
The road to agentic AI will be paved with stepping stones that progressively build on each other. Our research suggests that Agentic AI will not suddenly appear without a strong data foundation built on: 1) cloud-like scalability; 2) a unified metadata model; 3) data mesh organizing principles; 4) harmonized data and business process logic; and an orchestration framework that incorporates governance, security and observability.
While some believe the year of agentic AI will come to fruition in 2025, we predict bringing these capabilities together is a decade-long journey and there’s no shortcut on the yellow brick road to realizing agentic automation.
In this Breaking Analysis, we piece together previous research and point to a dramatic change in the enterprise software stack. We’ll explain how we see the journey playing out, the critical pieces of the emerging enterprise software architecture and the high value layers of real estate in that system that are still taking shape.
Background on our Research
Over the course of the past two years, we’ve been laying the groundwork for understanding the impact AI has on the enterprise software stack. We’ve tried to cut through the agent washing and highlight the pre-requisites for agentic AI success. We’ve discussed the progression of the data stack beyond separating compute from storage. And emphasized the importance of separating compute from data, underscored by open table formats like Iceberg and its potential unification with Delta. We’ve also discussed the need to unify metadata and the shift of control from the database to the governance layer and how that piece of the stack is opening up (think Unity and Polaris). This all builds on the work done early on by Zhamak Dehghani with data mesh as an organizational construct for breaking data silos.
Earlier this year our research focused on configurable business processes in the form of metadata, using the Salesforce data cloud as an example. And more recently, harmonizing not only data but also shared business logic with examples such as Celonis, Palantir and RelationalAI.
AI Needs a New Software Stack
AI is a catalyst and is disrupting an enterprise software stack that is five decades old.

Many believe this AI era is the most profound we’ve ever seen in tech. We agree and liken it to mobile’s role in driving on-prem workloads to the cloud and disrupting IT. But we see this as even more impactful. But for AI agents to work we have to reinvent the software stack and break down 50 years of silo building. The emergence of data lakehouses is not the answer as they are just a bigger siloed asset. Rather SaaS as we know it will be reimagined.
Two prominent CEOs agree. At the recent re:Invent conference we sat down with Amazon CEO Andy Jassy. Here’s what he had to say about the future of SaaS:
I’ll say supply chain is another area that we think we can be very effective and we have a lot of experience just like customer service there. But I also believe that AI is gonna open up all sorts of new SaaS opportunities and softwares and service opportunities. I’ve been saying this for a long time, I’ve told you guys this too, which is that I think every single SaaS company and application that we know of will be reinvented with what’s available in the cloud. And I think that’s doubly true when you think about what AI allows.
And Satya Nadella on the BG2 Pod recently went into some depth that we’re going to unpack. Here’s what he said:
The notion that business applications exist. That’s probably where they’ll all collapse, right? In the agent era, because if you think about it, right, they are essentially crud databases with a bunch of business logic. The business logic is all going to these agents and these agents are going to be multi repo crud, right? So they’re not going to discriminate between what the backend is. They’re going to update multiple databases and all the logic will be in the AI tier, so to speak. And once the AI tier becomes the place where all the logic is, then people will start replacing the backend.
Jassy sees cloud plus AI as the transformative catalyst and Nadella talks about multi-repo CRUD databases – which stands for Create, Read, Update and Delete. With the logic in the AI tier and when he talks about replacing the backend, Nadella, like Jassy envisions a sea change in SaaS.
What Nadella is talking about is really a 10-year vision without mentioning any intermediate steps on the way. Someday, we may have the technology to put all the deterministic rules and logic that constitute an application today into a non-deterministic neural network, in the form of an agent. We do not have that technology today. And so, there are many steps between where we are today and getting to the vision Nadella talked about, and we’re going to go through those.
What he’s saying, basically, is that we can “kneecap” every SaaS app and turn it into just its database schema. But if we do that, we’ll have another Tower of Babel, with a bunch of agents that don’t know how to talk to each other—even though the vision is that the agents can talk across the databases.
The Modern Cloud Data Stack is a Starting Point on the Journey
Let’s pick up from where we are today – the current modern data platform. A couple of years ago we started talking about the sixth data platform beyond the five modern existing data platforms typified by Snowflake and Databricks.
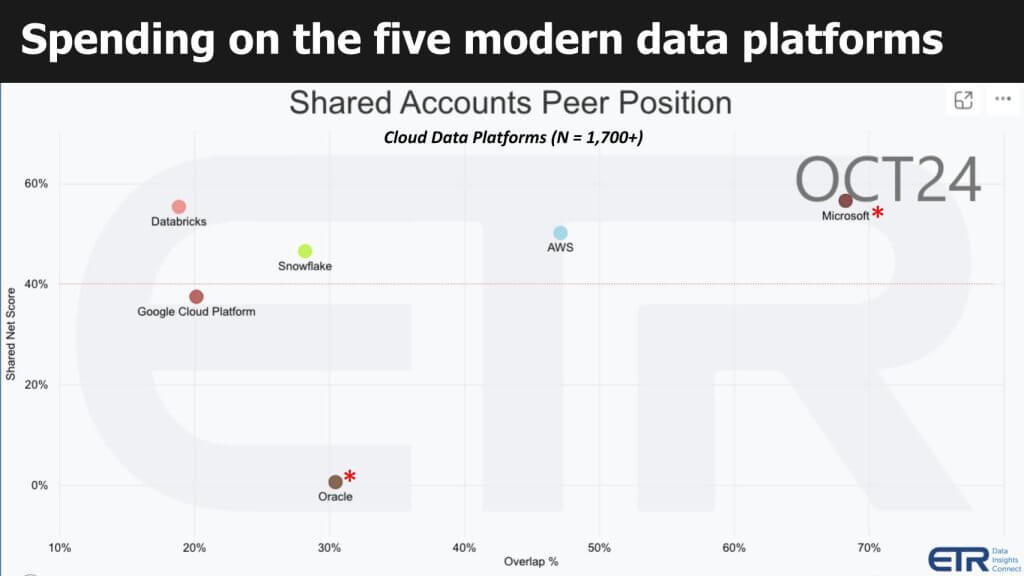
Above is data from ETR which shows Net Score or spending momentum on the vertical axis and Overlap or penetration into a data set of more than 1,700 IT decision makers on the horizontal plane. We’re plotting Snowflake and Databricks along with Google, AWS and Microsoft. We also show Oracle for context as the legacy database king. The red dotted line at 40% indicates a highly elevated Net Score. We annotate Microsoft and Oracle because they are in the data game but they’re not considered representations of the modern data stack per se. But we don’t want to debate that today…we show this because these are the players that are squarely in the mix of this transition. They have a lot to gain and much at risk.
The Journey on the Yellow Brick Road
As shown below the cloud data platforms are the starting point on our stroll down the yellow brick road.
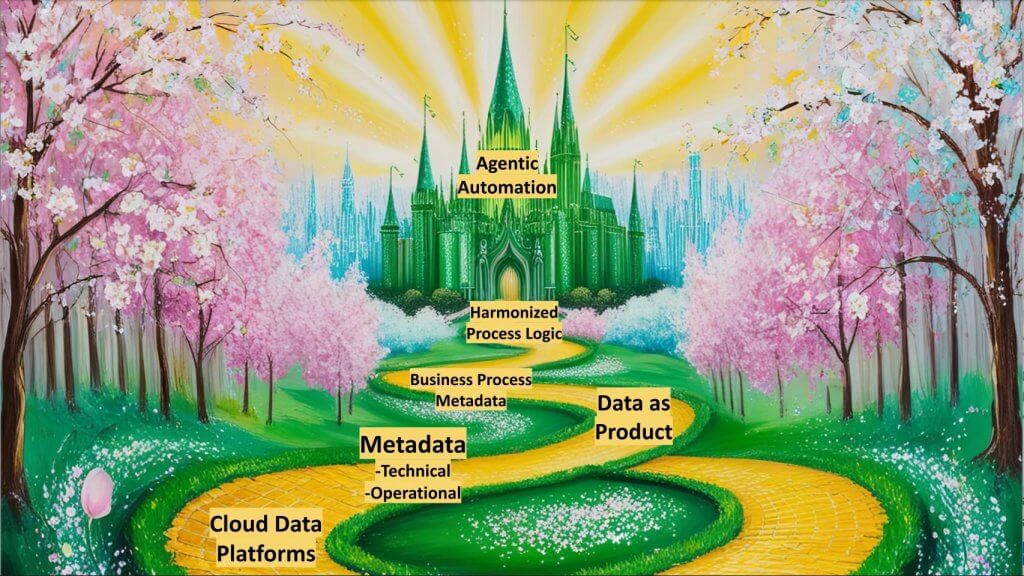
As reported previously, there is a shift underway from control at the database layer toward the governance catalog, shown above as the operational metadata. This shift begins to lay the foundation for a new application platform. Horizon from Snowflake and Polaris, its open source catalog, Unity from Databricks, and other established governance platforms like Informatica, Collibra, and Alation are all in play. Firms are thinking differently about organizing around data, employing concepts like data mesh and treating data as a product. They are leveraging information about people, places, and things in a distributed organization. The real excitement lies in the movement toward incorporating business processes and harmonizing both data and processes, enabling swarms of agents to work together toward a desired outcome.
The original cloud data platform—Snowflake—was among the first to separate compute from storage. Over time, the industry has recognized the need to separate compute from data. With the rise of open table formats (OTFs), multiple compute engines can access the same data. This requires separate metadata, including technical and operational details like lineage. Such metadata formed the foundation of data pipelines and created data products defining concepts such as “customer,” “product,” or “lead.” However, these constructs remain static entities.
To track a customer’s journey from engagement to prospect, then to lead, and ultimately to conversion, for example, current methods simulate the underlying business process using business process metadata. This provides a static representation that can be configured per customer, but only to a limited extent.
Salesforce’s Data Cloud stands out for customer data, representing Customer 360 and the entire customer journey in a harmonized way that supports analytics and applications. Instead of merely sharing tables, platforms share the concept of a customer and their journey. The next challenge is moving beyond a static metadata picture to sharing the business process logic itself across applications, enabling ultimate flexibility.
With harmonized process logic, agents can communicate across the entire Customer 360 and the customer journey, using a common language. Without this, agents must contend with scattered tables. An organization like JP Morgan might have 6,000 tables referring to “customer,” creating a modern Tower of Babel that does not function effectively.
This relates to the notion that the future may consist of numerous SaaS applications reduced to schemas, with thousands of tables referencing “customer” remaining disconnected. No current technology allows AI agents to harmonize such complexity independently. Symbolic harmonization is needed so agents can speak a unified language. This harmonized logic is crucial for achieving true automation. Perhaps in the distant future, it will be possible to discard this logic layer, but for now it remains out of reach.
The Shifting Points of Control and Value in the Enterprise Software Stack
Let’s take a look at how the enterprise software stack is changing as highlighted below.
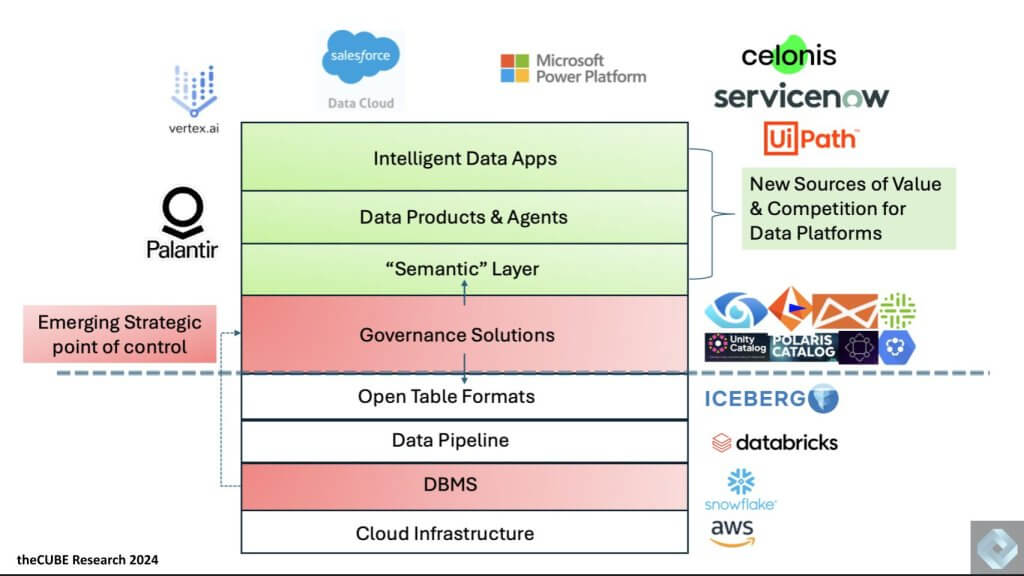
The concept shown above was introduced earlier this year. At the bottom of the stack, AWS represents the underlying cloud infrastructure, setting the stage for others like Google, Microsoft, and Oracle (with OCI) to join in. Snowflake popularized the separation of compute from storage, essentially providing infinite capacity as a cloud data warehouse. Databricks then focused on data science and data pipelines, influencing the shift toward open table formats like Iceberg. Databricks acquired Tabular and is now working to unify Delta and Iceberg. Amazon’s announcements at re:Invent around S3 tables and open table formats further underscore this trend, aiming for read/write capabilities and governance integration.
The key point, highlighted on the left side of the referenced chart, is the shift of control from the DBMS to the governance layer. This governance layer is increasingly open source, elevating the importance of what can be termed the “green layer.” This includes the semantic layer, which harmonizes data. However, as noted in previous research, the process now goes beyond data—it includes business logic and business processes. This is where the new source of competitive value emerges. Salesforce, Palantir, Celonis, and others are participating in this evolving ecosystem, creating a new competitive environment.
As previously emphasized, the data platform landscape was once dominated by the DBMS and its control of storage. The opening of the table format meant that the DBMS could no longer define the state of the tables if other engines were going to read and write to them. Control shifted to the operational catalog. Databricks’ Unity catalog, introduced in 2023, appears to be a strong contender here. Although there have been statements of direction around open sourcing Unity that are not fully realized yet, Databricks executes rapidly, and the unification of Iceberg and Delta is now expected sooner than we initially anticipated– perhaps as early as Q1 2025.
Snowflake’s Horizon catalog, the new source of truth for its ecosystem, still runs atop the Snowflake engine but synchronizes with Polaris. This allows governance policies set in Horizon to be applied to the open Iceberg ecosystem. The next layer up involves adding data semantics for concepts like customers, products, leads, and campaigns—the first part of the semantic layer. The far more challenging aspect is harmonizing processes, which requires changes to databases that have been decades in the making. Achieving this will pave the way for agents that can operate effectively in this new environment.
What the Software Stack Looks Like in the Future
Let’s paint a picture of what this stack looks like at a steady state.
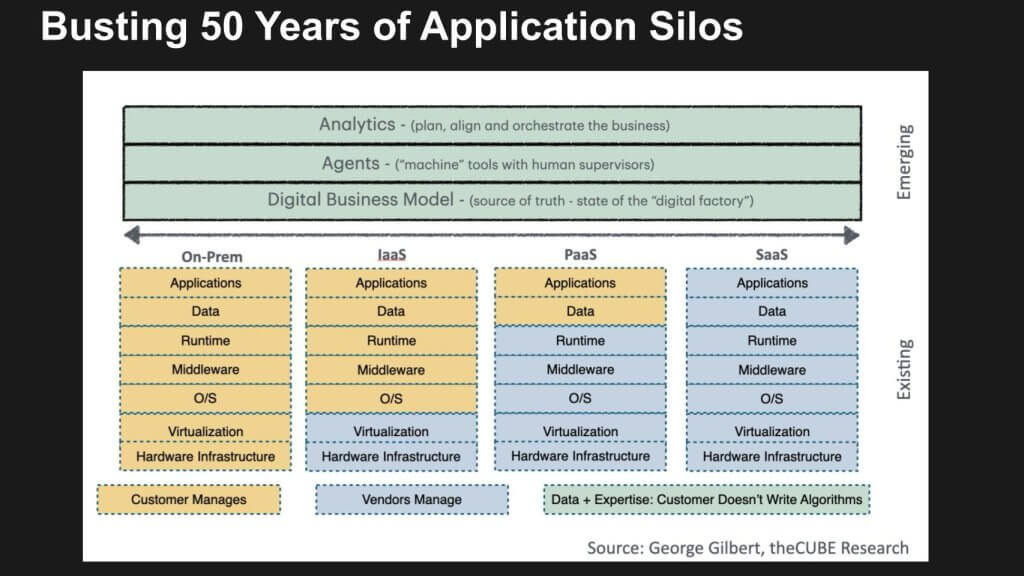
The evolution from on-premises environments to the cloud began with IaaS, which reduced much of the heavy lifting associated with infrastructure management. This progression continued with PaaS and SaaS, where more infrastructure activities—what Amazon calls “undifferentiated heavy lifting”—became managed services. However, the green layer at the top of the stack is where new value is emerging.
Three layers are shown above in the green: the digital representation of a business, a network of agents, and a new layer of analytics guided by top-down organizational goals. This structure enables the interpretation of goals and adjustments based on market changes or human guidance. The result is bottom-up outcomes driven by agents collaborating with each other and with humans, while taking action in a governed manner.
This new set of layers integrates the silos of applications and data built over the last 50 years. These silos can now be abstracted and turned into what Nadella described as “sediment.” Nadella’s viewpoint focuses on the data layer, while this perspective emphasizes the application logic layer that hosts the agents.
There is a clear business imperative behind this shift. We believe companies will differentiate themselves by aligning end-to-end operations with a unified set of plans—from three-year strategic assumptions about demand to real-time, minute-by-minute decisions, such as how to pick, pack, and ship individual orders to meet long-term goals. The function of management has always involved planning and resource allocation across various timescales and geographies, but previously there was no software capable of executing on these plans seamlessly across every time horizon.
This end-to-end integration requires a harmonized digital representation of the business as a foundation. With this, analytics can orchestrate and align agent activity that occurs not only within silos but also in collaboration with humans. Management thus becomes increasingly integrated into a software system—an evergreen capital project that is never truly finished. Instead of relying solely on tacit knowledge stored in the minds of a management team, this knowledge is gradually converted into an ever more integrated software product.
New High Value Layers are Emerging in the Stack
Let’s zoom in a bit on some of the high value pieces of the stack that we’ve highlighted previously but are worth reviewing.
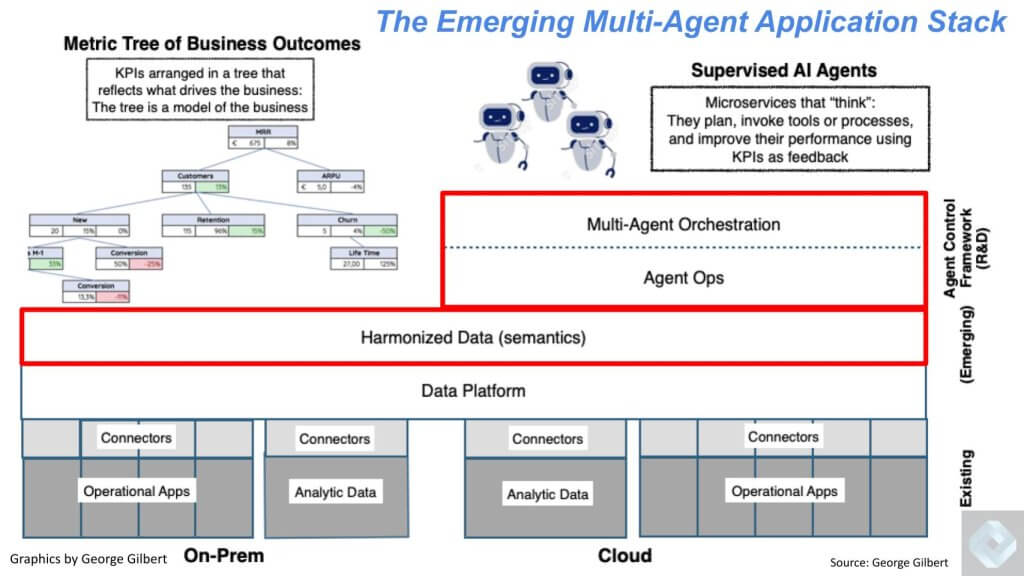
The evolution we envision connects backend systems—both analytic and operational—to extract business logic previously trapped inside applications and make it more accessible real-time. Rather than relying solely on analytic systems that produce historical snapshots, this approach aims to enable continuous decision making and automating workflows. Two layers stand out, highlighted in red:
- A unifying layer that harmonizes data and business logic.
- An agent control framework that orchestrates and communicates across agents and with humans.
At the top, organizational goals guide the process. A high-level goal, such as gaining market share, may set constraints around margins or pricing and specify revenue targets and tactics to achieve an outcome. Agents can understand these goals and execute bottom-up actions within defined guidelines. Working together with other agents and with human input, these “workerbee agents” adjust to changes in the market and adhere to top-down frameworks.
This is critical because the metric tree—representing business goals from forward-looking strategies at the top to more technical and operational states at the bottom—is not just a set of dashboards or historical reports. Instead, these metrics function like dials on a management system. Relationships between them must be learned over time. By applying predictive and process-centric platforms, organizations can conduct experiments, observe outcomes, and refine their understanding of how market demand shaping or other actions influence results.
When integrated with models and training cycles, agents learn from both human interventions and observed outcomes. If an agent encounters an exception it cannot handle, a human can step in to guide the resolution. Over time, the agent learns from these “teachable moments” and can handle similar situations independently. Likewise, when agents attempt to shape demand and measure the effects on metrics, they gain deeper insights that improve their future performance.
This learning framework—harmonized data, business processes, and metric-driven goals—offers a scarce and highly valuable layer in the enterprise stack. While there may be many agents, there will be relatively few such business process platforms within any given organization. Ultimately, as agents learn from both direct human intervention and the outcomes of their actions, they improve continuously, driving innovation and operational efficiency.
Which Technology Vendors are Leading the Way to Agentic?
There are many participants but below are some of the players that we’re tracking in this new world and where we see their value add in the stack.
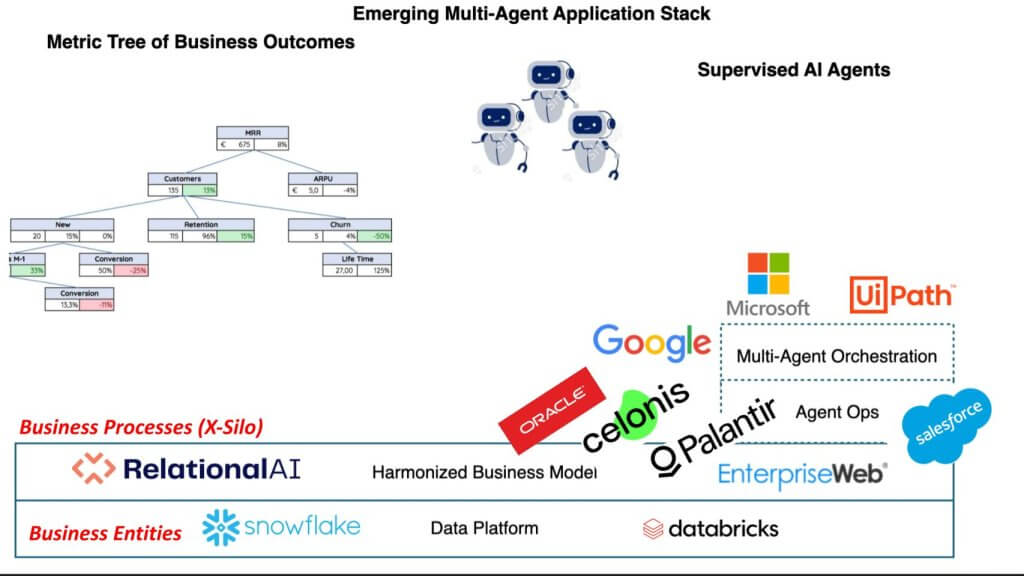
The bottom layer includes data platform providers such as Snowflake and Databricks, which are leading efforts to represent core business entities. Other companies like Relational AI, Celonis, and EnterpriseWeb are building cross-silo capabilities, often referred to as the business process layer. Above that layer, organizations like Palantir, Oracle, and Salesforce are harmonizing business processes within their own ecosystems. Moving further up, an agentic orchestration layer is emerging, featuring companies like Google, Microsoft, and UiPath. It is widely anticipated that AWS will also play a significant role in this evolving stack, based on recent announcements and developments.
A key point is that it is far more challenging to move from representing business entities—people, places, and things—to defining and aligning cross-silo business processes. The industry has spent decades building the data and application logic technologies needed to fuse these elements together. Relational AI, for example, uses a relational knowledge graph, allowing organizations to declaratively define application logic, similar to expressing requirements in SQL. This dramatically simplifies the process of articulating logic. Celonis provides business process building blocks so that customers can conduct process mining and configuration with minimal coding. Palantir excels at connecting deeply into core transactional systems but requires more procedural coding, as it does not supply out-of-the-box application templates. Salesforce, with its Data Cloud, offers comprehensive coverage of the entire customer 360 domain, including customer journeys and touchpoints, expressed through configurable business logic that fits its model. UiPath is in a position to automate processes including those where APIs may not be available.
These approaches highlight the complexity of harmonizing business logic across multiple platforms. Building a metrics tree of business outcomes requires a consistent representation of enterprise processes. This goes beyond simply connecting schemas from various applications. The metrics tree represents the “physics” of a business—its behavior and logic—linking high-level goals such as gaining market share to more granular operational metrics. Without harmonizing the underlying application logic, it is difficult to create this cohesive representation of business outcomes.
In short, while companies have made substantial progress in harmonizing data at scale, the next frontier involves fully integrating both data and business processes into a unified stack. Achieving this will unlock the potential of agentic orchestration and deliver a new level of automation, insight, and adaptability for the enterprise.
How AI Will Achieve 10X Productivity Impacts
The massive opportunity ahead was explained by Erik Brynjolfsson in the graphic below, annotated by George Gilbert.
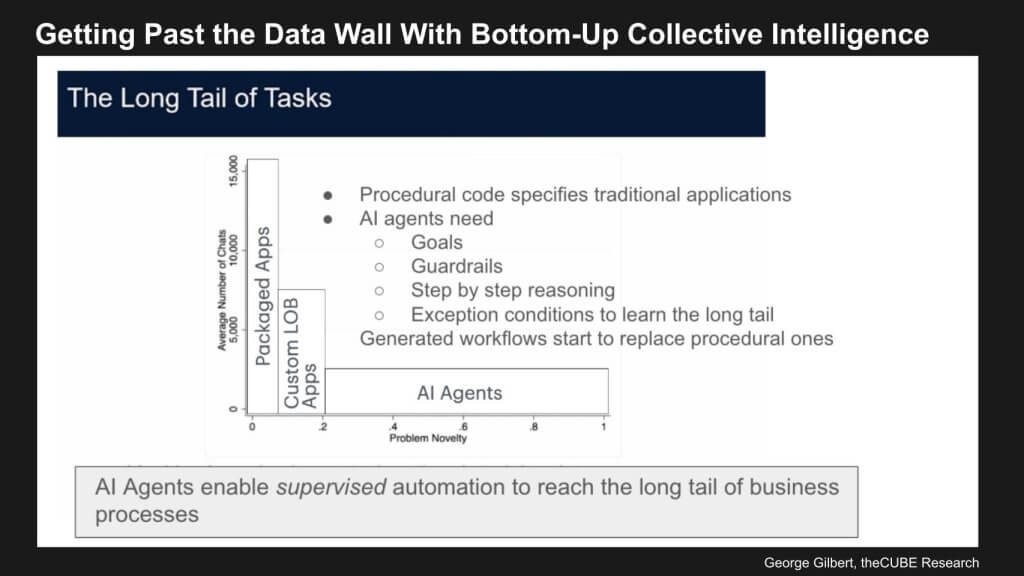
The frenzy around enterprise AI largely relates to boosting productivity. On the surface, this suggests achieving similar or greater outcomes with fewer employees. Industry observers, such as David Floyer, often discuss realizing the same results with a fraction of the workforce. The key question is how this will play out within the enterprise.
Erik Brynjolfsson perspective, depicted in a power law curve above, is useful here. Historically, packaged applications addressed certain high-volume, repeatable business functions—often in the back office and other well-defined domains. Custom modifications and applications were then introduced to handle proprietary processes, specialized data, vertical industry tasks, or unique organizational needs. These encompassed another sizable portion of automation.
Yet, beyond these implementations lies a very long tail of workflows that remain unautomated. This long tail represents the space where AI agents can deliver an order-of-magnitude increase in productivity. Rather than relying solely on pre-coded, deterministic logic—as seen in traditional packaged software—the next generation of agents will learn dynamically. They will adapt to unanticipated scenarios and exceptions by observing outcomes, incorporating human feedback, and refining their responses over time.
In other words, at the left end of the curve, tasks were automated through deterministic logic because they were well-understood and repetitive. Further along the tail, there are countless less-common, more nuanced workflows that cannot be fully predefined. By deploying AI agents that learn and improve continuously, enterprises can gradually tame these unstructured, long-tail processes. However, current technology cannot simply discard existing deterministic rules and rely entirely on a multitude of autonomous agents. Doing so would result in a chaotic environment—effectively back to a Tower of Babel—where agents struggle to understand their roles and responsibilities.
The path forward involves carefully combining traditional, deterministic systems with learning agents, enabling them to handle both well-understood tasks and emerging, unpredictable scenarios. Over time, as agents learn from outcomes and human intervention, more workflows can be automated, significantly increasing overall productivity.
2025 Outlook and the Future of Agentic AI
Let’s end with a look ahead to 2025 and beyond.

As previously discussed, there is likely to be significant “agent washing” in 2025. Many will market single agents or lightweight solutions as agentic systems, but closer inspection will reveal that the journey is only beginning. Some claim agentic AI capabilities will be widespread next year, yet substantial work remains. This is not a short-term trend; it is expected to be a multi-year process. While efforts may start to take shape in earnest in 2025, the real impact may take two to ten years to fully unfold.
One major concern is that vendor-specific agents will emerge within application silos, reinforcing fragmentation and risking yet another unfulfilled promise by the tech industry. Many previous initiatives—such as Customer 365, certain data warehousing efforts, and the Big Data craze—failed to meet lofty expectations. Although the cloud has largely delivered on performance, a number of data-related promises have either been broken or only partially realized. The danger is that the industry may simply bolt agents onto existing legacy architectures, effectively “paving the cow paths” rather than delivering a meaningful transformation.
The opportunity is to reinvent the application stack rather than perpetuate the status quo. While leaders such as Jassy and Nadella have acknowledged the need for change, even they concede there are challenges and uncertainties in how this will develop. The vision of an agentic future that delivers a 10x productivity gain hinges on harmonizing end-to-end business processes, ensuring that agents and humans collaborate effectively and share a common understanding.
Different vendors are placing varied bets. Major cloud providers are setting forth their strategies, data platforms like Snowflake and Databricks are staking their positions, and a diverse group of application players—including ServiceNow, Salesforce, Oracle, and SAP—are shaping their own approaches. Meanwhile, a flood of investment is pouring into agent startups. The question is whether these emerging players will help integrate the stack or create new silos. Many of these agents will need access to the business logic currently locked inside existing applications. Without harmonized logic and accessible platforms, these agents could struggle to deliver meaningful value, forcing them to pay a premium to tap into that logic.
This underscores the importance of not skipping crucial steps. The path forward involves creating new infrastructure layers, incorporating genuine harmonization, and avoiding the trap of superficial bolt-ons. While realizing this vision will take time and persistence, focusing on the pieces that do not yet exist—and making them real—can substantially increase the likelihood of achieving the productivity gains envisioned by this agentic era.
What do you think? How are you thinking about agents in your organization? What steps are you taking to prepare?
Let us know…
Image: Amila Vector


