
Premise
In just about any software market, customers have a choice between best of breed and integrated tools. The decision point for organizations of which direction to take depends on the degree of differentiation and value add derived from each option. Integration will yield simplicity, greater manageability and lower operational costs, but will limit differentiation and places the value add mandate outside of the software technology stack (e.g. business model, unique IP, pricing, etc.).
This research note applies this premise and highlights some of the trade-offs between specialized data preparation tools and integrated products. Although this is a high-level look at the market, the examples in each category should serve to illustrate which approaches resonate with IT practitioner needs. Informatica has earned a place in the comparison with the announcement of its Big Data v.10 product.
Approaches to building tools for the analytic data pipeline
Given the steps in the previous article on requirements, we can show the scope of integration that different vendors’ tools offer. Competing on scope of integration highlights the trade-off between having different modules reinforce each other and building the richest possible functionality in any one module.
Extract + Load/Ingest
This step was left implicit in the last article as the first step in the pipeline. In the data warehouse era, ETL tools had their own connectors to applications and databases and these fed the transformation hub. In the Data Lake era, the Kafka message queue is rapidly taking over. It doesn’t substitute for the rest of the pipeline, but it does make connectivity and transport fast and easy.
Governance: Waterline Data, Alation, Attunity
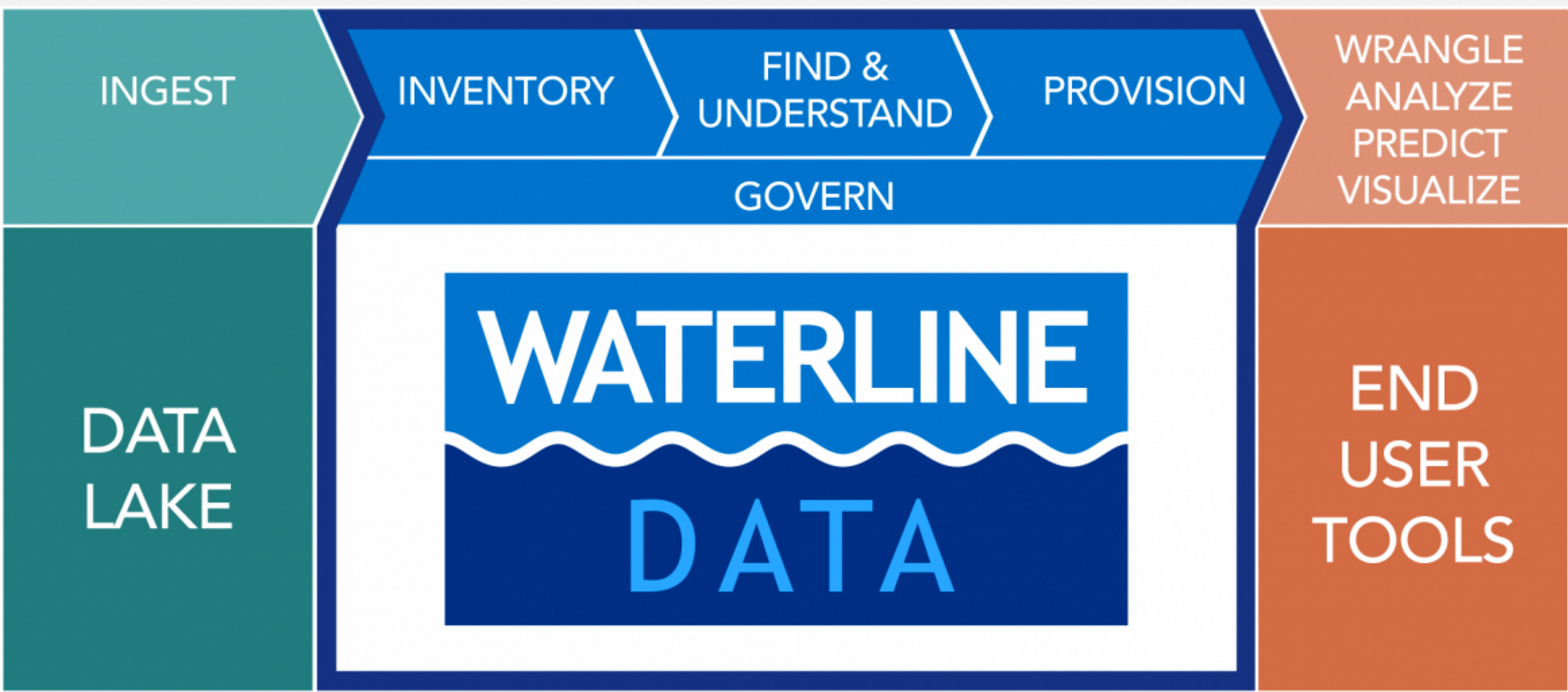
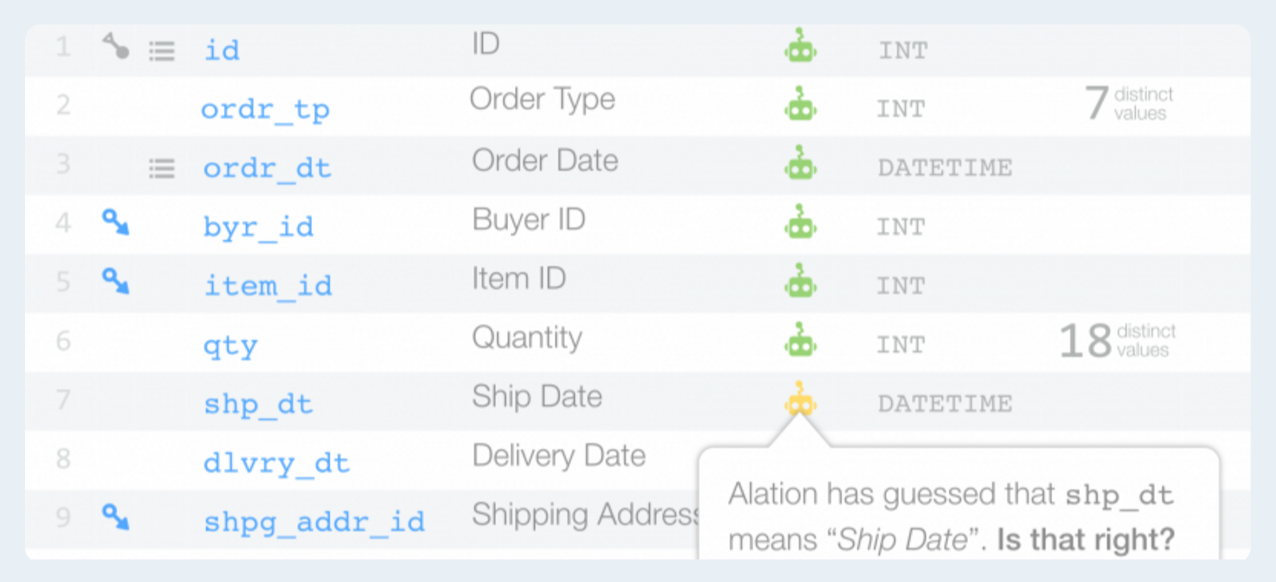
Several standalone governance tools have emerged because the scope of the need is so much greater. Two of the most prominent include Waterline Data and Alation. Waterline takes an inventory by crawling the data and then adds structure and meaning to it so it can be further structured and analyzed manually. In other words, it jumpstarts the process so data engineers and scientists encounter a partially curated pool of data.
Source: Wikibon 2015
Source: Wikibon 2015
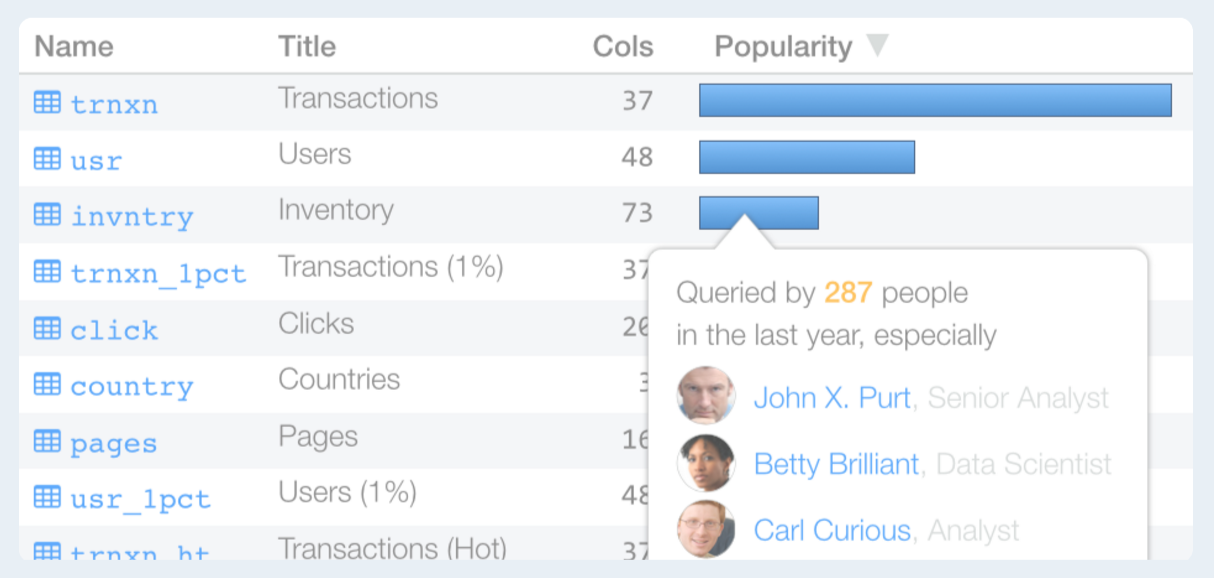
Alation takes a crowdsourcing approach. The more end users access the data, the more it learns about what’s valuable and how it can be used.
Source: Wikibon 2015
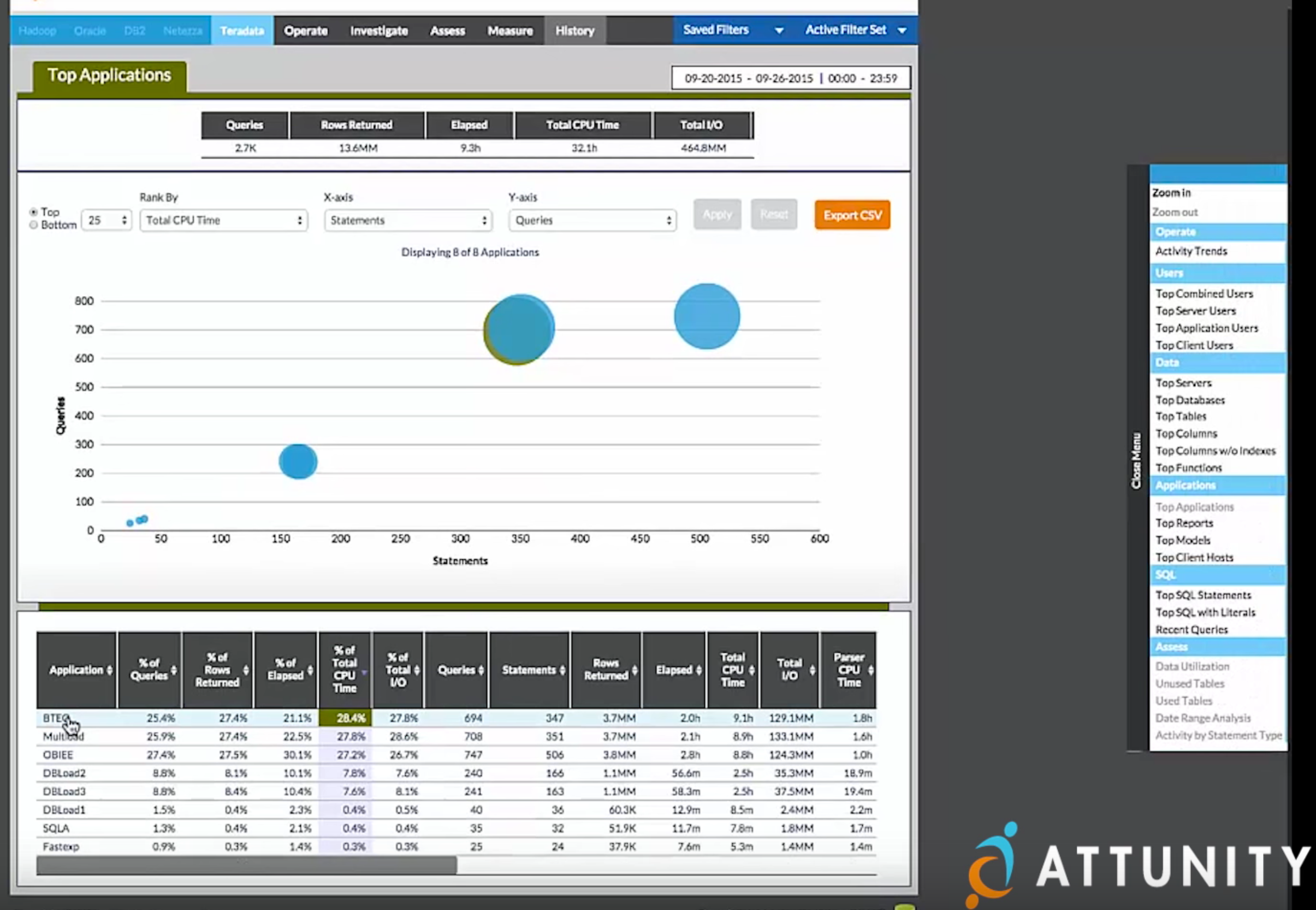
Attunity also belongs in this group because it helps create the proper data warehouse design and then optimizes resource utilization so the right workloads can go on the right platforms.
Security: PHEMI
PHEMI takes a new approach to security. It assumes orders of magnitude more users will be accessing data so traditional security models of perimeters and permissions will break down. Rather, it figures out what data particular users can see based on policies that take into account attributes of the user and the data they’re trying to access.
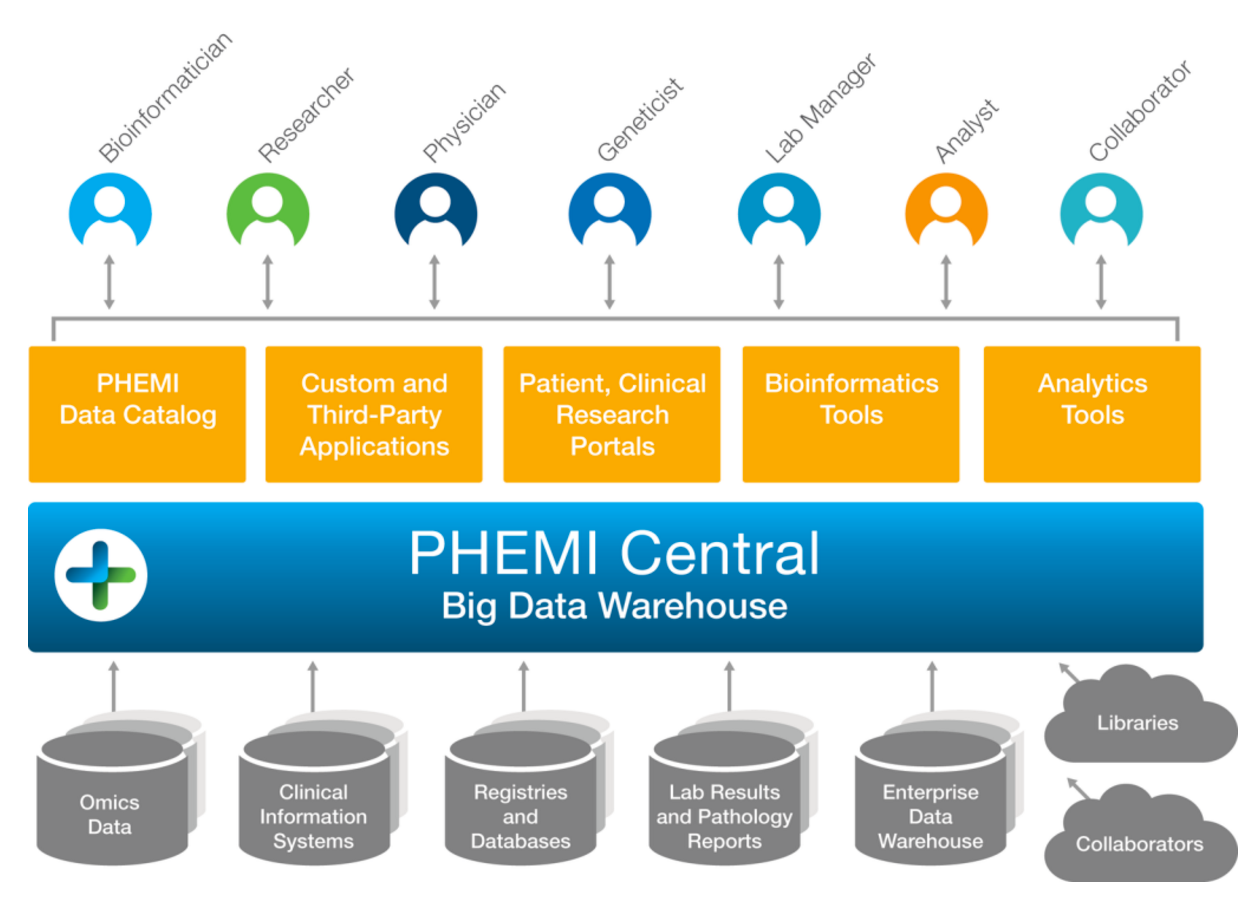
Source: Wikibon 2015
Data Wrangling: Trifacta
Trifacta was one of the earliest of the new generation of standalone data preparation tools. They help data analysts and engineers find structure when more automated approaches come up short.
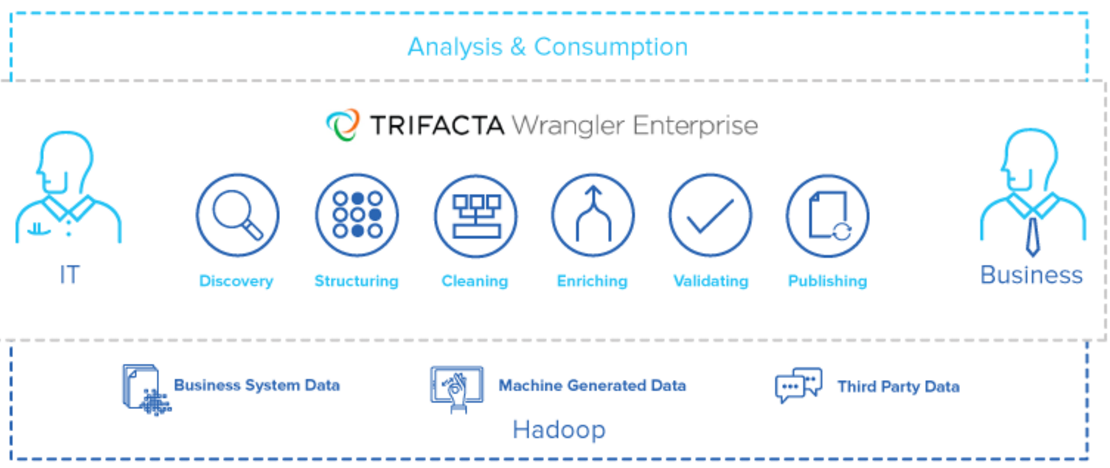
Source: Wikibon 2015
Integration and Runtime: Hadoop MapReduce, Hive, Spark
Increasingly, vendors are following their customers toward Hadoop infrastructure as the most scalable and cost-effective way to transform data and make it ready for analysis in the Data Lake. In the data warehouse generation, the data preparation and integration took place on a proprietary software foundation that typically lived on a very expensive server. Table stakes now requires execution on a Hadoop cluster. Bonus points goes to vendors who can execute on a choice of runtime engines such as MapReduce, Hive, or directly on Spark.
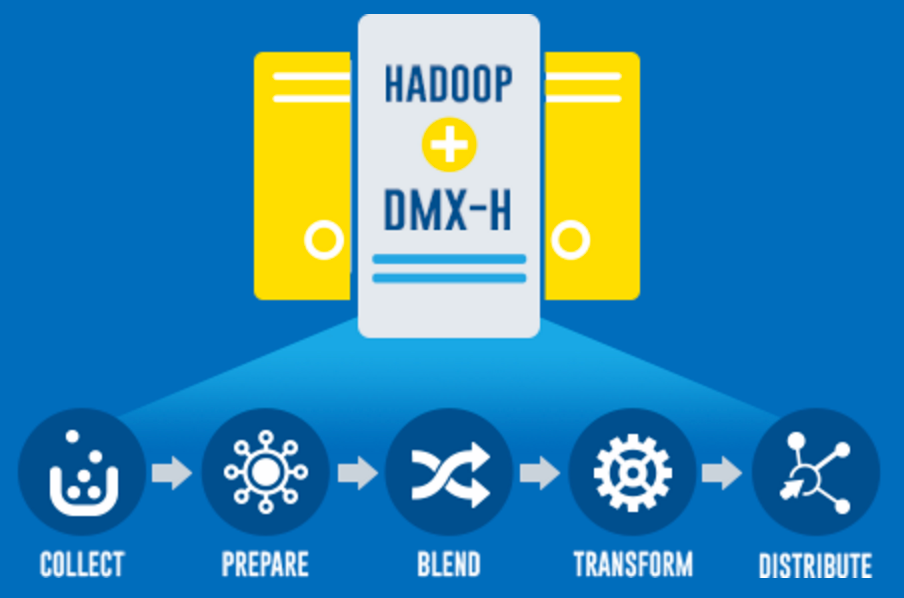
Source: Wikibon 2015
Where some of the more integrated vendors fit
Informatica chose a scope of product integration that leaves off just where their last generation product did. They chose to include everything up to analysis. Their perspective is that few companies standardize on one tool for the whole analytic data pipeline. However, if a vendor can integrate competitive functionality across data wrangling, integration, governance, and security, they can build functionality across these features that other vendors can’t do.
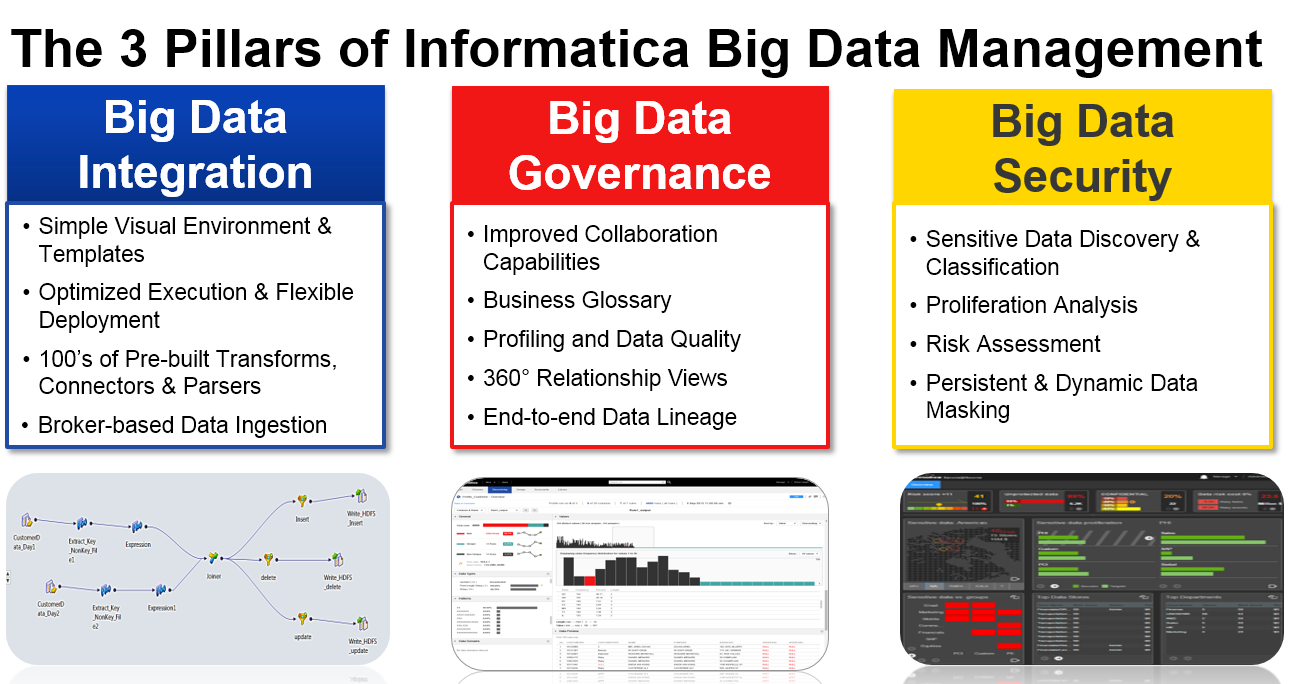
Source: Wikibon 2015
Talend appears to go further than Syncsort but not as far as Informatica. They find the synergistic intersection between data preparation and integration and master data management. Master Data helps ensure the quality of the data they are preparing and integrating.
Source: Wikibon 2015
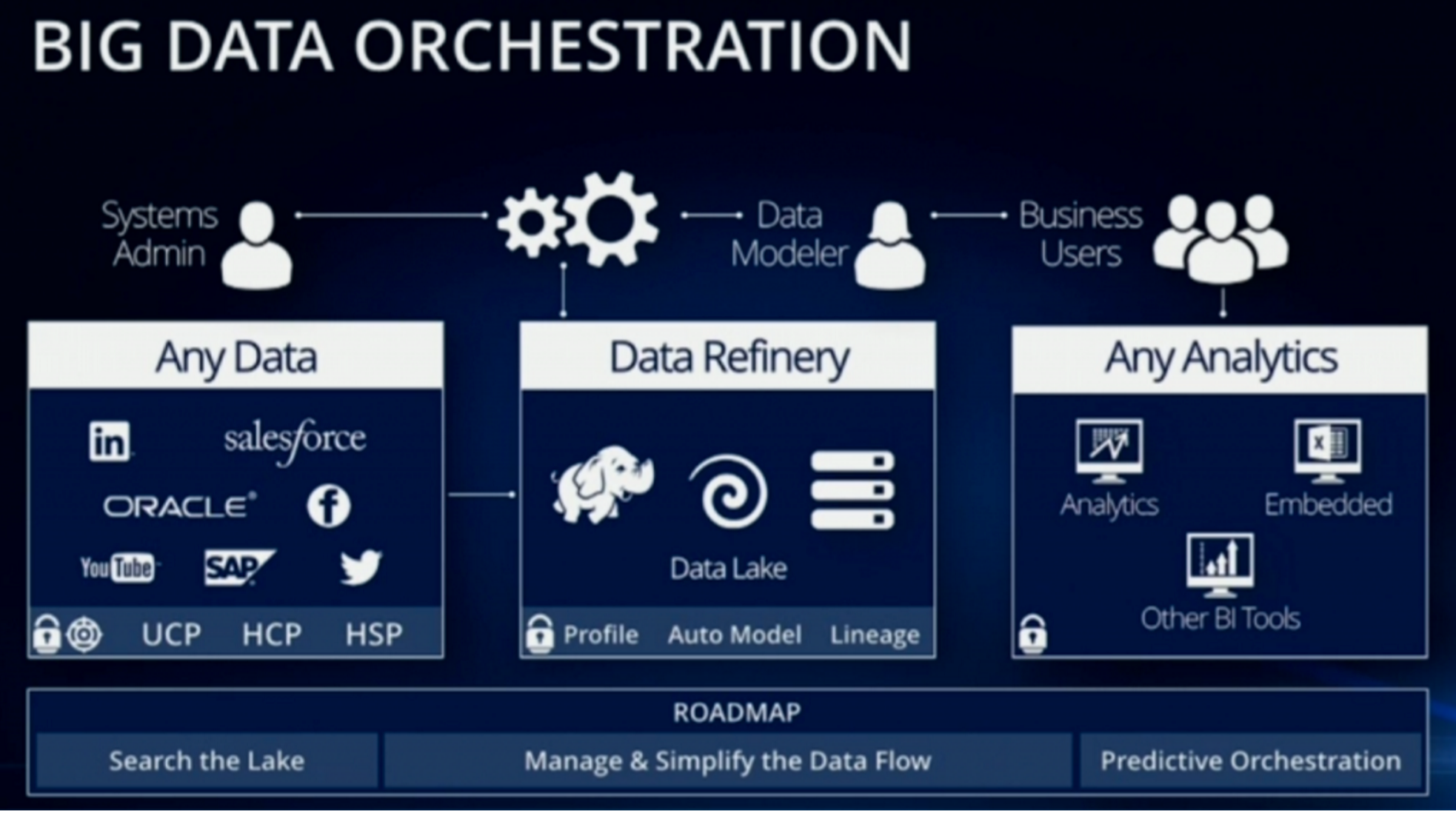
At the other end of the extreme is Pentaho. They chose to extend data prep and integration all the way through analytics. Their appeal is to customers whose collaboration around curating the data to be analyzed can help inform what data to prepare and integrate. These scenarios typically show up when the analysis gets embedded in an application to drive an operational decision.
Action Item
Choosing a data preparation and integration tool is the first step in upgrading Systems of Record to Systems of Intelligence. When IT decision makers are weighing best of breed vs. integrated solutions, they should consider the ultimate objectives for their new applications. If the goal is highly differentiated functionality aligned with a business strategy, specialized systems may have have an advantage. If the goal is matching the competition with the new systems and differentiating elsewhere, the greater simplicity of an integrated solution will probably be more competitive.


