
Premise
On-premises and public cloud computing have largely grown up independent of each other. Although there are some high-level similarities in developer abstractions or administrative processes, creating hybrid applications has been extremely challenging, particularly between VMware on-premises and AWS in the public cloud. Ahead of a major partnership announcement between these two companies, Wikibon has identified what we believe are the three most likely hybrid cloud scenarios and what they mean for big data workloads.
We use Hadoop as a proxy for big data workloads because it can be configured to serve many use cases. Since Elastic MapReduce (EMR) is the default Hadoop-as-a-Service implementation on AWS, we compare it to each of the VMware-based scenarios. Based on TCO data from Hortonworks and input comparing their on-prem deployments with their cloud-based HDInsight, we use two of the most common cluster configurations as examples for how each scenario would affect big data workloads.
- Ephemeral Hadoop workloads exploit elasticity and lower TCO: On-prem clusters that support data science and exploration, data preparation and ETL, and analytics & ad-hoc reporting can benefit most directly from a fixed cluster size on-prem with the ability to temporarily spin up additional nodes in AWS on-demand. AWS EMR lifts many of the operational burdens that place heavy administrative demands on customers.
- Always-on clusters can exploit lower TCO: Applications that have predictable resource requirements, such as real-time applications running on a NoSQL database or business intelligence workloads, can benefit from having a hybrid cloud provider assume responsibility for change management, upgrades, and performance optimization, among other things.
Wikibon believes AWS and VMware have 3 likely hybrid cloud scenarios for their partnership. For details on the advantages of running Hadoop workloads in any of the three scenarios relative to AWS today, see the tables below. (Note: the column for AWS native workloads is the same across the three scenarios to make comparisons easier. In addition, for all the likely focus on VMware’s role in the on-premises side of the equation, Qubole has told Wikibon that 90% of big data workloads currently run on bare metal).
- Hybrid Scenario #1: AWS offers a separate VMware cloud alongside AWS. In this scenario, a pool of VMware-managed IaaS resources exists within the AWS cloud. Beyond common billing, there is limited integration between vmware in the cloud and AWS.
- Hybrid Scenario #2: AWS manages vSphere VM in addition to native Xen VM. In this scenario, AWS can manage its own Xen-based VM’s as well as VMware’s native vSphere. AWS would probably accomplish this by hosting vSphere VM’s inside Xen VM’s.
- Hybrid Scenario #3: AWS extends #2 and manages on-premises edge appliances running the AWS stack with vSphere support. In this scenario, AWS provides VMware customers with an appliance similar to Microsoft’s on-premises Azure Stack. Only, in this case, the appliance would run infrastructure that AWS could manage in a hybrid configuration.
Action Item
Big data Pro’s are finally going to have a more meaningful form either of coexistence or a migration path from on-premises “private clouds” to the dominant and more fully automated public cloud run by AWS. Prioritizing what to deploy on whichever path emerges starts with reviewing the type of workload and then the hybrid cloud configuration. Ephemeral workloads should see the largest TCO savings, regardless of the hybrid cloud scenario. But the deepest integration between VMware and AWS, hybrid cloud scenario #3, should yield the greatest savings.
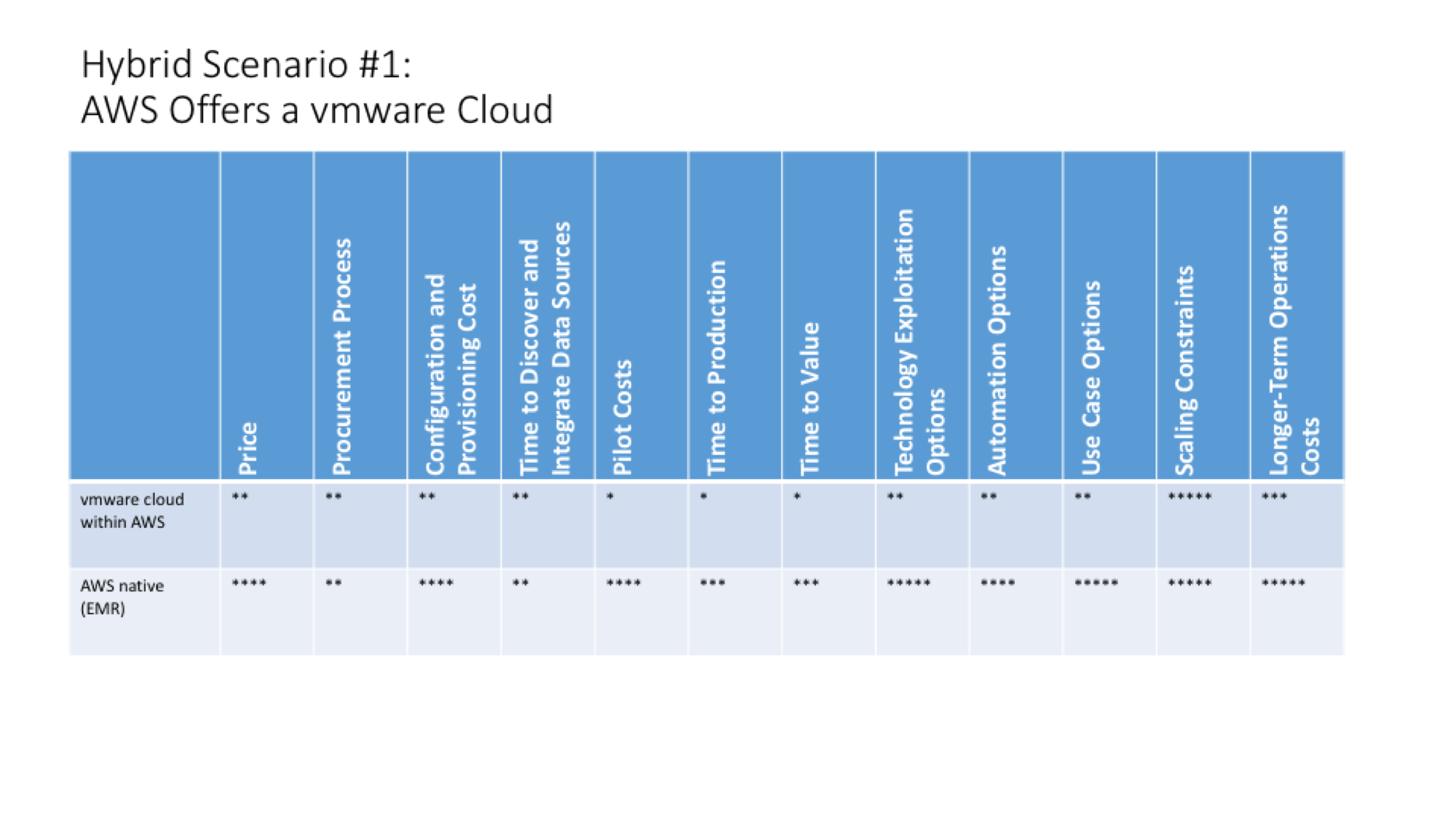
| Comparison criteria | VMware cloud within AWS | AWS native |
| Price | VMware likely to have lower utilization because of smaller pool of infrastructure so prices will likely be higher; unclear if storage can be separated from compute which is how AWS EMR maintains a large cost advantage over on-prem clusters with direct-attached storage. | Leverages largest pool of infrastructure of any cloud as well as option to separate storage from compute. Clusters can be shut down when not in use. |
| Procurement Process | AWS billing (presumably) | Native AWS billing |
| Configuration and Provisioning Cost | Hadoop needs to become a pre-defined workload that VMware can instantiate. | Low since it is based on EMR service. |
| Time to Discover and Integrate Data Sources | If data is in HDFS, it is probably tied more tightly to each compute node and may be harder to do discovery. | Data already likely in the cloud in S3 where it can be more easily separated from compute. |
| Pilot Costs | No pre-defined Hadoop-specific workload. | EMR workload pre-defined. |
| Time to Production | No pre-built building blocks for ingest or output requires additional data engineering and application development. | Building blocks to create ingest and output pipeline already in place. Though not yet data-as-a-service. |
| Time to Value | (same as Time to Production for now). | N/A |
| Technology Exploitation Options | Automation and management of other applications, tools, and services likely to be more limited than native AWS choices. | Richest selection of native and third party applications, tools, and services. |
| Automation Options | vRealize Management and Automation suite attach-rate on-premises has barely reached double digit percentages; unclear how many application workloads have been integrated. | Broadest selection of native and third party apps, tools, and services includes basic operational automation at least. |
| Scaling Constraints | Likely just as capable as AWS in elasticity. Speed of spinning up new nodes is unclear, however. GCP appears strongest here. | No limits other than speed of adding new nodes. |
| Longer-Term Operations Costs | Hadoop software must still be managed by customer, including patches, upgrades, and other admin tasks typical of on-prem software. | Hadoop-as-a-Service transfers most operational activities and costs from customers to AWS. Using Hortonworks’ experience with HDInsight on Azure as a proxy, customers experienced 63% lower TCO and 66% higher IT staff efficiencies relative to on-prem deployments. |
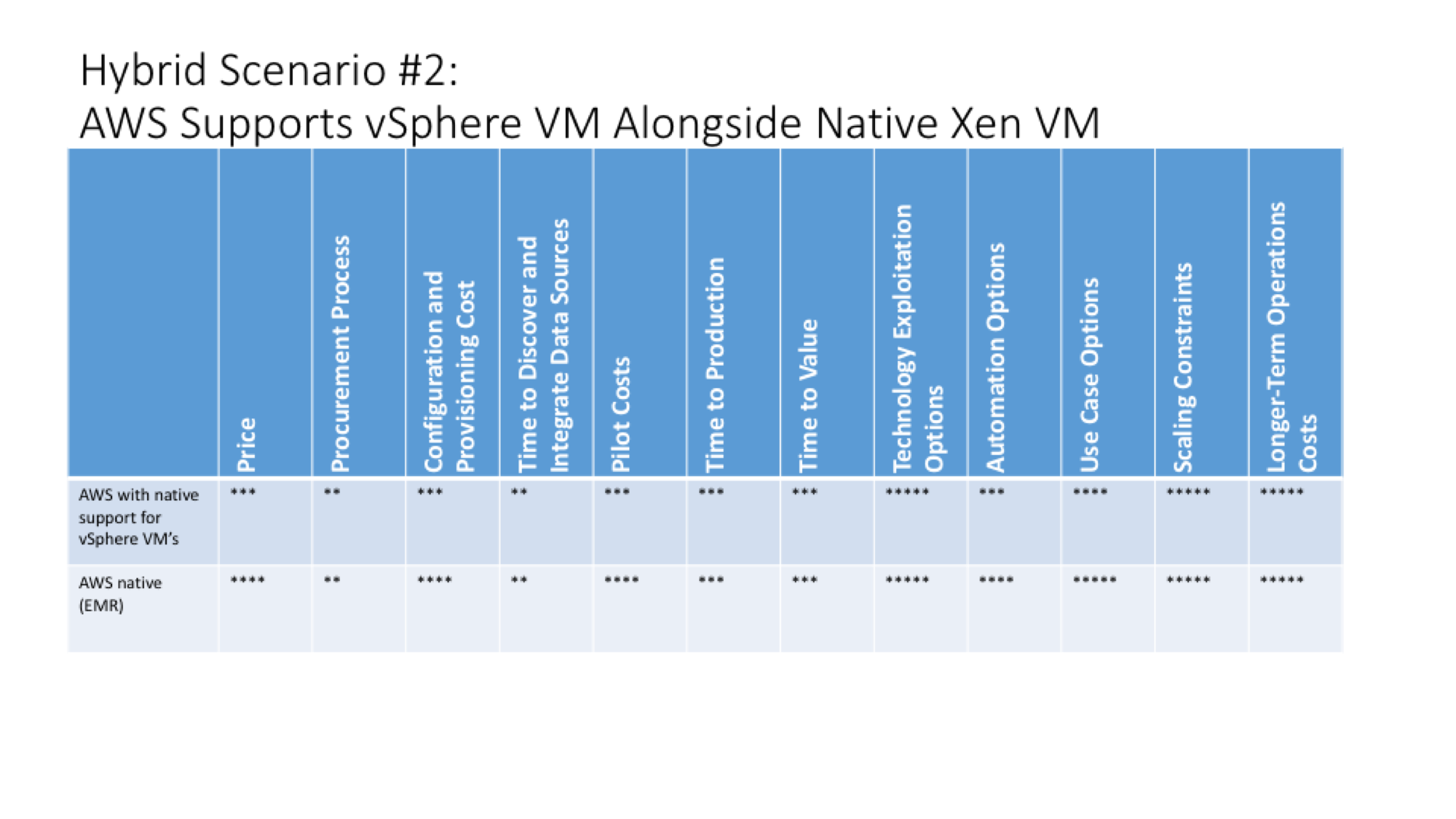
| Comparison criteria | AWS manages vSphere VM’s alongside native Xen VM’s | AWS native |
| Price | Should be similar to EMR when running on AWS. VMware hybrid big data workloads should become more price-competitive with the cloud-only solutions because the hybrid scenario will be able to support ephemeral or elastic clusters. The cloud-based portions of the elastic clusters should also be able to separate storage from compute, allowing idle clusters to be shut down. | AWS has always done better on pricing because it can separate storage from compute. This configuration essentially lets customers shut down a cluster or a portion of a cluster when it’s not needed. This does come at some cost at startup performance, but that is a separate consideration. |
| Procurement Process | AWS billing | Native AWS billing |
| Configuration and Provisioning Cost | Should be closer to AWS EMR if it can use common EMR setup automation. 100% compatibility unlikely in first release. | Low since it is based on EMR service. |
| Time to Discover and Integrate Data Sources | VMware-based VM’s should have the same access to data in sources such as S3 as EMR. | Data already likely in the cloud in S3 where it can be more easily separated from compute. Neither solution includes good data discovery tools such as Alation. |
| Pilot Costs | Some amount of the tooling for EMR or a similar workload should accelerate the time to stand up a pilot. | EMR workload pre-defined. |
| Time to Production | VMware-based Hadoop should be able to leverage some of the data movement, preparation, and other ingest and analysis services already on AWS. | Building blocks to create ingest and output pipeline already in place. Not yet data-as-a-service. |
| Technology Exploitation Options | While unlikely to be able to interoperate with 100% of native AWS services because of compatibility issues, options should be much more expansive than in a scenario with VMware as an isolated set of infrastructure. | Richest selection of native and third party applications, tools, and services. |
| Automation Options | The crucial feature is that automation options should now be able to span workloads that originated in both VMware and in AWS. | Broadest selection of native and third party apps, tools, and services includes basic operational automation at least. |
| Use Case Options | Ephemeral clusters expanded from fixed on-prem clusters for data science and exploration, data prep and ETL, and analytics & ad-hoc reporting. | In addition to ephemeral clusters, native AWS should support online applications built on NoSQL and traditional RDBMS’s. |
| Scaling Constraints | Likely just as capable as AWS in elasticity. Speed of spinning up new nodes relative to AWS Xen-based VM’s is unclear. | No limits other than speed of adding new nodes. |
| Longer-Term Operations Costs | AWS likely to be able to take over management formerly done by the customer, including patches, upgrades, and other admin tasks typical of on-prem software. | Hadoop-as-a-Service transfers most operational costs from customers to AWS. Using Hortonworks’ experience with HDInsight on Azure as a proxy, customers experienced 63% lower TCO and 66% higher IT staff efficiencies relative to on-prem deployments. |

| Comparison criteria | AWS manages on-prem appliance running AWS stack with vSphere support | AWS native |
| Price | An on-prem device changes the pricing model. AWS could lease the hardware so that it is accounted for as an operating expense. Chargeback for use of the AWS services should leverage the billing mechanism within the AWS stack. What’s unclear is if VMware’s higher price points for basic VM’s relative to AWS would raise the price for the combined VMware AWS stack relative to standalone AWS. In big data workloads, the biggest likely difference in price relative to cloud-based Hadoop should be whether the on-prem workload can separate storage from compute. If it can separate the two, cost should not be much different from AWS cloud-based services such as EMR. | AWS used to do better on pricing because it could separate storage from compute. This configuration essentially lets customers shut down a cluster or a portion of a cluster when it’s not needed. |
| Procurement Process | The customer now has to go through the traditional procurement process for on-prem hardware and software. Once the appliance is on-prem, however, it’s likely to facilitate easier procurement of services that span on-prem and AWS in the cloud. | Native billing |
| Configuration and Provisioning Cost | Since this is a deployment that encompasses on-prem and cloud, this activity will be more complex and expensive than cloud-only solutions. AWS may still take responsibility for managing both sides as a service, but there will likely be some differences in admin. | Same as traditional AWS |
| Time to Discover and Integrate Data Sources | On-prem appliances should place big data workloads closer to the data sets that have been traditionally better curated than the data that’s only recently been migrating to the cloud. Highly curated data comes from data warehouses as well feeds from operational applications. | Data already likely in the cloud in S3 where it can be more easily separated from compute. Neither solution includes good data discovery tools such as Alation. |
| Pilot Costs | Some amount of the tooling for EMR or a similar workload should accelerate the time to stand up a pilot. This tooling should work on-prem as well as for workloads that span on-prem and AWS. | EMR workload pre-defined. |
| Time to Production | VMware-based Hadoop should be able to leverage some of the on-prem data movement, preparation, and other ingest and analysis services already built for on-prem Hadoop. Access to these services would be in addition to the on-prem services that a VMware-based solution already has. | Building blocks to create ingest and output pipeline already in place. Not yet data-as-a-service. |
| Technology Exploitation Options | Options under this scenario should be greater than a VMware-based cloud option. In this case, applications and services are available both on-prem and in the cloud. | Richest selection of native and third party applications, tools, and services. |
| Automation Options | The crucial feature is that automation options should now be able to span workloads that originated in on-prem VMware, cloud-based VMware, and in AWS. | Broadest selection of native and third party apps, tools, and services includes basic operational automation at least. |
| Use Case Options | Ephemeral clusters expanded from fixed on-prem clusters for data science and exploration, data prep and ETL, and analytics & ad-hoc reporting. | In addition to ephemeral clusters, native AWS should support online applications built on NoSQL and traditional RDBMS’s. |
| Scaling Constraints | Likely just as capable as AWS in elasticity. Speed of spinning up new nodes relative to AWS Xen-based VM’s is unclear. | No limits other than speed of adding new nodes. |
| Longer-Term Operations Costs | AWS likely to be able to take over management formerly done by the customer, including patches, upgrades, and other admin tasks typical of on-prem software. | Hadoop-as-a-Service transfers most operational costs from customers to AWS. Using Hortonworks’ experience with HDInsight on Azure as a proxy, customers experienced 63% lower TCO and 66% higher IT staff efficiencies relative to on-prem deployments. |


