSs in order to minimize data movement. It provides a cache so that further iterative queries work at the speed of its engine, not at the speed of re-scanning a file system. It supports play/pause/rewind so that actionable insights can be found dynamically, as things happen. And it supports smart pushdown processing into back-end data platforms for derived fields.
The vendor goes to market through a mix of traditional OEM as well as through direct sales and channel partners for stand-alone enterprise customers. It has partnerships with big-data analytics solution vendors (SAP, Cloudera, Informatica, Google), and global systems integrators (Atos Codex, Deloitte, Infosys). It has active resellers in North America, Latin America, Europe, Africa, and Asia-Pacific.


