
With Watson 1.0, IBM deviated from the silicon valley mantra, fail fast, as it took nearly a decade for the company to pivot off of its original vision. In our view, a different dynamic is in play today with Watson 2.0 – i.e. watsonx. IBM’s deep research in AI and learnings from its previous mistakes, have positioned the company to be a major player in the Generative AI era. Specifically, in our opinion, IBM has a leading technological foundation, a robust and rapidly advancing AI stack, a strong hybrid cloud position (thanks to Red Hat), an expanding ecosystem and a consulting organization with deep domain expertise to apply AI in industry-specific use cases.
In this Breaking Analysis we share our takeaways and perspectives from a recent trip to IBM’s research headquarters. To do so we collaborate with analyst friends in theCUBE Collective, Sanjeev Mohan, Tony Baer and Merv Adrian. We’ll also share some relevant ETR spending data to frame the conversation.
IBM Research, an Iconic American Institution & an Enduring Asset

This past week, top industry analysts spent the day at the Thomas J. Watson Research Center in Yorktown Heights, New York. It’s a beautiful facility and an American gem of core scientific research. The innovations from this facility over the decades have spanned mathematics, physical science, computer science and other domains that have resulted in semiconductor breakthroughs, software innovations, supercomputing, Nobel prize winners and is a mainspring of IBM’s Quantum computing research.
The event was headlined by IBM’s head of research Dario Gil along with Rob Thomas, head of software and go to market. About fifty analysts attended for a full day of briefings on Gen AI, infrastructure, semiconductor advancements and quantum computing.
For today’s Breaking Analysis, we’ll set the stage with some perspectives on the spending data from ETR, then we’ll cut to the conversation with Sanjeev, Tony and Merv which took place during and immediately after the event.
The Big Picture on AI & Enterprise Tech Spending
First let’s review the top level macro picture in enterprise tech spending.
If you follow this program you’ve seen the format below previously. It plots spending momentum on the vertical axis using a proprietary ETR metric called Net Score. Net Score reflects the net percent of customers spending more in a particular sector (N= ~1,700 IT decision makers). The horizontal axis represents the penetration of a sector within the survey called Pervasion (sector N / total N). The red dotted line at 40% represents a highly elevated level of momentum on the Y axis.
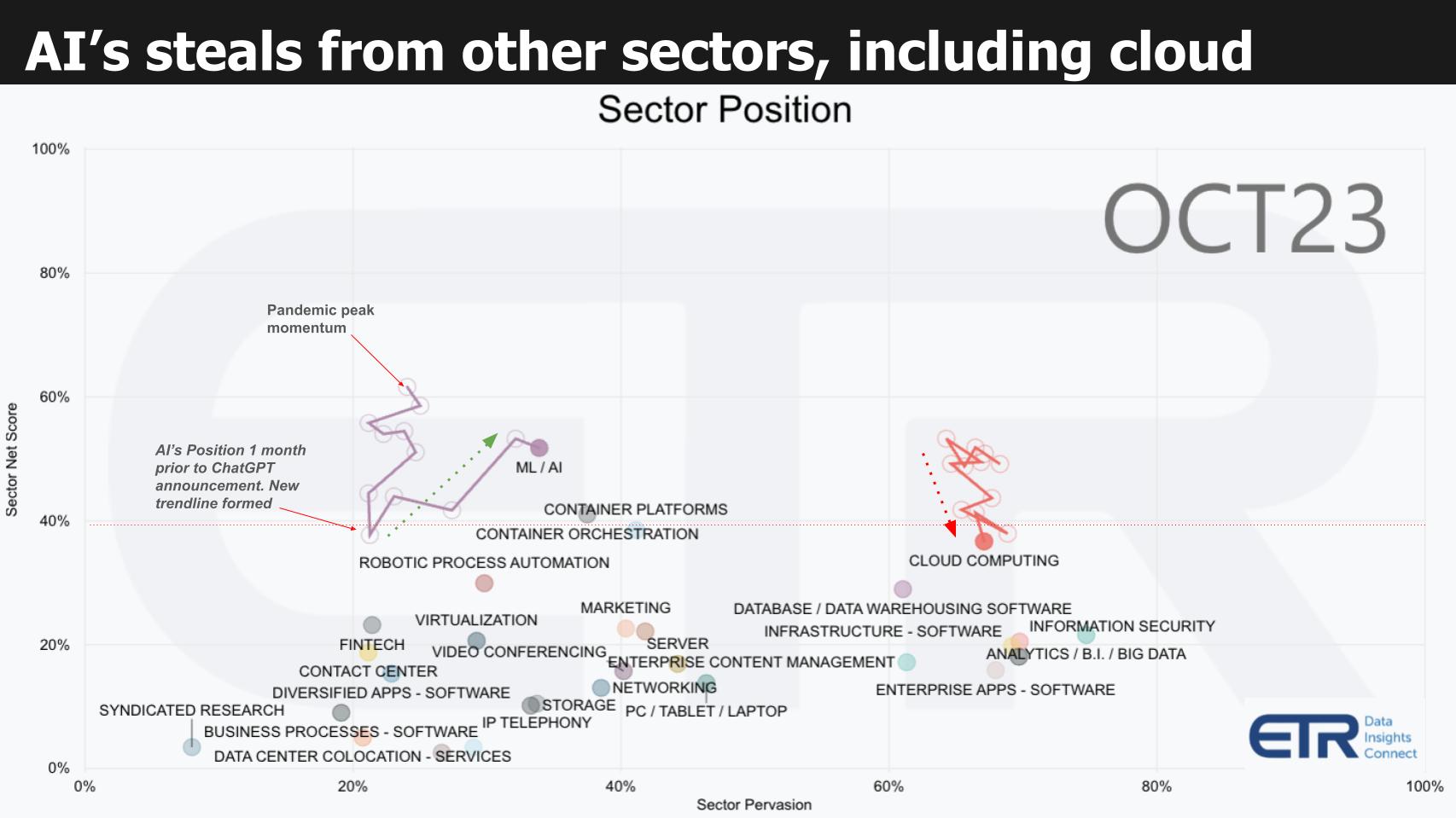
Here’s the story this picture tells:
- During the pandemic as you can see by the squiggly lines, spending on ML/AI peaked.
- As we exited the isolation economy we saw momentum in AI decelerate.
- Then, one month before ChatGPT was announced the sector bottomed and the trendline was reset.
- To fund Gen AI, organizations are reallocating budget.
Because discretionary IT budgets are still constricted, a majority of AI initiatives (we estimate at least 2/3rds), are funded by “stealing” money from other sector buckets. Above, we highlight cloud and you can see its downward trajectory as cloud optimization kicked in over this timeframe. But other sectors face the same headwind pressure.
Fast Delivery of Quality Gen AI Function is Critical to Adoption
It’s striking to see the momentum companies get from rapid feature acceleration and quality announcements in Gen AI. Below is a chart from the August ETR survey that shows which players’ products are getting traction in Gen AI.
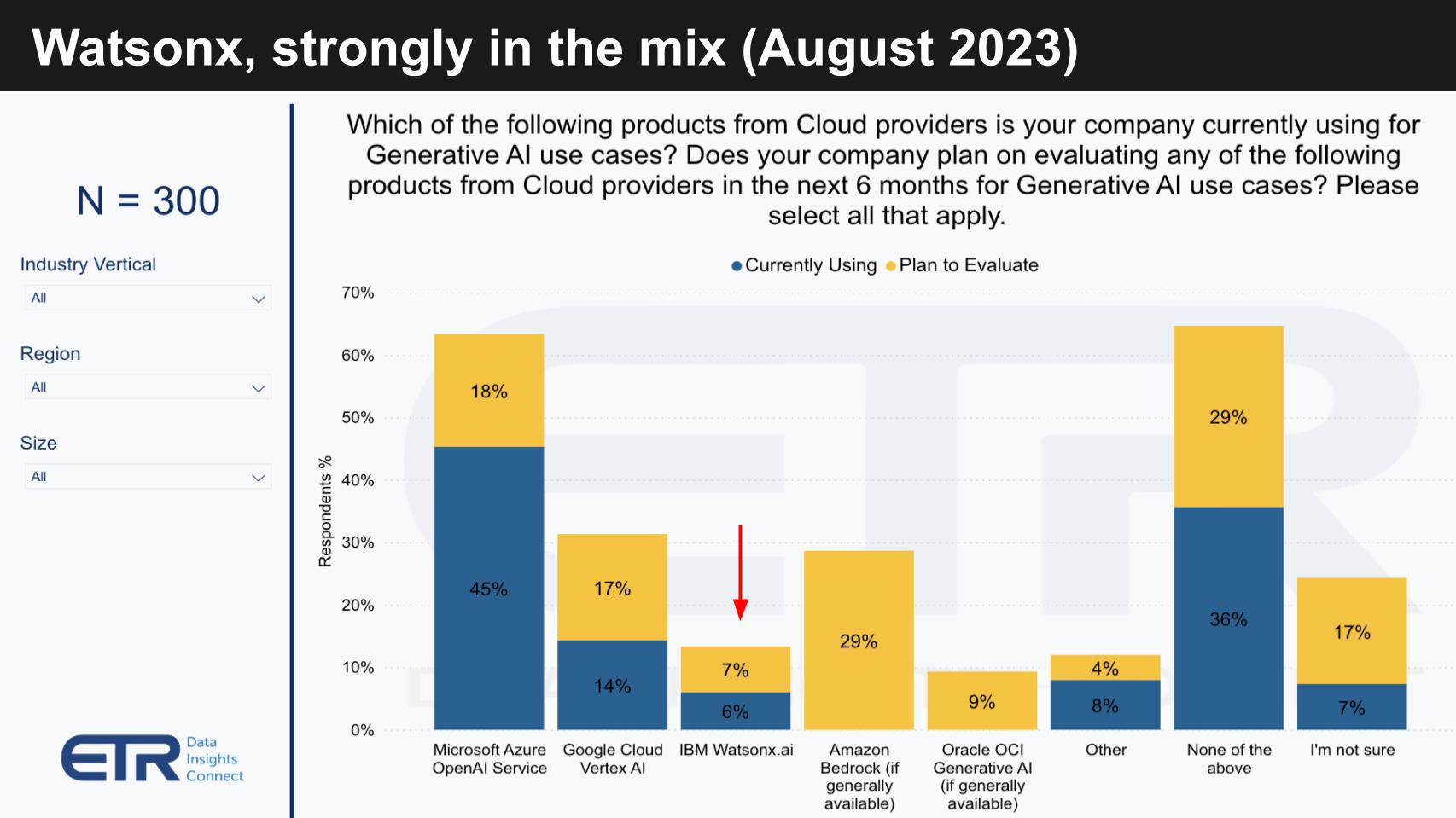
The blue bars indicate the then current usage. The yellow bars show planned usage. The following key points are noteworthy:
- Microsoft and OpenAI are clear leaders with Google Cloud in the next position at this time.
- IBM watsonx.ai is right in the hunt as the third most adopted platform.
- AWS had not GA’d Bedrock at the time but interest in experimenting with its tools is high.
- Other likely includes platforms like Anthropic, Cohere, Llama 2, etc.
The point for this research note is watsonx is clearly in the mix and IBM’s focus on AI and hybrid cloud is differentiating. Remember, this survey was taken just three months after IBM’s watsonx announcement at its Think conference, around the same timeframe Google announced Vertex AI. The point is the pace of innovation is fast and adoption is following close to announcements and general availability.
AWS Bedrock just went GA last month and we expect measurable impact in Q4. As well, all players are announcing new capabilities at an exceedingly rapid pace. We believe that pace, to the extent the announcements are substantive and deliver value (i.e. are not vaporware) will confer competitive advantage to the supplier.
Fast Forward Just 2 Months and the Need for Speed Becomes Obvious
Below is a similar XY graphic as shown previously with Y as spending velocity (Net Score) and the X representative of market presence (Pervasiveness) for specific AI platforms. The table insert informs the placement of the dots (Net Score and N’s). Note: This data depicts ML/AI and not isolated to Gen AI.
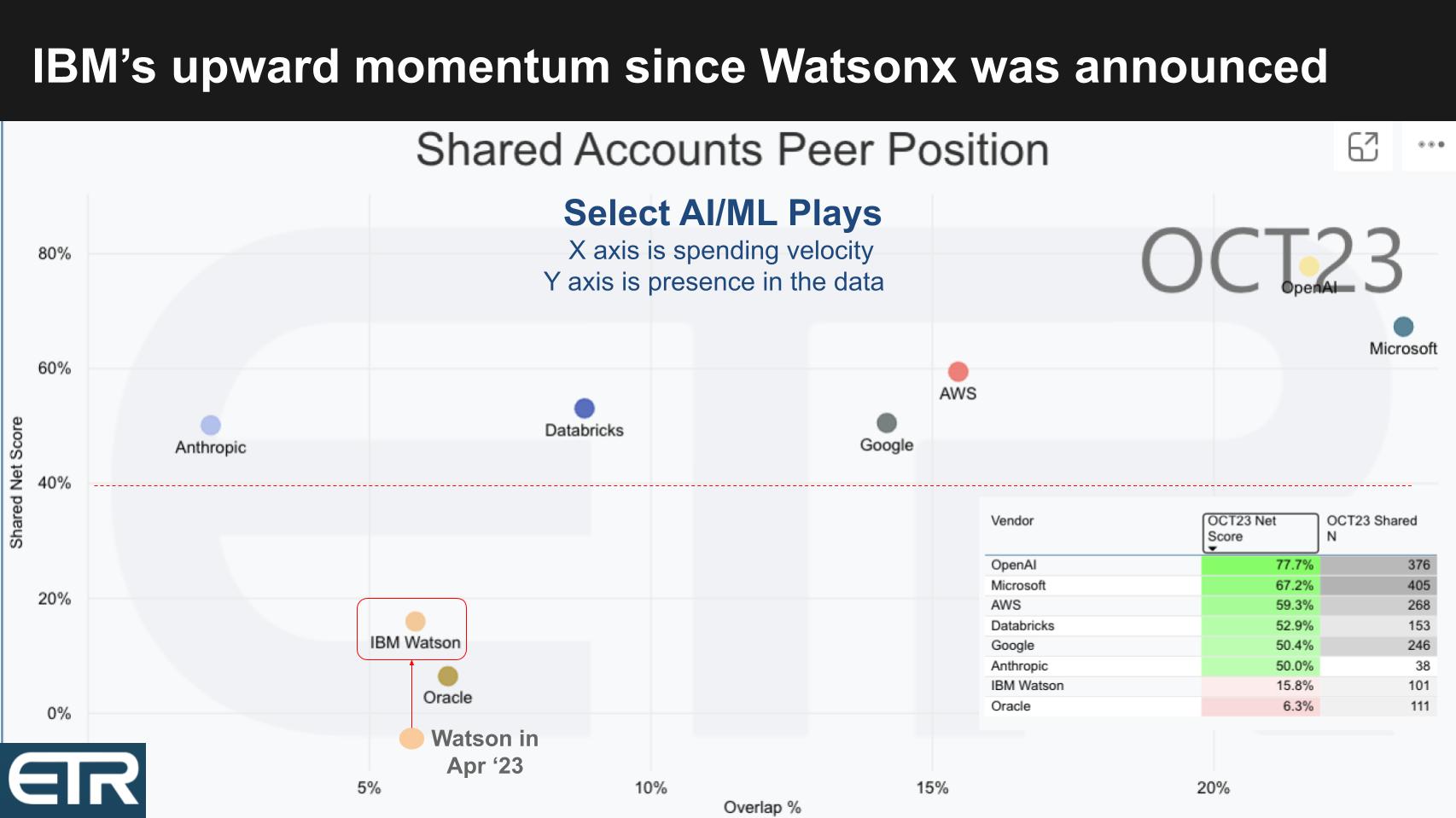
Start in the upper right and notice the positions of OpenAI and Microsoft. With Net Scores of 78% and 67% respectively it supports the narrative that they are winning in the market. Both companies are well above the 40% magic line. Also, in this random survey of IT decision makers, the combined N’s of OpenAI and Microsoft are greater than those of AWS, Google, IBM and Anthropic combined.
Nonetheless, the cloud players are top of mind as is Anthropic, IBM Watson, Databricks with its machine learning and data science heritage and Oracle.
IBM Watson’s Momentum Accelerates After watsonx is Announced
While IBM is showing much lower on both dimensions, look where the company was in April of this year, one month prior to its announcement of watsonx in May. They went from a negative Net Score – meaning spending was flat to down for a higher percentage of customers than was up – to a strongly trending up move at a 15.8% Net Score, surpassing Oracle.
Interestingly, when you dig into the data, one reason for that uptick is the percentage of new customers adding Watson jumped from 3.6% in July of 2022 to 13% in the October survey. Churn dropped from 16% to 7% over that same period. Remember, legacy Watson 1.0 is in these figures so they’re working off the decline there, transitioning the base to watsonx.
The percentage of new customers adding Watson jumped from 3.6% in July of 2022 to 13% in the October survey.
The point is quality announcements with strong features are coming fast and furious and are catalysts for Gen platform AI adoption.
Analysts’ Take
With this as context setting, let’s dig into the analyst roundtable. Below are the seven areas we’re going to focus on.

We’ll start with top takeaways. Then we’ll dig into the watsonx stack from silicon to SaaS. We evaluate the impact on two ecosystems – analytics and Gen AI partners – all the way up that stack. We’ll look at surprises from the event and we’ll finish with commentary on the roadmap and top challenges IBM must overcome in the market.
One area we don’t dive into too much in the conversation because it was mostly NDA is Quantum computing. We are not deep into quantum but will say it’s starting to feel like it’s getting more real. IBM is betting big on quantum and is taking a very long term view of the technology. Our take is conventional computing will be here for decades and the big question we think about is how existing computing models keep getting better and innovators are finding new ways to solve problems irrespective of quantum. So the crossover point is very fuzzy right now.
With that let’s take a look at the analyst discussion. What follows are edited excerpts from the full discussion which is available in the video at the end of this research post.
Analyst Roundtable – Sanjeev Mohan, Tony Baer & Merv Adrian
Q1. What are your top takeaways from the event at IBM’s Thomas J. Watson Research Center today?
Sanjeev:
Thank you for having us here. It’s incredible to be at this prestigious location. I’m particularly amazed by IBM’s pace. Watsonx’s rapid development since its announcement in May 2023 is striking. By June, watsonx.ai and watsonx.data were already generally available, followed by Code Assistant in September, and now watsonx.governance this November. The speed of turning research into commercial products is something I’ve never seen before. IBM has effectively shrunk the time between their research and commercialization.
Tony:
Following Sanjeev’s thoughts, my takeaway is about IBM’s growth since Watson’s debut on Jeopardy about a dozen years ago. Back then, Watson was more a showcase. But what struck me today is how IBM learned from that experience. They’ve made their technology simpler and more integrated, building upon their previous tools. Much of the watsonx portfolio is an extension of the original Watson tools. It feels like we’re seeing Watson 2.0 now.
Merv:
IBM is like an overnight sensation, but after 20 years of working on AI technology. The focus now is on immediate, actionable business outcomes. They’ve moved from pure science to technologies designed to solve real-world business problems for major companies. This shift to deliverable and optimized solutions is a significant change from their previous approach.
Dave:
Reflecting on what Tony called Watson 2.0, I see IBM as having an ’embarrassment of riches’. They’ve learned from the original Watson, building up expertise and lessons that are now paying off. They’re compressing the innovation timeline, which is crucial in our fast-paced world. IBM seems to have gotten it right this time, leveraging their past to accelerate their future.
[Watch the clip from theCUBE AI of the analysts discussing the top takeaways from the IBM event].
Q2. How do you think about the watsonx stack from chips and infrastructure to the foundation models / LLMs, IBM’s machine learning platform, the data and analytics components all the way up to apps and SaaS?
Merv:
It’s been a while since we’ve looked at the value of a truly deep vertically integrated manufacturer. From silicon up through the models, data collection, and extraction from underused assets, IBM has it all. They’ve created commercially viable models that are appropriately sized for performance and are indemnifiable. They’ve developed an environment that knows how to use, deploy, version, and provide ops for these technologies. On top of that, IBM has a consulting organization actively engaged in delivering technology packages for specific business problems. Everything we saw today is being used right now by customer banks, and all pieces are coming together simultaneously, not at varying maturity stages.
Tony:
IBM has thought through their stack from the hardware level to the orchestration layer, which I see as a unique asset. This includes the OpenShift layer and, on top of that, the application layer where watsonx and all the data reside. It’s a comprehensive vision with various components in different development stages. IBM’s differentiation from AWS or Google is notable. Unlike them, IBM has a deep understanding of customer business processes, thanks to their significant systems integration and consulting business. IBM stands to take AI further in terms of verticalization, matching foundation models with prescriptive datasets. That’s the potential that really stands out to me.
Dave:
IBM has always had significant data expertise, and the impact of Red Hat is becoming increasingly crucial. The mantra of hybrid cloud and AI, with OpenShift containers and Linux, will be omnipresent. Linux following data to the edge and containerizing workloads enables hybrid cloud. But, Sanjeev, do you have anything to add?
Sanjeev:
If you look at the layers of IBM’s AI stack, they’re not fundamentally different from others, but there are nuances. At the hardware layer, they’re versatile, running on Nvidia, Intel, AMD, even Google TPUs. The layer above includes OpenShift and Linux, and importantly, Ansible from Red Hat. The Ansible Automation Platform is a key component. Moving up the stack, there’s the governance layer, databases, data integration, and master data management. They have SDKs, APIs, and at the very top, an assistant for code generation. That’s IBM’s comprehensive view of their entire stack.
[Watch a clip of the analysts unpacking IBM’s AI stack].
Q3. Let’s talk about the impact of the overall ecosystem. IBM’s ecosystem spans from semiconductor partnerships to hyper-Scalers SaaS, ISVs, and of course its internal and external consulting partnerships. How do you think about the evolution of IBM’s ecosystem?
Sanjeev:
IBM’s partnerships, like with SAP, Salesforce, Adobe, and especially with Samsung, are crucial. We learned a lot about the Adobe Firefly collaboration today. But what’s really exciting is IBM’s work with Samsung on AI chips, currently at five nanometers and moving to two nanometers. They’re also partnering with a Japanese company, Rapidus, for a two nanometer chip. These partnerships, particularly with Samsung, who builds their chips, are a vital part of IBM’s strategy.
Dave:
That’s an interesting point, especially since IBM moved away from its own foundry, opting instead to leverage external ones like Samsung. This change in business model is not an exit from the semiconductor business but a strategic shift, with Samsung playing a key role in driving innovation.
Tony:
Continuing on Sanjeev’s note about Samsung, IBM’s strategy seems to be a classic licensing play. Given the market demand and limitations of suppliers like Nvidia, IBM’s partnership with Samsung positions it well in the race for advanced AI chips. This is crucial, especially with the evolving needs of Generative AI requiring different types of chips for various foundation models. Another key partnership to note is with AWS. About five years ago, Arvind Krishna outlined IBM’s hybrid cloud strategy, signaling a shift to embrace other clouds alongside IBM’s. Their evolving relationship with AWS, particularly with watsonx SaaS services, is a promising route to market for IBM.
Dave:
IBM’s leadership in quantum computing, though still years from significant market impact, is building a vital ecosystem. The development of a programming environment for quantum applications is underway, much like Nvidia’s CUDA. This could be a key element in IBM’s future business.
Sanjeev:
Discussing foundation models, another exciting partnership is between IBM and Hugging Face. It’s a tight, bidirectional integration. In IBM Studio, you can use IBM’s native model, Granite, or choose from Hugging Face’s collection. This integration is significant and indicative of IBM’s strategic collaborations.
Dave:
Indeed, Hugging Face is gaining momentum, especially post-ChatGPT announcement. Their rising adoption trajectory shows their importance as a partner in the ML/AI space.
Merv:
IBM’s strength in partnerships is evident. A notable discussion today was about their semiconductor factory, their collaboration with Samsung, and the construction of a new fab plant in New York State. They’re partnering with almost everyone, with notable exceptions being Google and Oracle. We heard more about AWS, Microsoft, and SAP. This selective partnership strategy is intriguing, suggesting a work in progress and potential future collaborations.
[Listen and watch the analysts discuss IBM’s ecosystem broadly].
Q4. What surprised you at this event?
Dave:
I’ll kick it off…I was struck by Dario Gil’s commentary on the steps that IBM has taken to actually turn research into commercial opportunities. And this is something that IBM struggled mightily with in the 2010s. He had very specific details, organizational details, the process, the mindset, collaboration, silo busting across multiple research organizations. And then Rob Thomas’ commentary on focus where the product folks do nothing but product. They’re not doing marketing, they’re not doing go-to market, which used to be a one third, one third, one third type of thing…rather they’re focused on products. So that was both surprising and refreshing
Tony:
I was struck by the change in IBM’s approach, especially with Arvind Krishna at the helm, focusing on products and simplifying operations. The labs, previously independent fiefdoms, are now more integrated, working from the same playbook with increased transparency and communication. This shift is remarkable. What really surprised me was the quick uptake of watsonx. Announced in May, it already has a significant customer base, reflecting IBM’s increased focus and the market’s confidence in their products. The Think conference’s themes of hybrid cloud and AI, and the consistency in messaging, have reinforced customer trust in IBM’s products.
Dave:
The data confirms the momentum in Watson’s spending compared to a year ago. While still not at the level of the big cloud players, IBM has made a significant move, indicating a trend we’re closely watching.
Merv:
The change in attitude at IBM was surprising. Rob Thomas’s discussion about the software organization’s collaboration with the research team and the decision to focus solely on product delivery was notable. This new focus on commercial delivery, after a period where it was lacking, is exciting. IBM’s current emphasis on providing practical solutions for business problems is a convergence of market trends that positions them uniquely well. This is the first time in a while that I’ve been this enthusiastic about IBM.
Sanjeev:
Seeing the new IBM, with its sense of urgency and focus, was refreshing. IBM is now effectively leveraging its past acquisitions, which previously operated in silos. The integration of various tools and acquisitions, like AI Code Assistant, Ansible, Instana, and Databand, shows a cohesive strategy. The way these different components work together, like AI recommendations being actionable through Ansible or monitored via Instana, is impressive and a significant change from the past.
[Watch the analysts riff on surprises from the event at IBM Research]
Q5. Let’s dig into an area of expertise for you three. What are your thoughts on IBM’s data & analytics ecosystem?
Merv:
IBM’s data and analytics ecosystem has its positives, like openness and hybrid cloud adaptability, but these aren’t unique. They’ve been adept with structured and some unstructured data. One impressive aspect was a demo showing data extraction from a handwritten form. This highlights a crucial challenge: preparing data for consumption by models. IBM has focused significantly on trust, governance, and PII recognition, even to the point of indemnifying their customers for using their models. This approach is unique and crucial, especially for customers facing regulatory scrutiny. The challenge remains in transforming data into a usable format for models.
Sanjeev:
IBM’s ecosystem comprises databases like Db2 and governance components. I noticed their lakehouse approach, watsonx.data, which uses Iceberg, and this is part of the next iteration of Cloud Pak for Data. However, I didn’t see any BI (Business Intelligence) offerings, which might have been an oversight on my part. Their existing pieces, like the lakehouse, are being leveraged effectively.
Tony:
I’m not entirely convinced we saw the next iteration of Cloud Pak for Data. IBM needs to integrate watsonx.data and Cloud Pak for Data more closely, which I didn’t see today. Regarding their lakehouse market, IBM’s support for Iceberg, the standard open table format, was expected. They’ve implemented Iceberg uniquely, adding capabilities like local data caching and distributed processing. However, I’m looking forward to seeing a real convergence with Cloud Pak for Data, which includes AI ops tools and analytics tools, potentially absorbing elements of Cognos Analytics for cloud deployment. This convergence is something IBM still needs to address.
[Listen and watch (in the dark) the analysts describe IBM’s data & analytics ecosystem].
Q6. We touched on this earlier with Sanjeev’s comments on Hugging Face but let’s dig in a bit more to IBM’s ecosystem as it relates specifically to Gen AI partnerships. What are your thoughts on that front?
Sanjeev:
The Gen AI partnership space, including partners like LangChain and Hugging Face, is fascinating but highly dynamic. For instance, OpenAI’s recent increase in context size highlights the rapid evolution in the field. It’s a constantly moving target. While partnerships are vital, there’s a need for constant adaptation and formation of new alliances, as the landscape is changing so swiftly. Today’s leading edge can quickly become tomorrow’s outdated technology.
Tony:
In the Gen AI space, it’s all about finding the right foundation models. General-purpose large language models (LLMs) aren’t efficient for most business problems. We need to consider the carbon footprint of these models and find those suited for specific problem classes and datasets. The partnership landscape isn’t qualitatively different among players like IBM, Google, Amazon, and others at this stage. However, IBM’s strength lies in its vertical industry expertise and consulting, which could help in finding and deploying the right foundation models for specific industry problems. This specificity, rather than just partnering with the same entities as others, will be where IBM can truly make a difference.
Dave:
The spending data shows OpenAI and Microsoft leading, with Anthropic also gaining momentum. Google’s Vertex AI and Meta’s Llama 2 are notable, with Llama 2 seeing significant on-prem deployment based on our data. Amazon’s Bedrock and the Cohere-Oracle partnership are also in the mix. The key to me lies in industry and domain specificity, which is where IBM could excel, thanks to its consulting capabilities and deep industry knowledge.
Merv:
IBM is returning to its core strengths by identifying and investing in technologies early. Their collaboration with Hugging Face is a prime example. While Hugging Face’s models aren’t indemnifiable yet, those developed in partnership with IBM will be. IBM excels in working within an ecosystem and transforming open-source innovations into industrial-grade solutions for mission-critical applications. This blend of open innovation and practical deployment is where IBM shines, ensuring their offerings are suitable for the most demanding environments.
[Watch and listen to the analysts dig deeper into IBM’s Gen AI partnership strategy].
Q7. Last question has two parts. First, what do you think about IBM’s roadmap? And the second part is what do you see as IBM’s key challenges?
Merv:
The roadmap for IBM, especially beyond the first half of next year, was somewhat missing [except for the Quantum NDA]. While the current and near-future plans are solid, there’s a lack of visibility into the long-term. This might be due to IBM’s strategy of being guided by deployment experiences. The potential for IBM lies in repurposing models developed for specific customers into more broadly applicable solutions. Despite IBM’s past relevance issues, they have a unique position in servicing large industrial and governmental organizations with complex problems. The transformation and migration of legacy software assets present a massive opportunity for IBM, potentially akin to the impact of C on Wall Street.
Tony:
IBM’s challenge lies in integrating its various assets. Their roadmap hints at a more vertical focus, which is promising. I’m particularly interested in how IBM will handle governance, especially with their Manta acquisition. The integration of model governance, AI governance, and data governance is crucial, and IBM’s approach to data lineage could be a key factor in this. Understanding the interaction between data drift and model performance is vital for effective governance.
Sanjeev:
IBM hasn’t provided a clear roadmap, and much of this is speculative. For example, vector databases weren’t explicitly mentioned but are expected. A notable point was Rob Thomas’ comment about IBM’s models not hallucinating, suggesting confidence in the curated models for specific use cases. However, as models are deployed more widely, the issue of hallucination might arise. Also, there was no mention of PowerPC, with the focus shifting to open chips from commercial parties. The expertise from PowerPC seems to be influencing their current AI chip development.
Dave:
The Quantum roadmap was detailed and impressive but it’s years in the making and won’t translate into meaningful revenue for some time. It’s big bet and if it pays it could be absolutely enormous. The key challenge for IBM in my view is raising awareness about its capabilities in AI, building back its credibility and effectively translating its R&D into tangible results. The compression of the innovation cycle and its measurable productivity are crucial factors. Vendors entering the AI market now, without a comprehensive stack, might struggle as they will be perceived as ‘me-too’ players. IBM’s advantage lies in its complete stack and decades of experience and consulting depth within industry and in combination, these set it apart in the era of Generative AI. Of course, as always execution matters.
Sanjeev, Tony and Merv have become great friends of theCUBE Collective and we are so grateful for their collaboration. Tony by the way just wrote a piece on SiliconANGLE reminding us there’s other AI beyond Gen AI. So check that out.
Keep in Touch
Thanks to Alex Myerson and Ken Shifman on production, podcasts and media workflows for Breaking Analysis. Special thanks to Kristen Martin and Cheryl Knight who help us keep our community informed and get the word out. And to Rob Hof, our EiC at SiliconANGLE.
Remember we publish each week on Wikibon and SiliconANGLE. These episodes are all available as podcasts wherever you listen.
Email david.vellante@siliconangle.com | DM @dvellante on Twitter | Comment on our LinkedIn posts.
Also, check out this ETR Tutorial we created, which explains the spending methodology in more detail.
Watch the full video analysis:
Note: ETR is a separate company from Wikibon and SiliconANGLE. If you would like to cite or republish any of the company’s data, or inquire about its services, please contact ETR at legal@etr.ai.
All statements made regarding companies or securities are strictly beliefs, points of view and opinions held by SiliconANGLE Media, Enterprise Technology Research, other guests on theCUBE and guest writers. Such statements are not recommendations by these individuals to buy, sell or hold any security. The content presented does not constitute investment advice and should not be used as the basis for any investment decision. You and only you are responsible for your investment decisions.
Disclosure: Many of the companies cited in Breaking Analysis are sponsors of theCUBE and/or clients of Wikibon. None of these firms or other companies have any editorial control over or advanced viewing of what’s published in Breaking Analysis.


